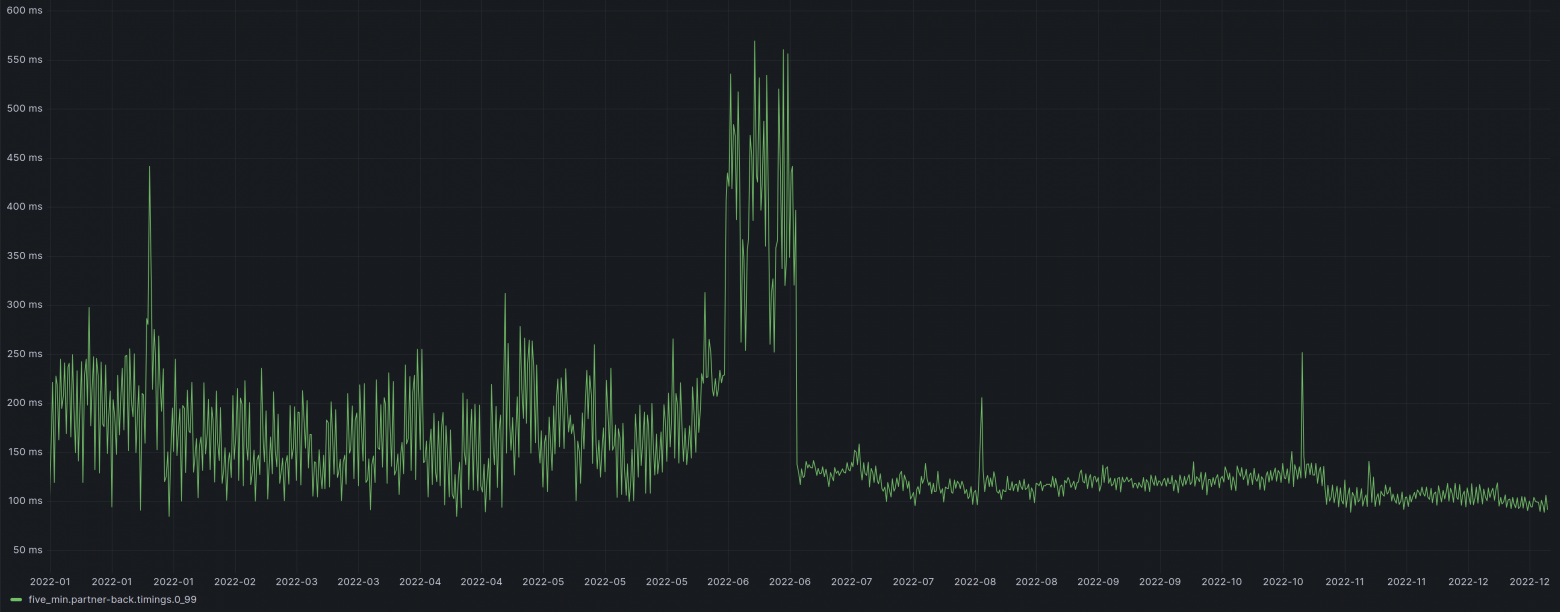
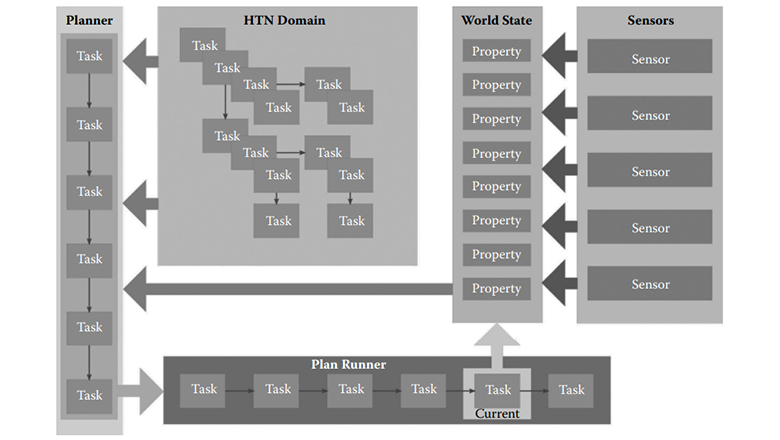
Я уже не раз писал, что условия с несколькими неравенствами (<, <=, >=, >) обычно плохо подходят для индексирования "классическим" btree, вызывают "тормоза", и необходимо придумывать различные нетривиальные подходы в PostgreSQL, чтобы добиться хорошей производительности подобного запроса.
В этой статье мы не только рассмотрим способы решения подобных задач "в общем виде", но и покажем, как нам удалось автоматизировать их решение в рамках функционала рекомендаций индексов нашего сервиса анализа планов explain.tensor.ru и его новых возможностях.