Comments 187
Вообще, мне кажется, это плохой тон задавать на собеседовании логические загадки. Кандидаты, как правило на нервах, даже если этого не видно, и рассчитывают на вопросы, ориентированные на их обязанности. Такие задачки просто сбивают их с толку.
Согласен. Логические задачи должны быть обоснованы какими-то определенными требованиями к позиции, например, вас собеседуют в исследовательский центр, где все время нужно изобретать велосипеды, тогда да, или вы будете руководить бизнесом в каких-то жестких рыночных условиях, где только творческие подходы имеют успех, или вы возглавляете экспедицию по стопам Индианы Джонса.
А я в последнее время перестал задавать устные задачи кандидатам, не все воспринимают устно, не все себя чувствуют комфортно на даче показаний.
Сначала завожу разговор о кандидате — что он ищет, что хочет получить от работы, куда стремится, его предыдущий опыт и его увлечения. И только после того, как я приму решение о нем, как о допустимом сотруднике — дается задание с практически неограниченным лимитом, например в неделю (время за которое решил бы его средний сотрудник на эту должность умноженную на два), читай-перечитывай, пиши-исправляй сколько угодно. Главное решение поставленной задачи. Справился — молодец.
Сначала завожу разговор о кандидате — что он ищет, что хочет получить от работы, куда стремится, его предыдущий опыт и его увлечения. И только после того, как я приму решение о нем, как о допустимом сотруднике — дается задание с практически неограниченным лимитом, например в неделю (время за которое решил бы его средний сотрудник на эту должность умноженную на два), читай-перечитывай, пиши-исправляй сколько угодно. Главное решение поставленной задачи. Справился — молодец.
С другой стороны, про «задачи устно» и логические — они показывают, как человек может справиться с волнением, сможет ли в критический момент сосредоточиться, а не тупить и просить недельку, чтобы подумать дома в спокойной обстановке. Но это нужно расценивать как плюс, а не определяющий фактор.
Чтобы программисту не приходилось справляться с волнением на работе, должен быть адекватный менеджер проектов или начальник отдела, которые должны создавать комфортную рабочую среду. И сразу не нужно разработчиков проверять на стрессоустойчивость. А если вы пришли на собеседования и на вас кричат, обливают водой из стакана на столе, то стоит задуматься, а туда ли я пришел.
1. Согласен отчасти, т.к. критические ситуации могут возникать не только из-за [кривого] управления сотрудниками и их загрузкой.
Например, проблемы сотрудника дома, менеджер редко может решить (максимум, помочь как-то), а они тоже вызывают стресс. Или, например, ещё есть дорога до работы — тут целый рассадник раздражителей. Т.е., подводя итог, вы зря всё спихиваете на менеджера.
2. Подскажите, пожалуйста, «сразу не нужно» — а когда нужно? На боевом проекте в самый ответственный момент?
2.0. Мне действительно интересно, когда нужно проверять разработчиков на стрессоустойчивость.
3. Кроме вопроса «а туда ли я пришёл», возможно, стоит ещё задуматься «а что вам, собственно, нужно».
Например, проблемы сотрудника дома, менеджер редко может решить (максимум, помочь как-то), а они тоже вызывают стресс. Или, например, ещё есть дорога до работы — тут целый рассадник раздражителей. Т.е., подводя итог, вы зря всё спихиваете на менеджера.
2. Подскажите, пожалуйста, «сразу не нужно» — а когда нужно? На боевом проекте в самый ответственный момент?
2.0. Мне действительно интересно, когда нужно проверять разработчиков на стрессоустойчивость.
3. Кроме вопроса «а туда ли я пришёл», возможно, стоит ещё задуматься «а что вам, собственно, нужно».
Очень часто неспособность решить логическую задачку на собеседовании означает неспособность решить её в принципе без гугления и всяких форумов. И очень многие это забывают, и оправдывают себя волнением. Не переоценивайте влияние волнения на собесеодвании. Если у вас хорошо работают мозги — вы всё решите. А если вы зашорились на одних и тех же тупых решениях которые делаете из проекта в проект неудивительно что на собеседовании вы не решите ничерта.
Я не отрицаю влияние волнения, но как слишком уж часто его ставят как главный фактор. О частой беспросветной тупости и забитости мозгов собеседуемых все как то внезапно забывают.
Я не отрицаю влияние волнения, но как слишком уж часто его ставят как главный фактор. О частой беспросветной тупости и забитости мозгов собеседуемых все как то внезапно забывают.
Пару лет назад, когда менял работу, просто забивал на большие тестовые задания, ибо предложений для программистов сейчас немало, в день по три-четыре собеседования, и тратить неделю, только на одно тз — очень неразумно.
Ну если вы бы решали эту задачу все отведенные максимальные 40 часов не вставая из-за компьютера — думаю мы бы не сработались. Многие задачи вообще были устные, например — опишите как можно оптимизировать данный код. Многие на оптимизацию чужого кода в комментариях на хабре тратят времени больше.
Если вы на собеседовании даете задание, которое у меня отнимает даже 8 часов — мы бы уже не сработались. Вы должны понимать, что вы не единственный работадатель к которому я пришел, вы должны понимать что если каждый начнет давать такие задания — поиск работы превратится в ад.
Среди оценивающих комментарии явно работодателей меньше чем соискателей :-)
Это нормально, если:
1) Компания хороша и кандидат хочет именно в нее, а не бегает по городу
2) Тестовое задание оплатить
1) Компания хороша и кандидат хочет именно в нее, а не бегает по городу
2) Тестовое задание оплатить
А вы можете привести хоть один пример компании, которая заплатит кандидату за тестовое задание? А то мне это, честно говоря, кажется весьма сомнительным. С первым пунктом не поспоришь, но опять же — вряд ли у вас на собеседовании спросят «Вы хотите именно в нашу компанию, или нет? Если именно в нашу, мы вам тестовое заданьеце дадим, а если нет — то так, устно поспрашиваем».
>>А вы можете привести хоть один пример компании, которая заплатит кандидату за тестовое задание?
Я могу. Правда это был граф. дизайн, но в данном случае это всё равно.
Да, в наших палестинах это редкость но случается тем не менее.
Я могу. Правда это был граф. дизайн, но в данном случае это всё равно.
Да, в наших палестинах это редкость но случается тем не менее.
Ну что ж, значит вам повезло ;) Я ни разу с подобным не встречался, да и в качестве задания давали бесполезную лабуду. Один раз, например, просили написать векторный графический редактор — мало того, что потом он никому не нужен, так еще и требований к заданию надавали на 15 листах. А тестовое задание по дизайну можно хотя бы в портфолио потом включить.
Да, на хабре было несколько примеров, когда тестовое задание было реальной работой и оплачивалось.
Я один раз делал тестовое задание. В итого от работы в той компании я отказался, но за тестовое они мне все равно заплатили.
Да я сам давненько на одеске без всякого собеседования получил $48 за тестовое задание. Мне потом вообще никто ни на что даже не ответил, но свои $48 за потраченные 2 часа я получил
Наша компания тоже платит за тестовые задания, в общем-то (они большие у нас). И в ранней молодости мне когда-то заплатили в компании за месяц испытательного срока. Это нормальная практика.
Мы в Dream Industries довольно щепетильны в наборе сотрудников — нам нужны самостоятельные люди, способные работать в команде и задачи у нас часто необычные и интересные.
Сейчас мы собираем информацию о человеке из различных источников. Иногда после этого технический уровень уже понятен и важно скорее сработаемся ли мы с ним в команде, иногда все по другому.
В любом случае — открытый, честный, искренний разговор многое проясняет.
Часто в случае человека начинающего мы даем «тестовое» задание, реально нужное проекту. Конечно, при этом подписывается NDA, эта работа оплачивается, etc. Практически это можно рассматривать как испытательный срок. Может оказаться, что задача для него слишком сложная, или она в реальности разворачивается в нечто гораздо большее, чем мы предполагали. Вариантов развития событий — бесконечность. Но это обычный процесс разработки, и по тому, что происходит в процессе решения задачи мы и принимаем окончательное решение.
Раз уж такая простыня получилась — разыскиваются frontend разработчики на интересную работу :) пишите в личку или на frontend@dreamindustries.co
Сейчас мы собираем информацию о человеке из различных источников. Иногда после этого технический уровень уже понятен и важно скорее сработаемся ли мы с ним в команде, иногда все по другому.
В любом случае — открытый, честный, искренний разговор многое проясняет.
Часто в случае человека начинающего мы даем «тестовое» задание, реально нужное проекту. Конечно, при этом подписывается NDA, эта работа оплачивается, etc. Практически это можно рассматривать как испытательный срок. Может оказаться, что задача для него слишком сложная, или она в реальности разворачивается в нечто гораздо большее, чем мы предполагали. Вариантов развития событий — бесконечность. Но это обычный процесс разработки, и по тому, что происходит в процессе решения задачи мы и принимаем окончательное решение.
Раз уж такая простыня получилась — разыскиваются frontend разработчики на интересную работу :) пишите в личку или на frontend@dreamindustries.co
то есть мой основной месседж был в: естественное лучше искусственного.
Человек может быть скромняжкой на собеседовании и зажигать при кодинге нереально, мочь работать только по ночам и поэтому тупить на всех собеседованиях при просьбе ответить на технический вопрос. Реальная разработка рулит.
Если разработчик более-менее взрослый — всегда можно показать проекты. С начинающими это не всегда работает.
Человек может быть скромняжкой на собеседовании и зажигать при кодинге нереально, мочь работать только по ночам и поэтому тупить на всех собеседованиях при просьбе ответить на технический вопрос. Реальная разработка рулит.
Если разработчик более-менее взрослый — всегда можно показать проекты. С начинающими это не всегда работает.
Я обычно даю тестовое задание, выполняемое прямо у нас в офисе часа за три. Интернетом и чем угодно пользоваться можно, разве что средствами связи нельзя. Да, сразу предлагаю задавать в любой момент любые вопросы, в том числе наводящие на способ решения поставленной задачи.
Кстати, тоже индикатор. Если соискатель уложился часа в 3 или меньше (у нас тестовое задание не менялось 6 лет, к следующему набору сотрудников придётся поменять) — отлично, наш уровень. Но если ковырялся часа 4 и на выходе сделал жуткий говнокод — уже есть вопросы.
А ещё мы в последнее время после собеседования стали просматривать историю браузера. Тоже очень информативно оказывается, сразу видно, как человек формулирует задаваемые поисковику вопросы и как подходит к поиску информации :)
Кстати, тоже индикатор. Если соискатель уложился часа в 3 или меньше (у нас тестовое задание не менялось 6 лет, к следующему набору сотрудников придётся поменять) — отлично, наш уровень. Но если ковырялся часа 4 и на выходе сделал жуткий говнокод — уже есть вопросы.
А ещё мы в последнее время после собеседования стали просматривать историю браузера. Тоже очень информативно оказывается, сразу видно, как человек формулирует задаваемые поисковику вопросы и как подходит к поиску информации :)
zagayevskiy вон писал, что вроде как месяц потратил на разработку игры, чтобы устроиться на работу.
Я лично не прочь недельку и потерпеть, если работа того стоит)
Я лично не прочь недельку и потерпеть, если работа того стоит)
например в неделю (время за которое решил бы его средний сотрудник на эту должность умноженную на два)
Вы платите в 2 раза выше рынка, чтобы позволить себе давать тестовые задания на 2.5 человеко-дня?
Имя компании в студию. Думаю, многим интересно будет.
Проблема логических задач в том, что они уже все известны (см. к примеру «Как передвинуть гору Фудзи» и т.п.), а крупные компании всё продолжают и продолжают их задавать и давать предпочтение людям, которые знали решение, но имитировали бурную мозговую деятельность с последующим решением, нежели тем, кто решения не знал (или не мог сосредоточиться на решении из-за нервов).
Я думаю что задавать логические задачки как раз хорошо, что бы оценить как кандидат может себя вести в нервно-стрессовой ситуации.
Тут не важен даже сам ответ, тут важно как кандидат рассуждает и как себя ведёт.
Потом уже можно спрашивать задачки по назначению и специальности. Тут уже будет важен ответ, конечно.
Тут не важен даже сам ответ, тут важно как кандидат рассуждает и как себя ведёт.
Потом уже можно спрашивать задачки по назначению и специальности. Тут уже будет важен ответ, конечно.
что бы оценить как кандидат может себя вести в нервно-стрессовой ситуации.
Это очень показательно. Если от программиста требуется работать в «нервно-стрессовой» ситуации, значит ПМ и тимлид раззвездяи и обходить такую контору стороной надо. Это если логические задачки от тех. специалистов идут. Если хрюша развлекается, то, почему бы и нет. Если это за нормы приличия не начинает выходить.
Работы бывают разные, компании бывают разные, клиенты бывают разные. Поэтому если есть стрессовые ситуации, то это не значит что начальство неадекватное, это просто особенность той работы. Там обычно доплачивают за вредность и я не вижу причины обходить стороной если деньги важны или важно что бы на резюме была такая компания.
Например, у меня жена раньше работала в конторе, где 10-12 часовой рабочий день — это норма. А ведь у них есть ещё сезонная занятость когда в день примерно 20 рабочих часов. Народ в этом стрессе работает за строчку в резюме, у них потом все дороги открыты если они хотят пойти работать в другое место. И тут дело не в начальниках, просто такая особенность работы.
А за нормы приличия не должен выходить даже обычный разговор на работе, это само собой.
Обычные логические задачки за нормы приличия не выходят.
Например, у меня жена раньше работала в конторе, где 10-12 часовой рабочий день — это норма. А ведь у них есть ещё сезонная занятость когда в день примерно 20 рабочих часов. Народ в этом стрессе работает за строчку в резюме, у них потом все дороги открыты если они хотят пойти работать в другое место. И тут дело не в начальниках, просто такая особенность работы.
А за нормы приличия не должен выходить даже обычный разговор на работе, это само собой.
Обычные логические задачки за нормы приличия не выходят.
Тут, скорее всего, вопрос в терминологии. Наверное, мы друг друга не поняли. Повышенную нагрузку я «стрессом» не считаю. Если работодатель честно предупредил об условиях работы, а работник согласился, то все нормально, имхо. Оба взрослые люди.
Под «стрессом» я подразумевал ситуацию, когда на работника возлагаются не свойственные его должности обязанности или ответственность без предварительного согласования. Например, когда разработчика вдруг сажают на поддержку или когда менеджер обещает заказчику золотые горы, которые будут реализованы за один день (т.е. заранее невыполнимое), а потом обвиняет разработчиков в некомпетентности. Как-то так. Ситуация, когда ты пришел готовить торт, а тебе в руки суют швабру со словами: «быстро мой пол, а то все взорвется», — и при этом наблюдают, как за обезьянкой, имхо, недопустима. Не хочу показаться Д'Артаньяном, но, имхо, такие фокусы прокатывают со слабо квалифицированным персоналом. И под нормами приличия я подразумевал 1-2 такие «задачки» на 5 минут времени. Если приходит человек с 5+ лет опытом работы, а ему суют под нос анкету и пол часа мурыжат задачками: «как влезть на гору, если ты без руки и у тебя есть зубочистка, труп дельфина и 5 кг мыла», — я считаю, что это проявление неуважения к кандидату на должность. При этом, я вполне допускаю, что компания имеет ресурсы и может себе позволить проявлять неуважение и ищет людей, которые согласны на такой порядок вещей. Это бизнес, один продает. другой покупает:)
Под «стрессом» я подразумевал ситуацию, когда на работника возлагаются не свойственные его должности обязанности или ответственность без предварительного согласования. Например, когда разработчика вдруг сажают на поддержку или когда менеджер обещает заказчику золотые горы, которые будут реализованы за один день (т.е. заранее невыполнимое), а потом обвиняет разработчиков в некомпетентности. Как-то так. Ситуация, когда ты пришел готовить торт, а тебе в руки суют швабру со словами: «быстро мой пол, а то все взорвется», — и при этом наблюдают, как за обезьянкой, имхо, недопустима. Не хочу показаться Д'Артаньяном, но, имхо, такие фокусы прокатывают со слабо квалифицированным персоналом. И под нормами приличия я подразумевал 1-2 такие «задачки» на 5 минут времени. Если приходит человек с 5+ лет опытом работы, а ему суют под нос анкету и пол часа мурыжат задачками: «как влезть на гору, если ты без руки и у тебя есть зубочистка, труп дельфина и 5 кг мыла», — я считаю, что это проявление неуважения к кандидату на должность. При этом, я вполне допускаю, что компания имеет ресурсы и может себе позволить проявлять неуважение и ищет людей, которые согласны на такой порядок вещей. Это бизнес, один продает. другой покупает:)
Согласен. Иногда на собеседовании они звучат как "В чём разница между уткой?"
Знание подобных задач можно рассматривать по разному, напимер что кандидат осмысленно готовился к собеседованию в компанию где дают такие задачи. Что в свою очередь может показывать его высокую мотивацию работать именно в этой компании.
Не обязательно. Нервы зашкаливают обычно только у выпускников. Когда вы уже поработали 5 — 20 лет, то чувствуете себя как рыба в воде. На собеседования тогда люди ходят с интересом, ведь деньги не так актуальны, вы ведь уже работаете, Важно найти вакансию, которая будет интересна.
Огромное спасибо. Я задавал вопрос в свой статье «Школьник об олимпиадном программировании» о том, нужны ли олимпиадники в «промышленном» программировании — вот он ответ. Очень похоже на олимпиадные задачи!
В промышленном программирование необходимо уметь решать поставленные задачи, будет ли этот код эталоном, или его будет страшно показывать — вторично.
Это очень зависит от ситуации. Зачастую решение задачи, сделанное некачественно, со скверным кодом ничуть не лучше отсутствия решения.
Не скажите. В адекватных командах не дадут писать нечитаемый код, даже если он как-то там решает задачу, ведь после его еще и поддерживать (представьте себе!) придется другими людьми. Но если под «промышленным программированием» понимать быдлокодинг, то ок, да.
Не путайте промышленное программирование с неуправляемым прототипированием, плавно перетекающим в продакшн с крайне дорогостоящей поддержкой и с фактическим отсутствием расширяемости.
Что-то не совсем понял в чем сложность первой задачи? Делаем в all_words_1 и all_words_2 поле word уникальным, а дальше
INSERT INTO all_words_1 SELECT * FROM words_1;
INSERT IGNORE INTO all_words_1 SELECT * FROM words_2;
INSERT INTO all_words_2 SELECT * FROM words_2;
INSERT IGNORE INTO all_words_2 SELECT * FROM words_1;
SELECT DISTINCT *
FROM words_1
UNION ALL
SELECT *
FROM words_2
FROM words_1
UNION ALL
SELECT *
FROM words_2
Не забываем, что одни и те же слова имеют разные ключи-ссылки, которые нужно сохранить. В самих словах повторов нет, поэтому SELECT DISTINCT * FROM words_1 равно SELECT * FROM words_1 (без DISTINCT).
Вообще-то UNION ALL _не_ удаляет дубликаты. Чтобы удалять их нужен просто UNION.
В вашем решении в конечную выборку попадут и 'кинотеатр — 2' и 'кинотеатр — 15', т.к. это уникальные строки. Эту задачу гораздо проще решить через FULL JOIN по словам с ISNULL'ами в блоке SELECT. По первому столбцу на исходных таблицах нужно предварительно построить индексы.
Тут важный вопрос в том, какое из предложенных решений будет действительно быстро работать. Я вот сейчас не могу проверить, к сожалению, скорость данного решения. Какое число сравнений здесь делается? Мне почему-то кажется, что при таком методе идет «пословная» выборка и вставка каждого слова, а при вставке каждое слово ищется (есть оно уже или нет). Да, здесь проверяется не каждое с каждым, но все равно очень много со многими.
(select test2.word, test2.num from test2 left join test1 using(word) WHERE test1.word IS NULL)
UNION
(select test1.word, test1.num from test1 left join test2 using(word));
create table words as select * from ((select * from words1) union (select * from words2)) as t group by word
К первой хеши являются решением?
Отсортировать оба списка, затем объединить в один с выбросом повторов за один проход.
На словах все верно. Проход один, число сравнений минимально. Если человек на собеседовании говорит так, то ему сразу первый плюс.
Зачем сортировать?
Если не сортировать, то проверка вхождения в список каждого слова будет за O(n), для n слов сложность будет O(n^2).
Если сначала отсортировать, например, HeapSort'ом, Timsort'ом или даже QSort'ом (в случае, если данные не подобраны специально, чтобы нагнуть QSort), то сортировка за O(n*logn) + слияние за O(n), итого O(n*logn), а это гораздо лучше, чем O(n^2).
Вот картинка (обратите внимание, что шкала логарифмическая; с равномерной шкалой уже при n=100 Вы увидите только один график n^2):

Если сначала отсортировать, например, HeapSort'ом, Timsort'ом или даже QSort'ом (в случае, если данные не подобраны специально, чтобы нагнуть QSort), то сортировка за O(n*logn) + слияние за O(n), итого O(n*logn), а это гораздо лучше, чем O(n^2).
Вот картинка (обратите внимание, что шкала логарифмическая; с равномерной шкалой уже при n=100 Вы увидите только один график n^2):

Немного поправлю: quicksort при соответствующей реализации не зависит от входных данных (в смысле не деградирует до n^2), даже без рандома.
Хм. А не могли бы Вы рассказать подробнее (хотя бы концептуально) или привести ссылку на ресурс?
Ну смотрите, на каждом шаге quicksort нам нужно выбрать медиану текущего участка массива (в качестве разделяющего элемента), и когда очевидно трудоёмкость будет O(nlogn). Есть детерминированный алгоритм выбора медианы (точнее, любого k-го по порядку элемента) за O(n), описанный например в Кормене. Если воспользоваться им, то асимптотика каждого шага quicksort не изменится (там и так есть разбиение по этому элементу, что занимает те же O(n)), а выбран будет всегда оптимальный элемент.
Кстати, возможно интересный факт — не обязательно выбирать именно медиану (т.е. элемент, больший чем половина массива), например если брать элемент, который больше чем миллионная часть массива (или какая-то другая часть, но фиксированная) — трудоёмкость всё равно будет O(nlogn), только с большей константой. Это всё тоже есть в Кормене, а мы проходили в этом семестре по теории алгоритмов :)
Кстати, возможно интересный факт — не обязательно выбирать именно медиану (т.е. элемент, больший чем половина массива), например если брать элемент, который больше чем миллионная часть массива (или какая-то другая часть, но фиксированная) — трудоёмкость всё равно будет O(nlogn), только с большей константой. Это всё тоже есть в Кормене, а мы проходили в этом семестре по теории алгоритмов :)
Минус ему, а не плюс. Если уж мы говорим о чисто алгоритмическом решении — сортировка даст нам асимптотику в O(N*logN), тогда как решение на хеш-таблицах — O(N). А уж определение эффективности алгоритма по количеству сравнений — уж извините, закрадывает некоторые сомнения в квалификации собеседующего.
Покажите мне это решение.
public Collection<Record> merge(Collection<Record> a, Collection<Record> b) {
Map<String, Record> map = new HashMap<String, Record>();
for (Record r : b)
map.put(r.word, r);
for (Record r : a)
map.put(r.word, r);
return map.values();
}
Так, я думал тут про вторую задачу говорят. Извиняюсь.
тогда как решение на хеш-таблицах — O(N).
Т.е. создание хэша у вас операция бесплатная?
То есть, создание хеша — линейная от количества элементов задача. На масштабах исходной задачи (n > 10^5) асимптотика значительно проявляется, тем более что у простых хешей «константа» низкая. И, вы не поверите, именно это позволяет эффективно работать бесчисленному количеству nosql решений, в том числе распределённых.
На мой взгляд, вы зря получили it-вышку.
На мой взгляд, вы зря получили it-вышку.
Это сильно зависит от условий!
Решение с сортитовкой прекрасно работает и на очень больших данных (больше памяти), а вот с хешом может получится некрасиво.
И хеш функция у вас должна быть хорошая. Она обычно хорошая, но бывают случаи…
Правда в данном случае 100k записей должны уложится в память.
Решение с сортитовкой прекрасно работает и на очень больших данных (больше памяти), а вот с хешом может получится некрасиво.
И хеш функция у вас должна быть хорошая. Она обычно хорошая, но бывают случаи…
Правда в данном случае 100k записей должны уложится в память.
Не зависит.
Решение линейно по памяти, значит если в память влазят исходные данные — влезет и мапа. Если не влазят — решение с сортировкой тоже не пойдет.
Хеш-функция для стрингов хорошая во всех известных мне языках. Не бывает случаев.
100к записей влезут аж со свистом. И 100м влезут — хватило бы памяти.
Решение линейно по памяти, значит если в память влазят исходные данные — влезет и мапа. Если не влазят — решение с сортировкой тоже не пойдет.
Хеш-функция для стрингов хорошая во всех известных мне языках. Не бывает случаев.
100к записей влезут аж со свистом. И 100м влезут — хватило бы памяти.
Что значит решение с сортировкой «не пойдёт»? Сортировкой слиянием можно сортировать сколь угодно большие данные, все их закачивать в память не надо. То же относится и к сравнению списков.
Идеальная хеш-функция это как идеальный архиватор, вроде бы можно, но не существует в жизни. По крайней мере в той же Java есть и SortedMap и TreeMap
Идеальная хеш-функция это как идеальный архиватор, вроде бы можно, но не существует в жизни. По крайней мере в той же Java есть и SortedMap и TreeMap
То и значит.
Опишите мне, пожалуйста, алгоритм мержсорта, который позволил бы сортировать не полностью лежащий в памяти массив.
> Идеальная хеш-функция это как идеальный архиватор, вроде бы можно, но не существует в жизни.
Это демагогия. Давайте конкретно: сколько коллизий вы встретите в жававской реализации строковых хэшкодов на, скажем, 1кк реальных строк из условия?
Да, и что такое — «идеальный архиватор», который «вроде бы можно»?
> По крайней мере в той же Java есть и SortedMap и TreeMap
Этого, извините, не понял. Раз уж мы обсуждаем именно Java — вы, конечно, в курсе, что SortedMap — это интерфейс, а TreeMap — его реализация на основе двоичных деревьев (с асимптотикой O(NlogN))?
Опишите мне, пожалуйста, алгоритм мержсорта, который позволил бы сортировать не полностью лежащий в памяти массив.
> Идеальная хеш-функция это как идеальный архиватор, вроде бы можно, но не существует в жизни.
Это демагогия. Давайте конкретно: сколько коллизий вы встретите в жававской реализации строковых хэшкодов на, скажем, 1кк реальных строк из условия?
Да, и что такое — «идеальный архиватор», который «вроде бы можно»?
> По крайней мере в той же Java есть и SortedMap и TreeMap
Этого, извините, не понял. Раз уж мы обсуждаем именно Java — вы, конечно, в курсе, что SortedMap — это интерфейс, а TreeMap — его реализация на основе двоичных деревьев (с асимптотикой O(NlogN))?
Сортировкой слиянием можно сортировать сколь угодно большие данные, все их закачивать в память не надо.
Я наверное немного туплю, но объясните пожалуйста как хранить отсортированные данные если не в памяти? (HDD — тоже память, просто с худшим на порядки временем доступа).
Мне кажется хранение отсортированных данных и созданного HashMap требует приблизительного одного объема памяти (вернее, конечно, немного разного, но разница будет на небольшую константу).
«Хеш-функция для стрингов хорошая во всех известных мне языках. Не бывает случаев.»
ЕМНИП, Блох говорил, что hashCode для строк в Яве был плохой и это выяснилось на длинных URL-ах. Но пофиксить было невозможно в силу необходимости обратной совместимости.
ЕМНИП, Блох говорил, что hashCode для строк в Яве был плохой и это выяснилось на длинных URL-ах. Но пофиксить было невозможно в силу необходимости обратной совместимости.
А как же обработка коллизий?
К тому же нельзя забывать, что O — это не только асимптотика, но и константа, а константа может быть очень большой.
К тому же нельзя забывать, что O — это не только асимптотика, но и константа, а константа может быть очень большой.
Коллизии в String.hashcode() — вещь настолько редкая, что в реальной жизнии ее можно не учитывать.
Ну и решение есть выше — покажите мне — откуда там возьмется большая константа?
Ну и решение есть выше — покажите мне — откуда там возьмется большая константа?
Если Вы обратите внимание, мой ответ был не к предложенному Вами решению. Я просто прокомментировал Ваше категоричное высказывание относительно использования хеширования для решения задачи, имея в виду, что не все так однозначно.
Касательно той же асимптотики, если уж на то пошло, то разница между O(n) и O(n log n) почти незаметна, если Вы не работаете с системами реального времени. Например ln (1 000 000) =~ 13. Можете построить графики и убедиться, что n*log n ведет себя почти линейно.
Касательно String.hashCode(), если я не ошибаюсь, уже при 30 000 элементов вероятность коллизии будет около 10%. Это не так уж и мало, чтобы игнорировать.
Касательно той же асимптотики, если уж на то пошло, то разница между O(n) и O(n log n) почти незаметна, если Вы не работаете с системами реального времени. Например ln (1 000 000) =~ 13. Можете построить графики и убедиться, что n*log n ведет себя почти линейно.
Касательно String.hashCode(), если я не ошибаюсь, уже при 30 000 элементов вероятность коллизии будет около 10%. Это не так уж и мало, чтобы игнорировать.
В данном случае все (почти) однозначно.
Если мы решаем абстрактную алгоритмическую задачу — достаточно сказать, что решение на хэш-таблицах имеет меньшую асимптотику.
Если мы решаем практическую задачу — решение с хэш-таблицами работает быстро и за один проход, в то время как решение с сортировкой обладает следующими недостатками:
— оно сильно медленнее (ниже подробности)
— имеет такую же асимптотику по памяти (для хранения результата)
— входящие коллекции должны поддерживать произвольный доступ (прощайте, курсоры базы данных и прочее подобное);
— входящие коллекции должны быть мутабельными (или сортировка в новые коллекции, что не ускоряет).
— решение требует больше строк кода.
Сортировка будет значительно медленнее как минимум потому, что она использует строковые сравнения, в то время как хэш-таблицы — сравнение хэшей. Надо ли объяснять, почему константа для сортировки увеличивается в М (средняя длина строки) раз?
Касательно коллизий — это легко проверить.
Вот прямо сейчас я взял первую книгу «Войны и Мира», разбил ее на слова (229540 слов, к слову) и составил (неповторяющиеся) строки из последовательно идущих 2,3,...,10 слов. Получилось 416588 фраз, причем не абстрактных, а вполне себе применимых в жизни.
На этом наборе коллизий у нас получилось целых 23.
Примеры коллизий:
«он. – Денисов, ты»
«пожилая дама. Князь»
«генералу. Здесь»
«лесом берег»
«что его»
«что же?»
И т.д.
Вы действительно считаете, что ~50 коллизий на миллион что-то решают?
Если мы решаем абстрактную алгоритмическую задачу — достаточно сказать, что решение на хэш-таблицах имеет меньшую асимптотику.
Если мы решаем практическую задачу — решение с хэш-таблицами работает быстро и за один проход, в то время как решение с сортировкой обладает следующими недостатками:
— оно сильно медленнее (ниже подробности)
— имеет такую же асимптотику по памяти (для хранения результата)
— входящие коллекции должны поддерживать произвольный доступ (прощайте, курсоры базы данных и прочее подобное);
— входящие коллекции должны быть мутабельными (или сортировка в новые коллекции, что не ускоряет).
— решение требует больше строк кода.
Сортировка будет значительно медленнее как минимум потому, что она использует строковые сравнения, в то время как хэш-таблицы — сравнение хэшей. Надо ли объяснять, почему константа для сортировки увеличивается в М (средняя длина строки) раз?
Касательно коллизий — это легко проверить.
Вот прямо сейчас я взял первую книгу «Войны и Мира», разбил ее на слова (229540 слов, к слову) и составил (неповторяющиеся) строки из последовательно идущих 2,3,...,10 слов. Получилось 416588 фраз, причем не абстрактных, а вполне себе применимых в жизни.
На этом наборе коллизий у нас получилось целых 23.
Примеры коллизий:
«он. – Денисов, ты»
«пожилая дама. Князь»
«генералу. Здесь»
«лесом берег»
«что его»
«что же?»
И т.д.
Вы действительно считаете, что ~50 коллизий на миллион что-то решают?
Вы идеализируете хеш-таблицы. Даже если ваша хеш-функция идеальна, то чтобы избежать коллизий, под таблицу надо отводить в несколько раз больше памяти, чем в ней будет записей. К тому же, надо эти самые хорошие хеш-функции вычислять. Отсюда и вылезает довольно ощутимая константа в этой вашей асимптотике. А логарифм не так уж быстро растет.
Поэтому не исключено, что решение с сортировкой более практичное. И как вам указали выше, вариант с сортировкой хорош тем, что его можно реализовать out-of-core, если использовать, например, merge sort. Представьте, например, что каждый из списков занимает 100 ГБ.
Поэтому не исключено, что решение с сортировкой более практичное. И как вам указали выше, вариант с сортировкой хорош тем, что его можно реализовать out-of-core, если использовать, например, merge sort. Представьте, например, что каждый из списков занимает 100 ГБ.
Избыточная память относительна. Если принять load factor за 0.5 (что явно избыточно) — в хэш-таблице будет N пустых записей. При этом пустая запись — это всего лишь десяток байт на пустой указатель, поэтому откуда тут «в несколько раз больше» — в упор не вижу. На 20%-30% больше разве что.
Сложность вычисления хэшкодов компенсируется относительной (по сравнению со строковым сравнением в случае сортировки) простотой сравнения.
Если принять средний размер записи во входящих данных за, допустим, 50 байт (стринг*2, ибо юникод, +оверхед на собственно объекты), то на 100ГБ данных получим 2*10^9 записей. Это ИМХО несколько многовато как для внешней строковой сортировки на обычной машине.
Сложность вычисления хэшкодов компенсируется относительной (по сравнению со строковым сравнением в случае сортировки) простотой сравнения.
Если принять средний размер записи во входящих данных за, допустим, 50 байт (стринг*2, ибо юникод, +оверхед на собственно объекты), то на 100ГБ данных получим 2*10^9 записей. Это ИМХО несколько многовато как для внешней строковой сортировки на обычной машине.
Вы сейчас про какую задачу? «Оба списка» — это про первую, да? То есть вы соглашаетесь, что нужно сначала отсортировать оба списка для решения этой задачи?
С задачей про 100-метровую отвесную гору не справился, но я ведь не успокоюсь теперь, какое решение? :)
Я решил ровно за 5 секунд, которые потребовались на копирование задачи в гугл
Возьмите с собой ножик, как в горы пойдете ;)
В условиях задачи про нож ничего не было сказано, хотя конечно можно ухитриться перерезать верёвку и острым камнем.
Моё решение — найти камень, весом чуть меньше себя самого, привязать к одному концу камень, перекинуть всё это через тот самый штырь, опустить камень на платформу, потом начать спускаться самому. Из-за силы трения и малой разницы в весе опуститься получиться достаточно плавно. Далее, камень можно спустить под собственным весом обратно на платформу.
Плюс решения — бесконечное (зависит от прочности верёвки) количество итераций с высотой одного шага вплоть до 80 метров.
P.S. А уже потом погуглил про нож, который был.
Плюс решения — бесконечное (зависит от прочности верёвки) количество итераций с высотой одного шага вплоть до 80 метров.
P.S. А уже потом погуглил про нож, который был.
Почему-то с первых нескольких попыток не нагуглилось. Уже нашел. Да, всё оказалось очень просто… утомился за день, мозги не работают. Но на собеседовании я в любом случае не решил бы.
Если человек уверенно справляется с этими заданиями, то как вариант можно предложить усложнение, и, соответственно, увеличение зарплаты и/или должности/категории.
Например, предположим теперь, что в определениях есть небольшие ошибки/опечатки.
жЕвотное с большими ушами — 1
жИвотное с большими ушами и длинным носом — 1
Как переписать ваш код так, чтобы отработало корректно, с тем же результатом, как будто и не было опечаток.
Мне решения присылать не нужно. Это просто мысли вслух. Для разминки кому интересно себя проверить.
Например, предположим теперь, что в определениях есть небольшие ошибки/опечатки.
жЕвотное с большими ушами — 1
жИвотное с большими ушами и длинным носом — 1
Как переписать ваш код так, чтобы отработало корректно, с тем же результатом, как будто и не было опечаток.
Мне решения присылать не нужно. Это просто мысли вслух. Для разминки кому интересно себя проверить.
Какие-то у вас подозрительно простые задачи.
Про верёвку: можно кусок в 25 метров привязать сверху, и использовать как блок для оставшейся верёвки для спуска на выступ, и её же использовать для обычного спуска на оставшиеся 50 метров. Если гора совсем отвесная, задача ещё проще: можно резать/развязывать верёвку и падать как на тарзанке.
Первая задача: любой подходящий хеш (O(n)). Для sql — знание union.
Вторая задача недостаточно корректна сформулирована: нет формального определения «частичной повторяемости», не описаны ограничения на количество определений для одного слова.
Если речь о префиксах, задача банальна и сводится к обрезанию определения до первого слова, что даже для всяких mysql элементарно.
На мой взгляд, наиболее эффективно на собеседовании просто задавать человеку вопросы по той теме, которой он занимался, чтобы понять глубину погружения и умения понимать, ну и просто уровень мышления. Само собой, начиная от банальных вопросов, для быстрого отсеивания людей, оказавшихся на собеседовании случайно…
Про верёвку: можно кусок в 25 метров привязать сверху, и использовать как блок для оставшейся верёвки для спуска на выступ, и её же использовать для обычного спуска на оставшиеся 50 метров. Если гора совсем отвесная, задача ещё проще: можно резать/развязывать верёвку и падать как на тарзанке.
Первая задача: любой подходящий хеш (O(n)). Для sql — знание union.
Вторая задача недостаточно корректна сформулирована: нет формального определения «частичной повторяемости», не описаны ограничения на количество определений для одного слова.
Если речь о префиксах, задача банальна и сводится к обрезанию определения до первого слова, что даже для всяких mysql элементарно.
На мой взгляд, наиболее эффективно на собеседовании просто задавать человеку вопросы по той теме, которой он занимался, чтобы понять глубину погружения и умения понимать, ну и просто уровень мышления. Само собой, начиная от банальных вопросов, для быстрого отсеивания людей, оказавшихся на собеседовании случайно…
Если вам кажется все элементарным, значит Вы отличный специалист!
Эти знания у меня были ещё в студенческие годы, до начала коммерческой разработки. Называть меня тогда «отличным специалистом» — несколько опрометчиво — опыт всевозможных ACM мало кому на самом деле нужен, а указанный уровень знания sql на практике тренировался до достаточного для собеседований уровня меньше чем за неделю.
Кстати, уточните, пожалуйста, условия второй задачи — интересно же.
Кстати, уточните, пожалуйста, условия второй задачи — интересно же.
Я(школьник), например, постеснялся вот так вот сказать, что мне кажется эта задача элементарной, поэтому задал вопрос, на который, кстати, так и не получил ответа. Но всё-же, меня гарантированно отличным специалистом назвать нельзя далеко не из-за того, что я не был уверен в ответе, а по ряду других причин, которые, как мне кажется, всем и так ясны.
Я над первой задачей мучался час, прочел ваш ответ — может идиот, но я ничего не понял. Как вы отвяжете веревку которая длиной 50 метров?
А следующие задания — был нужен java программист, а теперь не хватает человека со знаниями sql. Шило на мыло
А следующие задания — был нужен java программист, а теперь не хватает человека со знаниями sql. Шило на мыло
Веревка в 30 метров намертво привязана к вершине, на ее конце петля. В петлю продета веревка в 50 метров (она не привязана, сложена вдвое, то есть 25 метров). Вместе это 55 метров — хватит до уступа. На уступе за один конец вытаскиваем 50 метров (она не привязана), привязываем и спускаемся.
Смотрите: сверху привязывается 27-метровый кусок с петлёй снизу. Через эту петлю просто пробрасывается верёвка, без завязывания (лучше несколько раз, для уменьшения необходимой силы для удержания веса тела). Эта 53-метровая верёвка с одной стороны привязывается к телу, а другая сторона используется для аккуратного спуска. Уже на уступе эта верёвка просто вытаскивается через петлю, и привязывается к уступу.
По техническим вопросам, кмк, проверяется способность человека за ограниченное время решать хоть сколько-то непростые вопросы в знакомой ему области. Если он может — скорее всего он может научиться тому что нужно в другой области.
По техническим вопросам, кмк, проверяется способность человека за ограниченное время решать хоть сколько-то непростые вопросы в знакомой ему области. Если он может — скорее всего он может научиться тому что нужно в другой области.
Не совсем стандартное решение:
Ищем на горе камень, массой близкой или выше чем вы. (+ сила трения камня о гору)
Привязываем веревку, спускаемся медленно и аккуратно на уступ.
Привязываем нижний конец к уступу.
Посильнее дергаем за веревку. Камень с верхним концом падает на уступ (берегите голову :) или мимо. Пофиг.
Сбрасываем камень вниз, спускаемся.
У нас ведь нету ножа для разрезания, да? Да и тяжело сверху определить полную высоту горы чтобы точно разрезать…
В реальных условиях так бы и было. Тем более если это стальной трос и ножа / кусачек нет полюбому.
Камень на горе нужной массы более вероятен…
Ищем на горе камень, массой близкой или выше чем вы. (+ сила трения камня о гору)
Привязываем веревку, спускаемся медленно и аккуратно на уступ.
Привязываем нижний конец к уступу.
Посильнее дергаем за веревку. Камень с верхним концом падает на уступ (берегите голову :) или мимо. Пофиг.
Сбрасываем камень вниз, спускаемся.
У нас ведь нету ножа для разрезания, да? Да и тяжело сверху определить полную высоту горы чтобы точно разрезать…
В реальных условиях так бы и было. Тем более если это стальной трос и ножа / кусачек нет полюбому.
Камень на горе нужной массы более вероятен…
UFO just landed and posted this here
Зачем, к вашей массе добавиться ускорение с которым вы будете дергать.
Вы же способны подтягиваться с гирей? В тоже время держать равновесие с равноценной массой в покое или равномерном движении с небольшим ускорением…
Все реально.
Т.е. как бы стащить вниз камень даже в 2 раза большей массы уже не проблема
Привязав веревку на уступе, вы можете использовать рычаг градуса веревки и собственного тела с отвесом горы. Тогда все еще проще.
Стащите, не бойтесь)
Вы же способны подтягиваться с гирей? В тоже время держать равновесие с равноценной массой в покое или равномерном движении с небольшим ускорением…
Все реально.
Т.е. как бы стащить вниз камень даже в 2 раза большей массы уже не проблема
Привязав веревку на уступе, вы можете использовать рычаг градуса веревки и собственного тела с отвесом горы. Тогда все еще проще.
Стащите, не бойтесь)
Теоретически — да, на практике в контексте реальных физических законов вы просто физически не можете приложить сильно большую силу, чем та, которую вы прикладываете при обычном спуске вниз «рывками». Поэтому вы либо упадёте вместе с камнем, либо не сможете его уронить. Плюс, сбрасывать в горах большие камни — заведомо плохая идея.
> Привязав веревку на уступе, вы можете использовать рычаг градуса веревки и собственного тела с отвесом горы.
Тут кстати ситуация обратная, в случае верёвки оборот вокруг любого блока (здесь — уступа) в разы уменьшает силу.
> Привязав веревку на уступе, вы можете использовать рычаг градуса веревки и собственного тела с отвесом горы.
Тут кстати ситуация обратная, в случае верёвки оборот вокруг любого блока (здесь — уступа) в разы уменьшает силу.
Мне вот больше интересно что делает человек на горе без ножа =)
Счастливые вы все. У меня на последнем собеседовании половина вопросов была в стиле «Чем отличаются в PHP функции count() и sizeof()? А чем отличаются die() и exit()?» — причем даже не «в стиле», а именно эти вопросы.
Правильный ответ: — Сейчас посмотрю в справочнике.
Мне кажется, вы удивитесь, насколько много людей с большим опытом и зарплатными ожиданиями не знают php на достаточном для работы уровне — не ловят момент, когда вместо isset нужен array_key_exists, не знают разницы между array_merge и +, не знают, как работают ключи в массивах, не слышали про continue/break с числом, не умеют работать с mb_ функциями, очень плохо знают regexp'ы. Да что уж там, даже нормально заэкранировать строку не могут.
И это не говоря о более сложных вещах, типа понимания блокировок (и, как следствие, знания, как будет работать страничка вида «session_start();sleep(10);»), понимание атомарности, очередей и отложенного выполнения задач. Хотя да, «паттерны» знают, но почему-то в реальной реализации даже псевдокодом сильно путаются.
И это не говоря о более сложных вещах, типа понимания блокировок (и, как следствие, знания, как будет работать страничка вида «session_start();sleep(10);»), понимание атомарности, очередей и отложенного выполнения задач. Хотя да, «паттерны» знают, но почему-то в реальной реализации даже псевдокодом сильно путаются.
Это рынок. На пхпшников огромный спрос, вот и появляются такие предложения.
Это эффект Даннинга-Крюгера в чистом виде — людям не хватает профессиональной квалификации, чтобы понять, насколько у них всё плохо, в результате чего сильно завышают профессиональную самооценку, что отражается в том числе на зарплатных ожиданиях. Кроме того, немало таких «программистов» большей частью делали говносайты на друпалах и джумлах.
На всякий случай оставлю ссылку
На любого «эксперта» в php найдётся вопрос, на который он не сможет ответить. Ну вот невозможно всего знать там, разве что всю документацию вместе с комментариями пользователей зазубрить. И каждые грабли в реальной жизни встречаются, поэтому нельзя сказать, что вот такой-то вопрос «ничего не доказывает», а вот «знание четвёртого параметра json_decode» — доказывает. Я вот предпочту человека, который для sql-запросов использует PDT bindParam(), чем такого, который занимается ручным экранированием символов и преуспел в этом.
Там перечислены разноплановые вопросы. Вопросы про массивы — просто показатель опыта и того, что человек разбирался в причинах проблем. Безусловно, знание этого «ничего не доказывает», просто очень хорошо коррелирует с опытностью человека в технологии и желании разбираться в ключевых особенностях.
Вопросы про экранирование — показатель того, что человек знает, как работает та или иная технология, и умеет решать поставленные задачи; кроме того, экранировать данные надо не только для запросов к БД, но и для вывода в html.
Вопросы про экранирование — показатель того, что человек знает, как работает та или иная технология, и умеет решать поставленные задачи; кроме того, экранировать данные надо не только для запросов к БД, но и для вывода в html.
Так извините, я много чего знаю, но не всё помню и тем более на таком стрессовом мероприятии как собеседование. Вот, например, три года назад разбирался с блокировками в сессиях, писал свой обработчик, однако я это делал три года назад и уже вообще практически ничего не помню с того времени — один раз библиотеку сделал и всё дальше работает. Аналогично с экранированием, ну не буду я никогда сам ничего экранировать и не буду брать на работу человека, который это делает.
Проверять надо базовые концепции: использует ли человек шаблоны (или sprintf хотя бы) для форматирования вывода, понимает ли вообще, как работать с юникодом, знает ли HTTP. Из одного последнего вопроса можно нихилое дерево вопросов развернуть, поскольку мне важнее иметь человека, понимающего структуру текстового протокола, чем робота, который все атрибуты фугкций для работы с HTTP вызубрил.
Ну то есть общие знания должны преобладать над технологиями, мне практики нужны, а не энциклопедисты.
Проверять надо базовые концепции: использует ли человек шаблоны (или sprintf хотя бы) для форматирования вывода, понимает ли вообще, как работать с юникодом, знает ли HTTP. Из одного последнего вопроса можно нихилое дерево вопросов развернуть, поскольку мне важнее иметь человека, понимающего структуру текстового протокола, чем робота, который все атрибуты фугкций для работы с HTTP вызубрил.
Ну то есть общие знания должны преобладать над технологиями, мне практики нужны, а не энциклопедисты.
UFO just landed and posted this here
Тогда уж лучше давайте реальное задание, за которое заплатите деньги, если оно будет решено. Даже в случае, если не возьмете кандидата на работу, он не потеряет своё время.
Обычное собеседование длится 30 мин с HR (общие слова, заче вы к нам, какие-то анкетки), 30-60 мин с начальником отдела и ведущими разработчиками, еще 15-30 мин с директором департамента. Итого не больше 2 часов в совокупности.
Предложенные задачки не должны занимать больше 30-60 мин. Т.е. вы можете либо тратить свое время на то, чтобы показать, что вы реально умеете оперативно решать поставленные задачи, либо тратить на то, чтобы отвечать на вопросы sizeof() или count(). Как говорится, где что заведено. Лично мне нужны не теоретики, а практики. Решил, отсортировал, удалил и т.д. — молодец.
Опять же повторюсь, вы будете реально работать, т.е. что-то делать, программировать, а не рассуждать и холиварить, как это сложно или просто, разрешимо или неразрешимо.
Предложенные задачки не должны занимать больше 30-60 мин. Т.е. вы можете либо тратить свое время на то, чтобы показать, что вы реально умеете оперативно решать поставленные задачи, либо тратить на то, чтобы отвечать на вопросы sizeof() или count(). Как говорится, где что заведено. Лично мне нужны не теоретики, а практики. Решил, отсортировал, удалил и т.д. — молодец.
Опять же повторюсь, вы будете реально работать, т.е. что-то делать, программировать, а не рассуждать и холиварить, как это сложно или просто, разрешимо или неразрешимо.
На всех хороших местах работы, на которых я работал, беседа с HR была до очного собеседования по почте, скайпу и телефону. На собеседовании я HR не видел. А вот пару раз вляпался в конторы-какашки, там хрюши мне минут по 40 мозги любили анкетками и дурными вопросами.
С некоторых пор на анкете, если ее подсовывают, пишу: «все данные есть в резюме» и прикладываю распечатку резюме.
Конечно, выборка не репрезентативна, но, тем не менее :)
С некоторых пор на анкете, если ее подсовывают, пишу: «все данные есть в резюме» и прикладываю распечатку резюме.
Конечно, выборка не репрезентативна, но, тем не менее :)
Как насчет такой задачки: что больше, e^pi или pi^e?
А это задачка даёт знание, хорош ли программист?
Задачка может дать ответ, человек вообще умеет хоть как-то программировать или нет, если он это запрограммирует и результат покажет на экране.
Есть ли хоть один язык, кроме ассемблера, где эта задача не решается одной строкой кода? Можно еще дать программисту задание включить компьютер…
Ой, нет, тут программировать ничего не надо. Тут скорее подвох: все знают что такое ⅇ и π, а вот для того чтобы сравнить аналитически нужно подумать головой.
UFO just landed and posted this here
Да, инкапсуляция — это важный инструмент ООП, но если программист всю жизнь писал без ООП, то что, он теперь плохой?
Прошу прощения, но кто и когда выдал ООП монополию на инкапсуляцию?
Человек мог не знать такого слова (хоть и сомнительно), но чтоб не использовать — не представляю.
Однажды побывал на собеседовании, был вопрос (на javascript):
Что быстрее сработает бля объединения двух строк:
1. Всем привычное firstVar+secondVar;
2. Поочередное добавление каждого символа второй строки в конец первой (что-то в роде thirdVar[thirdVar.length] = secondVar[i] в цикле 0 <= i < secondVar.length)
Создалось такое ощущение, что человек, проводивший собеседование, хотел кому-то показать, что «он знает даже такие мелочи» (наверное, своей сотруднице, сидевшей рядом). Я подобных сравнений не проводил, и ни разу не сталкивался с ситуацией, когда на javascript нужно создать строковую переменную на пару мегабайт. К тому же, если представить код, в котором «a»+«b» заменены на for(var i=0; i<b.length; i++){a[a.length]=b[i];}…
В общем, мораль сей басни такова: «нет смысла судить о навыках человека по количеству 'костылей', о которых он слышал»
Что быстрее сработает бля объединения двух строк:
1. Всем привычное firstVar+secondVar;
2. Поочередное добавление каждого символа второй строки в конец первой (что-то в роде thirdVar[thirdVar.length] = secondVar[i] в цикле 0 <= i < secondVar.length)
Создалось такое ощущение, что человек, проводивший собеседование, хотел кому-то показать, что «он знает даже такие мелочи» (наверное, своей сотруднице, сидевшей рядом). Я подобных сравнений не проводил, и ни разу не сталкивался с ситуацией, когда на javascript нужно создать строковую переменную на пару мегабайт. К тому же, если представить код, в котором «a»+«b» заменены на for(var i=0; i<b.length; i++){a[a.length]=b[i];}…
В общем, мораль сей басни такова: «нет смысла судить о навыках человека по количеству 'костылей', о которых он слышал»
Тут ответ простой и очевидный и от языка не зависит: явная конкатенация, ибо это обычный сценарий использования и именно его будут оптимизировать. Более того только он поддается простой оптимизации (выделение нужного количества памяти сразу, копирование массивов оптимизированным способом, etc).
Даже если в какой-то версии какого-то браузера быстрее поэлементное добавление, то завязываться на это не стоит — ситуация наверняка поменяется в будущем.
Даже если в какой-то версии какого-то браузера быстрее поэлементное добавление, то завязываться на это не стоит — ситуация наверняка поменяется в будущем.
UFO just landed and posted this here
Вопрос отличный. Собственно, я давно заметил, что тесты ругают те, кто на них отсеивается :-) Конечно, «я не тупой, это тест плохой».Заткнитесь, учите теорию и нарабатывайте практику (не обращаюсь ни к кому конкретно). Тогда и тесты легкими станут.
И каким образом вам знание отличия в скорости a+b от for(...) помогают делать правильные оценки, следовать стандартам разработки, учавствовать в совещаниях, писать юнит-тесты и генерировать высокопроизводительный код в сжатые сроки? Ну правда?
Я думаю тут важнее все таки будет понимание почему, или просто логически обоснованное предположение. Если человек не сможет предположить и обосновать свое предположение для такой простой вещи, то это уже будет показателем.
Именно так.
Одно дело — тест с выбором единственно правильного ответа, другое «а как вы думаете, ....?»
Знание правильного ответа и попытка, пусть и в неверном направлении, до него добраться — разные вещи. Поэтому мой вопрос остался тем же: «с чего вы решили, что прохождение теста помогает ....»
Знание правильного ответа и попытка, пусть и в неверном направлении, до него добраться — разные вещи. Поэтому мой вопрос остался тем же: «с чего вы решили, что прохождение теста помогает ....»
Из опыта. Я постоянно отбираю людей. И прохождение теста реально помогает :) Если человек плохо проходит тест, то и дальнейший разговор с ним в абсолютном большинстве случаев демонстрирует его некомпетентность. Впрочем, обратное неверно. Если тест пройден хорошо, то необязательно он подойдет. Но всё же корреляция успешности прохождения теста и собеседования в целом положительная.
Кстати, люди, которые пытаются спорить и настаивать, что тест — это плохо, собеседование обычно не проходят :) Они и в работе такие же — в команде работают плохо, часто пытаются сделать по-своему, ни с кем не посоветовавшись, упрямы и агрессивны.
Кстати, люди, которые пытаются спорить и настаивать, что тест — это плохо, собеседование обычно не проходят :) Они и в работе такие же — в команде работают плохо, часто пытаются сделать по-своему, ни с кем не посоветовавшись, упрямы и агрессивны.
Понятно что корреляция есть (вы точно не только постоянно отбираете людей, но и затем работаете с ними?) — если уж я запарился почитать про какие-то тонкости или тем более логически до них дошёл, то я как минимум понимаю, в какие ещё стороны можно копать в используемой мною технологии. И практически ничего не говорит о том, как глубоко я туда копнул.
Но всё же из-за моего упрямства и агрессивных нападок, мало кто сможет переубедить в том, что тесты на собеседовании — хорошо. Они очень сильно облегчают жизнь собеседующему, но очень легко (но не всегда) могут быть совершенно оторваны от реальности тем, что будут сконцентрированы на никому не нужном бреде (кроме ЭГО автора).
Но всё же из-за моего упрямства и агрессивных нападок, мало кто сможет переубедить в том, что тесты на собеседовании — хорошо. Они очень сильно облегчают жизнь собеседующему, но очень легко (но не всегда) могут быть совершенно оторваны от реальности тем, что будут сконцентрированы на никому не нужном бреде (кроме ЭГО автора).
Это уж, увы, нельзя достоверно проверить на коротком собеседовании.
Ваш стиль задач и формулировок похож на задачи с codility.com, только там больше упор на данные+алгоритмы и оценки сложности.
А задача про отвесную скалу видимо тестирует готовность к разговору в духе «что вы называете решением и о чем еще умолчали в условии»?
А задача про отвесную скалу видимо тестирует готовность к разговору в духе «что вы называете решением и о чем еще умолчали в условии»?
На мой взгляд не каждый программист все это в совершенстве должен знать.Очень сомнительно. Перечисленное — базовые знания (считай вопросы на джуниора). Если программист базой не обладает, то нафиг надо.
Я вот придумал такой вопрос на собеседование:
Дано: таблица задана набором ячеек. Для каждой ячейки известны её положение в таблице (строка, столбец) и занимаемое место (colspan, rowspan). Написать/описать алгоритм упрощения структуры таблицы, чтобы количество строк и столбцов в ней было минимально возможным. Например:
Дана таблица 4x5 состоящая из 6 ячеек:

Необходимо алгоритмически определить те строки и столбцы, которые можно безболезненно объединить:
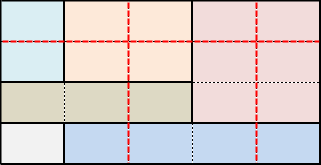
И в итоге получить таблицу 3x3 с тем же набором ячеек:
Как думаете, реально ли за час-два придумать хороший алгоритм? Поможет ли такая задача оценить навыки программиста?
P.S. Это реальная задача из одного проекта. Очень быстрое решение у меня есть.
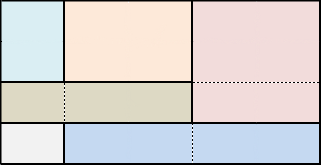
Дано: таблица задана набором ячеек. Для каждой ячейки известны её положение в таблице (строка, столбец) и занимаемое место (colspan, rowspan). Написать/описать алгоритм упрощения структуры таблицы, чтобы количество строк и столбцов в ней было минимально возможным. Например:
Дана таблица 4x5 состоящая из 6 ячеек:

Необходимо алгоритмически определить те строки и столбцы, которые можно безболезненно объединить:

И в итоге получить таблицу 3x3 с тем же набором ячеек:

Как думаете, реально ли за час-два придумать хороший алгоритм? Поможет ли такая задача оценить навыки программиста?
P.S. Это реальная задача из одного проекта. Очень быстрое решение у меня есть.
Или я к полуночи совсем не соображаю или тут нечего делать.
case class Cell(col: Int, row: Int, colspan: Int, rowspan: Int)
val allCells: Set[Cell] = ???
val usedRows = allCells.map{ c => c.row + c.rowspan - 1 }
val usedColumns = allCells.map{ c => c.col + c.colspan - 1 }
val maxRow = usedRows.max
val maxCol = usedColumns.max
// Эти удалить:
val notUsedRows = (1 until maxRow) filterNot usedRows
val notUsedColumns = (1 until maxCol) filterNot usedColumns
Если заранее известно количество строк и столбцов то еще проще:
val allCells: Set[Cell] = ???
val maxRow:Int = ???
val maxCol:Int = ???
val (notUsedRows, notUsedColumns) = allCells.foldLeft( (1 until maxRow).toSet -> (1 until maxCol).toSet ){
case ((rs, cs), c) => (rs - (c.row + c.rowspan - 1), cs - (c.col + c.colspan - 1))
}
Никогда не программировал на Scala, но алгоритм, вроде, правильный.
Я бы определял
Если заранее известно количество строк и столбцов ...
Я бы определял
usedRows и usedColumns вот так:case class Cell(col: Int, row: Int, colspan: Int, rowspan: Int)
val allCells: Set[Cell] = ???
val maxRow = ???
val maxCol = ???
val usedRows = allCells.map{ c => c.row }
val usedColumns = allCells.map{ c => c.col }
// Эти удалить:
val notUsedRows = (1 until maxRow) filterNot usedRows
val notUsedColumns = (1 until maxCol) filterNot usedColumns
Можно, конечно, придумывать что-нибудь кустарное, а можно свести задачу к выделению компонент связности графа — главное тут ребра правильно расставить. Т.к. ребер будет не более чем 4*<кол-во клеток> (вроде бы), то решаться она будет за O(<кол-во клеток>) = O(cols*rows).
UFO just landed and posted this here
UFO just landed and posted this here
Хочется узнать все же результаты такого подхода к найму. Устроили ли топикастера выбранные таким образом кандидаты? Чем они отличались от тех, кого нанимали до этого? Показали ли себя на реальных задачах?
Результаты такие: я взял первого человека, который справился с заданием. И он оказался чертовски толковый парень. Не могу сейчас точно сказать, было ли это просто совпадение или задачки все же помогли его выявить, но факт остается фактом. За все продолжительное время совместной работы не было никаких нареканий с моей стороны. Практика восторжествовала, задачи делались, программы работали, что там было внутри и как написано, я не знаю, другие люди смотрели за качеством кода.
По поводу отличия от других, думаю не совсем корректно сравнивать, люди все разные, и вряд ли дело в решенных задачах, но этот парень был человеком дела, про которого я всегда говорил, что вот пример, когда важен результат, а не процесс.
И еще добавлю, на собеседовании справиться с этим заданием сложнее, чем здесь, в обсуждении статьи, там и стресс, и другая рабочая среда, и результат надо выдать, а любой неправильный SQL запрос может завесить базу на долгое время, а у меня нет прав остановить процесс, значит нужно сделать тестовые таблички или ограниченные выборки, чтобы проверить решение, потом наращивать объемы и наблюдать за процессом, потом исправлять. Т.е. задача намного показательнее, чем кажется на первый взгляд, особенно когда начинаешь ее делать на реальных данных, а не на 5 строчках.
По поводу отличия от других, думаю не совсем корректно сравнивать, люди все разные, и вряд ли дело в решенных задачах, но этот парень был человеком дела, про которого я всегда говорил, что вот пример, когда важен результат, а не процесс.
И еще добавлю, на собеседовании справиться с этим заданием сложнее, чем здесь, в обсуждении статьи, там и стресс, и другая рабочая среда, и результат надо выдать, а любой неправильный SQL запрос может завесить базу на долгое время, а у меня нет прав остановить процесс, значит нужно сделать тестовые таблички или ограниченные выборки, чтобы проверить решение, потом наращивать объемы и наблюдать за процессом, потом исправлять. Т.е. задача намного показательнее, чем кажется на первый взгляд, особенно когда начинаешь ее делать на реальных данных, а не на 5 строчках.
>И еще добавлю, на собеседовании справиться с этим заданием сложнее, чем здесь, в обсуждении статьи, там и стресс, и другая рабочая среда
Мне потому и интересно, что разработчики обычно все же работают не в условиях стресса и в привычной рабочей среде.
Мне потому и интересно, что разработчики обычно все же работают не в условиях стресса и в привычной рабочей среде.
Так стресс может быть просто от того, что человек на собеседовании, что сейчас предстоит что-то сделать и показать себя, т.е. страх упасть лицом в грязь. Это как приходишь на олимпиаду, экзамен, всегда какое-то волнение, что делает человека более рассеяным, хотя кого-то, наоборот, собирает.
Другая рабочая среда — это версии программ, настройки, оборудование, например, вы привыкли дома работать на большом мониторире и у вас темная тема со светлыми буквами, а тут вам дали ноутбук с менее удобной клавиатурой, там выставлены другие цветовые схемы, и другая версия софта. Вот уже дискомфорт. А все это играет роль. Ну и мы тоже не будем подбирать настройки под каждого собеседующегося, вот возьмем на работу, тогда и настроим как вам угодно.
Другая рабочая среда — это версии программ, настройки, оборудование, например, вы привыкли дома работать на большом мониторире и у вас темная тема со светлыми буквами, а тут вам дали ноутбук с менее удобной клавиатурой, там выставлены другие цветовые схемы, и другая версия софта. Вот уже дискомфорт. А все это играет роль. Ну и мы тоже не будем подбирать настройки под каждого собеседующегося, вот возьмем на работу, тогда и настроим как вам угодно.
Один я не понял, почему в первой задаче, где требование сформулировано как «Нужно получить единую таблицу со всеми словами и соответствующими им ссылками.», правильным ответом являются две результирующие таблицы? На что также намекает комментарий «для одних и тех же слов ссылки в разных таблицах могут быть разные, т.к. словари были загружены из разных мест». И при этом первый вопрос к собеседующему будет «вы хотите увидеть дубли слова, когда в разных таблицах оно имеет разные ссылки?».
Не помню где услышал такую теорию, но она мне очень помогла, как со стороны работодателя, так и со стороны работника.
Не важно кого ищет работодатель бухгалтера или управляющего, оценивая кандидата он отвечает для себя на 3 вопроса:
1. Квалификация — может ли кандидат решать требуемые задачи, достаточна ли его квалификация.
2. Мотивация — хочет ли кандидат работать у работодателя, на сколько он в этом заинтересован, на сколько у него хватит запала.
3. Свой-чужой — подходит ли кандидат для коллектива, для руководителя, сможет ли он стать «своим» в ближайшее время.
О квалификации говорят в первую очередь, и это очень важный показатель, и его надо проявлять во всей красе.
О мотивации, говорят косвенно, «чем не устроило предыдущее место работы», «почему хотите работать у нас», «а кем вы видите себя через 5 лет» и т.п. Все вопросы такого рода надо сводить к тому что у вас в одном месте работает ядерный реактор, и вы просто не знаете куда девать его энергию.
Свой-чужой — это в первую очередь форма и атрибуты. То что ненавязчиво выдаст в вас «своего». Здесь уместно правило «по одежке встречают». Одежка должна быть такая же (имеется в виду стиль) как и у тех кто проводит интервью. Покажите признаки профессиональной деформации, даже если у вас их нет. Допустим профессиональный жаргон, причем не только из области своей компетенции, но и из области компании в целом. Одно дело устраиваться программистом в банк, и другое дело программистом в книжное издательство — отрасли разные, используемый словарь разный.
Так вот, что интересно, как правило, выбирают кандидата, (как собственно и машину иiPhone смартфон) иррационально, подводя уже потом под решение рациональную базу.
Так что, если вы кандидат, ваша основная задача показать дикую мотивацию, и мимикрировать под «своего».
Если вы работодатель, ваша задача трезво отдавать себе отчет, почему вы даете предпочтение одному а не другому, ваша задача гораздо сложнее чем у кандидата.
Не важно кого ищет работодатель бухгалтера или управляющего, оценивая кандидата он отвечает для себя на 3 вопроса:
1. Квалификация — может ли кандидат решать требуемые задачи, достаточна ли его квалификация.
2. Мотивация — хочет ли кандидат работать у работодателя, на сколько он в этом заинтересован, на сколько у него хватит запала.
3. Свой-чужой — подходит ли кандидат для коллектива, для руководителя, сможет ли он стать «своим» в ближайшее время.
О квалификации говорят в первую очередь, и это очень важный показатель, и его надо проявлять во всей красе.
О мотивации, говорят косвенно, «чем не устроило предыдущее место работы», «почему хотите работать у нас», «а кем вы видите себя через 5 лет» и т.п. Все вопросы такого рода надо сводить к тому что у вас в одном месте работает ядерный реактор, и вы просто не знаете куда девать его энергию.
Свой-чужой — это в первую очередь форма и атрибуты. То что ненавязчиво выдаст в вас «своего». Здесь уместно правило «по одежке встречают». Одежка должна быть такая же (имеется в виду стиль) как и у тех кто проводит интервью. Покажите признаки профессиональной деформации, даже если у вас их нет. Допустим профессиональный жаргон, причем не только из области своей компетенции, но и из области компании в целом. Одно дело устраиваться программистом в банк, и другое дело программистом в книжное издательство — отрасли разные, используемый словарь разный.
Так вот, что интересно, как правило, выбирают кандидата, (как собственно и машину и
Так что, если вы кандидат, ваша основная задача показать дикую мотивацию, и мимикрировать под «своего».
Если вы работодатель, ваша задача трезво отдавать себе отчет, почему вы даете предпочтение одному а не другому, ваша задача гораздо сложнее чем у кандидата.
ой
В первой половине мы прочитали выводы из 10-летней давности статьи Сполски «Искусство проведения интервью». Во второй вопросы по БД.
Познавательно.
Познавательно.
Задача отсюда
По-моему давать задачи отсюда гораздо эффективнее
Так это же задачи по математике, а не программированию. Что неплохо, но про другое. Разве что вы выбираете сотрудника в проект, где математики как раз много.
Ну математика здесь не сильная, я бы даже сказал школьная, так что это задачки на оптимальное решение. Это в первую очередь позволит понять насколько быстро и хорошо кандидат подбирает решения.
Ну вот возьмем такую задачку с первой же страницы: projecteuler.net/problem=46
Я бы не сказал, что это школьная математика. Вернее так: по Арнольду, такое и в 6 классе решать можно. Можно, если у тебя преподаватель — Арнольд, и школа типа ФМШ. Но мы же вроде как не социальным снобизмом заниматься хотим, а конкретные навыки проверить.
Возьмем меня, выпускника математического факультета одного сибирского вуза, с опытом работы постдоком последние 4 года. У меня голова забита задачами другой тематики и чтоб голову переключить на задачу нумер 46 по ссылке, нужно сосредоточенно потратить сколько-то времени. Я вот сейчас условие прочитал и понял что мгновенно даже идеи решения не приходит. Значит, нужно отложить в сторону на «подумать». В обстановке собеседования же времени на переключение контекста — нет.
Я бы не сказал, что это школьная математика. Вернее так: по Арнольду, такое и в 6 классе решать можно. Можно, если у тебя преподаватель — Арнольд, и школа типа ФМШ. Но мы же вроде как не социальным снобизмом заниматься хотим, а конкретные навыки проверить.
Возьмем меня, выпускника математического факультета одного сибирского вуза, с опытом работы постдоком последние 4 года. У меня голова забита задачами другой тематики и чтоб голову переключить на задачу нумер 46 по ссылке, нужно сосредоточенно потратить сколько-то времени. Я вот сейчас условие прочитал и понял что мгновенно даже идеи решения не приходит. Значит, нужно отложить в сторону на «подумать». В обстановке собеседования же времени на переключение контекста — нет.
У меня голова забита задачами другой тематикину знаете. В этом смысл работы — переключатся на нужную задачу и думать как её решить. Или Вы объясняете боссу о некоторых задачах — что вы не можете их сделать в срок или сделать вообще — потому что голова другим забита, и вам нужно сосредоточится? Это несерьезно. Так же несреьезно как думать что к каждой задаче надо сходу решение находить. Я думаю мало кого волнует что вы делали последние 4 года или вчера вечером и чем у вас голова забита. Если задача есть её надо решать, возможно долго и сложно — но именно отсюда знания и берутся.
Нельзя объять необъятное — рано или поздно попадется задача которую вы не знаете как решать и с точки зрения нанимателя — будет лучше если она попадется на уровне собеседование — вас сразу же можно будет оценить в интересной рабочей ситуации.
И в конце концов на собеседоваиях в основном хотят увидеть как вы решаете задачи, а не решение, ход ваших мыслей и рассуждений.
Честно говоря я не понимаю, почему вы формулируете возражение, при том что излагаете то же самое, что я говорил. Я об этом:
Верно, именно это я имел ввиду под переключением контекста.
Мне кажется, вы смешиваете качественно различные горизонты времени. Если нужно решить задачу за полчаса, то проверяется сухой остаток, то что вы можете сделать даже будучи разбуженным в 3 ночи. Если нужно решить задачу за полдня, то есть время пойти пить чай/кофе и мнэ, вытащить когда-то актуальный инструментарий с нужной полки подсознания в актуальную память. После чего вы вполне сможете решить эту задачу за полчаса, но без процесса переключения у вас это не получится. По крайней мере, у меня так. Если вы держите все чего когда-либо касались с 3хлетнего возраста в актуальной памяти — я вам и завидую, и нет одновременно.
Почему-то вы не хотите признать простой вещи: на собеседовании вам времени на переключение контекста не дадут.
Вот этого
я вообще не понял. Как можно «увидеть как вы решаете задачи», если не наблюдать «решение, ход ваших мыслей и рассуждений»?
Так же несреьезно как думать что к каждой задаче надо сходу решение находить.
Верно, именно это я имел ввиду под переключением контекста.
Мне кажется, вы смешиваете качественно различные горизонты времени. Если нужно решить задачу за полчаса, то проверяется сухой остаток, то что вы можете сделать даже будучи разбуженным в 3 ночи. Если нужно решить задачу за полдня, то есть время пойти пить чай/кофе и мнэ, вытащить когда-то актуальный инструментарий с нужной полки подсознания в актуальную память. После чего вы вполне сможете решить эту задачу за полчаса, но без процесса переключения у вас это не получится. По крайней мере, у меня так. Если вы держите все чего когда-либо касались с 3хлетнего возраста в актуальной памяти — я вам и завидую, и нет одновременно.
Почему-то вы не хотите признать простой вещи: на собеседовании вам времени на переключение контекста не дадут.
Вот этого
И в конце концов на собеседоваиях в основном хотят увидеть как вы решаете задачи, а не решение, ход ваших мыслей и рассуждений.
я вообще не понял. Как можно «увидеть как вы решаете задачи», если не наблюдать «решение, ход ваших мыслей и рассуждений»?
За последнее предложение извините — я русский забываю по-тихоньку.
«И в конце концов на собеседоваиях в основном хотят увидеть как вы решаете задачи, ход ваших мыслей и рассуждений, а не решение,»
Вы по-моему не понимаете, что увидеть как человек думает можно и не давая ему пол дня и литр кофе. На собседовании наблюдают за процессом нахождения решения. Я думаю если вы просто начнете рассуждать и показывать как бы вы стали находить решение — это уже было сказало о вас в очень положительном свете. Когда дают такие задачи — никто не требует от вас решить её за полчаса. Хотят увидеть зод ваших мыслей — вы же исходя из вашего поста выше отказываетесь даже думать о задача пока вам не дадут кучу времени и очень комфортную обстановку.
«И в конце концов на собеседоваиях в основном хотят увидеть как вы решаете задачи, ход ваших мыслей и рассуждений, а не решение,»
Вы по-моему не понимаете, что увидеть как человек думает можно и не давая ему пол дня и литр кофе. На собседовании наблюдают за процессом нахождения решения. Я думаю если вы просто начнете рассуждать и показывать как бы вы стали находить решение — это уже было сказало о вас в очень положительном свете. Когда дают такие задачи — никто не требует от вас решить её за полчаса. Хотят увидеть зод ваших мыслей — вы же исходя из вашего поста выше отказываетесь даже думать о задача пока вам не дадут кучу времени и очень комфортную обстановку.
Хм. Тут я с вами согласен, посмотреть как человек размышляет лучше всего. Но есть нюансы, ради которых я в беседу и ввязался. Начать с того, что желания собеседователя не всегда можно угадать заранее, а от этого зависит оптимальная стратегия подачи. Nothing personal, just business. Если исходить из посыла топикстартера, то проверять следует не «как думал», а наоборот «секундомер закончил отсчитывать, решения нет? Следующий!» Перед таким собеседователем разлиться соловьем о том, как ты выбираешь метод решения исходя из первых проверок условия — кажется это гарантированный способ завалить беседу.
В качестве наглядного примера советую сходить по вот такой ссылке codility.com/demo/take-sample-test/epsilon2011/ и попробовать пройти тест за жестко указанное время. Говоря попросту: у меня на днях не получилось. При том, что о вычислительной геометрии я в курсе, но она не в активном багаже. Вот такая же петрушка и произойдет на собеседовании, когда к вам придет программист с готовностью на скорость щелкать задачи олимпиадного программирования, а вы ему подсовываете задачу, требующую размеренного размышления в совершенно другой стилистике. Или наоборот. Просто надо понимать, что бывают качественно различные стили мышления и странно проверять умение играть на музыкальных инструментах при приеме на работу на стройку.
Но еще раз, если у вас идет разработка научного софта, все что я тут говорю не релеватно и вопросы с projecteuler хорошие.
В качестве наглядного примера советую сходить по вот такой ссылке codility.com/demo/take-sample-test/epsilon2011/ и попробовать пройти тест за жестко указанное время. Говоря попросту: у меня на днях не получилось. При том, что о вычислительной геометрии я в курсе, но она не в активном багаже. Вот такая же петрушка и произойдет на собеседовании, когда к вам придет программист с готовностью на скорость щелкать задачи олимпиадного программирования, а вы ему подсовываете задачу, требующую размеренного размышления в совершенно другой стилистике. Или наоборот. Просто надо понимать, что бывают качественно различные стили мышления и странно проверять умение играть на музыкальных инструментах при приеме на работу на стройку.
Но еще раз, если у вас идет разработка научного софта, все что я тут говорю не релеватно и вопросы с projecteuler хорошие.
Кстати, задача с верёвкой усложнена — гораздо проще её решить было бы, если бы речь шла о 75 метрах.
Вообще, мне одному кажется, что задачи на БД довольно простые?
При устройстве на последние две работы были технические тесты по часу. Лично мне такой подход нравится больше, чем тратить время на бессмысленные разговоры с HR.
Вот что я не понимаю, так чем тестовое задание лучше чем код на GitHub? За час будет проверка непонятно чего, на мелкой задаче, и тд. Зачем?
Sign up to leave a comment.
Две задачки для собеседования разработчиков