
Поделюсь с вами успешным опытом разработки рендера в браузере большой, постоянно расширяющейся анимационной сцены, состоящей из множества мелких двигающихся объектов, зацикленных в 5 секунд.

User
Поделюсь с вами успешным опытом разработки рендера в браузере большой, постоянно расширяющейся анимационной сцены, состоящей из множества мелких двигающихся объектов, зацикленных в 5 секунд.
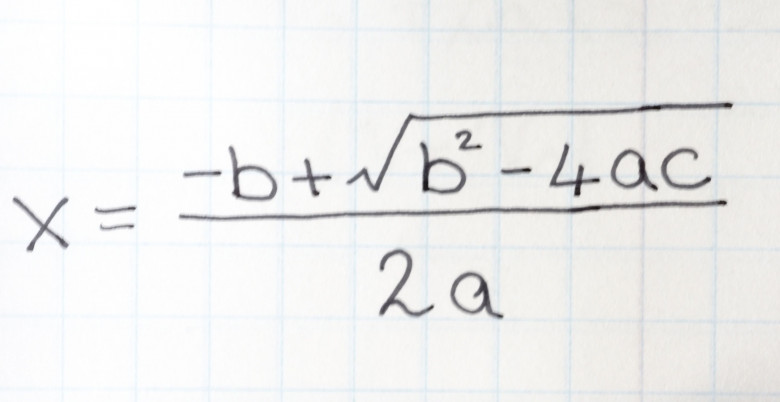
Как вам преподавали квадратные уравнения в школе? Это был 7-8 класс, примерно. Вероятнее всего, вам рассказали что есть формулы корней через дискриминант, что направление ветвей зависит от старшего коэффициента. Через пару занятий дали теорему Виета. Счастливчикам еще рассказали про метод переброски. И на этом решили отпустить.

Красивая формула Бине для чисел Фибоначчи содержит иррациональность - квадратный корень из пяти, что делает ее непригодной для точного вычисления больших чисел Фибоначчи. Это кажется вполне очевидным. Предлагаю способ, как избавиться от зловредного корня и сделать формулу Бине пригодной для точных вычислений.


Привет! Меня зовут Кирилл Богатов, я дизайнер голосовых интерфейсов в команде TORTU и заядлый геймер. Когда эти две страсти сталкиваются, рождаются необычные концепты для голосовых игр.
Месяц назад я выпустил игру «Охота на Вампуса» для голосового ассистента Алисы. Игра получила много положительных отзывов и побывала в топ-10 развлекательных навыков. В этой статье я поэтапно расскажу о процессе её создания: от переосмысления идей первоисточника — до технической реализации.
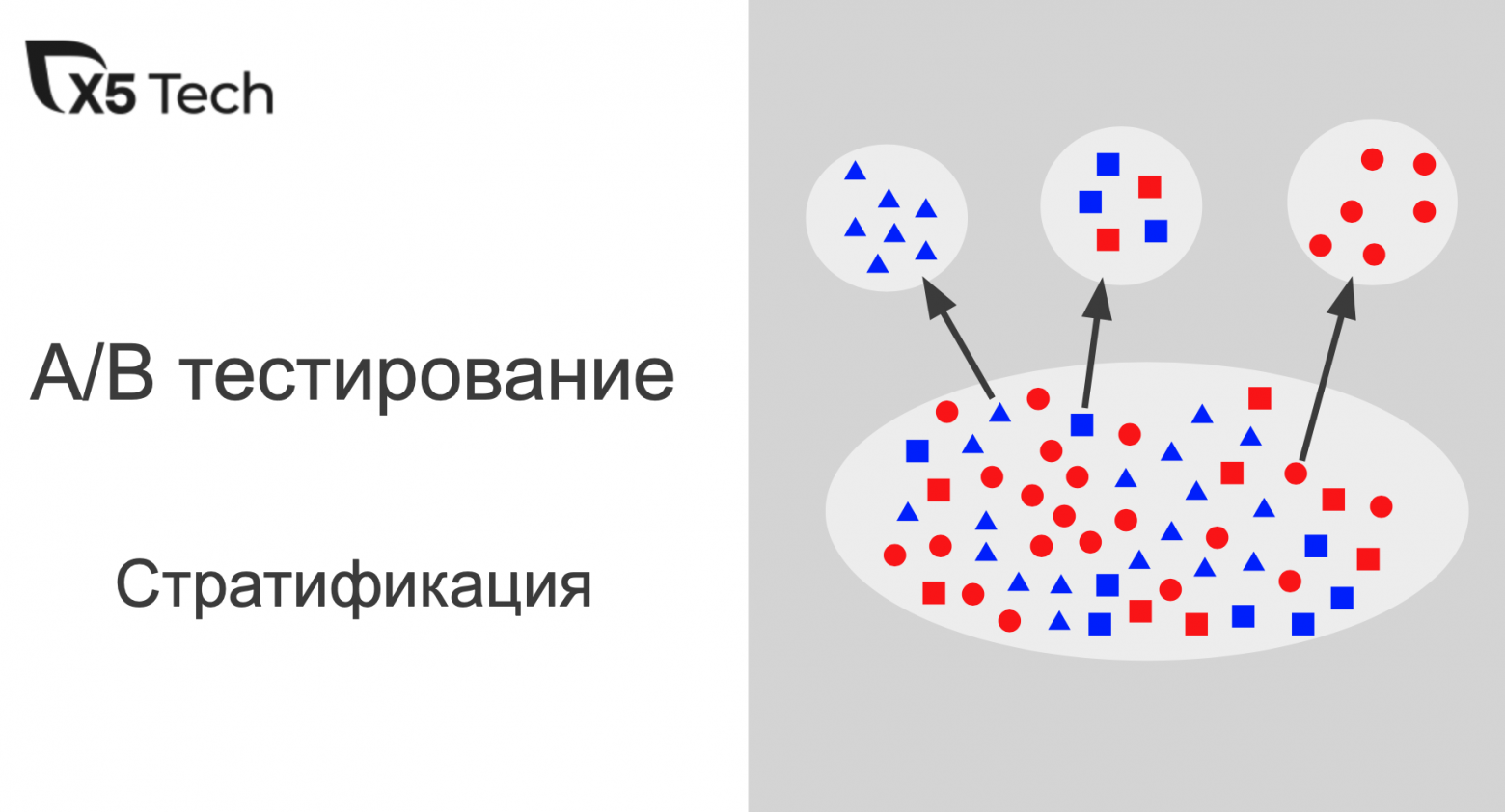
Всем привет! На связи команда ad-hoc аналитики X5 Tech.
Сегодня подробно обсудим применение стратификации для повышения чувствительности оценки AB экспериментов.



В интернете есть много информации о поиске похожих изображений и дубликатов. Но как построить свою систему? Какие современные подходы применять, на каких данных обучать, как валидировать качество поиска и куда смотреть при выводе в production?
В этой статье я собрал все необходимые компоненты поисковой системы на изображениях в одном месте, разбавив контент современными подходами.
") ,
, )") — пересечение полуплоскостей,
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
Приветствую тебя, Хабр! Наверняка вы заметили, что тема стилизации фотографий под различные художественные стили активно обсуждается в этих ваших интернетах. Читая все эти популярные статьи, вы можете подумать, что под капотом этих приложений творится магия, и нейронная сеть действительно фантазирует и перерисовывает изображение с нуля. Так уж получилось, что наша команда столкнулась с подобной задачей: в рамках внутрикорпоративного хакатона мы сделали стилизацию видео, т.к. приложение для фоточек уже было. В этом посте мы с вами разберемся, как это сеть "перерисовывает" изображения, и разберем статьи, благодаря которым это стало возможно. Рекомендую ознакомиться с прошлым постом перед прочтением этого материала и вообще с основами сверточных нейронных сетей. Вас ждет немного формул, немного кода (примеры я буду приводить на Theano и Lasagne), а также много картинок. Этот пост построен в хронологическом порядке появления статей и, соответственно, самих идей. Иногда я буду его разбавлять нашим недавним опытом. Вот вам мальчик из ада для привлечения внимания.



Так муравьи, столкнувшись где-нибудь,
Потрутся рыльцами, чтобы дознаться,
Быть может, про добычу и про путь.
Но только миг объятья дружбы длятся,
И с первым шагом на пути своем
Одни других перекричать стремятся...

