
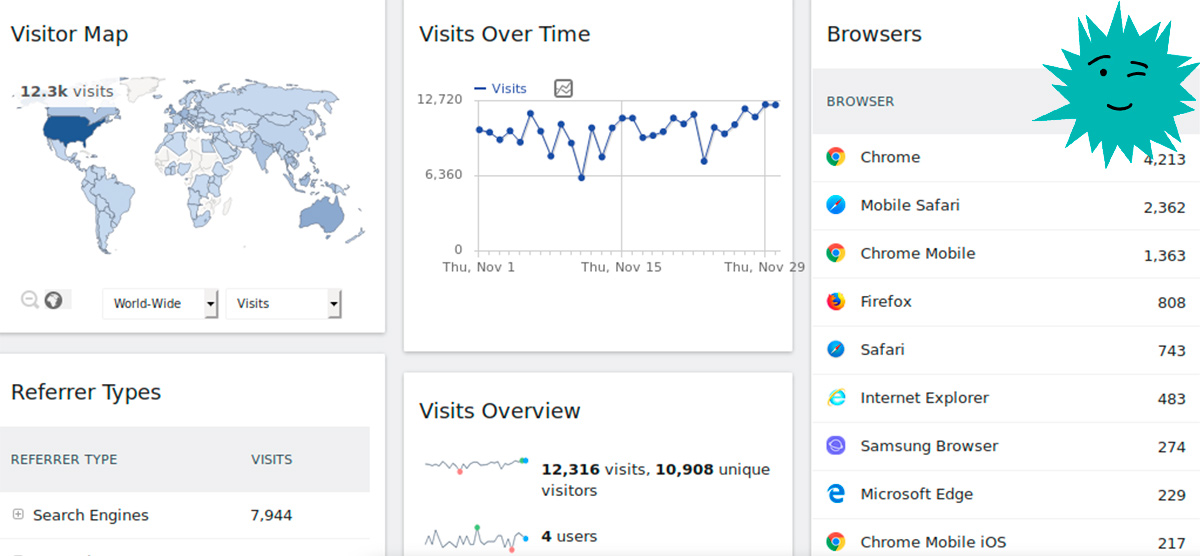
В этой статье приведены примеры популярных запросов Prometheus для мониторинга Kubernetes.
Рейтинг основан на опыте компании Sysdig, ежедневно оказывающей сотням клиентов помощь в настройке мониторинга их кластеров.

Пользователь
В этой статье приведены примеры популярных запросов Prometheus для мониторинга Kubernetes.
Рейтинг основан на опыте компании Sysdig, ежедневно оказывающей сотням клиентов помощь в настройке мониторинга их кластеров.

В последнее время на Хабре появляется всё больше статей о кастомных клавиатурах вообще и об эргономичных сплит клавиатурах (эргосплит) в частности. И это хорошо, ведь, глядя на ассортимент клавиатур в магазинах электроники, можно подумать, что альтернативы стандартным клавиатурам нет, а это далеко не так. Однако…
Не так давно вышла статья Эргономичная раздельная клавиатура. Iris. И знаете, какой комментарий набрал наибольшее количество голосов?
Что вы там этими клавиатурами набираете? Как жить без стрелок, PgUp/PgDn и прочего? А для почти всех IDE нужны F-клавиши.
Переключаться между десятком режимов, забивая ими голову, и скроллить через HJKL?
Каждый раз, когда вижу такие изделия, впечатление что это для того, чтобы было "как в кино у хакеров".
Эргономика должна быть не только для пальцев, но и для мозга.
Неужели с эргосплитами всё так плохо?
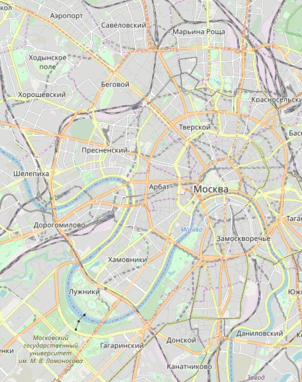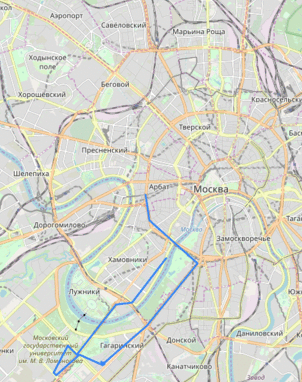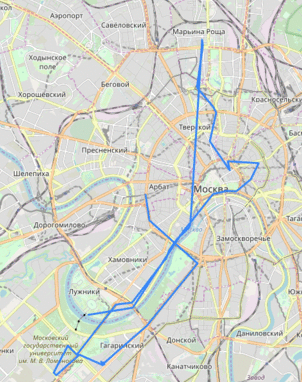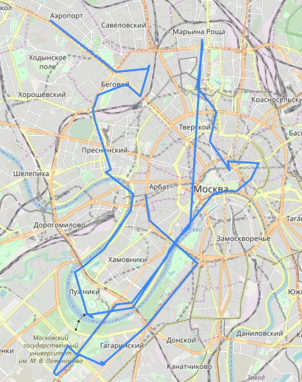 Утечка данных по всем машинам «Ситимобила» позволяет отслеживать конкретный автомобиль по его координатам. Мы не знаем фамилии водителя или номера, но видим его перемещения. Можете посмотреть в окно — и проверить, откуда приехало конкретное такси и куда оно повезёт следующего пассажира. Представитель компании не считает это проблемой.
Утечка данных по всем машинам «Ситимобила» позволяет отслеживать конкретный автомобиль по его координатам. Мы не знаем фамилии водителя или номера, но видим его перемещения. Можете посмотреть в окно — и проверить, откуда приехало конкретное такси и куда оно повезёт следующего пассажира. Представитель компании не считает это проблемой.Данная статья является частью серии «Кейс Locomizer», см. также

Мне нравится метал музыка разных направлений. Для отслеживания новинок я сделал парсер, который ищет свежие альбомы и складывает их в базу. За время существования приложения парсер я почти не трогал, хотя он и далек от идеала, а вот фронтенд был переделан несколько раз.
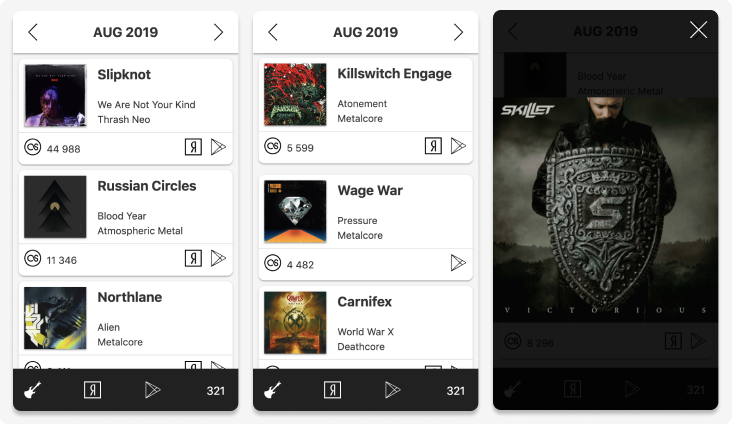
Под катом рассказ о том, как я переписал приложение с react-native на Svelte и опубликовал его в Google Play.
На днях писал тесты для модуля, который взаимодействует с базой данных. Привязывать модуль тестов к настоящей базе данных не хотелось — это создаёт дополнительные требования к окружению, где будет выполняться тестирование. Создавать сразу экземпляры типа sql.Rows, с нужными табличками также не хотелось — для меня этот тип "чёрный ящик", и хотелось бы, чтобы так оно и оставалось. Поиском по теме ничего интересного также не нашлось.
Захотел поделиться с сообществом своей находкой: в основной поставке Go, есть почти готовый инструмент для таких нужд: называется FakeDb.




PULSE_PROP="filter.want=echo-cancel"Вы под давлением коллег или сокурсников из более успевающих групп решились на отчаянный шаг, способный разделить вашу жизнь на период "до" и "после" (прошли vimtutor), и теперь не знаете что делать с вашими новообретёнными способностями? А может вы всё ещё сидите в какой-нибудь IDE и в ус не дуете зачем вам "эти ваши программистские блокноты" и "какой-то там Vim"? Тогда присаживайтесь поудобнее и налейте себе лимонад, сейчас я вам всё по полочкам разложу.

Казалось бы, тема избитая – про резервное копирование сказано и написано многое, поэтому нечего изобретать велосипед, просто бери и делай. Тем не менее, каждый раз, когда перед системным администратором web-проекта встает задача настроить бэкапы, для многих она повисает в воздухе большим вопросительным знаком. Как правильно собрать бэкап данных? Где хранить резервные копии? Как обеспечить необходимый уровень ретроспективы хранения копий? Как унифицировать процесс резервного копирования для целого зоопарка различного ПО?


 Когда я представляюсь и говорю, чем занимается наш стартап, у собеседника сразу возникает вопрос: вы раньше работали в Facebook, или ваша разработка создана под влиянием Facebook? Многие знают об усилиях Facebook по обслуживанию своего социального графа, потому что компания опубликовала несколько статей об инфраструктуре этого графа, который она тщательно выстроила.
Когда я представляюсь и говорю, чем занимается наш стартап, у собеседника сразу возникает вопрос: вы раньше работали в Facebook, или ваша разработка создана под влиянием Facebook? Многие знают об усилиях Facebook по обслуживанию своего социального графа, потому что компания опубликовала несколько статей об инфраструктуре этого графа, который она тщательно выстроила.
Итак, у вас есть кластер Kubernetes, а для проброса внешнего трафика сервисам внутри кластера вы уже настроили Ingress-контроллер NGINX, ну, или пока только собираетесь это сделать. Класс!
Я тоже через это прошел, и поначалу все выглядело очень просто: установленный NGINX Ingress-контроллер был на расстоянии одного helm install. А затем оставалось лишь подвязать DNS к балансировщику нагрузки и создать необходимые Ingress-ресурсы.
Спустя несколько месяцев весь внешний трафик для всех окружений (dev, staging, production) направлялся через Ingress-серверы. И все было хорошо. А потом стало плохо.
Все мы отлично знаем, как это бывает: сначала вы заинтересовываетесь этой новой замечательной штукой, начинаете ей пользоваться, а затем начинаются неприятности.


{kind=link}