Бэкапы нужно проверять.
В качестве вступления простая история из бурной молодости. Всем знакома ситуация, когда ресурсов нет, а хранить резервные копии нужно. В свое время для хранения резервных копий своих систем, использовалось два диска объемом по 500GB. Как можно было догадаться, при использовании RAID-1, полезное пространство ограничивалось теми самыми 500GB, чего катастрофически не хватало. Было принято решение использовать Linux LVM, тем самым получить 1000GB пространства, в ущерб надежности.
На протяжении года, а может и больше, резервные копии складывались на данный ресурс, скрипты отчитывались о том, что все хорошо, а список бэкапов при просмотре содержимого директории радовал глаз.
Наступил час Х, и нужно было восстанавливаться, удивлению не было предела, когда один из бэкапов был поврежден, ведь все говорило о том, что бэкапы делаются, хранятся, и в целом все хорошо. Как позже выяснилось, один из дисков, состоящих в LVM начал сыпаться, часть данных можно было восстановить, а другую часть уже нет.
Никогда не делайте так, как это делал в свое время я.
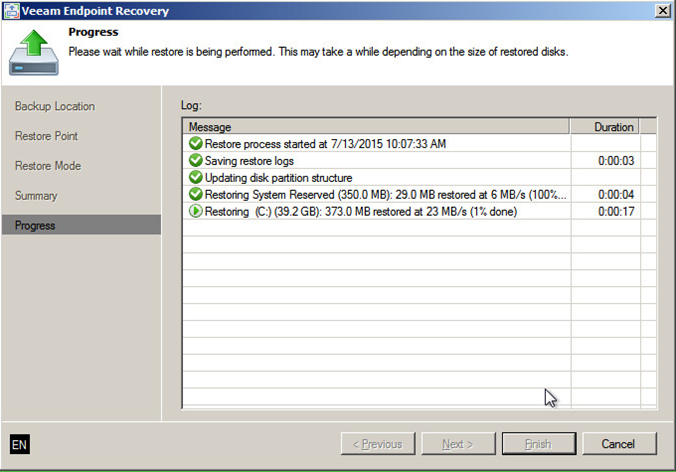
Сейчас уже мало компаний, не использующих у себя виртуализацию, чуть больше компаний, которые не выполняют резервное копирование своих виртуальных машин, и, возможно, еще больше тех, кто не проверяет свои резервные копии.
Тем, кому интересно как Veeam проверяет свои резервные копии, прошу под кат.




 В последние пару лет я все чаще использую Ansible для решения практически любых задач связанных с автоматизацией, будь то конфигурирование, резервное копирование или деплой проектов. Не смотря на то, что система очень хорошо документирована, я думаю смогу добавить немного полезной информации для тех кто еще только начинает пользоваться Ansible. Для начала я хотел бы рассказать об основных вещах, таких как структура проекта в котором будут содержаться плейбуки, роли, переменные, шаблоны и файлы необходимые для автоматизации развертывания серверов, кода и всего другого, что можно сделать с помощью Ansible.
В последние пару лет я все чаще использую Ansible для решения практически любых задач связанных с автоматизацией, будь то конфигурирование, резервное копирование или деплой проектов. Не смотря на то, что система очень хорошо документирована, я думаю смогу добавить немного полезной информации для тех кто еще только начинает пользоваться Ansible. Для начала я хотел бы рассказать об основных вещах, таких как структура проекта в котором будут содержаться плейбуки, роли, переменные, шаблоны и файлы необходимые для автоматизации развертывания серверов, кода и всего другого, что можно сделать с помощью Ansible.