
В этом посте мы начнём реализацию с нуля GPT всего в
60 строках numpy. Во второй части статьи мы загрузим в нашу реализацию опубликованные OpenAI веса обученной модели GPT-2 и сгенерируем текст.
Principal Machine Learning Scientist
60 строках numpy. Во второй части статьи мы загрузим в нашу реализацию опубликованные OpenAI веса обученной модели GPT-2 и сгенерируем текст.
В какой-то момент времени я превратился в педанта брюзгу. В фильмах малейшие нестыковки и провалы в логике портят мне весь просмотр. В чатах меня бесит it's вместо its. А в статьях про программирование... Всё плохо. За меня всё уже сказал @AlexanderAstafiev, я лишь процитирую:
Простите, я не могу так больше. Я слишком хорошо знаю Python, чтобы молчать при виде такого кода.
Я устал. Я не могу это читать. Простите за токсичную критику, накипело.
Самое забавное, что, по моим ощущениям, везде я вижу одни и те же классы проблем. Я даже запилил сервис, где можно закинуть код и получить код ревью, и, собрав немного статистики, понял, что 50 типов ошибок достаточно, чтобы покрыть большую часть проблем в чужом коде. Но выборка у меня была небольшая, и я подумал: а что, если проверить много кода?

Это первая статья из планируемого цикла статей в рамках открытого курса по квантовому машинному обучению. В этой статье мы попытаемся ответить на самые частые вопросы, которые можно встретить в комментариях к статьям к хабе "Квантовые технологии". А именно, мы поговорим о том, что это за компьютеры вообще, какие задачи они могут решать и для чего все так хотят их создать. Дальше мы постараемся оценить тот размер квантовых компьютеров, который необходим для того, чтобы они стали практически полезными и сравним его с теми размерами, которые имеют самые топовые квантовые компьютеры сегодня. В конце немного обсудим тему квантового превосходства, а именно, что это такое ну и немного поговорим о том, сколько стоит сегодня запустить что-то на настоящем квантовом компьютере в облаке.

Сейчас в сфере ML постоянно слышно про невероятные "успехи" трансформеров в разных областях. Но появляется все больше статей о том, что многие из этих успехов мягко говоря надуманы (из недавнего помню статью про пре-тренировку больших CNN в компьютерном зрении, огромную MLP сетку, статью про деконструкцию достижений в сфере трансформеров).
Если очень коротко просуммировать эти статьи — примерно все более менее эффективные нерекуррентные архитектуры на схожих вычислительных бюджетах, сценариях и данных будут показывать примерно похожие результаты.
Тем не менее у self-attention модуля есть ряд плюсов: (i) относительная простота при правильной реализации (ii) простота квантизации (iii) относительная эффективность на коротких (до нескольких сотен элементов) последовательностях и (iv) относительная популярность (но большая часть имплементаций имеет код раздутый раз в 5).
Также есть определенный пласт статей про улучшение именно асимптотических свойств self-attention модуля (например Linformer и его аналоги). Но несмотря на это, если например открыть список пре-тренированных языковых моделей на основе self-attention модулей, то окажется, что "эффективных" моделей там буквально пара штук и они были сделаны довольно давно. Да и последовательности длиннее 500 символов нужны не очень часто (если вы не Google).
Попробуем ответить на вопрос — а как существенно снизить размер и ускорить self-attention модуль и при этом еще удовлетворить ряду production-ready требований:



BERT — это нейронная сеть от Google, показавшая с большим отрывом state-of-the-art результаты на целом ряде задач. С помощью BERT можно создавать программы с ИИ для обработки естественного языка: отвечать на вопросы, заданные в произвольной форме, создавать чат-ботов, автоматические переводчики, анализировать текст и так далее.
Google выложила предобученные модели BERT, но как это обычно и бывает в Machine Learning, они страдают от недостатка документации. Поэтому в этом туториале мы научимся запускать нейронную сеть BERT на локальном компьютере, а также на бесплатном серверном GPU на Google Colab.



Не успели отшуметь новости о нейросети BERT от Google, показавшей state-of-the-art результаты на целом ряде разговорных (NLP) задач в машинном обучении, как OpenAI выкатили новую разработку: GPT-2. Это нейронная сеть с рекордным на данный момент числом параметров (1.5 млрд, против обычно используемых в таких случаях 100-300 млн) оказалась способна генерировать целые страницы связного текста.
Генерировать настолько хорошо, что в OpenAI отказались выкладывать полную версию, опасаясь что эту нейросеть будут использовать для создания фейковых новостей, комментариев и отзывов, неотличимых от настоящих.
Тем не менее, в OpenAI выложили в общий доступ уменьшенную версию нейросети GPT-2, со 117 млн параметров. Именно ее мы запустим через сервис Google Colab и поэкспериментруем с ней.
Можете пояснить что вам не нравится в современной записи (математических положений и) формул и как ее можно улучшить?Я постарался ответить в одном комментарии, но размер текстового поля не позволил закончить выкладки. Данная статья —
 Итак, на мой взгляд, основные претензии не столько к записи формул, сколько к подаче материала. Причем, к подаче материала на практически всех уровнях образования, начиная со школы, и заканчивая передовой наукой. Начало текущей ситуации положил Евклид, заявивший про отсутствие царской дороги в математике. Царскую дорогу не проложили до сих пор. Евклид обходился, и мы сможем.
Итак, на мой взгляд, основные претензии не столько к записи формул, сколько к подаче материала. Причем, к подаче материала на практически всех уровнях образования, начиная со школы, и заканчивая передовой наукой. Начало текущей ситуации положил Евклид, заявивший про отсутствие царской дороги в математике. Царскую дорогу не проложили до сих пор. Евклид обходился, и мы сможем.
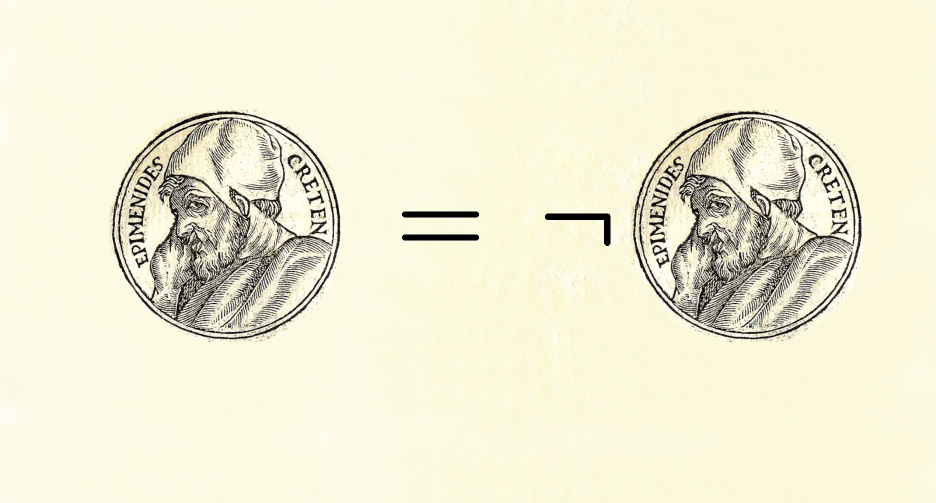
Теореме Гёделя о неполноте, одной из самых известных теорем математической логики, повезло и не повезло одновременно. В этом она похожа на специальную теорию относительности Эйнштейна. С одной стороны, почти все о них что-то слышали. С другой — в народной интерпретации теория Эйнштейна, как известно, «говорит, что всё в мире относительно». А теорема Гёделя о неполноте (далее просто ТГН), в примерно столь же вольной фолк-формулировке, «доказывает, что есть вещи, непостижимые для человеческого разума». И вот одни пытаются приспособить её в качестве аргумента против материализма, а другие, напротив, доказывают с её помощью, что бога нет. Забавно не только то, что обе стороны не могут оказаться правыми одновременно, но и то, что ни те, ни другие не удосуживаются разобраться, что же, собственно, эта теорема утверждает.
Итак, что же? Ниже я попытаюсь «на пальцах» рассказать об этом. Изложение моё будет, разумеется нестрогим и интуитивным, но я попрошу математиков не судить меня строго. Возможно, что для нематематиков (к которым, вообще-то, отношусь и я), в рассказанном ниже будет что-то новое и полезное.
Математическая логика — наука действительно довольно сложная, а главное — не очень привычная. Она требует аккуратных и строгих манёвров, при которых важно не перепутать реально доказанное с тем, что «и так понятно». Тем не менее, я надеюсь, что для понимания следующего ниже «наброска доказательства ТГН» читателю понадобится только знание школьной математики/информатики, навыки логического мышления и 15-20 минут времени.
Задача о многоруком бандите – одна из самых основных задач в науке о решениях. А именно, это задача об оптимальном распределении ресурсов в уcловиях неопределенности. Само название «многорукий бандит» пошло от старых игровых автоматов, которыми управляли при помощи ручек. Эти автоматы получили прозвище «бандиты», потому что после общения с ними люди обычно чувствовали себя ограбленными. А теперь представьте, что таких машин несколько и шанс выиграть у разных машин разный. Раз уж мы взялись играть с этими машинами, мы хотим определить, у какой этот шанс выше и использовать (exploit) эту машину чаще, чем другие.
Проблема в следующем: как нам эффективнее всего понять, какая машина подходит лучше всего, и при этом перепробовать много возможностей в реальном времени? Это не какая-то теоретическая проблема, это проблема, с которой бизнес сталкивается все время. Например, у компании есть несколько вариантов сообщений, которые надо показывать пользователям (в число сообщений, например, входят и реклама, сайты, изображения) так, чтобы выбранные сообщения максимизировали некое бизнес-задание (конверсию, кликабельность и пр.)



Решение поставленной перед разработчиком задачи бывает найти нелегко. Но как только оно получено, автору сразу хочется поделиться им со всем миром, ведь это так здорово — «отгружать» код. Неиспользуемая программа — это не что иное, как цифровой мусор. Чтобы не тратить время на никому не нужный софт, современные разработчики поставляют функциональность небольшими порциями, разбивая процесс на короткие итерации.
Такой способ создания программного обеспечения используется в процессах Непрерывной интеграции (Continuous Integration) и Непрерывного развертывания (Continuous Deployment), или CI/CD-цепочке. В этой статье мы пройдем по всем шагам настройки такой цепочки, используя для ее построения бесплатные облачные сервисы.


PyTorch — современная библиотека глубокого обучения, развивающаяся под крылом Facebook. Она не похожа на другие популярные библиотеки, такие как Caffe, Theano и TensorFlow. Она позволяет исследователям воплощать в жизнь свои самые смелые фантазии, а инженерам с лёгкостью эти фантазии имплементировать.
Данная статья представляет собой лаконичное введение в PyTorch и предназначена для быстрого ознакомления с библиотекой и формирования понимания её основных особенностей и её местоположения среди остальных библиотек глубокого обучения.
 NLP. Основы. Техники. Саморазвитие. Часть 2: NER
NLP. Основы. Техники. Саморазвитие. Часть 2: NER