Привет, Хабр! Представляю вашему вниманию перевод статьи "Detecting Sarcasm with Deep Convolutional Neural Networks" автора Elvis Saravia.

Одна из ключевых проблем обработки естественного языка — обнаружение сарказма. Обнаружение сарказма важно в других областях, таких как эмоциональные вычисления и анализ настроений, поскольку это может отражать полярность предложения.
В этой статье показано, как обнаружить сарказм и также приведена ссылка на нейросетевой детектор сарказма.
Сарказм можно рассматривать как выражение язвительной насмешки, либо иронию. Примеры сарказма: «Я работаю 40 часов в неделю, для того чтобы оставаться бедным», либо «Если больной очень хочет жить, врачи бессильны».
Чтобы понять и обнаружить сарказм, важно понять факты, связанные с событием. Это позволяет выявить противоречие между объективной полярностью (обычно отрицательной) и саркастическими характеристиками, переданными автором (обычно положительными).
Рассмотрим пример: «Мне нравится боль от расставания».
Трудно понять смысл, если в этом утверждении есть сарказм. В этом примере «Мне нравится боль» дает знание высказанного автором чувства (в данном случае положительного), а «расставание» описывает противоречивое чувство (отрицательное).
Другие проблемы, существующие в понимании саркастических высказываний, — это ссылка на несколько событий и необходимость извлечь большое количество фактов, здравого смысла и логических рассуждений.
«Сдвиг настроения» часто присутствует в общении, где имеется сарказм; таким образом, предлагается сначала подготовить модель настроения (на основе CNN) для извлечения признаков настроения. Модель выбирает локальные признаки в первых слоях, которые затем преобразуются в глобальные признаки на более высоких уровнях. Саркастические выражения специфичны для пользователя — некоторые пользователи используют больше сарказма, чем другие.
В предлагаемой модели для обнаружения сарказма используются, личностные признаки, признаки настроения и признаки, основанные на эмоциях. Набор детекторов составляет фрэймворк, предназначенный для обнаружения сарказма. Каждый набор признаков изучается отдельными предварительно обученными моделями.
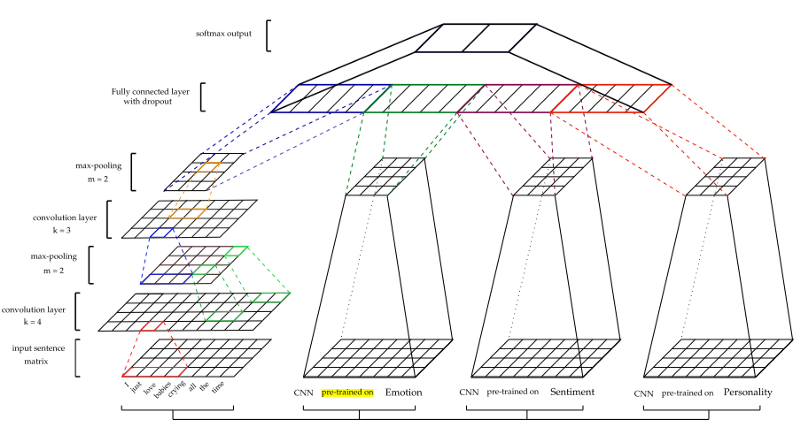
CNN эффективны при моделировании иерархии локальных признаков, чтобы выделить глобальные признаки, что необходимо для изучения контекста. Входные данные представлены в виде векторов слов. Для первичной обработки входных данных используется word2vec от Google. Параметры векторов получаются на этапе обучения. Максимальное объединение затем применяется к картам функций для создания функций. После полностью связанного слоя, идет слой softmax для получения окончательного предсказания.
Архитектура показана на рисунке ниже.

Для получения других особенностей — настроения (S), эмоций (E) и личности (P) — модели CNN проходят предварительную тренировку и используются для извлечения признаков из наборов данных сарказма. Для обучения каждой модели использовались разные учебные наборы данных. (Подробнее см. В документе)
Тестируются два классификатора — чистый CNN-классификатор (CNN) и CNN-извлеченные признаки, передаваемые в классификатор SVM (CNN-SVM).
Также обучается отдельный базовый классификатор (B), состоящий только из модели CNN без включения других моделей (например, эмоций и настроений).
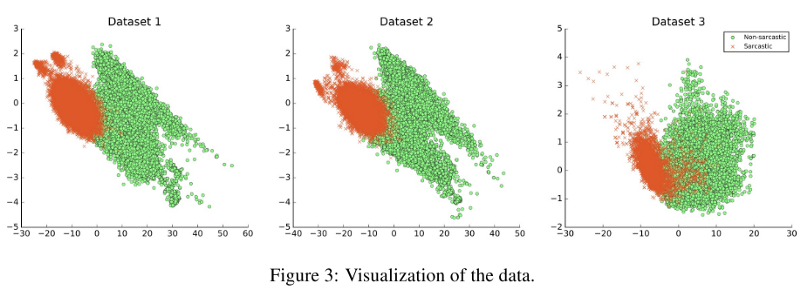
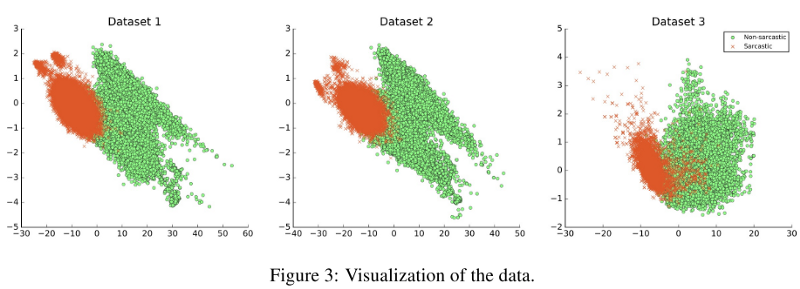
Данные. Сбалансированные и несбалансированные наборы данных были получены из (Ptacek et al., 2014) и детектора сарказма. Имена пользователей, URL-адреса и хэш-теги удаляются, затем применяется токенизатор NLTK Twitter.
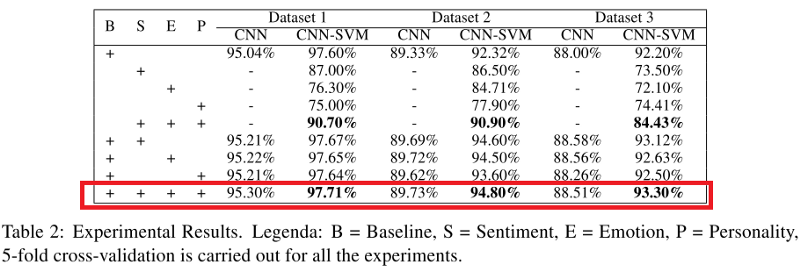
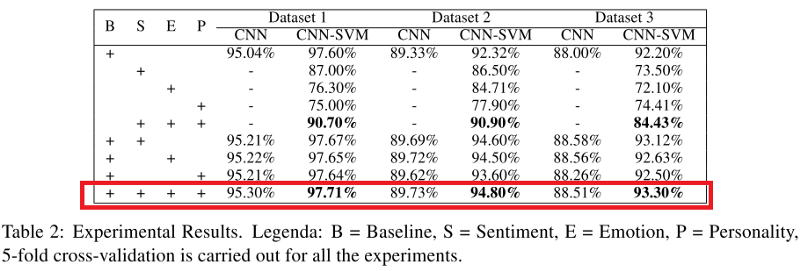
Показатели как CNN, так и CNN-SVM-классификатора, применяемые ко всем наборам данных, показаны в таблице ниже. Можно заметить, что, когда модель (в частности, CNN-SVM) сочетает в себе признаки сарказм, признаки эмоций, чувств и черты характера, она превосходит все другие модели, за исключением базовой модели (B).
Были опробованы возможности обобщаемости моделей, и основной вывод заключался в том, что если наборы данных отличались по своей природе, это существенно влияло на результатычто показано на рисунке ниже. Например, обучение проводилось по набору данных 1 и тестировалось по набору данных 2; F1-оценка модели составила 33,05%.
Одна из ключевых проблем обработки естественного языка — обнаружение сарказма. Обнаружение сарказма важно в других областях, таких как эмоциональные вычисления и анализ настроений, поскольку это может отражать полярность предложения.
В этой статье показано, как обнаружить сарказм и также приведена ссылка на нейросетевой детектор сарказма.
Сарказм можно рассматривать как выражение язвительной насмешки, либо иронию. Примеры сарказма: «Я работаю 40 часов в неделю, для того чтобы оставаться бедным», либо «Если больной очень хочет жить, врачи бессильны».
Чтобы понять и обнаружить сарказм, важно понять факты, связанные с событием. Это позволяет выявить противоречие между объективной полярностью (обычно отрицательной) и саркастическими характеристиками, переданными автором (обычно положительными).
Рассмотрим пример: «Мне нравится боль от расставания».
Трудно понять смысл, если в этом утверждении есть сарказм. В этом примере «Мне нравится боль» дает знание высказанного автором чувства (в данном случае положительного), а «расставание» описывает противоречивое чувство (отрицательное).
Другие проблемы, существующие в понимании саркастических высказываний, — это ссылка на несколько событий и необходимость извлечь большое количество фактов, здравого смысла и логических рассуждений.
Модель
«Сдвиг настроения» часто присутствует в общении, где имеется сарказм; таким образом, предлагается сначала подготовить модель настроения (на основе CNN) для извлечения признаков настроения. Модель выбирает локальные признаки в первых слоях, которые затем преобразуются в глобальные признаки на более высоких уровнях. Саркастические выражения специфичны для пользователя — некоторые пользователи используют больше сарказма, чем другие.
В предлагаемой модели для обнаружения сарказма используются, личностные признаки, признаки настроения и признаки, основанные на эмоциях. Набор детекторов составляет фрэймворк, предназначенный для обнаружения сарказма. Каждый набор признаков изучается отдельными предварительно обученными моделями.
CNN Framework
CNN эффективны при моделировании иерархии локальных признаков, чтобы выделить глобальные признаки, что необходимо для изучения контекста. Входные данные представлены в виде векторов слов. Для первичной обработки входных данных используется word2vec от Google. Параметры векторов получаются на этапе обучения. Максимальное объединение затем применяется к картам функций для создания функций. После полностью связанного слоя, идет слой softmax для получения окончательного предсказания.
Архитектура показана на рисунке ниже.
Для получения других особенностей — настроения (S), эмоций (E) и личности (P) — модели CNN проходят предварительную тренировку и используются для извлечения признаков из наборов данных сарказма. Для обучения каждой модели использовались разные учебные наборы данных. (Подробнее см. В документе)
Тестируются два классификатора — чистый CNN-классификатор (CNN) и CNN-извлеченные признаки, передаваемые в классификатор SVM (CNN-SVM).
Также обучается отдельный базовый классификатор (B), состоящий только из модели CNN без включения других моделей (например, эмоций и настроений).
Эксперименты
Данные. Сбалансированные и несбалансированные наборы данных были получены из (Ptacek et al., 2014) и детектора сарказма. Имена пользователей, URL-адреса и хэш-теги удаляются, затем применяется токенизатор NLTK Twitter.
Показатели как CNN, так и CNN-SVM-классификатора, применяемые ко всем наборам данных, показаны в таблице ниже. Можно заметить, что, когда модель (в частности, CNN-SVM) сочетает в себе признаки сарказм, признаки эмоций, чувств и черты характера, она превосходит все другие модели, за исключением базовой модели (B).
Были опробованы возможности обобщаемости моделей, и основной вывод заключался в том, что если наборы данных отличались по своей природе, это существенно влияло на результатычто показано на рисунке ниже. Например, обучение проводилось по набору данных 1 и тестировалось по набору данных 2; F1-оценка модели составила 33,05%.