Wuala, аналог заслуженно популярного Dropbox, известный своей политикой «облачного коммунизма» (сколько дискового пространства предоставишь — столько получишь места в облаке), меняет правила. Буквально пару часов назад я получил письмо следующего содержания:

User
Вышел Proxmox VE 2.0 beta!
2 min
Коллеги, у меня для вас сегодня очень хорошая новость. Вышла публичная бета второй версии великолепной свободной платформы виртуализации Proxmox VE. Если ранее Proxmox (версии 1.x) мог конкурировать с VMware при использовании в небольших компаниях, то сегодня он замахнулся как минимум на средние.
— Это свободная платформа виртуализации (Open Source, GNU AGPL v3)
— Это принцип KISS (Proxmox состоит из небольшого числа прозрачно взаимодействующих компонентов: Debian как основа, пропатченное ядро Linux, KVM и окружение Proxmox, которое включает в себя web-интерфейс, демон синхронизации и консольные утилиты управления)
— Это простая установка
— Это удобный и функциональный Web-интерфейс (без необходимости устанавливать клиент)
— Это надёжность
— Это возможность использования уже имеющихся навыков администрирования Linux, без необходимости переобучения
— Это возможность использования преимуществ Linux, которые могут быть и не предусмотрены Web-интерфейсом Proxmox VE (например DRBD)
Что же такое Proxmox?
— Это свободная платформа виртуализации (Open Source, GNU AGPL v3)
— Это принцип KISS (Proxmox состоит из небольшого числа прозрачно взаимодействующих компонентов: Debian как основа, пропатченное ядро Linux, KVM и окружение Proxmox, которое включает в себя web-интерфейс, демон синхронизации и консольные утилиты управления)
— Это простая установка
— Это удобный и функциональный Web-интерфейс (без необходимости устанавливать клиент)
— Это надёжность
— Это возможность использования уже имеющихся навыков администрирования Linux, без необходимости переобучения
— Это возможность использования преимуществ Linux, которые могут быть и не предусмотрены Web-интерфейсом Proxmox VE (например DRBD)
Обвал акций Яндекса, письмо инвесторам и Chrome
3 min
К сожалению, мимо Хабра прошла интересная история с первым крупным обвалом котировок Яндекса в минувшую среду. Восполним пробел.
Котировки отечественного поисковика рухнули на 13,1% — до $22,9 за акцию, что почти вдвое ниже максимальной рыночной цены в $42,01 за акцию после триумфального выхода на IPO в мае этого года.
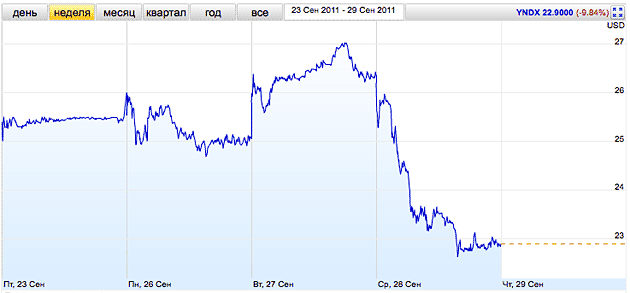
Снижение акций Яндекса было особенно заметно на фоне роста фондовых индексов США.
Котировки отечественного поисковика рухнули на 13,1% — до $22,9 за акцию, что почти вдвое ниже максимальной рыночной цены в $42,01 за акцию после триумфального выхода на IPO в мае этого года.
Снижение акций Яндекса было особенно заметно на фоне роста фондовых индексов США.
Microsoft Security Essentials удаляет Google Chrome, считая его PWS Win32/Zbot
1 min
 Сегодня один знакомый обратился ко мне за помощью. Пожаловался на то, что у него «слетел Хром» и он не может его установить. Вечером жена показала тот же «вирус» на своём нетбуке. Как оказалось, установленный у обоих жертв антивирус Microsoft Security Essentials решил, что нет места браузеру Google Chrome на компьютере, где есть IE, поэтому его стоит обозвать супер «вором паролей» и рекомендовать его снести :)
Сегодня один знакомый обратился ко мне за помощью. Пожаловался на то, что у него «слетел Хром» и он не может его установить. Вечером жена показала тот же «вирус» на своём нетбуке. Как оказалось, установленный у обоих жертв антивирус Microsoft Security Essentials решил, что нет места браузеру Google Chrome на компьютере, где есть IE, поэтому его стоит обозвать супер «вором паролей» и рекомендовать его снести :) StatCounter: в декабре Chrome обгонит Firefox и станет браузером № 2 в мире
2 min
По статистике StatCounter, браузер Chrome обгонит Firefox и выйдет на второе место в мире не позже, чем в конце декабря 2011 года. Пока что Chrome уступает несколько пунктов, но стабильный рост на протяжении всего 2011 года даёт возможность делать такой краткосрочный прогноз почти со 100%-ной вероятностью.
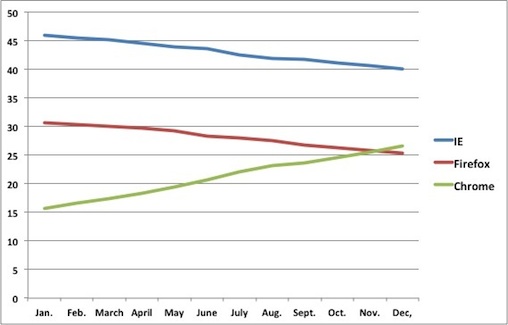
За текущий год Chrome прибавил около 50%, нарастив свою долю с 15% до 23%. За это же время Firefox растерял примерно 13% аудитории, а IE потерял 9% аудитории.
За текущий год Chrome прибавил около 50%, нарастив свою долю с 15% до 23%. За это же время Firefox растерял примерно 13% аудитории, а IE потерял 9% аудитории.
Методы борьбы с DDoS-атаками
5 min
Хотелось бы поговорить с вами на актуальную нынче тему, а именно — про DDoS и методы борьбы с ним. Рядовые администраторы знают, что это такое, а вот для большинства вебмастеров это аббревиатура остается загадкой до того момента пока они на личном опыте не столкнуться с этой неприятностью. Итак, DDoS — это сокращение от Distributed Denial of Service (распределенный отказ в обслуживании), когда тысячи зараженных компьютеров отправляют на сервер множество запросов, с которыми он, в последствии, не может справиться. Целью DDoS атаки является нарушение нормальной работы сервера, а в дальнейшем — «падение» сайта или сервера целиком.
Как же от этого защититься? К сожалению, универсальных мер защиты от DDoS-атак до сих пор не существует. Тут необходим комплексный подход, который будет включать меры аппаратного, программного и даже организационного характера.
Как же от этого защититься? К сожалению, универсальных мер защиты от DDoS-атак до сих пор не существует. Тут необходим комплексный подход, который будет включать меры аппаратного, программного и даже организационного характера.
Пошаговая стратегия как хобби
5 min

Привет, хабралюди! Кто из вас не мечтал создать свою игру? А возможно ли написать браузерную стратегию, не имея при этом опыта и денег? Возможно, если очень этого хотеть.
Под катом моя история создания бесплатной пошаговой стратегии.
Сетевая игра на bash: шахматы
5 min
Я давно хотел написать какую-нибудь сетевую игру на bash, причём желательно, чтобы управление было удобное, с клавиатуры, обычными курсорным клавишами. Вообще, тема интерактивного взаимодействия в bash глубже, чем «введите число, нажмите „Enter“» не раскопана. Мне пришлось всё изобретать и исследовать самостоятельно. Я очень старался найти что-то похожее по уровню интерактивности, но не нашёл.
Поскольку тонкости управления с клавиатурой съели очень много моего времени, я не стал заморачиваться с тонкостями совместимости, поэтому игра тестировалась только под Mac OS X, есть ненулевая вероятность, что она заработает и под Linux и уж точно её можно допилить там до рабочего состояния.
Для работы игра требует наличия nc (aka Netcat) и терминала с поддержкой 256 цветов (под Mac OS рекомендую iTerm2). При наличие интереса к игре, допилю до терминала на 16 цветов и /dev/tcp. Кстати начал выкладывать все свои шел-поделки на ГитХаб.
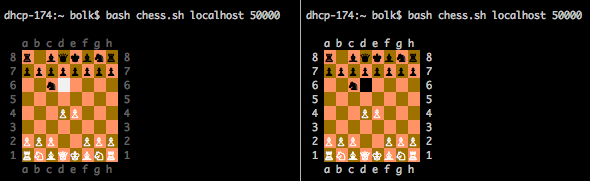
Так как игра сетевая, у неё требуется указать два параметра, о которых она расскажет, если её запустить без них. Первый — адрес машины противника, второй — порт. Порт выбирается одинаковым на обеих машинах. Игру можно запустить и на одной машине, в двух консолях (на скриншоте как раз такой случай).
Играть просто — в каждый момент времени активна только одна доска (на скриншоте — правая, у неё буквы и цифры вокруг доски ярче), на активной доске курсор двигается курсорными клавишами — ←, →, ↑ и ↓, взять фигуру и поставить её на доску — по клавише пробела или Enter. Как только вы поставили фигуру на доску, ход переходит к сопернику. «Съесть» фигуру соперника проще простого — достаточно поставить свою фигуру на чужую. В игре есть защита — нельзя «съесть» свою фигуру.
Ничего помимо этого в игре нет — не производится правильность контроля ходов, нет проверки на завершение игры, можно даже ходить фигурами соперника. Было очень сложно придумать как обрабатывать нажатия в shell, так что остальное сделать я просто не успел, не поместилось в формат «игрушка за вечер».
Я постарался снабдить свой код комментариями и писать достаточно структурировано, чтобы можно было разобраться как всё работает самостоятельно.
Поскольку тонкости управления с клавиатурой съели очень много моего времени, я не стал заморачиваться с тонкостями совместимости, поэтому игра тестировалась только под Mac OS X, есть ненулевая вероятность, что она заработает и под Linux и уж точно её можно допилить там до рабочего состояния.
Для работы игра требует наличия nc (aka Netcat) и терминала с поддержкой 256 цветов (под Mac OS рекомендую iTerm2). При наличие интереса к игре, допилю до терминала на 16 цветов и /dev/tcp. Кстати начал выкладывать все свои шел-поделки на ГитХаб.
Так как игра сетевая, у неё требуется указать два параметра, о которых она расскажет, если её запустить без них. Первый — адрес машины противника, второй — порт. Порт выбирается одинаковым на обеих машинах. Игру можно запустить и на одной машине, в двух консолях (на скриншоте как раз такой случай).
Играть просто — в каждый момент времени активна только одна доска (на скриншоте — правая, у неё буквы и цифры вокруг доски ярче), на активной доске курсор двигается курсорными клавишами — ←, →, ↑ и ↓, взять фигуру и поставить её на доску — по клавише пробела или Enter. Как только вы поставили фигуру на доску, ход переходит к сопернику. «Съесть» фигуру соперника проще простого — достаточно поставить свою фигуру на чужую. В игре есть защита — нельзя «съесть» свою фигуру.
Ничего помимо этого в игре нет — не производится правильность контроля ходов, нет проверки на завершение игры, можно даже ходить фигурами соперника. Было очень сложно придумать как обрабатывать нажатия в shell, так что остальное сделать я просто не успел, не поместилось в формат «игрушка за вечер».
Я постарался снабдить свой код комментариями и писать достаточно структурировано, чтобы можно было разобраться как всё работает самостоятельно.
Взаимодействие между несколькими .bat, мультиплеер на .bat
7 min
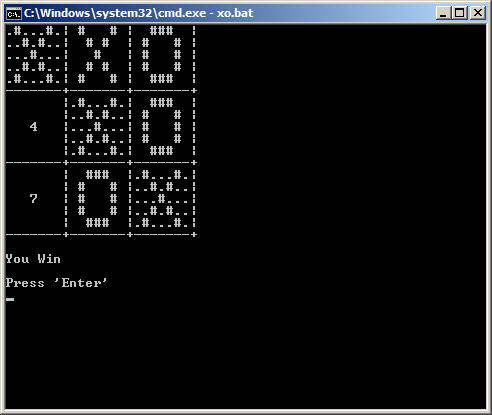
Бат-файлы лишены возможности передавать по сети какую-нибудь полезную информацию друг другу.
Организация памяти
7 min
За последнюю неделю дважды объяснял людям как организована работа с памятью в х86, с целью чтобы не объяснять в третий раз написал эту статью.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
И так, чтобы понять организацию памяти от вас потребуется знания некоторых базовых понятий, таких как регистры, стек и тд. Я по ходу попробую объяснить и это на пальцах, но очень кратко потому что это не тема для этой статьи. Итак начнем.
Получаем изображение с оптического сенсора комьютерной мыши с помощью Arduino
3 min

Для решения одной из задач мне потребовалось программно получать и обрабатывать изображения небольшого участка поверхности бумаги с очень близкого расстояния. Не получив достойного качества при использовании обычной USB камеры и уже на пол пути в магазин за электронным микроскопом, я вспомнил одну из лекций, на которой нам рассказывали как устроены различные девайсы, в том числе и компьютерная мышка.
Поисковые технологии или в чем загвоздка написать свой поисковик
3 min
Когда-то давно взбрела мне в голову идея: написать свой собственный поисковик. Было это очень давно, тогда я еще учился в ВУЗе, мало чего знал про технологии разработки больших проектов, зато отлично владел парой десятков языков программирования и протоколов, да и сайтов своих к тому времени было понаделано много.
Ну есть у меня тяга к монструозным проектам, да…
В то время про то, как они работают было известно мало. Статьи на английском и очень скудные. Некоторые мои знакомые, которые были тогда в курсе моих поисков, на основе нарытых и мной и ими документов и идей, в том числе тех, которые родились в процессе наших споров, сейчас делают неплохие курсы, придумывают новые технологии поиска, в общем, эта тема дала развитие довольно интересным работам. Эти работы привели в том числе к новым разработкам разных крупных компаний, в том числе Google, но я лично прямого отношения к этому не имею.
На данный момент у меня есть собственный, обучающийся поисковик от и до, со многими нюансами – подсчетом PR, сбором статистик-тематик, обучающейся функцией ранжирования, ноу хау в виде отрезания несущественного контента страницы типа меню и рекламы. Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
Ну есть у меня тяга к монструозным проектам, да…
В то время про то, как они работают было известно мало. Статьи на английском и очень скудные. Некоторые мои знакомые, которые были тогда в курсе моих поисков, на основе нарытых и мной и ими документов и идей, в том числе тех, которые родились в процессе наших споров, сейчас делают неплохие курсы, придумывают новые технологии поиска, в общем, эта тема дала развитие довольно интересным работам. Эти работы привели в том числе к новым разработкам разных крупных компаний, в том числе Google, но я лично прямого отношения к этому не имею.
На данный момент у меня есть собственный, обучающийся поисковик от и до, со многими нюансами – подсчетом PR, сбором статистик-тематик, обучающейся функцией ранжирования, ноу хау в виде отрезания несущественного контента страницы типа меню и рекламы. Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
С чего начинается поисковик, или несколько мыслей про crawler
3 min
В продолжение начатой темы про собственную поисковую машину
Итак есть несколько крупных задач, которые должна решить система поиска, начнем с того что отдельную страницу надо получить и сохранить.
Тут есть несколько способов, в зависимости от того, какие способы обработки Вы выберете в дальнейшем.
Очевидно, надо иметь очередь страниц, которые надо загрузить из web, хотя бы для того чтобы потом на них смотреть длинными зимними вечерами, если ничего лучшего не придумать. Я предпочитаю иметь очередь сайтов и их главных страниц, и локальную мини очередь того что я буду обрабатывать в данное время. Причина проста – список всех страниц которые я хотел бы загрузить просто за месяц – может существенно превысить объем моего немаленького винчестера :), поэтому я храню только то что действительно необходимо – сайты, их на данный момент 600 тысяч, и их приоритеты и времена загрузки.
Итак есть несколько крупных задач, которые должна решить система поиска, начнем с того что отдельную страницу надо получить и сохранить.
Тут есть несколько способов, в зависимости от того, какие способы обработки Вы выберете в дальнейшем.
Очевидно, надо иметь очередь страниц, которые надо загрузить из web, хотя бы для того чтобы потом на них смотреть длинными зимними вечерами, если ничего лучшего не придумать. Я предпочитаю иметь очередь сайтов и их главных страниц, и локальную мини очередь того что я буду обрабатывать в данное время. Причина проста – список всех страниц которые я хотел бы загрузить просто за месяц – может существенно превысить объем моего немаленького винчестера :), поэтому я храню только то что действительно необходимо – сайты, их на данный момент 600 тысяч, и их приоритеты и времена загрузки.
Немного про проектирование баз данных для поисковой машины
3 min
Без базы данных, даже без нескольких кардинально разных, такой проект невозможен. Поэтому немного посвящу времени этому вопросу.
Итак как минимум будет нужна БД обслуживающая обычные «плоские» («2D») данные – т.е. некоторому идентификатору ID ставится в соответствие поле данных.
Почему поле данных я рассматриваю одно? Потому что:
Если не задаваться задачей минимизации кол-ва строк кода работы с данными и немного удобством, то почти любую задачу можно свести к той, где эти пункты будут достаточны. И в случае таких высоких требований к оптимальности и скорости, по моему мнению это вполне оправдано.
Итак как минимум будет нужна БД обслуживающая обычные «плоские» («2D») данные – т.е. некоторому идентификатору ID ставится в соответствие поле данных.
Почему поле данных я рассматриваю одно? Потому что:
- выборка производится только по полю ID – поиск по данным не производится. Для этого есть специализированные индексы – иначе с такими количествами информации толку будет мало
- любое количество полей можно упаковать в одно, для этого я «на коленке» создал набор небольших прикладных библиотек, в частности при упаковке сохраняется CRC данных, чтобы не использовать не дай бог битые
Если не задаваться задачей минимизации кол-ва строк кода работы с данными и немного удобством, то почти любую задачу можно свести к той, где эти пункты будут достаточны. И в случае таких высоких требований к оптимальности и скорости, по моему мнению это вполне оправдано.
Построение индекса для поисковой машины
4 min
Полное содержание и список моих статей по поисковой машине будет обновлятся здесь.
В предыдущих статьях я рассказывал про работу поисковой машины, вот и дошел до сложного технически момента. Напомню что разделяют 2 типа индексов – прямой и обратный. Прямой – сопоставление документу списка слов в нем встреченного. Обратный – слову сопоставляется список документов, в которых оно есть. Логично, что для быстрого поиска лучше всего подходит обратный индекс. Интересный вопрос и про то, в каком порядке в списке хранить документы.
На предыдущем шаге DataFlow от модуля-индексатора мы получили кусочек данных в виде прямого индекса, ссылочной информации и информации о страницах. Обычно у меня он составляет около 200-300mb и содержит примерно 100 тысяч страниц. Со временем я отказался от стратегии хранения цельного прямого индекса, и храню только все эти кусочки + полный обратный индекс в нескольких версиях, чтобы можно было откатиться назад.
Устройство обратного индекса с виду, простое, – храним файл, в нем в начале таблица адресов начала данных по каждому слову, потом собственно данные. Это я утрировано. Так получается самый выгодный для оптимизации скорости поиска формат — не надо прыгать по страницам — как писали Брин и Пейдж, — 1 seek, 1 read. На каждой итерации перестроения, я использую 20-50 кусочков информации описанных выше, очевидно загрузить всю инфу из них в память я не могу, тем более что там полезно хранить еще кучу служебных данных об индексе.
В предыдущих статьях я рассказывал про работу поисковой машины, вот и дошел до сложного технически момента. Напомню что разделяют 2 типа индексов – прямой и обратный. Прямой – сопоставление документу списка слов в нем встреченного. Обратный – слову сопоставляется список документов, в которых оно есть. Логично, что для быстрого поиска лучше всего подходит обратный индекс. Интересный вопрос и про то, в каком порядке в списке хранить документы.
На предыдущем шаге DataFlow от модуля-индексатора мы получили кусочек данных в виде прямого индекса, ссылочной информации и информации о страницах. Обычно у меня он составляет около 200-300mb и содержит примерно 100 тысяч страниц. Со временем я отказался от стратегии хранения цельного прямого индекса, и храню только все эти кусочки + полный обратный индекс в нескольких версиях, чтобы можно было откатиться назад.
Устройство обратного индекса с виду, простое, – храним файл, в нем в начале таблица адресов начала данных по каждому слову, потом собственно данные. Это я утрировано. Так получается самый выгодный для оптимизации скорости поиска формат — не надо прыгать по страницам — как писали Брин и Пейдж, — 1 seek, 1 read. На каждой итерации перестроения, я использую 20-50 кусочков информации описанных выше, очевидно загрузить всю инфу из них в память я не могу, тем более что там полезно хранить еще кучу служебных данных об индексе.
Алкотестер от facebook
16 min

Все знают социальную сеть facebook. Многие слышали о неких программистских задачках, опубликованных администрацией этой сети с целью поиска программистов в свою контору (хотя, судя по комментариям на форуме, эта практика давно приостановлена). Некоторые пытались эти задачки решать. Кое-кто даже добился в этом успеха. Но лишь единицы поделились своим опытом в этом. А опыт, надо сказать, весьма и весьма полезный. Собравшись с мыслями, я решил слегка исправить это упущение.
Небольшой дисклеймер: В этой статье не будет красивого кода, следования принципам ООП, соблюдения принятых конвенций и прочих популярных ныне вещей. Красиво отрефакторить работающий код можно успеть всегда, задачей же, решаемой на протяжении статьи, является написание собственно работающего кода.
Итак, алкотестер. Он же breathalyzer. Это задачка snack-сложности по классификации facebook, т.е. по их меркам она совсем не сложная. Что не помешало мне потратить на её решение добрых пару недель(отчасти из-за принципиального желания решить её на Ruby). Эту задачу я делал второй по-очереди, и именно она натолкнула меня на основную идею, побудившую меня прикладывать кучу усилий для поиска решения. А идея была в следующем — я не умею программировать…
Почему фрилансер и заказчик часто считают друг друга идиотами
10 min
 Мне повезло: я побывал по обе стороны баррикад и теперь знаю, что и как делает заказчик на проектах разного уровня и что делает фрилансер, чтобы получить или провалить такой проект. В итоге я уверен, что 95% фрилансеров говорят с заказчиком на разных языках.
Мне повезло: я побывал по обе стороны баррикад и теперь знаю, что и как делает заказчик на проектах разного уровня и что делает фрилансер, чтобы получить или провалить такой проект. В итоге я уверен, что 95% фрилансеров говорят с заказчиком на разных языках.Осторожно, butthurt.