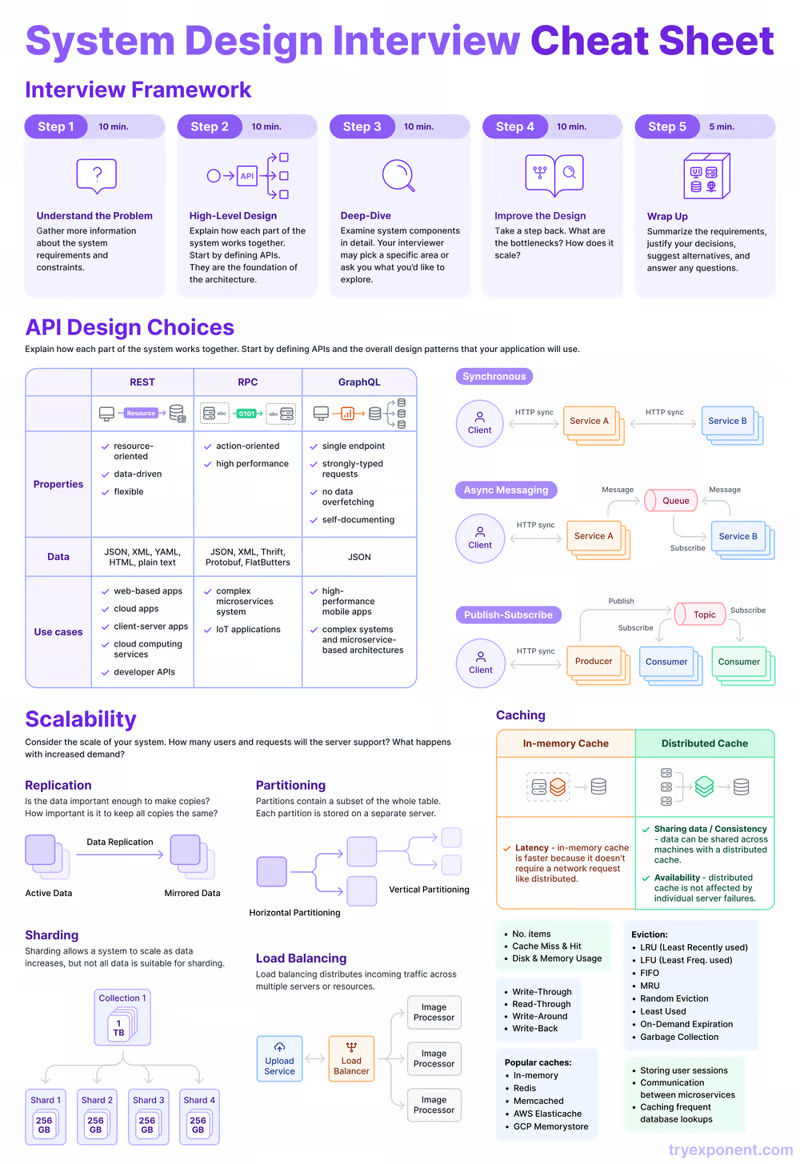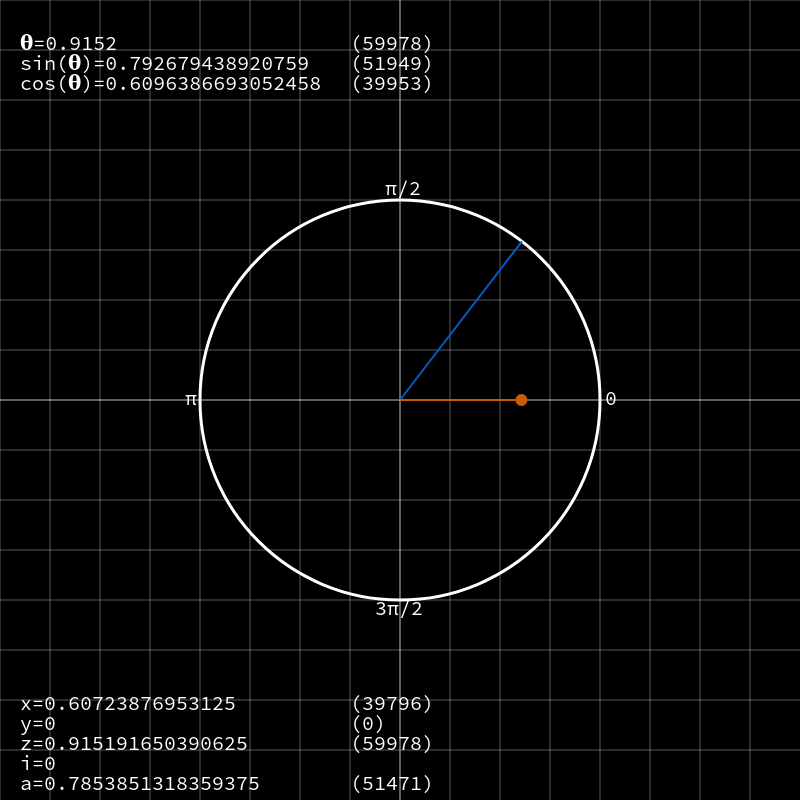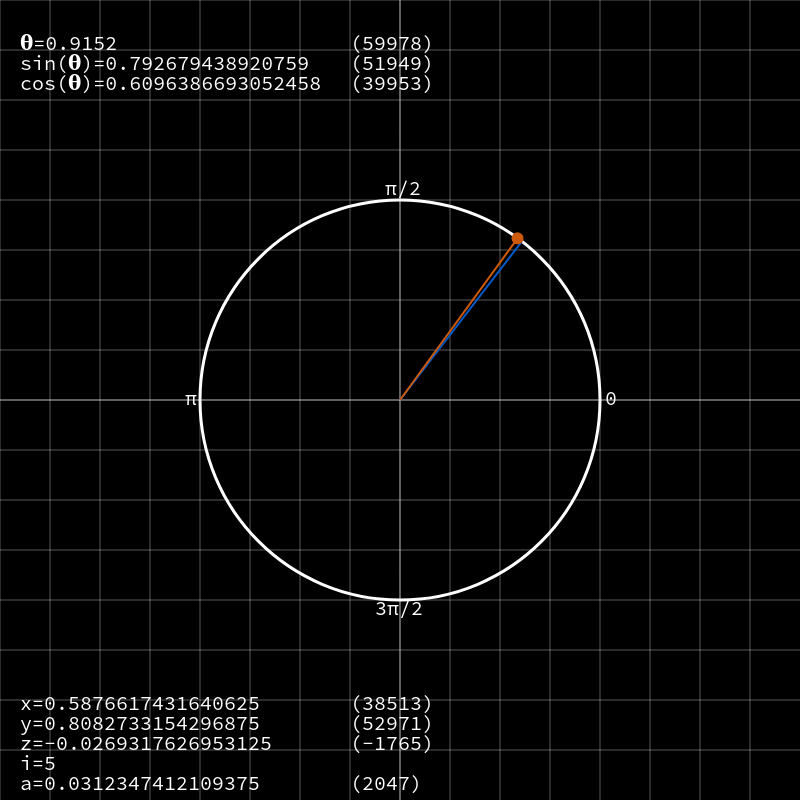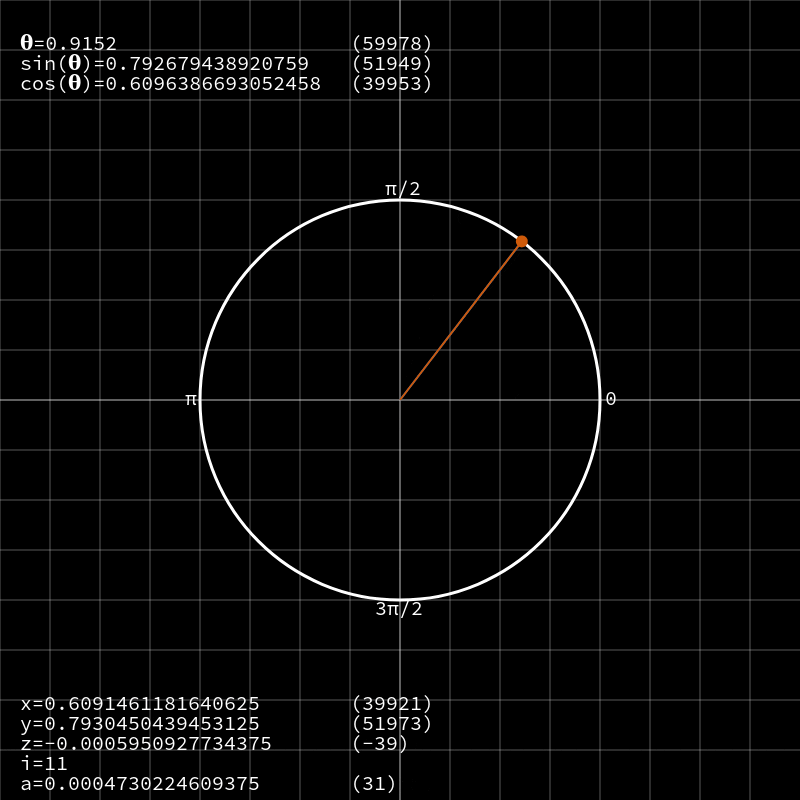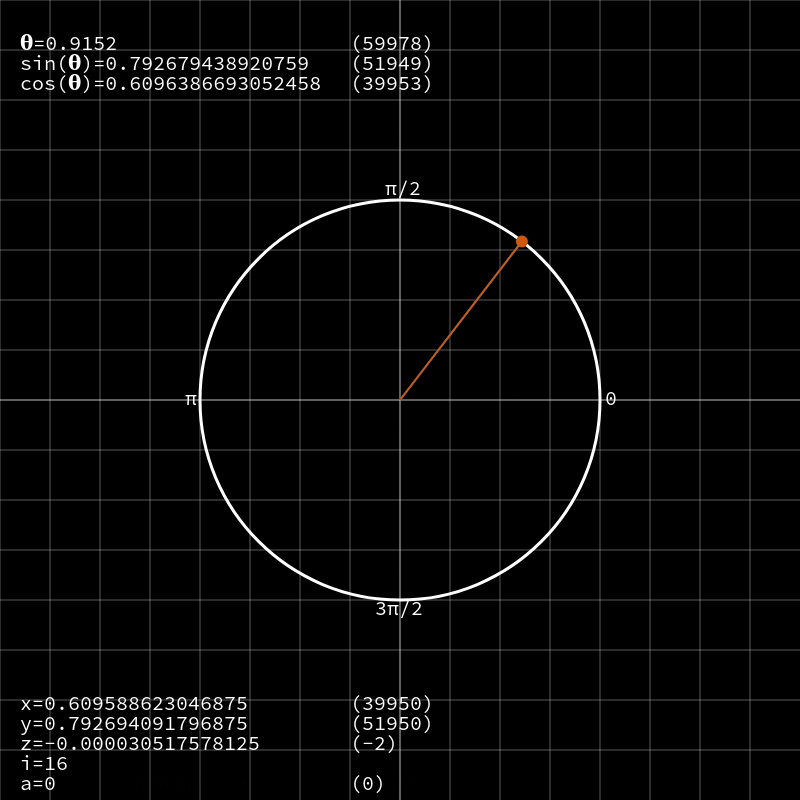
CORDIC — это алгоритм для вычисления тригонометрических функций вроде
sin, cos, tan и тому подобных на маломощных устройствах без использования модуля обработки операций с плавающей запятой или затратных таблиц поиска. По факту он сводит эти сложные функции до простых операций сложения и битового сдвига.Перейду сразу к делу и скажу, почему я так сильно люблю этот алгоритм, а затем займёмся изучением принципов его работы. По сути, фактические операции CORDIC весьма просты — как я уже сказал, это сдвиги и сложение — но выполняет он их путём комбинирования векторной арифметики, тригонометрии, доказательств сходимости и продуманных техник компьютерных наук. Лично я считаю, что именно это имеют ввиду, описывая его природу, как «элегантную».