
Краткое и понятное описание подхода RAG (Retrieval Augmented Generation) при работе с большими языковыми моделями.

Data Engineer | Python Software Engineer
Краткое и понятное описание подхода RAG (Retrieval Augmented Generation) при работе с большими языковыми моделями.
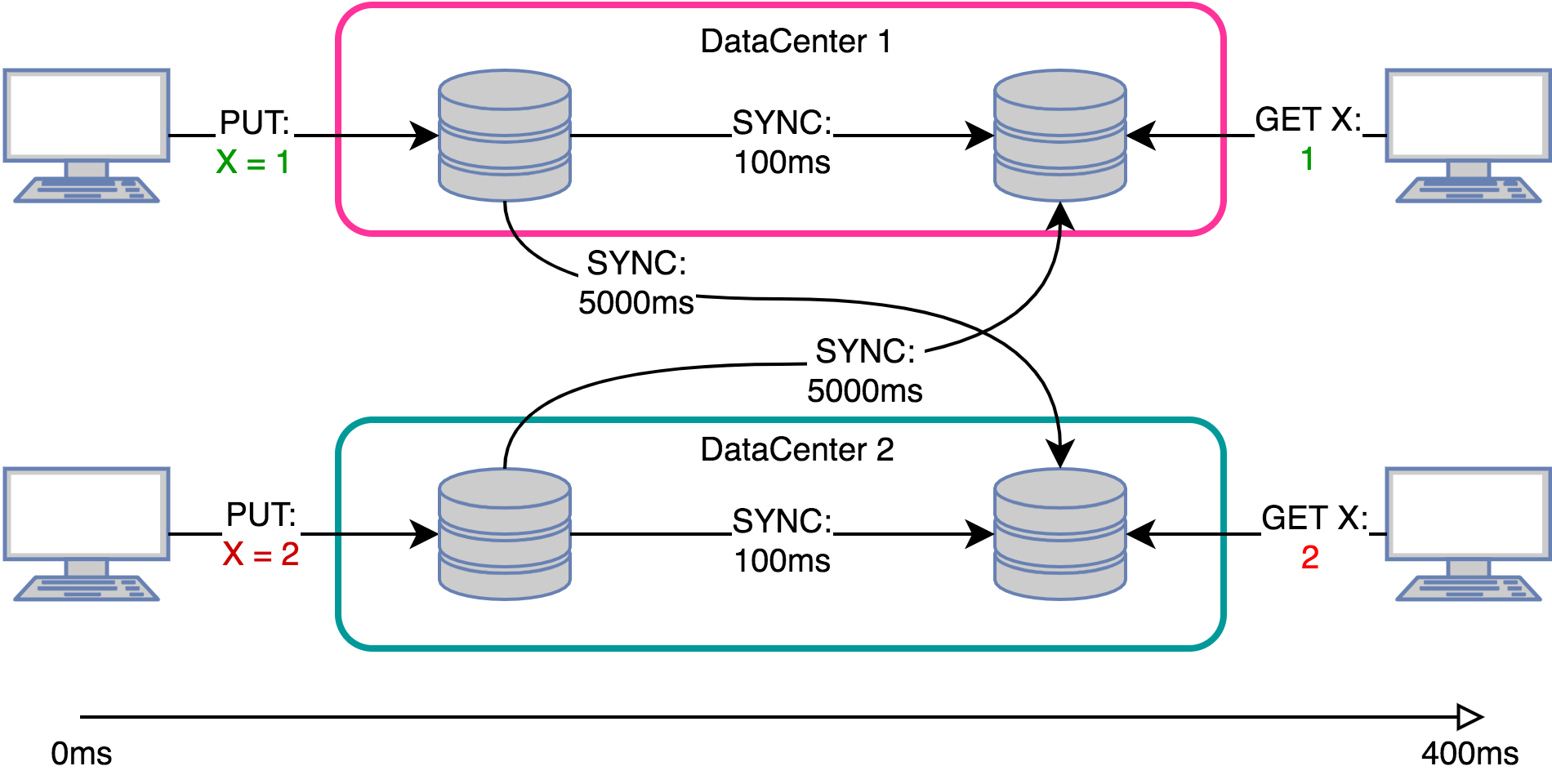

В настоящее время набирают популярность модели Reinforcement Learning для решения прикладных задач бизнеса. В этой статье мы рассмотрим подмножество этих моделей, а именно многоруких бандитов (multi-armed bandits). Также мы:
- обсудим, какие задачи теоретически могут быть решены с помощью этих моделей;
- рассмотрим некоторые популярные реализации моделей многоруких бандитов;
- опишем симулятор ценообразования, применим эти алгоритмы в нём и сравним их эффективность.

Завершаем исследование фреймворка llamaIndex. В этой части разбираемся с ретриверами, которые обеспечивают различные способы извлечения релевантного контекста из индексов документов.

Продолжаем изучать фреймворк для создания AI-ботов. В этой части узнаем про тонкости индексирования собственной базы документов.

Принятие решений на основе данных является неотъемлемой частью работы аналитика. Данные помогают сделать это быстро. Но что если объём данных достигает десятков петабайт? Подобная задача становится не такой тривиальной, как может показаться на первый взгляд. Как масштабировать работу с данными в продуктовых командах? Как быстро найти инсайты в куче данных? Какие инструменты могут быть полезны для аналитика?
Заинтригованы? Добро пожаловать в мир аналитики больших данных.

Занимаясь BI-решениями почти всю сознательную жизнь, я обнаружил, что на самом деле ими пользуются только в случае крайней необходимости.
Про BI вспоминают, когда аудиторы запрашивают детализированные данные для подготовки ежеквартальной/ годовой/ другой отчетности акционерам и топ-менеджменту. Причем очень часто business intelligence системы используются, чтобы сформировать итоговый Excel или PowerPoint. В лучшем случае BI могут применять аналитики для подготовки планов продаж или закупок. Топ-менеджеры, к сожалению, не пользуются BI практически никогда.
Мы придумали, как решить эту проблему и сделать принятие data-driven решений в компании намного проще.



Привет, Хабр, меня зовут Дима. В последние пару лет занимаюсь аналитикой, отвечаю за данные в Почте Mail.ru. Развиваю аналитическое хранилище данных и инструменты для работы с ними. Мы плотно работаем со стеком Hadoop, Hive, Spark, Clickhouse и Kafka. Я хочу остановиться на некоторых аспектах работы с данными в Spark: как мы храним петабайты информации и как выполняем запросы к ним?
Прежде всего поделюсь своими практическими наблюдениями. Расскажу как в нашем хранилище мы превратили 7 петабайт в 0,5 петабайт, что позволило сэкономить годовой бюджет по закупке серверов. И также расскажу о ключевых проблемах с данными, знание о которых помогло бы вам построить своё классное хранилище без последующей переделки.


Если вы работали над проектом по реферированию текстов, то вы могли заметить сложность получения тех результатов, которые ожидалось получить. Если у вас имелись представления относительно того, как должен работать некий алгоритм, какие предложения он должен выделять при формировании рефератов, то этот алгоритм, чаще всего, выдавал результаты, весьма далёкие от ваших представлений. А ещё интереснее — ситуация с извлечением из текстов ключевых слов. Дело в том, что существует множество самых разных алгоритмов — от тех, что используют тематическое моделирование, до тех, где применяется векторизация данных и эмбеддинги. Все они работают очень хорошо. Но если дать одному из них абзац текста, то выданный им результат, опять же, будет далеко не самым правильным. А дело тут в том, что слова, которые встречаются в тексте чаще всего — это не всегда самые важные слова.

Глубокое обучение (Deep learning. DL) - это современное решение многих проблем машинного обучения, таких как компьютерное зрение или недостатки естественного языка, и превосходит альтернативные методы. Последние тенденции включают применение методов DL в рекомендательных системах. Многие крупные компании, такие как AirBnB, Facebook, Google, Home Depot, LinkedIn и Pinterest, делятся своим опытом использования DL для рекомендательных систем.
Недавно NVIDIA и команда RAPIDS.AI выиграли три соревнования с использованием DL: ACM RecSys2021 Challenge, SIGIR eCom Data Challenge и ACM WSDM2021 Booking.com Challenge.
Область рекомендательных систем сложна. В этом посте я сосредоточусь на архитектуре нейронной сети и ее компонентах, таких как эмбеддинг и полностью связанные слои, рекуррентные ячейки нейронной сети (LSTM или GRU) и блоки трансформеров. Я расскажу о популярных сетевых архитектурах, таких как Wide и Deep от Google и Deep Learning Recommender Model (DLRM) от Facebook.
На Хабре можно найти немало статей, посвящённых оптимизациям поиска кратчайшего пути на графе. Я расскажу ещё про еще один подход. Речь пойдёт о распараллеливании алгоритма A* и исполнении его на двух потоках, а также о сложностях, с которыми я столкнулся при реализации, и их преодолении.
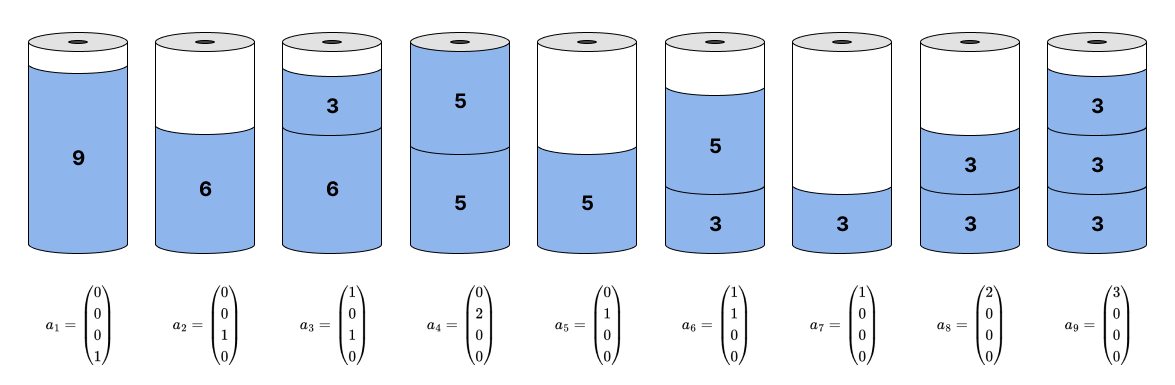
Теперь к истокам задачи: часто, чтобы математическая модель была применима в реальном секторе, необходимо использовать очень много ограничений и большое количество переменных. Задачи, возникающие в бизнесе в реальных условиях, требуют использования моделей с большим количеством ограничений и большим количеством переменных. Временами задача в лоб может и не решиться, поэтому были придуманы различные трюки. Один из них - метод « генерации столбцов» (Column generation).


Привет! Меня зовут Ирина Кротова, я NLP-исследователь из компании MTS AI. В этой статье из цикла про разметку данных я расскажу об ещё одном способе собирать данные более качественно и экономить на разметке — фильтрации похожих друг на друга текстов.
В предыдущей статье я рассказывала о том, что такое аннотация данных, как это связано с работой инженера машинного обучения и о способах сократить количество ручной разметки в проекте.

Roadmap, который поможет вам научиться работать с SQL. Чтобы стать настоящим экспертом в SQL, нужно много практиковаться и изучать различные аспекты языка на протяжении многих лет. Мой Roadmap предлагает отличный старт для начала изучения SQL, поэтому я рекомендую вам приступить к обучению согласно плану.

Один из важных вопросов как в нашей жизни, так и в бизнесе, и в IT — вопрос эффективности. Эффективно ли мы планируем наше время, те ли задачи решает бизнес, тот ли код мы оптимизируем? Чтобы ответить на эти вопросы, результат должен обладать главным критерием — измеримостью. Измеримость результата новых фич для бизнеса и IT обеспечивает платформа А/B-тестов. О том, как её можно построить, выдерживать большой RPS и при этом не облажаться уронить прод, я расскажу в этой статье.
В конце статьи вы узнаете, как мы задетектили проблемы инфраструктуры, оптимизация которых значительно повлияла на скорость всего Ozon.