
Биллинг — сложная система, одним из важнейших компонентов которой является база данных. В ней содержится множество разнообразных таблиц, которые со временем разрастаются до больших размеров.
Для того, чтобы это рост не замедлял работу базы, в Oracle, PostgreSQL и других СУБД существует эффективный механизм секционирования (partitioning) — однако его не всегда можно применять. К примеру, он отсутствует в относительно бюджетной редакции системы Oracle Standard Edition.
Исторически сложилось так, что в нашем биллинге для операторов связи «Гидра» мы не реализовывали собственный механизм секционирования, ограничившись созданием руководства для клиентов, в котором были описаны шаги для отслеживания роста таблиц и минимизации возможных проблем с быстродействием системы. Как выяснилось в дальнейшем, этого было явно недостаточно.
Предыстория
Биллинг «Гидра» используют операторы связи, а значит, одной из самых важных и крупных таблиц в базе является та, которая отвечает за хранение данных о PPP-сессиях и CDR абонентов провайдеров интернета или телефонии. В этой таблице хранятся данные о начале, завершении и времени ее последнего обновления, а также информация об абоненте, инициировавшем ее, например, IP-адресе, с которого он установил соединение.
Чем больше в базе оператора связи абонентов, тем быстрее растет таблица с данными о сессиях. Самым простым решением в этой ситуации выглядит простое удаление старых записей время от времени. Однако по российскому законодательству провайдеры обязаны хранить данные о доступе абонентов в сеть, которые могут понадобиться правоохранительным органам, на протяжении трех лет.
При разработке биллинга еще много лет назад мы учли этот момент и допустили, что объем таблицы с сессиями может достигать 15 млн строк. По достижению этой планки должен был запускаться скрипт выгрузки и архивации данных.
Тем не менее, необходимость мониторинга размеров таблицы сохранялась — если совсем не обращать на это внимания, она могла вырасти и до значительно больших размеров. Что в конечном итоге и произошло у одного из наших клиентов.
Все плохо
По разным причинам специалисты этого провайдера не настроили мониторинг размера таблицы с сессиями и не подключили наш сервис мониторинга (специально для ленивых клиентов мы создали специальный инструмент, который способен собирать метрики работы системы и оповещать о возможных проблемах).
Таблица росла, причем об этом не знала ни компания, в чьей базе все происходило, ни наша служба поддержки. В конечном итоге ее размер составил 36 млн строк, что более чем в два раза превысило максимальный лимит.
У этого конкретного оператора абоненты попадали в сеть по VPN, а значит, им нужно было получить доступ к VPN-серверу, который уже по протоколу RADIUS обращался к базе данных.
В результате в день, когда в сети оператора случился всплеск активности абонентов вследствие перезагрзуки одного из магистральных коммутаторов, RADIUS-сервер биллинга не смог своевременно авторизовать нахлынувший поток абонентов.
Произошло вот что — производительность выборок из таблицы сессий в определенный момент серьезно упала. Это привело к тому, что процесс авторизации абонентов не успевал завершиться в отведенное для этого время. В результате пользователи стали получать отказы доступа в сеть и повторно отправлять запросы на авторизацию, которые слились в настоящую лавину, захлестнувшую систему.
При таймауте обработки запроса VPN-сервер посылает еще пару запросов на авторизацию — и для их обработки опять необходимо прочитать данные из той самой огромной таблицы. И только после этого абонент увидит сообщение об отказе в доступе. Естественно, что получив такое сообщение, пользователь пытается установить соединение повторно, и все повторяется вновь. Таким образом возникла ситуация с настоящим DoS сервера RADIUS.
Что делать
Столкнувшись с серьезными проблемами авторизации собственных абонентов, провайдер обратился в нашу службу поддержки. Причину проблем удалось установить очень быстро — слишком уж большой была таблица с сессиями, кроме того в топе запросов по IOWAIT находились те самые запросы на чтение из таблицы сессий. Исправить сложившуюся ситуацию можно было единственным способом — очисткой строк таблицы в БД. При этом данные потерять было нельзя, так что их предварительно нужно было куда-то скопировать.
Поэтому мы выгрузили записи в CSV-файлы, тем самым уменьшив объём таблицы. Чтобы пустить в сеть часть абонентов в процессе этих работ, был также активирован автономный режим работы RADIUS-сервера. Он заключается в использовании механизма кэширования — в кэше сохраняются данные о результате последней авторизации абонента, так, чтобы при потере связи с биллингом сервер мог провести авторизацию пользователей с использованием этих данных.
Механизм автономного режима на тот момент был довольно прост и имел свои недостатки — например, данные в кэше не находились в постоянной репликации с базой данных, поэтому в них могли быть расхождения. Это значит, что если пользователь последний раз авторизовался месяц назад, а затем не платил за интернет и должен был быть заблокирован, то при работе в автономном режиме на основе сохраненной записи месячной давности система его авторизует — или не авторизует того, кто имеет право на доступ, но был заблокирован в последнюю попытку соединения. Но в сложившейся ситуацией это было меньшее из зол.
В итоге, когда таблица с сессиями сократилась в размере до 30 млн строк, авторизация абонентов вновь заработала, и мы смогли отключить автономный режим работы RADIUS-сервера.
Уроки
Эта история дала нам немало пищи для размышлений. Выяснилось, что мало просто выдать клиентам рекомендации или дать платную возможность мониторинга важных моментов — если в конечном итоге выполнение действий отдается на откуп клиенту, то стоит ожидать, что он не станет их осуществлять. Поэтому мы реализовали новые схемы мониторинга, которые позволяют нам самим отслеживать возникновение проблем в клиентских системах.
Теперь при обнаружении потенциально опасной ситуации, подобной описанное выше, создается заявка в службу поддержки «Латеры», с которой мы детально разбираемся.
Кроме того, мы изменили и подход к организации работы с данными и процесса кэширования RADIUS-сервера. Все это вылилось в создание механима архивации в новой версии биллинга — он предусматривает архивирование данных постоянно растущих таблиц в отдельную схему Oracle. Этот процесс идет в фоновом режиме и не влияет на работу биллинга. Причем для клиента этот механизм работает таким образом, что при создании отчетов по сессиям, он получает одновременно данные из основных и таблиц из схемы с архивом, без «плясок с бубном».
Также мы сделали полностью автономный RADIUS-сервер с локальной базой данных, которая выступает не в качестве кэша, а локально хранит реплицированную из основной базы биллинга информацию, необходимую для авторизации абонентов. Таким образом была решена проблема возможного предоставления услуг связи тем, абонентам, которые должны быть заблокированы, и отказ в доступе для тех, кого нужно авторизовать. В новом варианте RADIUS-сервера реализованы механизмы по максимально безболезненному выходу из ситуации при разрыве связи с биллингом. Мы описывали их в статье про обеспечение отказоустойчивости биллинга.
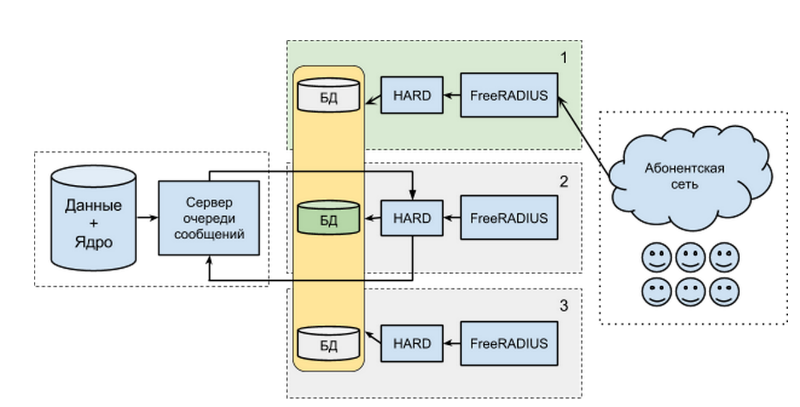
Если описывать схему кратко, то каждый сервер доступа состоит из нескольких компонентов:
- База данных с профилями абонентов и данными о потребленных услугах.
- Наше приложение под кодовым названием HARD. Оно отвечает на HTTP-запросы, которые идут от следующего компонента.
- FreeRADIUS — непосредственно сервер, реализующий стандартный AAA-протокол — RADIUS. Он непосредственно общается с абонентской сетью и переводит запросы из бинарного формата в обычный HTTP+JSON для HARD.
Базы данных всех AAA-серверов (это MongoDB) объединены в группу с одним основным узлом (master) и двумя подчиненными (slave). Все запросы из абонентской сети идут на один AAA-сервер, при этом необязательно и даже нежелательно, чтобы им был сервер с основной БД.
Если что-то пойдет не так, и один из компонентов откажет, то, абоненты не потеряют доступ к услугам. Скорее всего, они вообще ничего не заметят.
Кроме того, мы продолжаем следить за размером таблиц, в том числе отслеживаем объём таблицы сессий — никто не застрахован от роста данных в неархивный период.
На сегодня все, спасибо за внимание! Не забывайте подписываться на наш блог.
