Comments 100
Очень flask'о подобно как-то :)
Да и я не понимаю, зачем использовать джангу для микро преоктов? Возьмите flask и т.п.
Да и я не понимаю, зачем использовать джангу для микро преоктов? Возьмите flask и т.п.
Да это же Flask! :)
Вообще, если надо быстро/микро — берём Flask. Не ленимся, тратим пару часов на чтение SQLAlchemy или MongoAlchemy, если нужны формы — WTForms (ещё пол-часа времени на доки). Jinja2 будет как дом родной для тех, кто на ты с шаблонизатором Django, (я вот лично полюбил макросы, вкусно). Да и быстрее всё в разы. Мало того, во Flask есть те же class-based views, хоть и в упрощённом варианте, есть полезный и быстро растущий набор расширений… Короче стрельба из пушки по воробьям. Разве что ради Django ORM, но, опять же, есть варианты.
Вообще, если надо быстро/микро — берём Flask. Не ленимся, тратим пару часов на чтение SQLAlchemy или MongoAlchemy, если нужны формы — WTForms (ещё пол-часа времени на доки). Jinja2 будет как дом родной для тех, кто на ты с шаблонизатором Django, (я вот лично полюбил макросы, вкусно). Да и быстрее всё в разы. Мало того, во Flask есть те же class-based views, хоть и в упрощённом варианте, есть полезный и быстро растущий набор расширений… Короче стрельба из пушки по воробьям. Разве что ради Django ORM, но, опять же, есть варианты.
Тут все из коробки )
Плюсом — миддлваре, кеши и прочие вкусности.
Плюсом — миддлваре, кеши и прочие вкусности.
Но не спорю — кому то удобнее Flask.
Всё ж от задачи зависит. Странно для сайтов-визиток задействовать Django и странно писать большие сайты-приложения на Flask.
Ну вот у меня было пару сайтов визиток на джанго с одним единственным app.
Теперь будут на djmicro.
Теперь будут на djmicro.
> странно писать большие сайты-приложения на Flask
почему?
как раз-таки для большей гибкости и максимальной производильности лучше вместо джанговского ORM использовать sqlalchemy / mongo и jinja2
почему?
как раз-таки для большей гибкости и максимальной производильности лучше вместо джанговского ORM использовать sqlalchemy / mongo и jinja2
Давайте холивар разводить не будем. Решения что в плане ORM-а и в плане шаблонов практически идентичны. Что по функционалу, что по скорости.
А то из вашего комментария следует неверный вывод о том что джанговский орм и шаблонизатор медленный и ужасно монолитный.
Тут 100% вопрос привычки.
А то из вашего комментария следует неверный вывод о том что джанговский орм и шаблонизатор медленный и ужасно монолитный.
Тут 100% вопрос привычки.
просто не понимаю почему для Flask странно писать большие сайты? в чем причина?
p.s.
orm и шаблоны как раз-таки отличаются еще как ) но не будем об этом.
p.s.
orm и шаблоны как раз-таки отличаются еще как ) но не будем об этом.
У меня за всё время работы с Django ORM появилась только одна претензия — это невозможность параметризировать аннотацию. А вот Jinja2 даже визуально быстрее отрабатывает. Хотя нет темплейт-тегов (но можно вырулить другими средствами).
Flask сложно поддерживать структурно при разрастании проекта. Вот сейчас я и провожу такой эксперимент, пишу сайт на Flask+MongoAlchemy+всякое. Как побочный продукт родился Flask Kit, с которым всё несколько удобнее, если сайт — это не один единственный application. Я его запилил на GitHub, но не особо афиширую, так как не могу выкроить время на написание полноценной документации.
UFO just landed and posted this here
> Вообще, если надо быстро/микро — берём Flask. Не ленимся, тратим пару часов на чтение
:-)
:-)
Ну, если так говорить, то проще взять джангу ;)
django хорош своими батарейками, и тут уж или использовать все,
или брать Flask+sqlalchemy/mongo+jinja2+wtforms.
не вижу смысла в djmicro
или брать Flask+sqlalchemy/mongo+jinja2+wtforms.
не вижу смысла в djmicro
А мне это напомнило новый и очень удобный микрофреймворк bottlepy.
А мне понравился djmicro, Уже придумал, где его использовать.
UFO just landed and posted this here
Все книги из разряда «Напишите свой первый блог в 30 строк кода»
Но читать djangobook конечно в первую очередь.
А так — рекомендую вписаться к более опытным товарищам в проект. Увидишь кучу хорошего кода и правильных архитектурных решений.
Но читать djangobook конечно в первую очередь.
А так — рекомендую вписаться к более опытным товарищам в проект. Увидишь кучу хорошего кода и правильных архитектурных решений.
UFO just landed and posted this here
UFO just landed and posted this here
А еще можно lalala.html через nginx отдавать :-)
Вьюха, вроде бы, нужна, чтобы какие-то данные там достать/обработать и передать в шаблон…
Вьюха, вроде бы, нужна, чтобы какие-то данные там достать/обработать и передать в шаблон…
Поскольку речь зашла про Django vs Flask, то поделюсь, почему я отказался от Джанги. Да-да, именно так )
Когда я разрабатываю миниприложение, то разворачивать Джангу мне кажется делом долгим и утомительным. К тому же, архитектура Джанги этому не способствует — у нас есть проект, в котором должно быть приложение. Зачем, когда некоторые приложения можно целиком уместить в один файл, как во Фласке?
В других приложениях мне не подошла Джанговоская авторизация и модель юзера. У нас все было завязано на номер сотового телефона — его приходилось хранить в профиле, что было очень не удобно.
Разбираясь со Фласком, я познакомился с расширениями для админки, авторизации. Например, авторизация во Фласке позволяет самому задавать класс пользователя. Получается, что практически все возможности Джанги покрыты, а система гораздо гибче.
Когда я разрабатываю миниприложение, то разворачивать Джангу мне кажется делом долгим и утомительным. К тому же, архитектура Джанги этому не способствует — у нас есть проект, в котором должно быть приложение. Зачем, когда некоторые приложения можно целиком уместить в один файл, как во Фласке?
В других приложениях мне не подошла Джанговоская авторизация и модель юзера. У нас все было завязано на номер сотового телефона — его приходилось хранить в профиле, что было очень не удобно.
Разбираясь со Фласком, я познакомился с расширениями для админки, авторизации. Например, авторизация во Фласке позволяет самому задавать класс пользователя. Получается, что практически все возможности Джанги покрыты, а система гораздо гибче.
можно плз подробнее про расширения для админки? что-то мы смотрели (давно правда) несколько и на тот момент мало что устроило, вдруг что допилили уже )
Там все очень просто, до уровня Джанги не дотягивает, конечно, но Create, Edit и Delete работают. Что еще надо?
Указываете, какие модели отслеживать в админке. Можно указать свои формы, если генерируемые по-умолчанию не устраивают. Создаете админский блюпринт и подключаете к приложению.
Чего не хватает — так это поиска по указанным полям.
Указываете, какие модели отслеживать в админке. Можно указать свои формы, если генерируемые по-умолчанию не устраивают. Создаете админский блюпринт и подключаете к приложению.
Чего не хватает — так это поиска по указанным полям.
Допишу, что поддерживаются связанные поля, т.е. ссылки на другие модели.
Скрин админки
Скрин админки
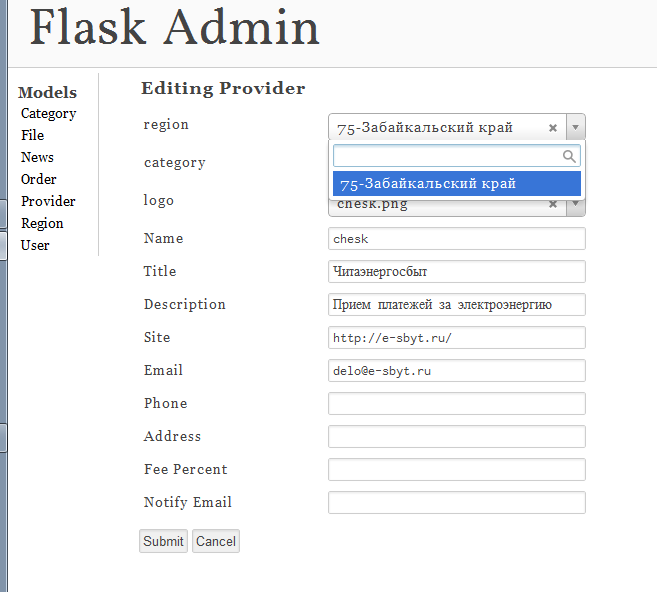{kind=link}
Надо же, как странно, а мы наоборот, благодаря Джанге сэкономили кучу времени…
90% всех претензий Джанги (а из перечисленных Вами наверное 99%) — это проблема не Джанги, а уровня разработчиков.
Типичные обвинения типа «ОРМ» и «Шаблонизатор» звучат со стороны тех, кто ни разу не открывал исходников Джанги. И почему-то умалчивается тот факт, что 90% синтаксиса Jinja — это синтаксис Django. И почему?
При этом обвинения в сторону производительности шаблонизатора звучат с уст тех, кто ни разу не разрабатывал проекта с посещаемостью более 1000 уник. в сутки… Потому что иначе критерии мышления были бы другими…
Всего 5 строчек кода нужно для того, чтобы в разы поднять производительность шаблонизатора Джанги.
ОРМ Джанги — обычно критикуется зря. Есть костность QuerySet (а не ORM), но эта проблема решаема. Есть множество способов решить этот вопрос. И даже без raw и extra… SQL в строчном виде. А высокоуровневыми средствами. И не обязательно даже SQLAlchemy.
Лично я одинаково отношусь и к Flask, и к Django, и к Svarga (жаль что забросили), и к wep.py (не путать с wep2py), и к Pyramid, и к Plone, и к CherryPy, и к bottle, и к TurboGear…
Но когда проект большой, и «один в поле не воин», тогда Джанго — хороший инструмент. Один только djangopackages.com/ чего стоит… Есть причины, по которым такого «окружения» нет у других фреймверков. Именно причины, а не недостатки. Там где начинается много гибкости, — там обычно заканчивается много унифицированности.
> В других приложениях мне не подошла Джанговоская авторизация и модель юзера. У нас все было завязано на номер сотового телефона — его приходилось хранить в профиле, что было очень не удобно.
— есть масса способов не хранить телефон в профайле, а хранить его в юзере…
> не подошла Джанговоская авторизация
— Авторизация, или аутентификация? Скорее всего аутентификация. Сложно представить ситуацию, когда система аутентификации Джанги может не подойти… по крайней мере, судя по этому github.com/omab/django-social-auth А чтобы интерфейс авторизации не подошел, — еще сложнее верится, опять же, судя по этому djangopackages.com/grids/g/perms/
> Например, авторизация во Фласке позволяет самому задавать класс пользователя.
— setattr(model, 'ClassName', NewUser) тоже позволяет… Но в Вашем случае хватило бы Field.contribute_to_class()
> Получается, что практически все возможности Джанги покрыты, а система гораздо гибче.
— гм… Ну, Flask, вообще-то, хорошая система… мне нравится, по крайней мере… Просто сравнение не совсем корректное…
90% всех претензий Джанги (а из перечисленных Вами наверное 99%) — это проблема не Джанги, а уровня разработчиков.
Типичные обвинения типа «ОРМ» и «Шаблонизатор» звучат со стороны тех, кто ни разу не открывал исходников Джанги. И почему-то умалчивается тот факт, что 90% синтаксиса Jinja — это синтаксис Django. И почему?
При этом обвинения в сторону производительности шаблонизатора звучат с уст тех, кто ни разу не разрабатывал проекта с посещаемостью более 1000 уник. в сутки… Потому что иначе критерии мышления были бы другими…
Всего 5 строчек кода нужно для того, чтобы в разы поднять производительность шаблонизатора Джанги.
ОРМ Джанги — обычно критикуется зря. Есть костность QuerySet (а не ORM), но эта проблема решаема. Есть множество способов решить этот вопрос. И даже без raw и extra… SQL в строчном виде. А высокоуровневыми средствами. И не обязательно даже SQLAlchemy.
Лично я одинаково отношусь и к Flask, и к Django, и к Svarga (жаль что забросили), и к wep.py (не путать с wep2py), и к Pyramid, и к Plone, и к CherryPy, и к bottle, и к TurboGear…
Но когда проект большой, и «один в поле не воин», тогда Джанго — хороший инструмент. Один только djangopackages.com/ чего стоит… Есть причины, по которым такого «окружения» нет у других фреймверков. Именно причины, а не недостатки. Там где начинается много гибкости, — там обычно заканчивается много унифицированности.
> В других приложениях мне не подошла Джанговоская авторизация и модель юзера. У нас все было завязано на номер сотового телефона — его приходилось хранить в профиле, что было очень не удобно.
— есть масса способов не хранить телефон в профайле, а хранить его в юзере…
> не подошла Джанговоская авторизация
— Авторизация, или аутентификация? Скорее всего аутентификация. Сложно представить ситуацию, когда система аутентификации Джанги может не подойти… по крайней мере, судя по этому github.com/omab/django-social-auth А чтобы интерфейс авторизации не подошел, — еще сложнее верится, опять же, судя по этому djangopackages.com/grids/g/perms/
> Например, авторизация во Фласке позволяет самому задавать класс пользователя.
— setattr(model, 'ClassName', NewUser) тоже позволяет… Но в Вашем случае хватило бы Field.contribute_to_class()
> Получается, что практически все возможности Джанги покрыты, а система гораздо гибче.
— гм… Ну, Flask, вообще-то, хорошая система… мне нравится, по крайней мере… Просто сравнение не совсем корректное…
> При этом обвинения в сторону производительности шаблонизатора звучат с уст тех, кто ни разу не разрабатывал проекта с посещаемостью более 1000 уник. в сутки…
хех :) я разрабатывал, и честно говоря шаблоны джанги мне не очень нравятся, и выше я уже писал про ту же отсылку писем например, на jinja2 генериться млн. писем будет гораздо быстрее
> Есть множество способов решить этот вопрос. И даже без raw и extra… SQL в строчном виде. А высокоуровневыми средствами. И не обязательно даже SQLAlchemy
можно плз подробнее?
> есть масса способов не хранить телефон в профайле, а хранить его в юзере…
тоже поясните плз как вы делали?
хех :) я разрабатывал, и честно говоря шаблоны джанги мне не очень нравятся, и выше я уже писал про ту же отсылку писем например, на jinja2 генериться млн. писем будет гораздо быстрее
> Есть множество способов решить этот вопрос. И даже без raw и extra… SQL в строчном виде. А высокоуровневыми средствами. И не обязательно даже SQLAlchemy
можно плз подробнее?
> есть масса способов не хранить телефон в профайле, а хранить его в юзере…
тоже поясните плз как вы делали?
> не хранить телефон в профайле, а хранить его в юзере… тоже поясните плз как вы делали?
— уже сказал, setattr(model, 'ClassName', NewUser) или Field.contribute_to_class() (или Model.add_to_class())
Пример как перебить объект в модуле — bitbucket.org/carljm/django-localeurl/src/48e3391e3197/localeurl/models.py только там функция вместо объекта.
> Есть множество способов решить этот вопрос. И даже без raw и extra… SQL в строчном виде. А высокоуровневыми средствами. И не обязательно даже SQLAlchemy… можно плз подробнее?
1. habrahabr.ru/blogs/python/128052/
2. Объявлять модели через свою фабрику, как сделано bitbucket.org/deepwalker/amalgam
3. Использовать SQLBuilder от SQLObject, StormORM, SQLAlchemy, py-smart-sql-constructor и т.п. для создания SQL, и затем подставлять его в Manager.raw(). Там нужно будет решить несколько нюансов, но они решаемы. И даже связи у результата запроса (инстанции модели) подхватываются.
> а jinja2 генериться млн. писем будет гораздо быстрее
— А Вам нужно каждый раз читать и парсить шаблон? Редко бывает, что пути поиска шаблонов в процессе работы скрипта меняются. Всего 5 строчек кода, — и шаблон только единожды прочтётся и распарсится, а затем будет просто реднериться. Потом можете и замеры делать…
— уже сказал, setattr(model, 'ClassName', NewUser) или Field.contribute_to_class() (или Model.add_to_class())
Пример как перебить объект в модуле — bitbucket.org/carljm/django-localeurl/src/48e3391e3197/localeurl/models.py только там функция вместо объекта.
> Есть множество способов решить этот вопрос. И даже без raw и extra… SQL в строчном виде. А высокоуровневыми средствами. И не обязательно даже SQLAlchemy… можно плз подробнее?
1. habrahabr.ru/blogs/python/128052/
2. Объявлять модели через свою фабрику, как сделано bitbucket.org/deepwalker/amalgam
3. Использовать SQLBuilder от SQLObject, StormORM, SQLAlchemy, py-smart-sql-constructor и т.п. для создания SQL, и затем подставлять его в Manager.raw(). Там нужно будет решить несколько нюансов, но они решаемы. И даже связи у результата запроса (инстанции модели) подхватываются.
> а jinja2 генериться млн. писем будет гораздо быстрее
— А Вам нужно каждый раз читать и парсить шаблон? Редко бывает, что пути поиска шаблонов в процессе работы скрипта меняются. Всего 5 строчек кода, — и шаблон только единожды прочтётся и распарсится, а затем будет просто реднериться. Потом можете и замеры делать…
> setattr(model, 'ClassName', NewUser) или Field.contribute_to_class() (или Model.add_to_class())
в прошлом проекте у нас был Model.add_to_class(),
в итоге этих строчек было очень много, тут же еще и методы надо добавлять таким способом, это смотрится как-то совсем ужасно, это совсем не python-way.
> 1. 2. 3.
как-то все это костыльно, да и паттерны-то отличаются, у алхимии Data mapper.
мне интересно можно ли поймать event между получением данных из базы и созданием model instances чтобы добавить к model instances дополнительное поле которое не объявлено никак, а данные для этого поля приходят из дополнительного генерируемого поля в query.
например нам нужно вывести дерево комментариев одним запросом через WITH RECURSIVE ..., level и прочее для комментариев в базе не хранятся, чтобы дерево не пересчитывалось долго (а когда комментариев очень много, то пересчет долгий), level считается на лету, и нам нужно подсчитанный level добавить в инстанс модели.
> шаблон только единожды прочтётся и распарсится, а затем будет просто реднериться
ну так сам рендер и медленный же.
в прошлом проекте у нас был Model.add_to_class(),
в итоге этих строчек было очень много, тут же еще и методы надо добавлять таким способом, это смотрится как-то совсем ужасно, это совсем не python-way.
> 1. 2. 3.
как-то все это костыльно, да и паттерны-то отличаются, у алхимии Data mapper.
мне интересно можно ли поймать event между получением данных из базы и созданием model instances чтобы добавить к model instances дополнительное поле которое не объявлено никак, а данные для этого поля приходят из дополнительного генерируемого поля в query.
например нам нужно вывести дерево комментариев одним запросом через WITH RECURSIVE ..., level и прочее для комментариев в базе не хранятся, чтобы дерево не пересчитывалось долго (а когда комментариев очень много, то пересчет долгий), level считается на лету, и нам нужно подсчитанный level добавить в инстанс модели.
> шаблон только единожды прочтётся и распарсится, а затем будет просто реднериться
ну так сам рендер и медленный же.
> ну так сам рендер и медленный же.
— цифры?
— цифры?
сейчас я сам тест писать не буду, не до этого.
раньше проверял, была разница.
ну а так есть в сети же тесты тоже
www.askthepony.com/blog/2011/07/django-and-postgresql-improving-the-performance-with-no-effort-and-no-code/
stackoverflow.com/questions/8318999/why-isnt-this-jinja2-template-rendering-faster-than-djangos
раньше проверял, была разница.
ну а так есть в сети же тесты тоже
www.askthepony.com/blog/2011/07/django-and-postgresql-improving-the-performance-with-no-effort-and-no-code/
stackoverflow.com/questions/8318999/why-isnt-this-jinja2-template-rendering-faster-than-djangos
Повторять сейчас не буду расчеты, но мы тестировали — если сишные спидапсы под джинджу поставить, то разница есть. Углубились вместе после того, как ребята провели свои тесты и не ощутили разницы.
В итоге ребята приняли решение взять таки джинджу и потратить время на ее внедрение.
Плюс эти спидапсы даже в GAE запилены, специально под джинджу.
В итоге ребята приняли решение взять таки джинджу и потратить время на ее внедрение.
Плюс эти спидапсы даже в GAE запилены, специально под джинджу.
> мне интересно можно ли поймать event между получением данных из базы и созданием model instances чтобы добавить к model instances дополнительное поле которое не объявлено никак, а данные для этого поля
QuerySet.iterator если на низком уровне.
Или добавить свой метод get_comments_with_level
QuerySet.iterator если на низком уровне.
Или добавить свой метод get_comments_with_level
хм, пока не представляю как это можно сделать в джанге без костылей.
iterator() возвращает просто сырые данные? т.е. инстансы моделей нам самим создавать и заполнять?
> get_comments_with_level
вопрос как заполнять эти дополнительные поля, проходиться отдельным циклом по данным это не айс :)
iterator() возвращает просто сырые данные? т.е. инстансы моделей нам самим создавать и заполнять?
> get_comments_with_level
вопрос как заполнять эти дополнительные поля, проходиться отдельным циклом по данным это не айс :)
хм, пока не представляю как это можно сделать в джанге без костылей.
Каких костылей?
Пишите свой Manager в котором указываете метод get_queryset
iterator() возвращает просто сырые данные? т.е. инстансы моделей нам самим создавать и заполнять?
Он возвращает инстанс модели.
code.djangoproject.com/browser/django/trunk/django/db/models/query.py#L231
вопрос как заполнять эти дополнительные поля, проходиться отдельным циклом по данным это не айс :)
Ничего не понимаю. Вы сейчас говорите о недостатке какого-то конкретного решения, которое сами придумали для джанги и осуждаете?
Почему алгоритм который не будет проходить отдельным циклом будет работать где-то еще а не будет в джанге? Вам не кажется что вы сейчас черезчур субьективно рассуждаете.
Каких костылей?
Пишите свой Manager в котором указываете метод get_queryset
def get_query_set(self):
"""Returns a new QuerySet object. Subclasses can override this method
to easily customize the behavior of the Manager.
"""
return QuerySet(self.model, using=self._db)
iterator() возвращает просто сырые данные? т.е. инстансы моделей нам самим создавать и заполнять?
Он возвращает инстанс модели.
code.djangoproject.com/browser/django/trunk/django/db/models/query.py#L231
вопрос как заполнять эти дополнительные поля, проходиться отдельным циклом по данным это не айс :)
Ничего не понимаю. Вы сейчас говорите о недостатке какого-то конкретного решения, которое сами придумали для джанги и осуждаете?
Почему алгоритм который не будет проходить отдельным циклом будет работать где-то еще а не будет в джанге? Вам не кажется что вы сейчас черезчур субьективно рассуждаете.
ну что поделать, у меня есть конкретная задача, и к сожалению данное решение мне не подходит.
Да ладно, просто признайте что не хуже SQLAlchemy )
если бы был данный event (что возможно когда-нибудь добавят в будущем), то да, а так нет
и это еще несмотря на то что джанга в принципе такой запрос сгенерировать не сможет и придется писать ручками
1. Какой такой?
2. В чем проблема написать SQL?
2. В чем проблема написать SQL?
with recursive, в итоге должно получаться что-то подобное pastebin.com/Aa1z0i9k
для алхимии есть готовый extension
для алхимии есть готовый extension
> как-то все это костыльно, да и паттерны-то отличаются, у алхимии Data mapper.
Почему костыли? Причина? Только в том что используется другой SQLBuilder?
В SQLObject он полностью автономный, не зависит от ORM, легко отделяется от библиотеки, — всего три файла. С точки зрения Архитектуры — никаких костылей (и жаль что вы чистое архитектурное решение назвали костылем, это впрочем, о многом говорит). У Вас просто в проекте 2 SQLBuilder, — один простой, но зато удобный. Второй гибкий, для сложных SQL-запросов.
> да и паттерны-то отличаются, у алхимии Data mapper.
— Дорогой Lestat, не могли бы Вы пояснить, как связаны SQLBuilder и ORM? И какое отношение к SQLBuilder имеет «event между получением данных из базы и созданием model instances»?
Вы либо используете один, и только один ОРМ, независимо от того, чем строите SQL, либо у Вас в проекте два самостоятельных ОРМ, но с общими схемами.
> в итоге этих строчек было очень много
— Можно подробнее? Где именно, на каких таких моделях получилось много строчек? Всего на одной модели User? Какие еще модели?
Не нравится Field.contribute_to_class(), используйте setattr(), чтобы код был чистым. Или вообще, — весь файл перепишите по своему, и укажите где модуль должен его искать docs.python.org/tutorial/modules.html#packages-in-multiple-directories
Абсолютно не вижу проблем в таком языке программирования как Питон, если в нем конечно хоть немного разбираться…
Почему костыли? Причина? Только в том что используется другой SQLBuilder?
В SQLObject он полностью автономный, не зависит от ORM, легко отделяется от библиотеки, — всего три файла. С точки зрения Архитектуры — никаких костылей (и жаль что вы чистое архитектурное решение назвали костылем, это впрочем, о многом говорит). У Вас просто в проекте 2 SQLBuilder, — один простой, но зато удобный. Второй гибкий, для сложных SQL-запросов.
> да и паттерны-то отличаются, у алхимии Data mapper.
— Дорогой Lestat, не могли бы Вы пояснить, как связаны SQLBuilder и ORM? И какое отношение к SQLBuilder имеет «event между получением данных из базы и созданием model instances»?
Вы либо используете один, и только один ОРМ, независимо от того, чем строите SQL, либо у Вас в проекте два самостоятельных ОРМ, но с общими схемами.
> в итоге этих строчек было очень много
— Можно подробнее? Где именно, на каких таких моделях получилось много строчек? Всего на одной модели User? Какие еще модели?
Не нравится Field.contribute_to_class(), используйте setattr(), чтобы код был чистым. Или вообще, — весь файл перепишите по своему, и укажите где модуль должен его искать docs.python.org/tutorial/modules.html#packages-in-multiple-directories
Абсолютно не вижу проблем в таком языке программирования как Питон, если в нем конечно хоть немного разбираться…
> например нам нужно вывести дерево комментариев одним запросом через WITH RECURSIVE ..., level и прочее для комментариев в базе не хранятся, чтобы дерево не пересчитывалось долго (а когда комментариев очень много, то пересчет долгий), level считается на лету, и нам нужно подсчитанный level добавить в инстанс модели.
— Этот вопрос немного из другой области. Тут нужно просто выбрать верный способ хранения дерева. Благо в Джанге вопрос работы с деревьями хорошо решен:
— github.com/django-mptt/django-mptt
— bitbucket.org/tabo/django-treebeard
— bitbucket.org/fivethreeo/django-easytree
Причем, если выбирать NS, — то можно на каждую ветку делать свое дерево. А больших веток не бывает, — т.е. тормоза NS вы не почувствуете. Ну или MP. Кстати в github.com/HonzaKral/django-threadedcomments как раз MP и используется, если не ошибаюсь (в последней версии).
— Этот вопрос немного из другой области. Тут нужно просто выбрать верный способ хранения дерева. Благо в Джанге вопрос работы с деревьями хорошо решен:
— github.com/django-mptt/django-mptt
— bitbucket.org/tabo/django-treebeard
— bitbucket.org/fivethreeo/django-easytree
Причем, если выбирать NS, — то можно на каждую ветку делать свое дерево. А больших веток не бывает, — т.е. тормоза NS вы не почувствуете. Ну или MP. Кстати в github.com/HonzaKral/django-threadedcomments как раз MP и используется, если не ошибаюсь (в последней версии).
> Пример как перебить объект в модуле…
Извините, но меня смущает такой подход. Я хочу, чтобы у меня была «чистая» модель безо всяких шаманств. И расширение flask-login вообще крайне лояльно относится к классу пользователя, оно лишь требует, чтобы у класса было всего 4 метода, которые добавляются mixin-ом. Сразу видно, что разработчик не пытался домыслить за остальных, что им нужно, а просто продумал гибкую архитектуру.
Извините, но меня смущает такой подход. Я хочу, чтобы у меня была «чистая» модель безо всяких шаманств. И расширение flask-login вообще крайне лояльно относится к классу пользователя, оно лишь требует, чтобы у класса было всего 4 метода, которые добавляются mixin-ом. Сразу видно, что разработчик не пытался домыслить за остальных, что им нужно, а просто продумал гибкую архитектуру.
Ну если Вам легче сменить фреймверк, нежели использовать штатные средства языка программирования (даже не фреймверка) — то это Ваше личное дело. Причем тут Джанго?
Правда последние Ваши слова немного не согласуются с первыми:
> «В других приложениях мне не подошла Джанговоская авторизация и модель юзера. У нас все было завязано на номер сотового телефона — его приходилось хранить в профиле, что было очень не удобно.»
Как выяснилось, Джанго Вас ни в чем не ограничивало. И вопрос не в ней, а в способности разбираться с вопросом. Иначе инструментов не напасешься…
Лично я когда использую Flask, — то причина не в том, что Django плохая. Я понимаю, что сегодня модно плюнуть в сторону PHP, Django и т.д., и таким образом лишний раз утвердиться. Я с одинаковым комфортом могу работать как в Django так и во Flask. И выбираю их исходя из того, что лучше подходит под задачу.
Если я делаю, например, социальную сеть, и для Джанги я могу найти готового кода на 8 человеко*месяцев, — то я выбираю Джанго. Даже если и будет несколько костылей (но это отнюдь не то, что вы назвали костылями)
Правда последние Ваши слова немного не согласуются с первыми:
> «В других приложениях мне не подошла Джанговоская авторизация и модель юзера. У нас все было завязано на номер сотового телефона — его приходилось хранить в профиле, что было очень не удобно.»
Как выяснилось, Джанго Вас ни в чем не ограничивало. И вопрос не в ней, а в способности разбираться с вопросом. Иначе инструментов не напасешься…
Лично я когда использую Flask, — то причина не в том, что Django плохая. Я понимаю, что сегодня модно плюнуть в сторону PHP, Django и т.д., и таким образом лишний раз утвердиться. Я с одинаковым комфортом могу работать как в Django так и во Flask. И выбираю их исходя из того, что лучше подходит под задачу.
Если я делаю, например, социальную сеть, и для Джанги я могу найти готового кода на 8 человеко*месяцев, — то я выбираю Джанго. Даже если и будет несколько костылей (но это отнюдь не то, что вы назвали костылями)
Учитывая количество современных языков и фреймворков, можно утверждать, что сегодня выбор фреймворка носит исключительно личностный характер. По сути, разработчик ощупывает разные технологии, прислушиваясь к ощущениям — что лучше ложится на мозги, что легче осмыслить. Для себя я выяснил, что лучше работать с нормально построенной моделью пользователя. В этом смысле меня ограничивает Джанга — ваш вариант скрывает ясность процесса, что противоречит известным принципам в питоне.
Я непонимаю что подразумевается под микропроектами. Если взять туже сайт визитку, то там нужна админка, менюхи, страницы, генерация урлов, разные блоки, аплоэд файлов, формы и т.п. Это довольно быстро решается с помощью батареек. А если все это писать самому в одном файле, то будет потрачено очень много времени. Если речь идет о сайтах-заглушках, там и вовсе питон не нужен, выложил html файлы и все.
То что на микрофреймворке все быстрее в разы, дак это вообще не аргумент. У джанги скорость достаточная как для визиток так и для highload. И что такого «долгого и утомительного» в разворавичании джанги мне тоже непонятно.
То что на микрофреймворке все быстрее в разы, дак это вообще не аргумент. У джанги скорость достаточная как для визиток так и для highload. И что такого «долгого и утомительного» в разворавичании джанги мне тоже непонятно.
Визитка — это не всегда микропроект. То, что вы описали — это явно не «микро». Микропроектом можно назвать приложение, которое имеет всего один обработчик. Например, интерфейс для взаимодействия с платежными системами. Такое приложение принимает запрос и возвращает XML-документ. Всё приложение умещается в один файл на 100-150 строк.
вообще к чему все это, я пытаюсь донести что не единой джангой в питоне можно жить.
джанга хороша для 90% случаев, но это не значит что в остальных 10% надо пытаться подогнать ее под работу.
как где-то говорилось «большинство проблем начинается с того, что пытаются использовать инструмент, не предназначенный для этого».
и если грамотно писать, то любой пришедший джангист в проект написанный на Flask'е легко разберется и очень быстро включится в работу.
джанга хороша для 90% случаев, но это не значит что в остальных 10% надо пытаться подогнать ее под работу.
как где-то говорилось «большинство проблем начинается с того, что пытаются использовать инструмент, не предназначенный для этого».
и если грамотно писать, то любой пришедший джангист в проект написанный на Flask'е легко разберется и очень быстро включится в работу.
Нет, судя по всему все кто пишут про фласк пытаются донести то что этот микрофреймворк не нужен. Иначе бы хватило первого комментария про него.
Опять же фласк и джанго это инструмент. Каждый его использует как хочет. Вот для джанги появилась возможность упростить кое-что благодаря djmicro. Я об этом написал.
В ответ прилетело 100500 комментариев что нужно использовать SQLAlchemy, что Jinja быстрее итд.
Еще раз говорю — у меня все проекты на джанго. У меня она стоит везде. Я знаю все ее плюсы, минусы, баги и прочие вещи, потому что я ее использую уже с времен когда она была 0.х.
Я могу решить на ней абсолютно любые задачи, которые решаемы на Flask/Jinja/SQLAlchemy и прочих.
Зачем мне тратить свое время на незнакомый для меня инструмент?
PS Вариант «изучить что-то новое» не вариант, потому что я в данном контексте сейчас смотрю на Haml и coffescript. Как появится время думаю взглянуть на скалу, objective C и хаскелл.
Опять же фласк и джанго это инструмент. Каждый его использует как хочет. Вот для джанги появилась возможность упростить кое-что благодаря djmicro. Я об этом написал.
В ответ прилетело 100500 комментариев что нужно использовать SQLAlchemy, что Jinja быстрее итд.
Еще раз говорю — у меня все проекты на джанго. У меня она стоит везде. Я знаю все ее плюсы, минусы, баги и прочие вещи, потому что я ее использую уже с времен когда она была 0.х.
Я могу решить на ней абсолютно любые задачи, которые решаемы на Flask/Jinja/SQLAlchemy и прочих.
Зачем мне тратить свое время на незнакомый для меня инструмент?
PS Вариант «изучить что-то новое» не вариант, потому что я в данном контексте сейчас смотрю на Haml и coffescript. Как появится время думаю взглянуть на скалу, objective C и хаскелл.
Но шутки в сторону. Скажите мне замшелые троглодиты из реально нереально серьезной веб разработки, что, экономия на рендере шаблонов это лишнее для проектов с посещаемостью >1000? Более быстрая разработка с более гибким ORM это лишнее? Да вы вообще БД используете, или планируете проект на sqlite запускать в продакшн? Даже обработка URL в Werkzeug быстрее. Можно говорить что где-то это копейки, но когда все копейки собираются во Flask, это уже становится серьезно, мимо проходить уже как-то непрофессионально, и даже как-то стыдно.
Полная версия ответа:
deepwalker.blogspot.com/2012/03/django-web.html
Полная версия ответа:
deepwalker.blogspot.com/2012/03/django-web.html
Михаил, я не хочу с тобой спорить, потому что знаю что ты серьезный специалист, и говоришь всегда то что есть на самом деле.
Но при всем моем уважении, — есть случаи, когда рациональнее выбирать Dojo, а не jQuery, хотя он может где-то уступает в удобстве, и уж тем более — в легковесности.
Так же само есть случаи, когда рациональнее выбирать Джанго (при всем моем отличном отношении к Flask, и не буду скрывать, к Вашей Svarga (зря Вы все-таки похоронили хорошую идею)).
Что касается "… когда все копейки собираются во Flask, это уже становится серьезно...", — то могу сказать, только одно, и, думаю, ты со мной согласишься. В подавляющем большинстве проектов, шаблонизатор и обработчик URL влияют на производительность в наименьшей степени. Как правило, в средне-статистическом проекте такое количество пожирателей ресурсов, что хоть на Ассемблер переписывай эту логику, — сайт быстрее работать не станет. И если уж и говорить про вопросы быстродействия и оптимизации, — то заходить надо с другой стороны.
Если уж заниматься производительностью, — то ей нужно заниматься серьезно. Это как раз та область, где уровень квалификации разработчика играет более весомую роль, нежели скоростные показатели фреймверка. А когда не совсем квалифицированные разработчики сводят свою борьбу за производительность к тому, чтобы покритиковать Джангу, то это просто удовлетворение самолюбия, и ничего общего к Джанге не имеет…
Но при всем моем уважении, — есть случаи, когда рациональнее выбирать Dojo, а не jQuery, хотя он может где-то уступает в удобстве, и уж тем более — в легковесности.
Так же само есть случаи, когда рациональнее выбирать Джанго (при всем моем отличном отношении к Flask, и не буду скрывать, к Вашей Svarga (зря Вы все-таки похоронили хорошую идею)).
Что касается "… когда все копейки собираются во Flask, это уже становится серьезно...", — то могу сказать, только одно, и, думаю, ты со мной согласишься. В подавляющем большинстве проектов, шаблонизатор и обработчик URL влияют на производительность в наименьшей степени. Как правило, в средне-статистическом проекте такое количество пожирателей ресурсов, что хоть на Ассемблер переписывай эту логику, — сайт быстрее работать не станет. И если уж и говорить про вопросы быстродействия и оптимизации, — то заходить надо с другой стороны.
Если уж заниматься производительностью, — то ей нужно заниматься серьезно. Это как раз та область, где уровень квалификации разработчика играет более весомую роль, нежели скоростные показатели фреймверка. А когда не совсем квалифицированные разработчики сводят свою борьбу за производительность к тому, чтобы покритиковать Джангу, то это просто удовлетворение самолюбия, и ничего общего к Джанге не имеет…
Sqlalchemy и разработка на django orm под sqlite — использование возможностей хорошей БД типа postgres это спички? Django ORM даже куцый sqlite не покрывает.
Невозможность использовать gevent в django спички?
Классическое приложение это выборка данных из базы и форматирование их в страницу — все эти вещи во flask будут сильно быстрее и проще в использовании. Это экономит время на разработку, это экономит затраты на функционирование сервиса в облаке — use less to do more.
Но все это фигня, в сравнении с тем, насколько у фласка более умное API, насколько обезжиренный contrib, насколько каждый компонент гибче, и насколько просто любой из них выкинуть и вкрутить другой.
Это источник другого взгляда на разработку. Но в общем что-то опять пост получается, закруглим.
Невозможность использовать gevent в django спички?
Классическое приложение это выборка данных из базы и форматирование их в страницу — все эти вещи во flask будут сильно быстрее и проще в использовании. Это экономит время на разработку, это экономит затраты на функционирование сервиса в облаке — use less to do more.
Но все это фигня, в сравнении с тем, насколько у фласка более умное API, насколько обезжиренный contrib, насколько каждый компонент гибче, и насколько просто любой из них выкинуть и вкрутить другой.
Это источник другого взгляда на разработку. Но в общем что-то опять пост получается, закруглим.
Экономия на рендере шаблонов, урлах и т д — ну смешно же. Поднимем еще пару нод на s3, проблем-то.
Куда важнее, что пока в Виллариба пишут очередной компрессор css-файлов/цмс/crud для древовидных структур/авторизацию, в Виллабаджо уже сдали проект.
Да, общее качество кода в джанго-проектах в pypi оставляет желать лучшего (не лютый ад типа phpclasses.org конечно, но все же). Да, dependency hell. Зато как приятно, когда 70% проекта находится в requirements.txt
P.S: сейчас перетягиваем кусок проекта на торнадо. джанга не вытягивает, ага, оверхед большой. но большую часть кода это вообще никак не затронет. работает — и славненько
Куда важнее, что пока в Виллариба пишут очередной компрессор css-файлов/цмс/crud для древовидных структур/авторизацию, в Виллабаджо уже сдали проект.
Да, общее качество кода в джанго-проектах в pypi оставляет желать лучшего (не лютый ад типа phpclasses.org конечно, но все же). Да, dependency hell. Зато как приятно, когда 70% проекта находится в requirements.txt
P.S: сейчас перетягиваем кусок проекта на торнадо. джанга не вытягивает, ага, оверхед большой. но большую часть кода это вообще никак не затронет. работает — и славненько
Экономия это приятный бонус, разработка на flask проще. Компрессор есть, какая-то админка есть. Есть альтернативный ORM pewee некий — там с админкой и тп, комплектом, но сам я не смотрел, ибо не понял в чем преимущество перед sqla.
В общем Flask он не пустынен, requirements там вполне себе обширный выходит. Так что Виллабаджо замучается пыль глотать.
В общем Flask он не пустынен, requirements там вполне себе обширный выходит. Так что Виллабаджо замучается пыль глотать.
у pewee преимуществ перед sqla как раз таки-нету, если сравнивать объективно и по всем показателям
и кстати, при всей возне никто не рассматривает конкурентом pyramid — интересно — почему бы это? В нем конечно не jinja из коробки, а скорее Mako — синтаксис которой оставляет желать лучшего, но это всё опционально и заменяемо :)
И кстати — приложение в виде одного файла реализуется так же просто как и во Flask
И кстати — приложение в виде одного файла реализуется так же просто как и во Flask
Ну начинается, эта мне оппозиция, вечно растекаются по кандидатам. Суть же в протестном голосовании, чтобы джанго не ушла на второй проект. А Flask выбран как единый кандидат :)
а я вот всерьез рассматриваю пирамиду как опцию с возможностью автогенерации ресурсных урлов, если сейчас еще окажется, что там отдача контента следует RESTful нотации, то плакал ваш Flask далеко позади (и да, в pyramid sqla уже есть). У меня сейчас на той же задаче крутится tornado, скорость и удобство разработки под который заставляет — хм, много думать об альтернативных вариантах.
Черт, придется таки поставить пирамиду и попинать. Умеете убеждать, товарищ.
а я хотел поглядеть торнадо )
а в чем проблемы с ним?
а в чем проблемы с ним?
Проблем-то как раз нет, но местами возникают вопросы — а нужна ли асинхронность при последовательном ожидании результата из data-storage. Когда следующая операция зависит от предыдущей и приходится ожидать.
Лапши колбэков, увы, тоже нету, @gen.engine + gen.Task спасает всё же.
Сейчас уже есть пара мыслей как это «правильно» реализовать с учетом websocket и некоторого времени, прошедшего со старта разработки.
Лапши колбэков, увы, тоже нету, @gen.engine + gen.Task спасает всё же.
Сейчас уже есть пара мыслей как это «правильно» реализовать с учетом websocket и некоторого времени, прошедшего со старта разработки.
Просматривал другой топик, и подвернулась удачная фраза, которая как нельзя лучше описывает процесс выбора фреймверка:
> В общем «Если бы губы Никанора Ивановича да приставить к носу Ивана Кузьмича, да взять сколь-нибудь развязанное, какая у Балтазара Балтазаровича, да, пожалуй, прибавить к этому еще дородности Ивана Павловича — я бы тогда тотчас же решилась. А теперь — поди подумай!»
> В общем «Если бы губы Никанора Ивановича да приставить к носу Ивана Кузьмича, да взять сколь-нибудь развязанное, какая у Балтазара Балтазаровича, да, пожалуй, прибавить к этому еще дородности Ивана Павловича — я бы тогда тотчас же решилась. А теперь — поди подумай!»
вроде есть же асинхронные драйверы для postgresql/mysql/etc? или тут не прокатывают?
Всё правильно, асинхронные драйверы есть. Суть в том, что они тоже любят callback одним из аргументов — решение, как я уже говорил — использовать tornado.gen, но если идёт обработка нескольких зависимых сетов — толку от асинхронности — ноль по вдоль.
Не совсем понял суть проблемы..., можно же вместо callback использовать deferred объекты, и когда завершатся несколько параллельных зависимых операций — идти дальше… ??
Где-то я даже встречал, что кто-то вырезал deferred из twisted, вроде эта ссылка github.com/mikeal/deferred там и цепочки можно создавать… и списки запускать… и ожидать результата пока требуемые процессы завершатся…
Хотя… вот тут вроде что-то похожее написано… www.tornadoweb.org/documentation/gen.html
Где-то я даже встречал, что кто-то вырезал deferred из twisted, вроде эта ссылка github.com/mikeal/deferred там и цепочки можно создавать… и списки запускать… и ожидать результата пока требуемые процессы завершатся…
Хотя… вот тут вроде что-то похожее написано… www.tornadoweb.org/documentation/gen.html
Ну вот он этот «протестный» принцип успешно и применяет… Как говорится, не рой яму другому…
Ха, вот уж не думал… От создателя Flask (Armin Ronacher), — всеми ругаемый Django QuerySet для SQLAlchemy…
github.com/mitsuhiko/sqlalchemy-django-query
даже не знаю, что сказать…
github.com/mitsuhiko/sqlalchemy-django-query
даже не знаю, что сказать…
Sign up to leave a comment.
Django Micro