Привет, хаброчеловек!
В этой статье мы обсудим путь среднестатистического обывателя в Machine Learning, а именно — как стать ML-инженером. Поговорим о специфике области, какие требуются знания и скиллы, что нужно делать и с чего начать.

User
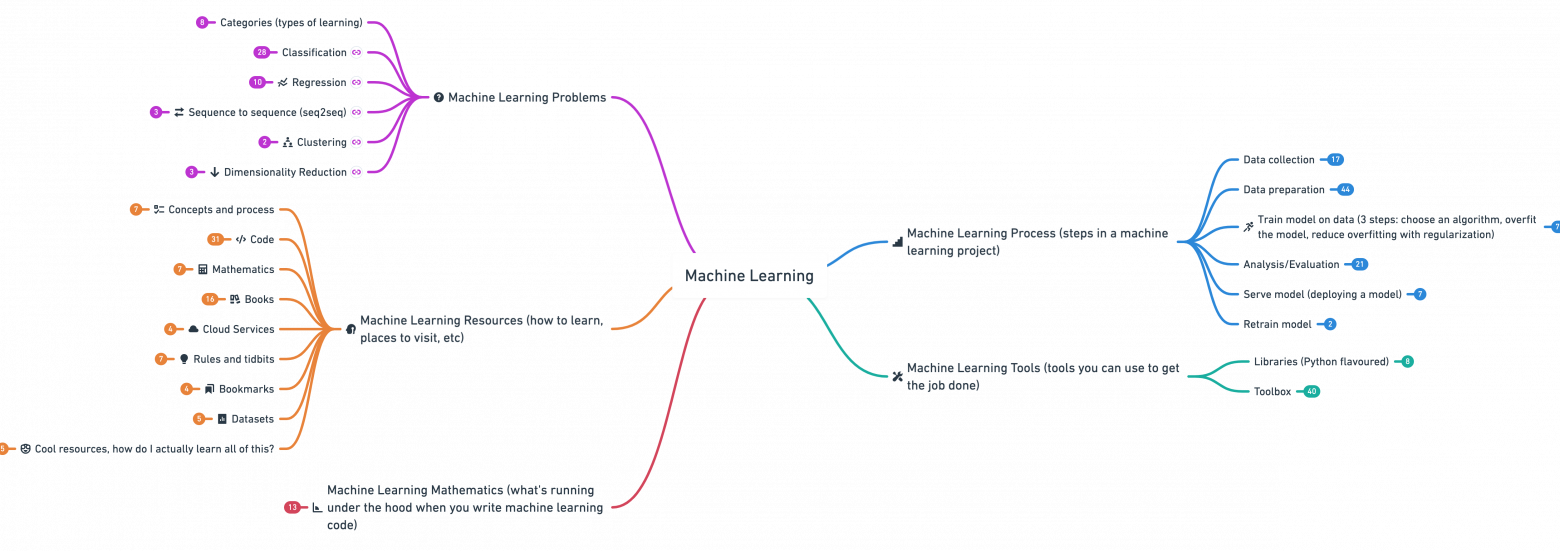
Привет, хаброчеловек!
В этой статье мы обсудим путь среднестатистического обывателя в Machine Learning, а именно — как стать ML-инженером. Поговорим о специфике области, какие требуются знания и скиллы, что нужно делать и с чего начать.
В первой части говорили про использование поиска и генерации ответа с помощью языковых моделей. В этой части рассмотрим память и агентов.
Для этой задачи использую LLM (Large Language Models - например, chatGPT или opensouce модели) для внутренних задач (а-ля поиск или вопрос-ответную систему по необходимым данным).
Я пишу на языке R и также увлекаюсь NLP (надеюсь, я не один такой). Но есть сложности из-за того, что основной язык для LLM - это python. Соответственно, на R мало примеров и документации, поэтому приходится больше времени тратить, чтобы “переводить” с питона, но с другой стороны прокачиваюсь от этого.
Чтобы не городить свою инфраструктуру, есть уже готовые решения, чтобы быстро и удобно подключить и использовать. Это LangChain и LlamaIndex. Я обычно использую LangChain (дальше он и будет использоваться). Не могу сказать, что лучше, просто так повелось, что использую первое. Они написаны на питоне, но с помощью библиотеки reticulate всё работает и на R.
Есть много локальных аналогов ChatGPT, но им не хватает качества, даже 65B модели не могут конкурировать хотя бы с ChatGPT-3.5. И здесь я хочу рассказать про 2 открытые модели, которые всё-таки могут составить такую конкуренцию.
Речь пойдет о OpenChat 7B и DeepSeek Coder. Обе модели за счет размера быстры, можно запускать на CPU, можно запускать локально, можно частично ускорять на GPU (перенося часть слоев на GPU, на сколько хватит видеопамяти) и для такого типа моделей есть графический удобный интерфейс.
И бонусом затронем новую модель для качественного подробного описания фото.
UPD: Добавлена информация для запуска на Windows с ускорением на AMD.

Представьте приложение, в которое вы можете загрузить любую книгу на иностранном языке. При чтении вы будете нажимать на любое незнакомое слово, а приложение будет вам выдавать не кучу переводов из словаря, а предложит перевод, который соответствует контексту. А при переводе устойчивого выражение приложение не просто переведет его, а предложит вам объяснение этой фразы, привязанное к контексту. Ниже я покажу как оно работает.

60 строках numpy. Во второй части статьи мы загрузим в нашу реализацию опубликованные OpenAI веса обученной модели GPT-2 и сгенерируем текст.
Вышедшая чуть больше месяца назад ChatGPT уже успела нашуметь: школьникам в Нью-Йорке запрещают использовать нейросеть в качестве помощника, её же ответы теперь не принимаются на StackOverflow, а Microsoft планирует интеграцию в поисковик Bing - чем, кстати, безумно обеспокоен СЕО Alphabet (Google) Сундар Пичаи. Настолько обеспокоен, что в своём письме-обращении к сотрудникам объявляет "Code Red" ситуацию. В то же время Сэм Альтман, CEO OpenAI - компании, разработавшей эту модель - заявляет, что полагаться на ответы ChatGPT пока не стоит.
Насколько мы действительно близки к внедрению продвинутых чат-ботов в поисковые системы, как может выглядеть новый интерфейс взаимодействия, и какие основные проблемы есть на пути интеграции? Могут ли модели сёрфить интернет бок о бок с традиционными поисковиками? На эти и многие другие вопросы постараемся ответить под катом.
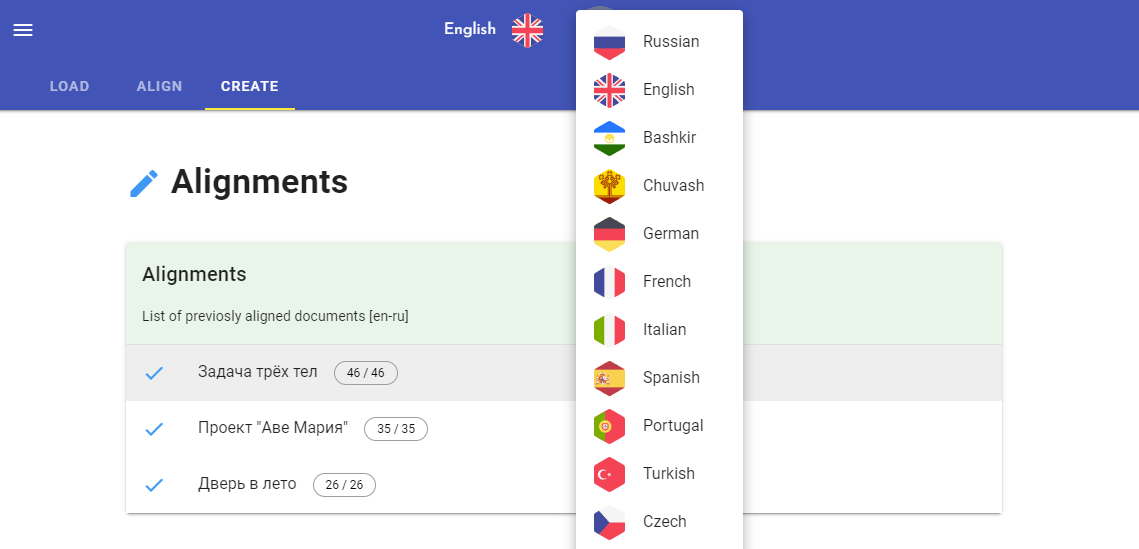
Хочу показать, как создать мультиязычный параллельный корпус и книги при помощи моего пет-проекта.
Для примера возьмем 10 редакций "Мастера и Маргариты" Михаила Булгакова (ru, uk, by, en, fr, it, es, de, hu, zh). Сначала выровняем девять переводов с оригиналом, а затем выровняем все вместе. Получим параллельный корпус на 10 языках и много красивых книг. Приступим.
Код я оформил в виде веб-приложения, основная логика которого выполняется при помощи библиотеки lingtrain-aligner. Выравнивать можно прямиком из кода на python, либо через UI. В приложении будет удобней разрешать конфликты и там есть редактор, позволяющий корректировать получающийся корпус плюс дополнительные опции по верстке. Код у проекта открытый, можно посмотреть как все работает внутри. Приступим.

Разберёмся что “под капотом” формата EPUB и как перевести текст, но не переводить код в книге. Познакомимся с библиотекой Ebook Lib, а также узнаем для чего нам понадобиться библиотека Beautiful Soup.
Сложно понять содержимое текста, если в нем встречается много незнакомых слов. Вариант решения этой проблемы – замена слов на близкие к ним по значению. Заменить слово на синоним можно, например, тремя способами – трансформером, word2vec и его модификацией - RusVectores.
Зачем вообще упрощать текст? Есть, как минимум, три кейса, почему есть вероятность столкнуться с этой задачей:
- если перед вами текст на иностранном языке, то замена «сложного» слова на синоним поможет сориентироваться в сути предложения
- если вы работаете с доменной тематикой, то также подбор синонимов может сделать текст проще для восприятия (так, например, «ирригация» можно заменить на «орошение» и наоборот, в таком случае шанс понять текст у читающего увеличивается)
- для расширения датастета: аугментация текстовых данных – это всегда вызов, важно учитывать контекст для того, чтобы подобрать синоним. Тут, конечно, важно учитывать размер корпуса, частота встречаемости слов в рамках контекста будет точнее, если корпус состоит из миллионов предложений, а не из тысяч.
Если говорить более предметно, то это задача делится на две: поиск сложного слова или словосочетания и поиска его замены, исходя из контекста. Давайте последовательно разберемся с каждой из задач.
Если кому-то интересно ознакомиться только с кодом, то welcome на github, там можно найти пошаговую реализацию.
Задача выделения сложных слов

Эта статья посвящена основным современным моделям для генерирующего реферирования и генерации текста в целом: BertSumAbs, GPT, BART, T5 и PEGASUS, и их использованию для русского языка.
В отличие от извлекающих моделей, которые рассмотрены в предыдущих двух статьях, эти модели создают новые тексты, а не только выделяют предложения из оригинального документа. Из-за этого они могут нетривиально изменять исходный текст: удалять слова или заменять их на синонимы, сливать и упрощать предложения, а значит делать ровно то, что делают люди при составлении рефератов.
Ещё десять лет назад методы из этой категории казались фантастикой. Развитие систем нейросетевого машинного перевода сделало генерирующее автоматическое реферирование намного более лёгкой задачей.
Серьёзные методы оценки качества реферирования будут в следующих частях цикла. Сейчас же для наглядности мы испытаем алгоритмы на одной конкретной новости про секвенирование РНК клеток коры головного мозга. Это свежая новость, то есть модели заведомо не могли её видеть. К тому же она довольно сложная: 5.7 баллов по шкале N+1.
Кстати говоря, заголовок к этой статье написан одной из описываемых моделей.
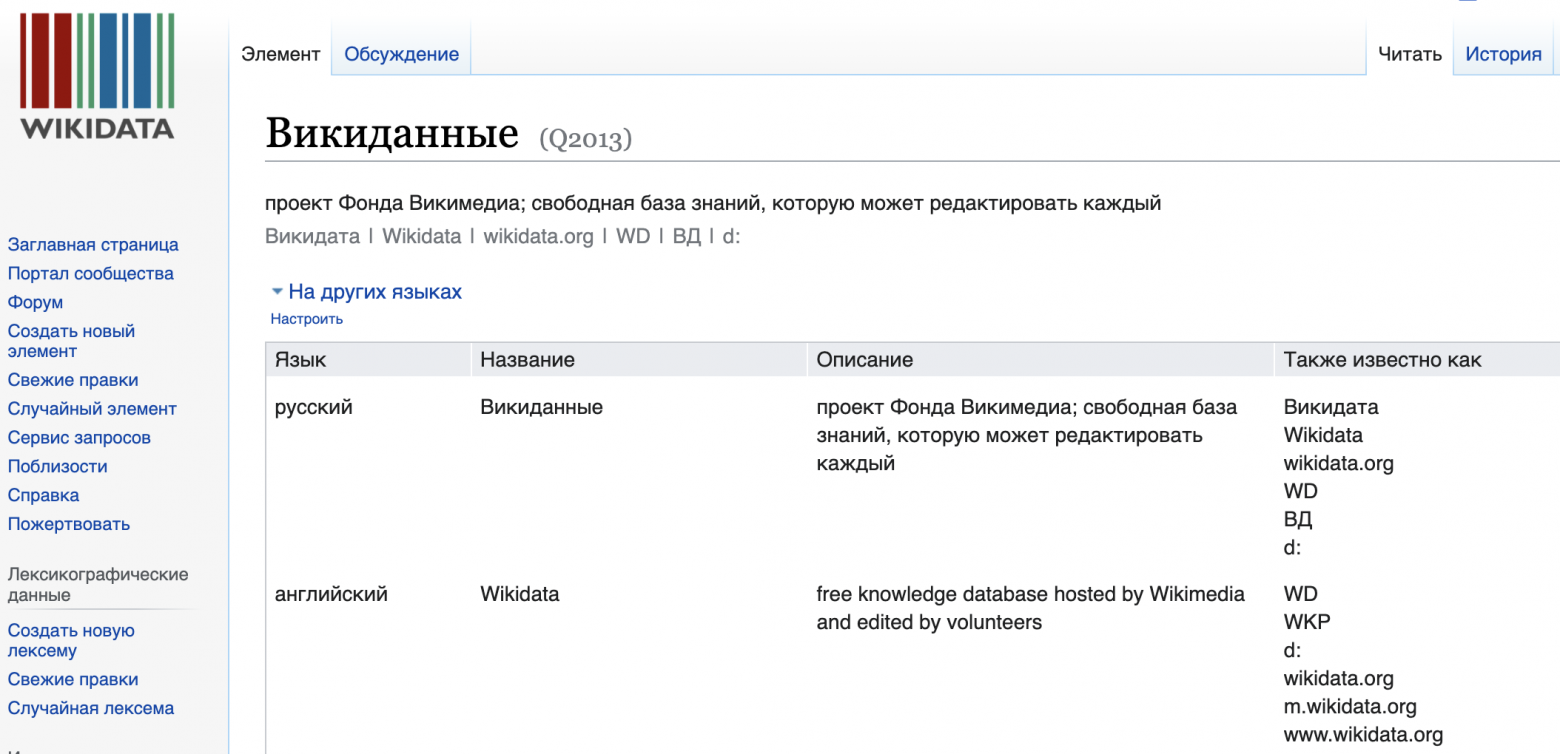
Существует множество сервисов по подбору синонимов, но они редко справляются с терминами, которые содержат в себе более одного слова. Для подбора синонимов для более сложных выражений могут помочь Викиданные. Мало кто знает, что помимо стандартной Википедии существует дополнительная база данных Викиданные(Wikidata), которая представляет собой граф знаний фонда Викимедия. Сейчас она интегрирована в саму Википедию, поэтому для многих статей в левом меню можно найти пункт Элемент Викиданных. Викиданные представлены в модели rdf, то есть информация имеет вид триплетов, которые характеризуют сущность. Триплет выглядит, как утверждение субьект - предикат - обьект. Пример, для сущности Англия одним из таких информационных триплетов представлен: Англия - имеет столицу - Лондон.
Один из предикатов(типов связи) это altLabel, подразумевающий под собой альтернативные названия, который как раз таки и поможет нам в поиске синонимов.
Сразу стоит учитывать, что Викиданные это очень обширная база знаний, но, тем не менее, не совершенная. Поэтому, для терминов, которые там не представлены, или представлены, но для их сущностей нет введенных альтернативных названий, синонимов найдено не будет.

К старту флагманского курса по Data Science делимся визуализациями марсианского ландшафта на основе изображений, полученных благодаря беспилотным полётам над поверхностью планеты. За подробностями приглашаем под кат.

И снова всем привет!
На этот раз рассмотрим извлекающие методы, которым нужны эталонные рефераты для обучения. При этом эти методы всё ещё могут лишь выбирать предложения из оригинального текста. К методам этой группы и относятся описываемые ниже SummaRuNNer и BertSumExt.
Статьи цикла:
1) Постановка задачи автоматического реферирования и методы без учителя
2) Извлекающие методы автоматического реферирования ⬅️
3) Секреты генерирующего реферирования текстов

Предупреждение: в статье присутствуют заголовки реальных новостей. Я отношусь к ним исключительно как к рабочему материалу, не представляю какую-либо точку зрения на политическую или экономическую ситуацию в какой бы то ни было стране.

Всем привет!
Для написания кандидатской диссертации я недавно составил обзор различных методов автоматического реферирования, суммаризации. Обзор получился субъективно хорошим, поэтому я публикую его и здесь. Он очень объёмный, и я разбил его на несколько частей, которые и буду постепенно выкладывать. По мере публикации ниже будут появляться ссылки на остальные части цикла.
Статьи цикла:
1) Постановка задачи автоматического реферирования и методы без учителя ⬅️
2) Извлекающие методы автоматического реферирования
3) Секреты генерирующего реферирования текстов
Это первая статья цикла, посвящённая самой задаче и методам без учителя, которым не нужен эталонный корпус рефератов: методу Луна, TextRank, LexRank, LSA и MMR.


Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов... или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимаетот него хотите, благодаря ш, что вы тукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с "простым текстом" или формулы, например. В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру "ó", поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Так как всё-таки происходит обработка таких запросов?
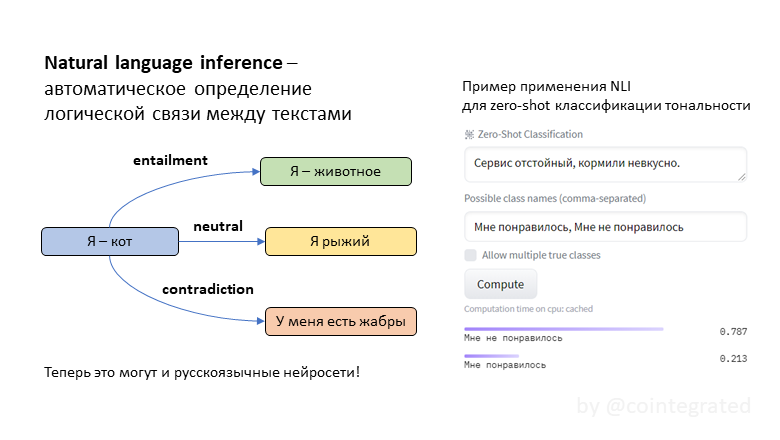
NLI (natural language inference) – это задача автоматического определения логической связи между текстами. Обычно она формулируется так: для двух утверждений A и B надо выяснить, следует ли B из A. Эта задача сложная, потому что она требует хорошо понимать смысл текстов. Эта задача полезная, потому что "понимательную" способность модели можно эксплуатировать для прикладных задач типа классификации текстов. Иногда такая классификация неплохо работает даже без обучающей выборки!
До сих пор в открытом доступе не было нейросетей, специализированных на задаче NLI для русского языка, но теперь я обучил целых три: tiny, twoway и threeway. Зачем эти модели нужны, как они обучались, и в чём между ними разница – под катом.