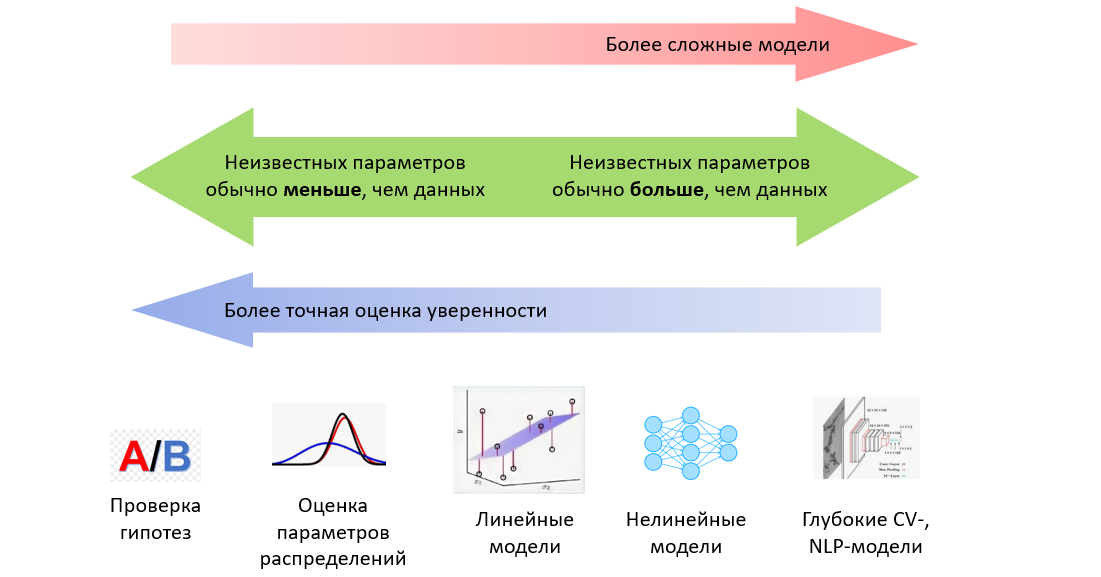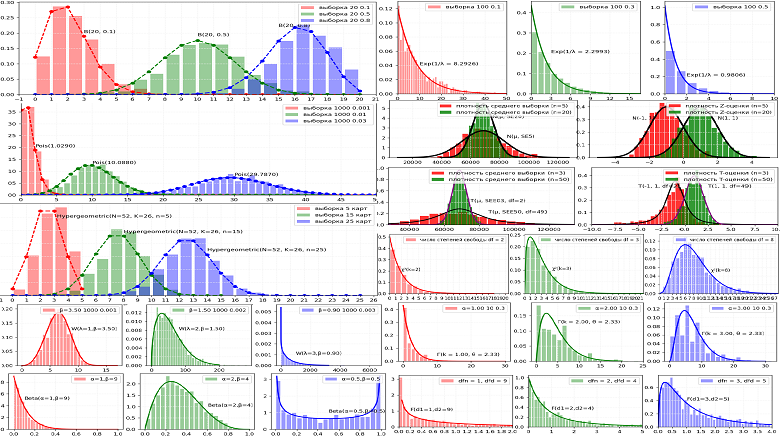
Статистические исследования и эксперименты являются краеугольным камнем развития любой компании. Особенно это касается интернет-проектов, где учёт количества пользователей в день, времени нахождения на сайте, нажатий на целевые кнопки, покупок товаров является обычным и необходимым явлением. Любые изменения в пользовательском опыте на сайте компании (внешний вид, структура, контент) приводят к изменениям в работе пользователя и, как результат, изменения наблюдаются в собираемых данных. Важным элементом анализа изменений данных и его фундаментом является использование основных типов распределений случайных величин, от понимания которых напрямую зависит качество оценки значимости наблюдаемого изменения. Рассмотрим их подробнее на наглядных примерах.