
Если бы хайлоад преподавали в школе, в учебнике по этому предмету была бы такая задача. «У соцсети N есть 2 000 серверов, на которых 150 000 файлов объемом по 900 Мб PHP-кода и стейджинг-кластер на 50 машин. На серверы код деплоится 2 раза в день, на стейджинг-кластере код обновляется раз в несколько минут, а еще дополнительно есть „хотфиксы“ — небольшие наборы файлов, которые выкладываются вне очереди на все или на выделенную часть серверов, не дожидаясь полной выкладки. Вопрос: считаются ли такие условия хайлоадом и как в них деплоить? Напишите не менее 5 вариантов деплоя». Про задачник по хайлоаду можем только мечтать, но уже сейчас мы знаем, что Юрий Насретдинов (youROCK) точно бы решил эту задачу и получил «пятерку».
На простом решении Юрий не остановился, а дополнительно провел доклад, в котором раскрыл тему понятия «деплой кода», рассказал про классические и альтернативные решения масштабного деплоя кода на PHP, проанализировал их производительность и презентовал самописную систему деплоя MDK.
На простом решении Юрий не остановился, а дополнительно провел доклад, в котором раскрыл тему понятия «деплой кода», рассказал про классические и альтернативные решения масштабного деплоя кода на PHP, проанализировал их производительность и презентовал самописную систему деплоя MDK.


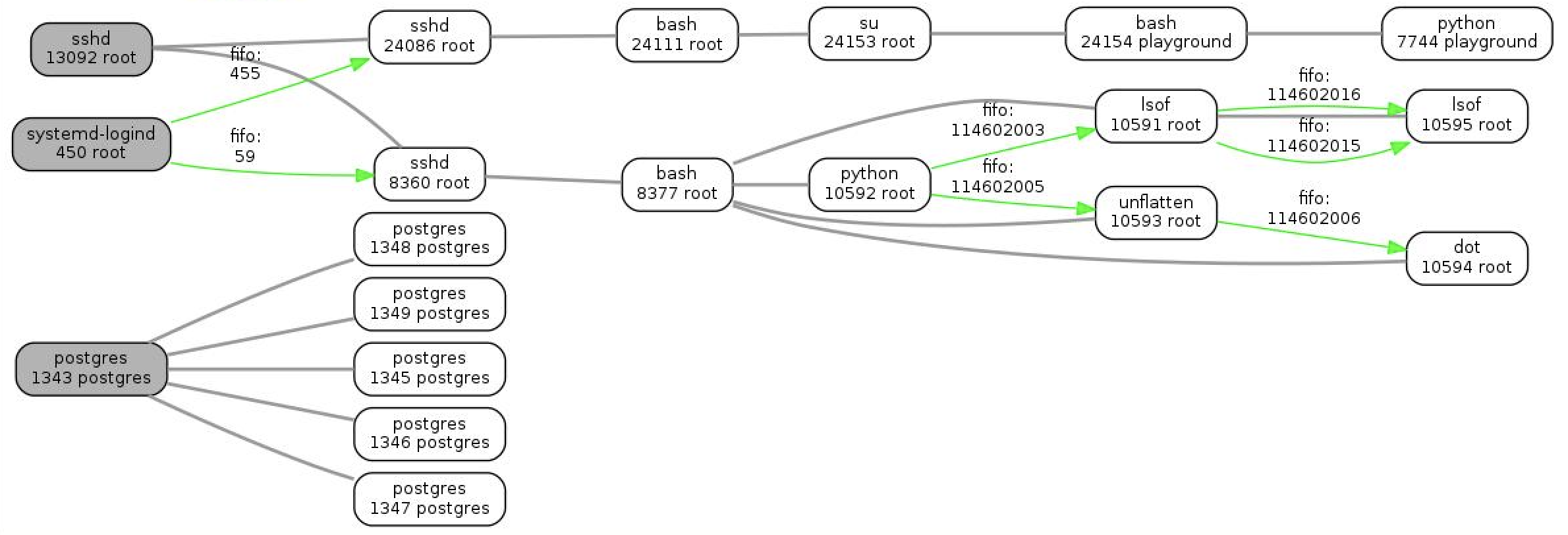





 В процессе эксплуатации систем с SELinux я выделил несколько интересных кейсов, решения которых вряд-ли описаны в Интернете. Сегодня я решил поделиться с вами своими наблюдениями в надежде, что число сторонников SELinux еще немного возрастет :)
В процессе эксплуатации систем с SELinux я выделил несколько интересных кейсов, решения которых вряд-ли описаны в Интернете. Сегодня я решил поделиться с вами своими наблюдениями в надежде, что число сторонников SELinux еще немного возрастет :) [Обновление] Теперь я в каком-то списке спецслужб, потому что написал статью про некий вид «бомбы», так?
[Обновление] Теперь я в каком-то списке спецслужб, потому что написал статью про некий вид «бомбы», так? 