Comments 6
Сам Google правильно говорит про свой Analytics, да и все аналитические системы: «Системы аналитики служат не для получения точных цифр, а для отслеживания трендов».
Интересная статья. Действительно, качество объявлений трудно оценивать и делать это следует по большому множеству показателей в контексте друг друга. В этом плане, Adwords удобнее сделан со своим «особенным» предложением ротации объявлений и функцией оптимизатора конверсий.
Интересная статья. Действительно, качество объявлений трудно оценивать и делать это следует по большому множеству показателей в контексте друг друга. В этом плане, Adwords удобнее сделан со своим «особенным» предложением ротации объявлений и функцией оптимизатора конверсий.
Я был увлечены подобными вопросами последний месяц или два, и ваша статья для меня выглядит фантастическим совпадением! Теперь буду знать, каким боком статистику к Adwords прикладывать. Спасибо!
Можно попробовать посмотреть на задачу сравнения двух рекламных объявлений со стороны Байесовской статистики и вероятностного вывода.
Конверсию можно рассматривать как случайную величину, имеющую распределение Бернулли и принимающую два значения: 1 (конверсия) и 0 (нет конверсии) с вероятностями p и q = 1 — p соответственно.
Рассмотрим задачу о нахождении распределения параметра p по имеющимся у нас наблюдениям конверсии с каждым визитом: x1,x2, ..., xN.
Сумма x1+x2+… +xN — это число конверсий при N визитах, она имеет биномиальное распредление с N степенями свободы и вероятностью конверсии p.
Как известно, для случайной величины, распредленной по закону Бернулли с неизвестным параметром p, в качестве сопряженного априорного распредления выступает бета-распредление (с параметрами альфа и бета). Параметры альфа и бета выбираются так, чтобы отразить имеющуюся априорную информацию — наше убеждение о распредлении параметра p перед размещением объявления.
Мы можем выбрать для параметра p альфа=бета=1 — это даст равномерное распределение. Это говорит о том, что наше убеждение относительно параметра p таково, что он равновероятно принимает значение в интервале от 0 до 1. Далее, в процессе поступления данных, мы будем обновлять бета-распределение для параметра p таким образом, что оно будет B(s+1, n-s+1), где s — число конверсий произошедших за последние n визитов.
Рассмотрим это на примере Ваших двух рекламых объявлений. По первому объявлению у нас имеется 143 визита и 3 конверсии, по второму — 184 визита и 5 конверсий.
Мы начали с полной неуверенности относительно параметра p — он подчиняется бета-распределению B(1,1), т.е. распределен равномерно в интервале от 0 до 1.
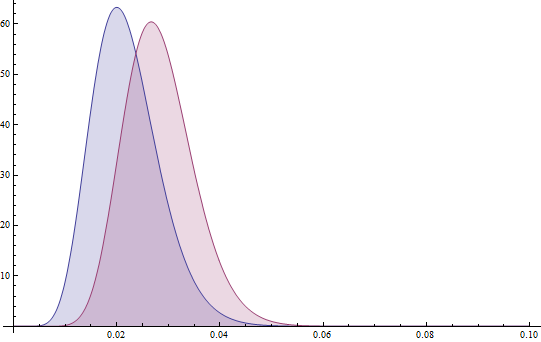
Для первого объявления после 143 визитов мы уточняем распредление вероятности p1 до B(4,141) (mean=0.02759), для второго объявления мы уточняем распредление вереоятности p2 до B(6, 180) (mean=0.03226). Если мы посмотрим на плотность распределения обоеих вероятностей p1 и p2, то увидим, что из равномерного они постепенно «превращаются» в нессиметричные колоколы (тот, что левее со средним 0.02759 соответствует распредлению B (4,141), тот, что правее соответствует распредлению B(6, 180) со средним 0.03226):

Итак, мы видим что оценка среднего значения вероятности для второго объявления выше. Исходя из оценок распредления вероятностей конверсии для обоих объявлений ответим на вопрос: с какой вероятностью процент конверсии второго объявления выше, чем процент конверсии первого объявления?
В лоб это вычисляется через интеграл:
N[Integrate[
PDF[BetaDistribution[6, 180], x]*
CDF[BetaDistribution[4, 141], x], {x, 0, 1}]]
В ответе получаем 0.6116. Т.е. с вероятностью 61.16% процент конверсии второго объявления выше, чем процент конверсии первого.
Предположим, что по прошествии какого-то времени, для первого объявления у нас имеется 500 визитов и 10 конверсий, для второго объявления у нас имеется 600 визитов и 16 конверсий. Тогда для процента конверсии по первому объявлению мы имеем распредление B(11,491) (mean=0.02191), а для второго B(17,585) (mean=0.02824).
А уверенность того, что процент конверсии второго объявления выше, чем первого возрастает до 75.50%.
Если продолжать наблюдения и дальше, то колокола будут сужаться и перемещаться, уточняя ожидаемое значение вероятности p, а «из колоколов» можно получить и доверительные интервалы, если нужно.
Также стоит обратить внимание, что ничего страшного не происходит в том случае, если конверсий не происходит. В этом случае колокол будет постепенно прижиматься к левому краю.
Если при 100 визитах не было конверсий, то имеем распредление Beta(1,101)[mean=0.009804]
Если при 100 визитах не было конверсий, то имеем распредление Beta(1,201)[mean=0.00495]
Ниже эти два случая на рисунке изображены.

Понятно, что если сравнивать такие случаи с другими объявлениями, где конверсии происходят, то уверенность в том, что в них конверсия выше, будет значительно больше.
Также никто не мешает нам начать не с равномерного распределение, а установить его, исходя из опыта прошлых рекламных кампаний.
Конверсию можно рассматривать как случайную величину, имеющую распределение Бернулли и принимающую два значения: 1 (конверсия) и 0 (нет конверсии) с вероятностями p и q = 1 — p соответственно.
Рассмотрим задачу о нахождении распределения параметра p по имеющимся у нас наблюдениям конверсии с каждым визитом: x1,x2, ..., xN.
Сумма x1+x2+… +xN — это число конверсий при N визитах, она имеет биномиальное распредление с N степенями свободы и вероятностью конверсии p.
Как известно, для случайной величины, распредленной по закону Бернулли с неизвестным параметром p, в качестве сопряженного априорного распредления выступает бета-распредление (с параметрами альфа и бета). Параметры альфа и бета выбираются так, чтобы отразить имеющуюся априорную информацию — наше убеждение о распредлении параметра p перед размещением объявления.
Мы можем выбрать для параметра p альфа=бета=1 — это даст равномерное распределение. Это говорит о том, что наше убеждение относительно параметра p таково, что он равновероятно принимает значение в интервале от 0 до 1. Далее, в процессе поступления данных, мы будем обновлять бета-распределение для параметра p таким образом, что оно будет B(s+1, n-s+1), где s — число конверсий произошедших за последние n визитов.
Рассмотрим это на примере Ваших двух рекламых объявлений. По первому объявлению у нас имеется 143 визита и 3 конверсии, по второму — 184 визита и 5 конверсий.
Мы начали с полной неуверенности относительно параметра p — он подчиняется бета-распределению B(1,1), т.е. распределен равномерно в интервале от 0 до 1.
Для первого объявления после 143 визитов мы уточняем распредление вероятности p1 до B(4,141) (mean=0.02759), для второго объявления мы уточняем распредление вереоятности p2 до B(6, 180) (mean=0.03226). Если мы посмотрим на плотность распределения обоеих вероятностей p1 и p2, то увидим, что из равномерного они постепенно «превращаются» в нессиметричные колоколы (тот, что левее со средним 0.02759 соответствует распредлению B (4,141), тот, что правее соответствует распредлению B(6, 180) со средним 0.03226):

Итак, мы видим что оценка среднего значения вероятности для второго объявления выше. Исходя из оценок распредления вероятностей конверсии для обоих объявлений ответим на вопрос: с какой вероятностью процент конверсии второго объявления выше, чем процент конверсии первого объявления?
В лоб это вычисляется через интеграл:
N[Integrate[
PDF[BetaDistribution[6, 180], x]*
CDF[BetaDistribution[4, 141], x], {x, 0, 1}]]
В ответе получаем 0.6116. Т.е. с вероятностью 61.16% процент конверсии второго объявления выше, чем процент конверсии первого.
Предположим, что по прошествии какого-то времени, для первого объявления у нас имеется 500 визитов и 10 конверсий, для второго объявления у нас имеется 600 визитов и 16 конверсий. Тогда для процента конверсии по первому объявлению мы имеем распредление B(11,491) (mean=0.02191), а для второго B(17,585) (mean=0.02824).

А уверенность того, что процент конверсии второго объявления выше, чем первого возрастает до 75.50%.
Если продолжать наблюдения и дальше, то колокола будут сужаться и перемещаться, уточняя ожидаемое значение вероятности p, а «из колоколов» можно получить и доверительные интервалы, если нужно.
Также стоит обратить внимание, что ничего страшного не происходит в том случае, если конверсий не происходит. В этом случае колокол будет постепенно прижиматься к левому краю.
Если при 100 визитах не было конверсий, то имеем распредление Beta(1,101)[mean=0.009804]
Если при 100 визитах не было конверсий, то имеем распредление Beta(1,201)[mean=0.00495]
Ниже эти два случая на рисунке изображены.

Понятно, что если сравнивать такие случаи с другими объявлениями, где конверсии происходят, то уверенность в том, что в них конверсия выше, будет значительно больше.
Также никто не мешает нам начать не с равномерного распределение, а установить его, исходя из опыта прошлых рекламных кампаний.
Спасибо большое за отличный комментарий и метод!
Спасибо за отличный комментарий!
Могли бы вы пояснить, как читать вот эту формулу в математических терминах?
N[Integrate[
PDF[BetaDistribution[6, 180], x]*
CDF[BetaDistribution[4, 141], x], {x, 0, 1}]]
Могли бы вы пояснить, как читать вот эту формулу в математических терминах?
N[Integrate[
PDF[BetaDistribution[6, 180], x]*
CDF[BetaDistribution[4, 141], x], {x, 0, 1}]]
Это формула записана в терминах Mathematica.
N[expr] — численно вычислить выражение expr.
Integrate[f, {x, xmin, xmax}] — интеграл функции f по х в интервале от xmin до xmax.
PDF[dist, x] — функция плотности вероятности для распределения dist в точке x.
CDF[dist,x] — функция распределения случайной величины для распределения dist в точке x.
BetaDistribution[alfa, beta] — непрерывное бета-распределение с параметрами alfa, beta.
N[expr] — численно вычислить выражение expr.
Integrate[f, {x, xmin, xmax}] — интеграл функции f по х в интервале от xmin до xmax.
PDF[dist, x] — функция плотности вероятности для распределения dist в точке x.
CDF[dist,x] — функция распределения случайной величины для распределения dist в точке x.
BetaDistribution[alfa, beta] — непрерывное бета-распределение с параметрами alfa, beta.
Sign up to leave a comment.
Веб-аналитика: Не все цифры одинаково полезны