Comments 8
Однако, если мы проведем ЛСА, то веса у «аккумулятора» и «батарейки» выровняются, и эти сообщения можно будет объединить на основе хотя и слабого критерия, но наиболее важного для товара критерия.
Слова «аккумулятор» и «батарейка» часто встречаются в аналогичных контекстах. В частности, они часто встречаются при обсуждении мобильных телефонов, и практически никогда — при обсуждении автомобилей. Поэтому, мы можем говорить о подобии этих слов для контекста, связанного с мобильниками, и существенном различии этих слов для контекста, связанного с автомобилями.
Другими словами — мы можем выстроить контекстно-зависимую метрику между словами — в виде степени подобия между ними.
Сообщения, содержащие подобные друг-другу слова на аналогичных синтаксических позициях — говорят об одном и том-же. То есть, имеют близкий смысл.
Сообщения, содержащие подобные друг-другу слова на аналогичных синтаксических позициях — говорят об одном и том-же. То есть, имеют близкий смысл.
— это, разумеется, неверно.
Для того, чтобы различать «батарейку» и «аккумулятор» в разных тематиках можно:
1) строить тематические модели, т.е. на каждую тему своя модель;
2) построить одну модель, но в качестве документа при преобразовании использовать тематически однородный материал.
— это, разумеется, неверно.
Весьма сильное и провокационное заявление. Впрочем, я потому и писал про «контекстно-зависимую» метрику, что метрика зависит от тематики.
С чем не соглашусь — так это с идеей, что тематику необходимо определять или ограничивать вручную. Тематику можно определять автоматически — это достаточно легко формулируемая задача кластеризации.
Согласен, тематику нужно определять автоматически. Не сказал бы, это простая задача: легко кластеризовать тематику кулинария, и, скажем, автомобили, но кластеризовать поток новостей, например, на 30-50 тематик с точностью хотя бы 85-90% — задача не из легких.
Если мы говорим про контекстную зависимость, например, подключаем н-граммы, то это уже не только синтаксис, а и примитивная семантика. Да, так будет работать, даже с неплохой точностью, но не очень хорошим покрытием. Использование синтаксиса в чистом виде для языков грамматического типа, как нами употребляемый, мало что даст.
И главное, это зависит от решаемой задачи: искать синонимы, пополнять тезаурусы — это да, есть методы и попроще. ЛСА — это не метод классификации или кластеризации (ибо тяжеловат он для этого). Его используют, когда нужно получить меру ассоциативной близости двух разнородных лексически, но однородных семантичеки документов, например. Или построить ассоциативно-семантичесукую сеть.
Если мы говорим про контекстную зависимость, например, подключаем н-граммы, то это уже не только синтаксис, а и примитивная семантика. Да, так будет работать, даже с неплохой точностью, но не очень хорошим покрытием. Использование синтаксиса в чистом виде для языков грамматического типа, как нами употребляемый, мало что даст.
И главное, это зависит от решаемой задачи: искать синонимы, пополнять тезаурусы — это да, есть методы и попроще. ЛСА — это не метод классификации или кластеризации (ибо тяжеловат он для этого). Его используют, когда нужно получить меру ассоциативной близости двух разнородных лексически, но однородных семантичеки документов, например. Или построить ассоциативно-семантичесукую сеть.
Сообщения, содержащие подобные друг-другу слова на аналогичных синтаксических позициях — говорят об одном и том-же. То есть, имеют близкий смысл.
— это, разумеется, неверно.
Контрпримеры подобрать, разумеется, несложно. Но, похоже, это чаще верно, чем неверно.
Увы, LSA очень медленный при большом числе категорий, и высокого качества с его помощью получить почему-то не удаётся.
Про code.google.com/p/word2vec/ и www.socher.org/index.php/DeepLearningTutorial/DeepLearningTutorial планируете рассказать в следующих частях?
Про code.google.com/p/word2vec/ и www.socher.org/index.php/DeepLearningTutorial/DeepLearningTutorial планируете рассказать в следующих частях?
Согласен, метод не быстрый, но, наряду с DLA, позволяет решать задачи, которые не могут решить другие алгоритмы.
В следующих частях хотелось бы подробнее остановиться на технических деталях, объяснить принцип работы алгоритма и рассказать, как его реализовать.
В следующих частях хотелось бы подробнее остановиться на технических деталях, объяснить принцип работы алгоритма и рассказать, как его реализовать.
Ага, пишите обязательно. Интересно, что это за задачи :)
Я-то ближе к лингвистике, а там RNN убедительно обгоняет LSA:
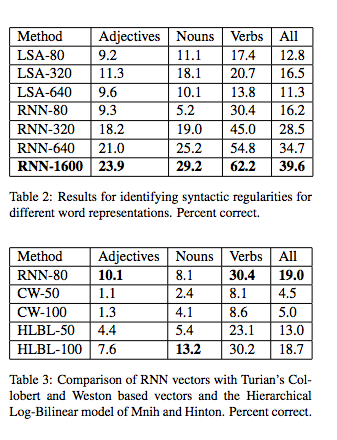
(из работы research.microsoft.com/pubs/189726/rvecs.pdf )
Я-то ближе к лингвистике, а там RNN убедительно обгоняет LSA:

(из работы research.microsoft.com/pubs/189726/rvecs.pdf )
Sign up to leave a comment.
Латентно-семантический анализ и искусственный интеллект (ЛСА и ИИ)