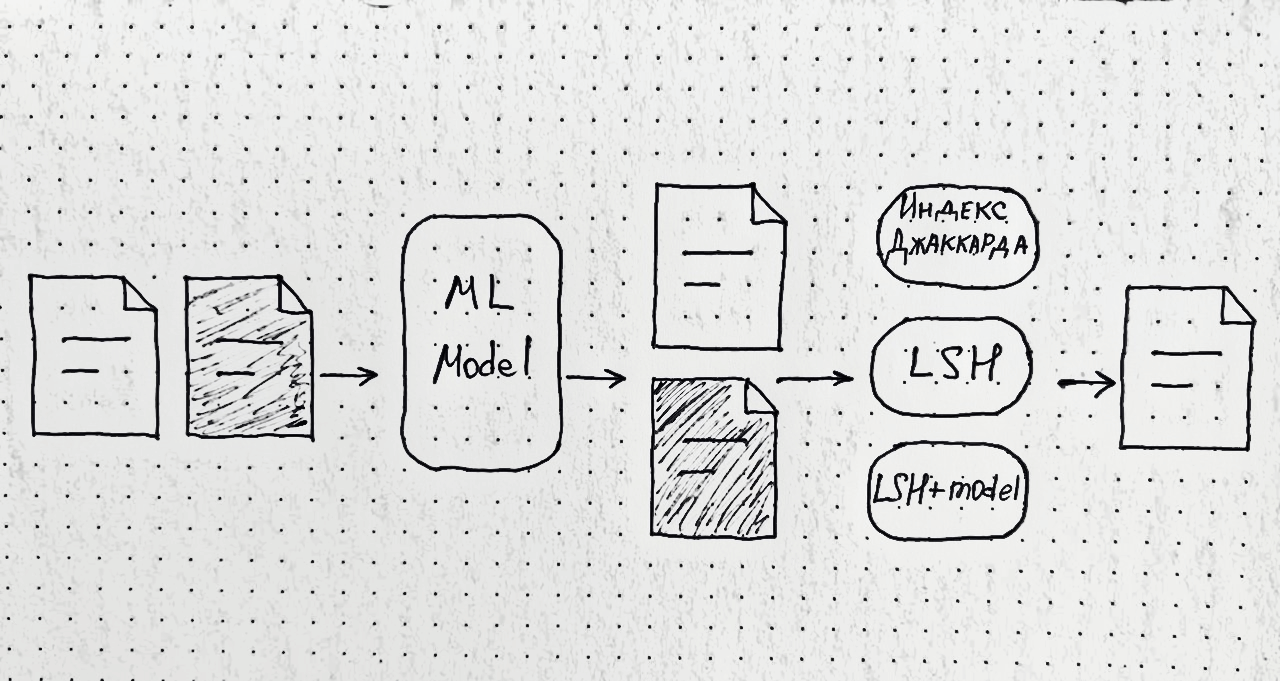
Нам надо искать неполные дубликаты.
При анализе данных могут возникнуть проблемы, если в DataFrame присутствуют дубликаты строк.
Самый простой способ выявить и удалить повторяющиеся строки — это дропнуть их с помощью Pandas, используя метод drop_duplicates(). Но как найти неполные дубликаты, не размечая при этом всех текстовых пар и избегая ложноположительных ошибок?
Нам нужен был такой алгоритм ML, который хорошо масштабируется и работает с пограничными случаями, например, когда разница в парах текстов — только в одной цифре.
Я занимаюсь задачами обработки естественного языка в Газпромбанке. Вместе с DVAMM в этом посте расскажем, какие методы дедупликации мы используем и с какими проблемами столкнулись на практике при детекции неполных дубликатов.




 Все мы знаем, что большинство гаджетов дешевле купить в США, чем у нас на родине, и особенно это относится к различным новинкам, цены на которые у нас просто взлетают к небесам! Так же всем известно, что самые «вкусные» предложения на eBay и в интернет магазинах США обычно имеют доставку US only и соответственно не доступны для нас. В этой статье я попытаюсь рассказать про еще один способ исправить это недоразумение. Конечно все более-менее опытные интернет-покупатели знают о посредниках, которые предоставляют услугу mail forwarding — тоесть пересылку посылок. Происходит это так — вы заказываете доставку товара на адрес в США, который вам выдал посредник, он получает посылку и пересылает ее вам, беря за это небольшую комиссию. Известные посредники это Shipito, Ebaytoday, Бандеролька и т.д. их достаточно много и все они предлагают набор услуг — пересылка, объединение нескольких посылок в одну, наоборот — разделение крупной посылки на несколько мелких и тд. Берут обычно фиксированную плату за каждую посылку + оплату за дополнительные услуги. Стоимость самой пересылки обычно рассчитывается по тарифам USPS и этой же службой отправляют посылку вам. Я же хочу рассказать про еще одну компанию —
Все мы знаем, что большинство гаджетов дешевле купить в США, чем у нас на родине, и особенно это относится к различным новинкам, цены на которые у нас просто взлетают к небесам! Так же всем известно, что самые «вкусные» предложения на eBay и в интернет магазинах США обычно имеют доставку US only и соответственно не доступны для нас. В этой статье я попытаюсь рассказать про еще один способ исправить это недоразумение. Конечно все более-менее опытные интернет-покупатели знают о посредниках, которые предоставляют услугу mail forwarding — тоесть пересылку посылок. Происходит это так — вы заказываете доставку товара на адрес в США, который вам выдал посредник, он получает посылку и пересылает ее вам, беря за это небольшую комиссию. Известные посредники это Shipito, Ebaytoday, Бандеролька и т.д. их достаточно много и все они предлагают набор услуг — пересылка, объединение нескольких посылок в одну, наоборот — разделение крупной посылки на несколько мелких и тд. Берут обычно фиксированную плату за каждую посылку + оплату за дополнительные услуги. Стоимость самой пересылки обычно рассчитывается по тарифам USPS и этой же службой отправляют посылку вам. Я же хочу рассказать про еще одну компанию —