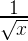 Гейзенбаг — это худшее, что может произойти. В описанном ниже исследовании, которое растянулось на 20 месяцев, мы уже дошли до того, что начали искать аппаратные проблемы, ошибки в компиляторах, линкерах и делать другие вещи, которые стоит делать в самую последнюю очередь. Обычно переводить стрелки подобным образом не нужно (баг скорее всего у вас в коде), но в данном случае нам наоборот — не хватило глобальности виденья проблемы. Да, мы действительно нашли баг в линкере, но кроме него мы ещё нашли и баг в ядре Windows.
Гейзенбаг — это худшее, что может произойти. В описанном ниже исследовании, которое растянулось на 20 месяцев, мы уже дошли до того, что начали искать аппаратные проблемы, ошибки в компиляторах, линкерах и делать другие вещи, которые стоит делать в самую последнюю очередь. Обычно переводить стрелки подобным образом не нужно (баг скорее всего у вас в коде), но в данном случае нам наоборот — не хватило глобальности виденья проблемы. Да, мы действительно нашли баг в линкере, но кроме него мы ещё нашли и баг в ядре Windows.В сентябре 2016 года мы стали замечать случайно происходящие ошибки при сборке Хрома — 3 билда из 200 провалились из-за крэша процесса protoc.exe. Это один из бинарников, который при сборке Хрома сначала собирается сам, а затем запускается для генерации заголовочных файлов других компонентов. Но вместо этого он падал с ошибкой «access violation».