В первой статье этой серии мы говорили о том, как работает старая система доставки сообщений и некоторых выводах, которые мы сделали по итогам ее работы. Во второй мы рассмотрели конструкцию новой системы и то, почему мы выбрали Cloud Pub/Sub в качестве транспортного механизма для всех событий. В этой третьей и последней статье мы объясним, как мы намереваемся работать со всеми опубликованными событиями при помощи Dataflow, и что мы узнали о таком подходе.
Большинство задач, выполняемых сегодня в Spotify – это пакетные задания. Они требуют того, чтобы события были надежно экспортированы в постоянное хранилище. В качестве такого постоянного хранилища мы традиционно используем Hadoop Distributed File System (HDFS) и Hive. Чтобы соответствовать росту Spotify – который можно измерить как размером сохраненных данных, так и количеством инженеров – мы медленно переключаемся с HDFS на Cloud Storage, а с Hive на BigQuery.
Extract, Transform and Load (ETL) задания – это компоненты, которые мы используем для экспорта данных из HDFS и Cloud Storage. Экспорт Hive и BigQuery обрабатывается пакетными заданиями, которые преобразовывают данные из почасовых сборок на HDFS и Cloud Storage.
Все экспортируемые данные делятся, в соответствии с временными метками, на часовые пакеты. Это открытый интерфейс, который был представлен еще в самой первой нашей системе доставки событий. Система была основана на команде scp и она копировала часовые syslog файлы со всех серверов в HDFS.
ETL задания должны определить, с высокой достоверностью, что все данные для часовых сборок записаны в постоянное хранилище. Когда больше данных для часовой сборки не ожидается, она помечается как полная.
Опоздавшие к уже полной сборке данные добавляться в нее не могут, так как выполняющиеся задачи обычно читают данные из сборки один раз. Чтобы решить эту проблему, ETL задание должно обрабатывать опоздавшие данные отдельно. Все опоздавшие данные записываются в текущую открытую часовую сборку, сдвигая временную отметку события в будущее.
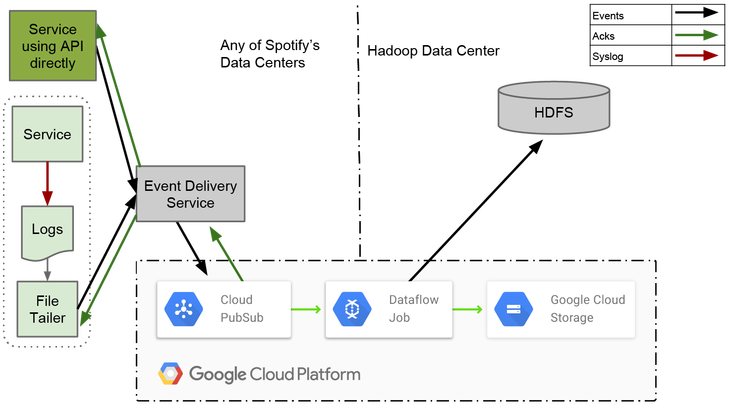
Для написания ETL задания мы решили поэкспериментировать с Dataflow. Этот выбор был обусловлен тем, что мы хотели для себя как можно меньше оперативной ответственности, и чтобы другие решали большие проблемы за нас. Dataflow является как фреймворком для конвейерной записи данных, так и полностью управляемым сервисом в Google Cloud для выполнения таких конвейеров. Он «из коробки» может работать с Cloud Pub/Sub, Cloud Storage и BigQuery.
Написание конвейеров в Dataflow во много похоже на их написание в Apache Crunch. Это не удивительно, так как оба проекта были вдохновлены FlumeJava. Отличие в том, что Dataflow предлагает унифицированную модель для потоковой и пакетной работы, в то время как у Crunch есть только пакетная модель.
Для достижения хорошей end-to-end задержки мы написали наш ETL как потоковое задание. За счет того, что оно постоянно запущено, мы можем инкрементально заполнять отдельные часовые сборки по мере прибытия данных. Это дает нам меньшую задержку по сравнению с пакетной работой, которая экспортировала данные один раз в конце каждого часа.
ELT задача использует windowing (оконную) концепцию Dataflow для разделения данных на часовые сборки на основании времени. В Dataflow окна могут быть назначены как по времени событий, так и по времени обработки. Тот факт, что окна могут быть созданы на основании временной отметки, дает Dataflow преимущества по сравнению с другими потоковыми фреймворками. До сих пор только Apache Flink поддерживает оконную работу и по времени, и по обработке.
Каждое окно состоит из одного или нескольких блоков (pane), и каждый блок содержит набор элементов. Триггер, который назначается каждому окну, определяет, как блоки создаются. Эти блоки выделяются только после того, как данные проходят через GroupByKey. Поскольку GroupByKey группирует по ключу и окну, все агрегированные элементы в одном блоке имеют один и тот же ключ и принадлежат одному окну.
Dataflow обеспечивает механизм, называемый «водяной знак» (watermark, который здесь имеет значение скорее пределах или границы, а не такой же как для изображений или купюр), который можно использовать для определения того, когда закрывать окно. Он используется время событий входящего потока данных для вычисления точки во времени, когда высока вероятность того, что все события для конкретного окна уже прибыли.
В этом разделе мы рассмотрим некоторые проблемы, с которыми мы столкнулись в процессе создания Dataflow ETL задачи для доставки событий. Они могут быть немного сложными для понимания, если у вас не было опыта с Dataflow или подобной системой. Хороший помощник в понимании (если концепция и терминология в новинку для вас) — это публикация о DataFlow от Google.
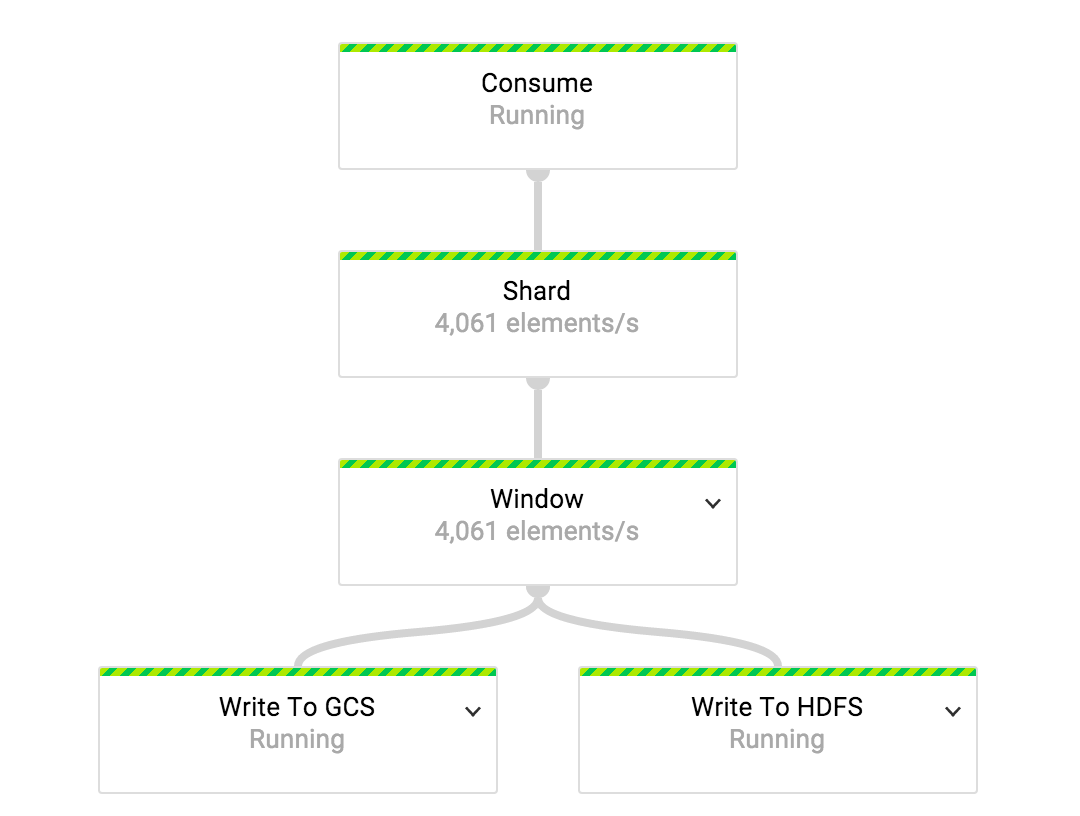
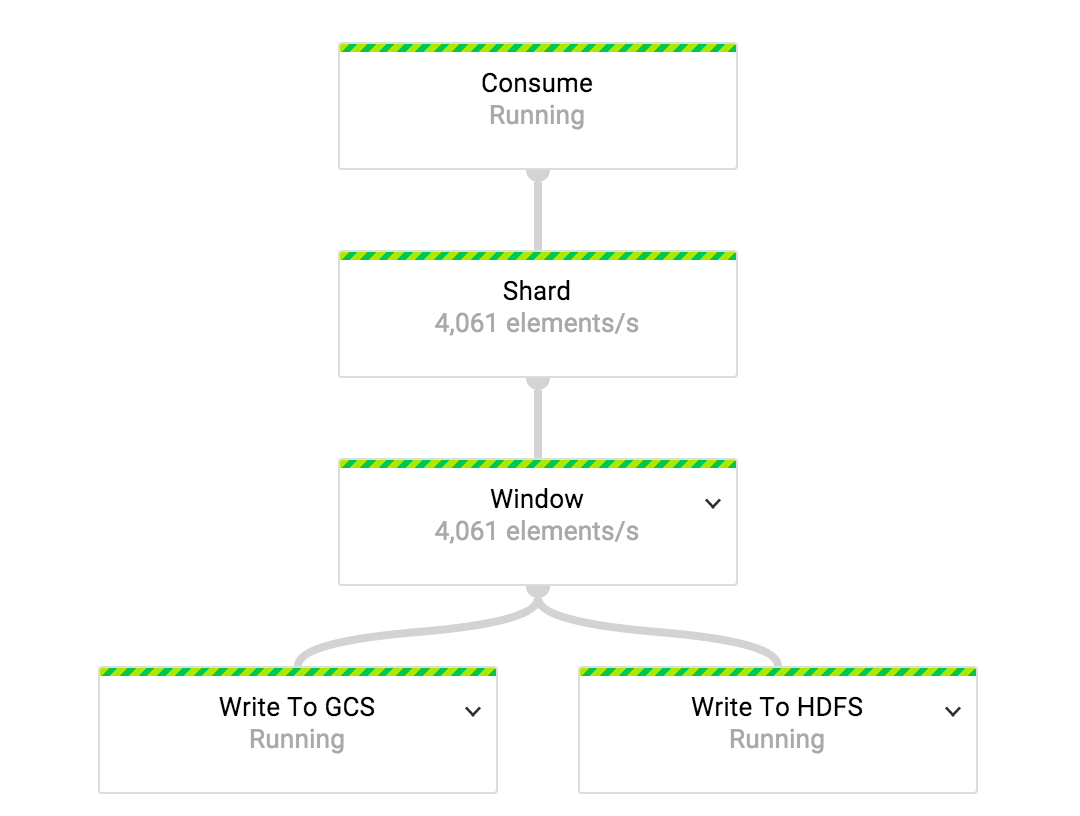
В нашей системе доставки событий у нас отображение 1:1 между типами событий и топиками Cloud Pub/Sub. Одна ETL задача работает с одним потоком типов событий. Мы используем независимые ETL задачи для обработки данных от всех типов событий.
Для того, чтобы поровну распределить нагрузку между всеми доступными воркерами, поток данных разделяется до того, как он проходит трансформацию, назначающую окно каждому событию. Количество шардов, которые мы используем, это функция от числа воркеров, назначенных на задачу.
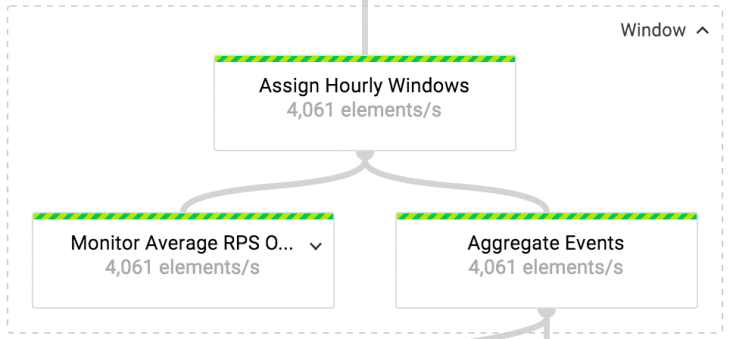
«Окно» является составным преобразованием. На первом этапе этой трансформации мы назначаем часовые фиксированные окна всем событиям во входящем потоке. Окна считаются закрытыми, когда водяной знак переходит за границу часа.
При назначении окон у нас есть ранний триггер, который установлен на то, чтобы выделять в блоки каждые N элементов, пока окно не закроется. Благодаря триггеру, часовые пакеты постоянно наполняются по мере прибытия данных. Так настроенный триггер помогает нам не только достигать меньшей задержки в экспорте, но и обходить ограничения GroupByKey. Объем данных, собирающийся в панели, должен умещаться в памяти на машинах воркеров, так как GroupByKey представляет собой трансформацию в памяти.
Когда окно закрывается, выделение блоков управляется later-триггером. Этот триггер создает блок из данных либо после N элементов, либо после 10 секунд времени работы. События отбрасываются, если они опоздали более чем на один день.
Материализация (создание временного хранилища или таблицы, например) блоков производится в трансформации «Агрегация Событий», которая не что иное как GroupByKey преобразование.
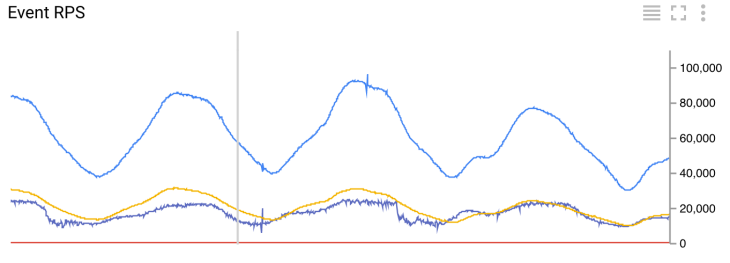
Количество входящих событий в секунду
Для того, чтобы отслеживать количество входящих событий в секунду, проходящих через ETL задачу, мы применяем «Отслеживание среднего RPS своевременных или опоздавших событий» (Monitor Average RPS Of Timely And Late Events) на выходе Assign Hourly Windows. Все показатели преобразований отправляются, как кастомные метрики, в Cloud Monitoring. Показатели вычисляются на скользящих пятиминутных окнах, которые передаются каждую минуту.
Информация о своевременности события может быть получена только после того, как событие назначено окну. Сравнение максимальной временной метки элементов окна с текущим водяным знаком дает нам такую информацию. Поскольку данные о водяных знаках не синхронизируется между трансформациями, обнаружение своевременности таким способом может быть неточным. Число ложно обнаруженных опоздавших событий, которое мы наблюдаем сейчас, довольно низко: менее одного в день.
Мы можем достаточно точно обнаруживать своевременность событий, если преобразование мониторинга (или Monitor Average RPS Of Timely And Late Events) будет применена к выходу Aggregate Events. Недостатком такого подхода была бы непредсказуемость получения метрик, так как окно получается на основе количества элементов и времени событий.
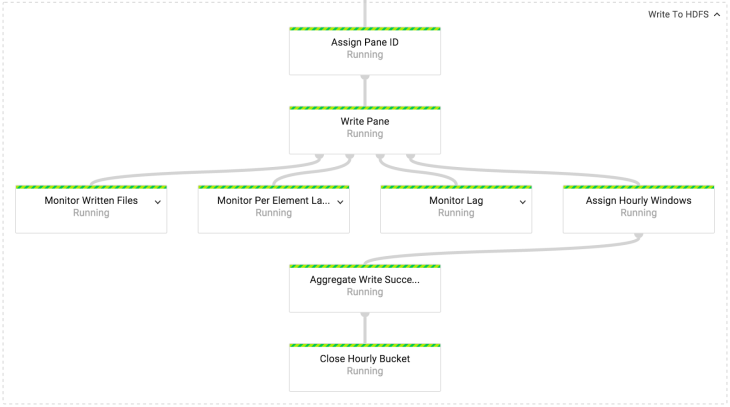
В преобразовании Write to HDFS/GCS мы пишем данные либо в HDFS, либо в Cloud Storage. Механика записи в HDFS и Cloud Storage одинакова. Единственная разница в том, какой API файловой системы используется. В нашей реализации, оба API скрыты за интерфейсом IOChannelFactory.
Чтобы гарантировать, что только один файл записывается в блок, даже пренебрегая возможностью сбоя, каждый блок получает уникальный ID. Идентификатор блока затем используется как уникальный ID для всех записываемых файлов. Файлы пишутся в Avro формате со схемой, которая соответствует схеме ID событий.
Своевременные блоки пишутся в пакеты (bucket) на основе времени события. Запоздавшие пишутся в пакеты текущего часа, так как дополнение закрытых сборок нежелательно в работе с данными в Spotify. Для понимания того, своевременный ли блок, мы используем объект PaneInfo. Он создается при создании блока.
Маркер законченности для часовой сборки пишется только один раз. Для этого основной выходной поток действия Write Pane переобрабатывается (re-windowed) в часовое окно и агрегируется в Aggregated Write Successes.
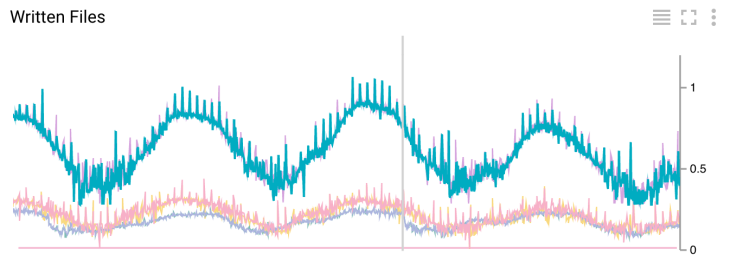
Количество записанных файлов в секунду
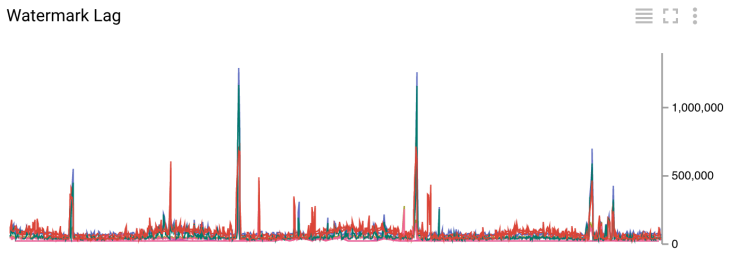
Задержка водяного знака в миллисекундах
Получение метрик является побочным выходом действий Write Pane. Мы получаем данные, которые показывают, сколько файлов записалось в секунду, среднюю задержку событий и лаг «водяного знака» по сравнению с текущим временем. Все эти метрики рассчитываются для 5 минутного окна и передаются каждую минуту.
Поскольку отставание водяного знака мы измеряем после записи в HDFS/Cloud Storage, оно непосредственно связано со всей латентностью системы. На графике с задержкой можно видеть, что отставание текущего знака в основном меньше 200 с (примерно 3.5 минуты). Вы можете видеть случайные всплески до 1500 с (примерно 25 минут) на этом же рисунке. Такие пики вызваны разрозненностью при записи в наш Hadoop кластер через VPN. Для сравнения, латентность в нашей старой системе составляет два часа в «лучший день» и три часа в среднем.
Реализация ETL задания пока находится в стадии прототипирования. Пока у нас есть четыре выполняющихся ETL задания (смотрите график с количеством событий в секунду). Самое маленькое задание потребляет около 30 событий в секунду, а самое большое достигает пиковых значений в 100К событий в секунду.
Мы еще не нашли хороший способ вычислять оптимальное количество воркеров для ETL задач. Их количество пока определяется вручную после проб и ошибок. Мы используем два воркера для наименьшей задачи и 42 для наибольшей. Интересно отметить, что выполнение заданий также зависит от памяти. Для одного конвейера, обрабатывающего около 20К событий в секунду, мы используем 24 воркера, в то время как для второго, обрабатывающего события с той же скоростью, но со средним размером сообщения вчетверо меньше, мы задействуем только 4. Управление конвейерами может намного упроститься, когда мы реализуем функцию автоматического масштабирования.
Мы должны гарантировать, что при перезапуске задачи (job), мы не потеряем никаких данных. Сейчас это не так, если job update не работает. Мы активно сотрудничаем с инженерами Dataflow в поиске решения этой проблемы.
Поведение водяного знака все еще остается загадкой для нас. Нам нужно проверить, что его вычисление предсказуемо как в случае сбоя, так и в случае нормальной работы.
Наконец, нам надо определить хорошую модель CI/CD для быстрых и надежных обновлений ETL задания. Это нетривиальная задача — нам надо управлять одной ETL задачей для каждого типа событий, а их у нас более 1000.
Мы активно работаем над тем, чтобы запустить новую систему в продакшен. Предварительные цифры, которые мы получили из запуска новой системы в экспериментальной фазе, очень обнадеживают. Худшее общее время задержки в новой системе в четыре раза меньше общего времени задержки старой платформы.
Но повышение производительности это не единственное, что мы хотим получить от новой системы. Мы хотим с помощью облачных продуктов намного снизить операционные издержки. Это, в свою очередь, означает, что у нас будет гораздо больше времени на улучшение продуктов Spotify.
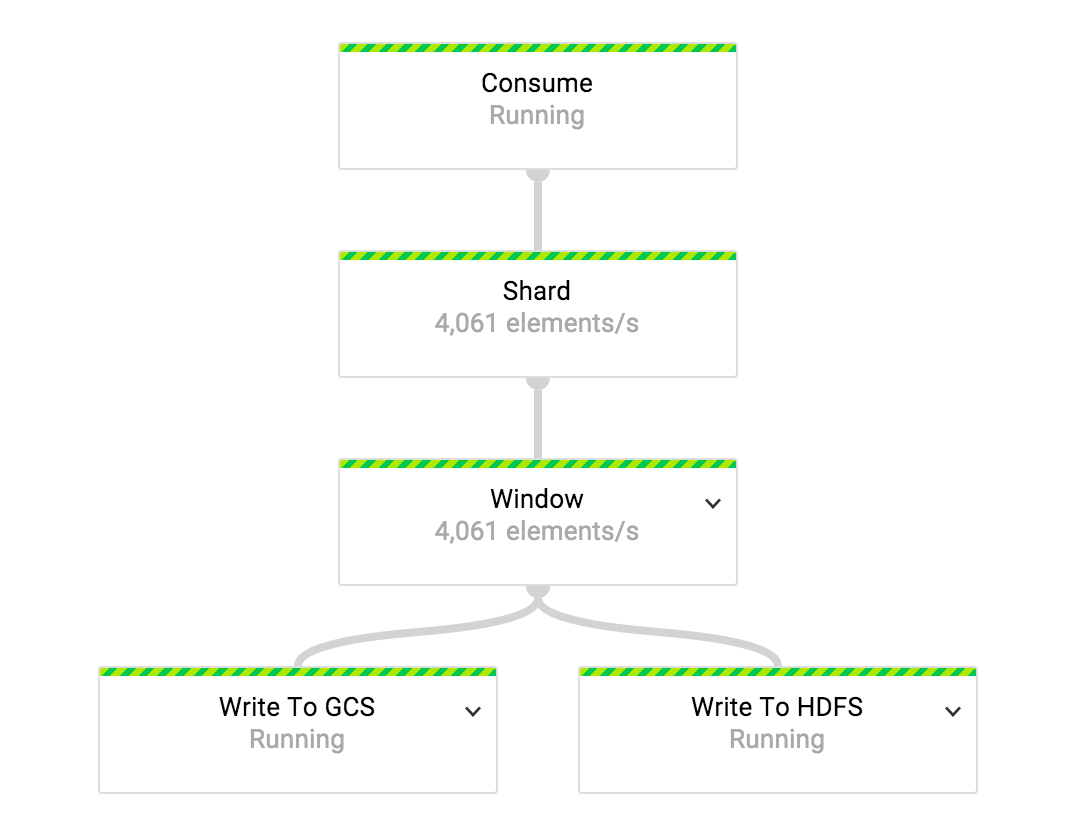
Экспорт событий из Pub/Sub в (по)часовые интервалы с помощью Dataflow
Большинство задач, выполняемых сегодня в Spotify – это пакетные задания. Они требуют того, чтобы события были надежно экспортированы в постоянное хранилище. В качестве такого постоянного хранилища мы традиционно используем Hadoop Distributed File System (HDFS) и Hive. Чтобы соответствовать росту Spotify – который можно измерить как размером сохраненных данных, так и количеством инженеров – мы медленно переключаемся с HDFS на Cloud Storage, а с Hive на BigQuery.
Extract, Transform and Load (ETL) задания – это компоненты, которые мы используем для экспорта данных из HDFS и Cloud Storage. Экспорт Hive и BigQuery обрабатывается пакетными заданиями, которые преобразовывают данные из почасовых сборок на HDFS и Cloud Storage.
Все экспортируемые данные делятся, в соответствии с временными метками, на часовые пакеты. Это открытый интерфейс, который был представлен еще в самой первой нашей системе доставки событий. Система была основана на команде scp и она копировала часовые syslog файлы со всех серверов в HDFS.
ETL задания должны определить, с высокой достоверностью, что все данные для часовых сборок записаны в постоянное хранилище. Когда больше данных для часовой сборки не ожидается, она помечается как полная.
Опоздавшие к уже полной сборке данные добавляться в нее не могут, так как выполняющиеся задачи обычно читают данные из сборки один раз. Чтобы решить эту проблему, ETL задание должно обрабатывать опоздавшие данные отдельно. Все опоздавшие данные записываются в текущую открытую часовую сборку, сдвигая временную отметку события в будущее.
Для написания ETL задания мы решили поэкспериментировать с Dataflow. Этот выбор был обусловлен тем, что мы хотели для себя как можно меньше оперативной ответственности, и чтобы другие решали большие проблемы за нас. Dataflow является как фреймворком для конвейерной записи данных, так и полностью управляемым сервисом в Google Cloud для выполнения таких конвейеров. Он «из коробки» может работать с Cloud Pub/Sub, Cloud Storage и BigQuery.
Написание конвейеров в Dataflow во много похоже на их написание в Apache Crunch. Это не удивительно, так как оба проекта были вдохновлены FlumeJava. Отличие в том, что Dataflow предлагает унифицированную модель для потоковой и пакетной работы, в то время как у Crunch есть только пакетная модель.
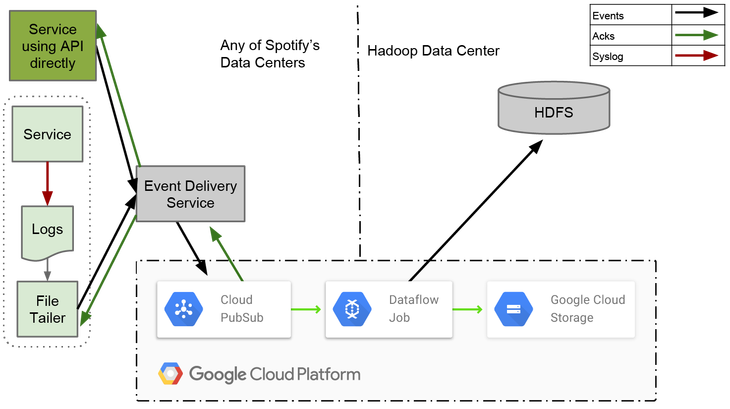
Для достижения хорошей end-to-end задержки мы написали наш ETL как потоковое задание. За счет того, что оно постоянно запущено, мы можем инкрементально заполнять отдельные часовые сборки по мере прибытия данных. Это дает нам меньшую задержку по сравнению с пакетной работой, которая экспортировала данные один раз в конце каждого часа.
ELT задача использует windowing (оконную) концепцию Dataflow для разделения данных на часовые сборки на основании времени. В Dataflow окна могут быть назначены как по времени событий, так и по времени обработки. Тот факт, что окна могут быть созданы на основании временной отметки, дает Dataflow преимущества по сравнению с другими потоковыми фреймворками. До сих пор только Apache Flink поддерживает оконную работу и по времени, и по обработке.
Каждое окно состоит из одного или нескольких блоков (pane), и каждый блок содержит набор элементов. Триггер, который назначается каждому окну, определяет, как блоки создаются. Эти блоки выделяются только после того, как данные проходят через GroupByKey. Поскольку GroupByKey группирует по ключу и окну, все агрегированные элементы в одном блоке имеют один и тот же ключ и принадлежат одному окну.
Dataflow обеспечивает механизм, называемый «водяной знак» (watermark, который здесь имеет значение скорее пределах или границы, а не такой же как для изображений или купюр), который можно использовать для определения того, когда закрывать окно. Он используется время событий входящего потока данных для вычисления точки во времени, когда высока вероятность того, что все события для конкретного окна уже прибыли.
Глубокое погружение в реализацию ETL
В этом разделе мы рассмотрим некоторые проблемы, с которыми мы столкнулись в процессе создания Dataflow ETL задачи для доставки событий. Они могут быть немного сложными для понимания, если у вас не было опыта с Dataflow или подобной системой. Хороший помощник в понимании (если концепция и терминология в новинку для вас) — это публикация о DataFlow от Google.
В нашей системе доставки событий у нас отображение 1:1 между типами событий и топиками Cloud Pub/Sub. Одна ETL задача работает с одним потоком типов событий. Мы используем независимые ETL задачи для обработки данных от всех типов событий.
Для того, чтобы поровну распределить нагрузку между всеми доступными воркерами, поток данных разделяется до того, как он проходит трансформацию, назначающую окно каждому событию. Количество шардов, которые мы используем, это функция от числа воркеров, назначенных на задачу.

«Окно» является составным преобразованием. На первом этапе этой трансформации мы назначаем часовые фиксированные окна всем событиям во входящем потоке. Окна считаются закрытыми, когда водяной знак переходит за границу часа.
@Override
public PCollection<KV<String, Iterable<Gabo.EventMessage>>> apply(
final PCollection<KV<String, Gabo.EventMessage>> shardedEvents) {
return shardedEvents
.apply("Assign Hourly Windows",
Window.<KV<String, Gabo.EventMessage>>into(
FixedWindows.of(ONE_HOUR))
.withAllowedLateness(ONE_DAY)
.triggering(
AfterWatermark.pastEndOfWindow()
.withEarlyFirings(AfterPane.elementCountAtLeast(maxEventsInFile))
.withLateFirings(AfterFirst.of(AfterPane.elementCountAtLeast(maxEventsInFile),
AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(TEN_SECONDS))))
.discardingFiredPanes())
.apply("Aggregate Events", GroupByKey.create());
}При назначении окон у нас есть ранний триггер, который установлен на то, чтобы выделять в блоки каждые N элементов, пока окно не закроется. Благодаря триггеру, часовые пакеты постоянно наполняются по мере прибытия данных. Так настроенный триггер помогает нам не только достигать меньшей задержки в экспорте, но и обходить ограничения GroupByKey. Объем данных, собирающийся в панели, должен умещаться в памяти на машинах воркеров, так как GroupByKey представляет собой трансформацию в памяти.
Когда окно закрывается, выделение блоков управляется later-триггером. Этот триггер создает блок из данных либо после N элементов, либо после 10 секунд времени работы. События отбрасываются, если они опоздали более чем на один день.
Материализация (создание временного хранилища или таблицы, например) блоков производится в трансформации «Агрегация Событий», которая не что иное как GroupByKey преобразование.
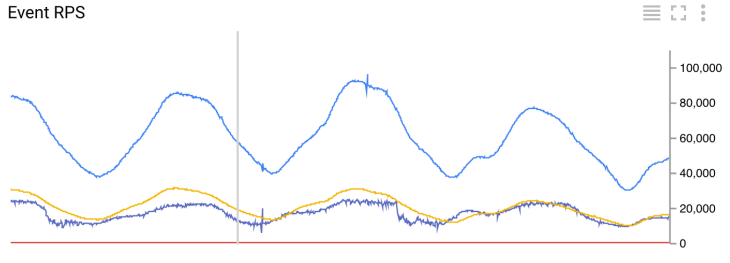
Количество входящих событий в секунду
Для того, чтобы отслеживать количество входящих событий в секунду, проходящих через ETL задачу, мы применяем «Отслеживание среднего RPS своевременных или опоздавших событий» (Monitor Average RPS Of Timely And Late Events) на выходе Assign Hourly Windows. Все показатели преобразований отправляются, как кастомные метрики, в Cloud Monitoring. Показатели вычисляются на скользящих пятиминутных окнах, которые передаются каждую минуту.
Информация о своевременности события может быть получена только после того, как событие назначено окну. Сравнение максимальной временной метки элементов окна с текущим водяным знаком дает нам такую информацию. Поскольку данные о водяных знаках не синхронизируется между трансформациями, обнаружение своевременности таким способом может быть неточным. Число ложно обнаруженных опоздавших событий, которое мы наблюдаем сейчас, довольно низко: менее одного в день.
Мы можем достаточно точно обнаруживать своевременность событий, если преобразование мониторинга (или Monitor Average RPS Of Timely And Late Events) будет применена к выходу Aggregate Events. Недостатком такого подхода была бы непредсказуемость получения метрик, так как окно получается на основе количества элементов и времени событий.
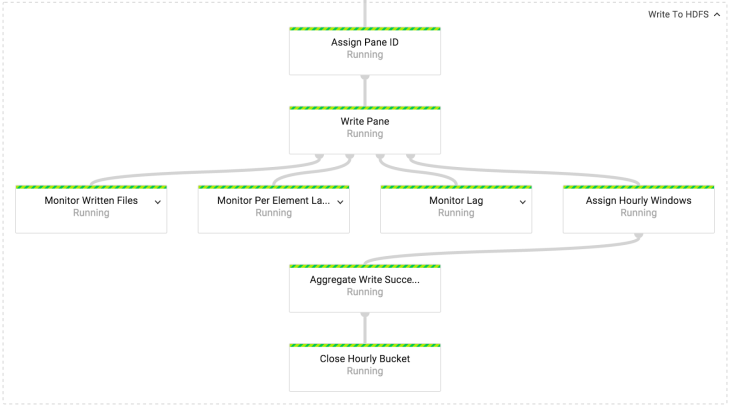
В преобразовании Write to HDFS/GCS мы пишем данные либо в HDFS, либо в Cloud Storage. Механика записи в HDFS и Cloud Storage одинакова. Единственная разница в том, какой API файловой системы используется. В нашей реализации, оба API скрыты за интерфейсом IOChannelFactory.
Чтобы гарантировать, что только один файл записывается в блок, даже пренебрегая возможностью сбоя, каждый блок получает уникальный ID. Идентификатор блока затем используется как уникальный ID для всех записываемых файлов. Файлы пишутся в Avro формате со схемой, которая соответствует схеме ID событий.
Своевременные блоки пишутся в пакеты (bucket) на основе времени события. Запоздавшие пишутся в пакеты текущего часа, так как дополнение закрытых сборок нежелательно в работе с данными в Spotify. Для понимания того, своевременный ли блок, мы используем объект PaneInfo. Он создается при создании блока.
Маркер законченности для часовой сборки пишется только один раз. Для этого основной выходной поток действия Write Pane переобрабатывается (re-windowed) в часовое окно и агрегируется в Aggregated Write Successes.

Количество записанных файлов в секунду
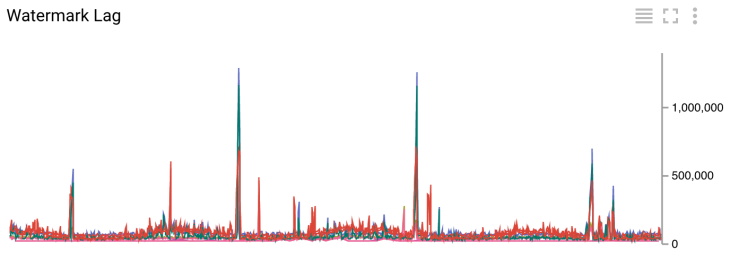
Задержка водяного знака в миллисекундах
Получение метрик является побочным выходом действий Write Pane. Мы получаем данные, которые показывают, сколько файлов записалось в секунду, среднюю задержку событий и лаг «водяного знака» по сравнению с текущим временем. Все эти метрики рассчитываются для 5 минутного окна и передаются каждую минуту.
Поскольку отставание водяного знака мы измеряем после записи в HDFS/Cloud Storage, оно непосредственно связано со всей латентностью системы. На графике с задержкой можно видеть, что отставание текущего знака в основном меньше 200 с (примерно 3.5 минуты). Вы можете видеть случайные всплески до 1500 с (примерно 25 минут) на этом же рисунке. Такие пики вызваны разрозненностью при записи в наш Hadoop кластер через VPN. Для сравнения, латентность в нашей старой системе составляет два часа в «лучший день» и три часа в среднем.
Следующие шаги в ETL задании
Реализация ETL задания пока находится в стадии прототипирования. Пока у нас есть четыре выполняющихся ETL задания (смотрите график с количеством событий в секунду). Самое маленькое задание потребляет около 30 событий в секунду, а самое большое достигает пиковых значений в 100К событий в секунду.
Мы еще не нашли хороший способ вычислять оптимальное количество воркеров для ETL задач. Их количество пока определяется вручную после проб и ошибок. Мы используем два воркера для наименьшей задачи и 42 для наибольшей. Интересно отметить, что выполнение заданий также зависит от памяти. Для одного конвейера, обрабатывающего около 20К событий в секунду, мы используем 24 воркера, в то время как для второго, обрабатывающего события с той же скоростью, но со средним размером сообщения вчетверо меньше, мы задействуем только 4. Управление конвейерами может намного упроститься, когда мы реализуем функцию автоматического масштабирования.
Мы должны гарантировать, что при перезапуске задачи (job), мы не потеряем никаких данных. Сейчас это не так, если job update не работает. Мы активно сотрудничаем с инженерами Dataflow в поиске решения этой проблемы.
Поведение водяного знака все еще остается загадкой для нас. Нам нужно проверить, что его вычисление предсказуемо как в случае сбоя, так и в случае нормальной работы.
Наконец, нам надо определить хорошую модель CI/CD для быстрых и надежных обновлений ETL задания. Это нетривиальная задача — нам надо управлять одной ETL задачей для каждого типа событий, а их у нас более 1000.
Облачная система доставки событий
Мы активно работаем над тем, чтобы запустить новую систему в продакшен. Предварительные цифры, которые мы получили из запуска новой системы в экспериментальной фазе, очень обнадеживают. Худшее общее время задержки в новой системе в четыре раза меньше общего времени задержки старой платформы.
Но повышение производительности это не единственное, что мы хотим получить от новой системы. Мы хотим с помощью облачных продуктов намного снизить операционные издержки. Это, в свою очередь, означает, что у нас будет гораздо больше времени на улучшение продуктов Spotify.
