
Индикатор кулачкового аналогового компьютера / Wiki
В нашем блоге мы уже рассказывали о разработке системы квантовой связи и о том, как из простых студентов готовят продвинутых программистов. Сегодня мы решили вернуться к теме машинного обучения и привести адаптированную (источник) подборку полезных материалов.
Это список предназначен для тех, кто только начинает изучать тему машинного обучения, например, с использованием Python (если вы хотите начать учить Python, вам в помощь эта статья).
Машинное обучение – это лишь одна из математических дисциплин, связанных с понятием «данные». Чтобы разобраться в том, что такое аналитика данных, анализ данных, наука о данных, машинное обучение и большие данные, прочитайте этот материал.
Вот инструменты, которые вам понадобятся:
- Python (Python 3 – наилучший вариант),
- IPython и Jupyter Notebook (IPython Notebook),
- Пакеты для расчетов: NumPy, Pandas, Scikit-Learn, Matplotlib.
Вы можете установить Python 3 и все необходимые пакеты в несколько кликов с помощью сборки Anaconda Python. Anaconda – это достаточно популярный дистрибутив среди людей, занимающихся машинным обучением.
Не страшно, если у вас установлен Python 2.7. Переходить на Python 3 нет необходимости. Вместо Anaconda вы можете воспользоваться pip или virtualenv. Не можете определиться? Прочитайте этот материал.
Для начала познакомьтесь с IPython Notebook (это займет 5-10 минут). Еще можете посмотреть это видео. Далее рассмотрите небольшой пример (это займет 10 минут) классификации цифр с использованием библиотеки scikit-learn.
Наглядное введение в теорию машинного обучения
Давайте побольше узнаем о машинном обучении: об идеях и особенностях. Прочитайте статью Стефани Йи (Stephanie Yee) и Тони Чу (Tony Chu) «Наглядное введение в машинное обучение. Часть 1».
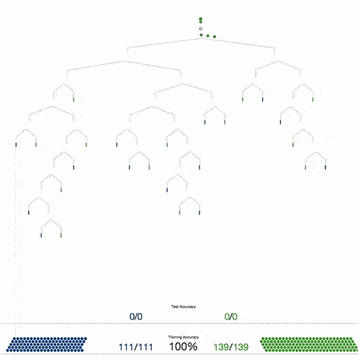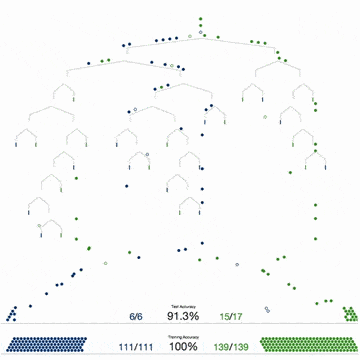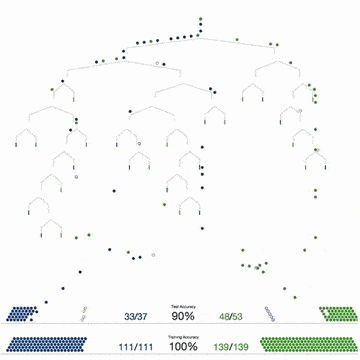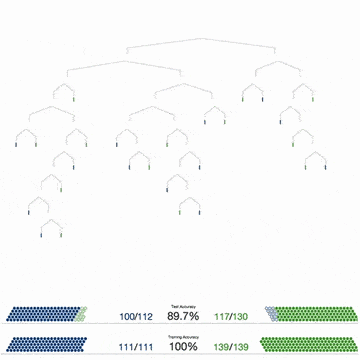
Прочитайте статью профессора Педро Домингоса (Pedro Domingos). Во время чтения не торопитесь, делайте заметки. В статье можно выделить два основных момента:
Одних только данных недостаточно. Домингос писал: «…нет ничего удивительного в том, что для обучения нужны знания. Машинное обучение не может получить что-то из ничего, но может получить большее из меньшего. Обучение похоже на сельское хозяйство, где большую часть работы делает природа. Фермеры дают семенам питательные вещества, чтобы вырастить урожай. Так и здесь: чтобы создать программу, нужно совместить знания и данные».
Большое количество данных лучше детально продуманного алгоритма. Не пытайтесь изобретать велосипед и усложнять решения: выбирайте кратчайший путь, ведущий к цели. Домингос говорит: «Как правило, «глупый» алгоритм с большим количеством данных превосходит «умный» алгоритм с небольшим количеством данных. В машинном обучении главную роль всегда играют данные».
Итак, знания и данные имеют решающее значение. Это означает, что усложнять алгоритмы нужно только тогда, когда у вас действительно нет выбора.
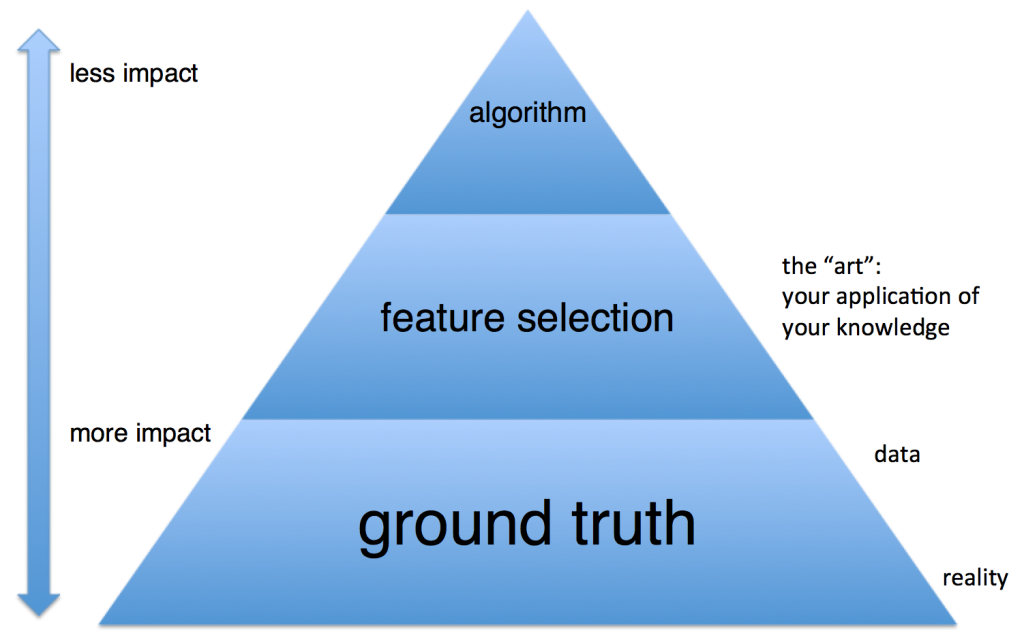
Схема составлена на основе слайда из лекции Алекса Пинто (Alex Pinto) «Математика на страже безопасности: руководство по мониторингу с применением машинного обучения».
Обучайтесь на примерах
Выберете и рассмотрите один или два примера из представленных ниже.
- Распознавание лиц на фотографиях из базы данных сайта Labeled Faces in the Wild.
- Машинное обучение на основе данных о катастрофе Титаника. Здесь демонстрируются методы преобразования данных и их анализа, а также техники визуализации. Есть примеры методов машинного обучения с учителем.
- Прогнозирование итогов выборов: использование модели Нейта Сильвера (Nate Silver) для составления прогноза итогов выборов президента США в 2012 году, опубликованных The New York Times.
Вот еще руководства и обзоры:
Другие источники, в которых можно найти блокноты IPython:
- Галерея интересных блокнотов IPython: статистика, машинное обучение и наука о данных.
- Большая галерея Фабиана Педрегозы (Fabian Pedregosa).
Курсы по машинному обучению
Будет полезно, если вы начнете работать над каким-нибудь небольшим самостоятельным проектом – так у вас будет возможность применить полученные знания на практике. Можете воспользоваться одним из этих наборов данных.
Еще часто рекомендуют книгу «The Elements of Statistical Learning», но она, как правило, выступает в роли справочника. Книга бесплатная, поэтому скачайте ее или добавьте в закладки браузера.
Еще есть вот эти онлайн-курсы:
- Курс «Машинное обучение» профессора Педро Домингоса из Вашингтонского университета.
- Практикум по науке о данных.
- Наука о данных.
- Видео «Введение в машинное обучение с scikit-learn» от Кевина Маркхэма (Kevin Markham). После просмотра видеоматериала, вы можете пройти интерактивный курс по науке о данных (есть его более ранние версии: 7, 5, 4, 3).
- Гарвардский курс CS109 – наука о данных.
- Продвинутый курс статистических вычислений (курс BIOS8366 университета Вандербильта).
Отзывы о курсах и различные обсуждения:
- Ознакомьтесь с ответом Джека Голдинга (Jack Golding) на Quora. Там вы найдете ссылку на специализацию «Data Science» на Coursera – если вам не нужен сертификат, то можете пройти все 9 курсов бесплатно.
- Другое обсуждение на Quora: как стать специалистом по обработке и анализу данных?
- Большой перечень ресурсов по науке о данных от сайта Data Science Weekly, а также список открытых онлайн-курсов.
Изучаем Pandas
Чтобы работать с Python, вам необходимо познакомиться с пакетом Pandas. Вот список материалов, которые в этом помогут:
- Основное: знакомство с Pandas,
- Руководство: несколько вещей в Pandas, которые я бы хотел знать раньше (блокноты IPython),
- Полезные фрагменты кода Pandas,
Вам также стоит уделить внимание этим ресурсам:
- Cookbook: репозиторий с примерами,
- Структуры данных: раздел DataFrame,
- Изменение формы данных путем транспонирования DataFrame,
- Вычислительные средства: моменты и функции,
- SE: о ковариации простыми словами,
- Groupby: как выполнить split-apply-combine на некотором подмножестве столбцов,
- Визуализация DataFrame.
Еще больше материалов и статей
- Доступная книга Джона Формана (John Foreman) «Data Smart»,
- Курс по науке о данных с блокнотами IPython,
- Статья: основные трудности раздела науки о данных (прочитайте статью и комментарий Джозефа Маккарти (Joseph McCarthy)),
- IPython: ключевые навыки специалистов по работе с данными.
Вопросы, ответы, чаты
На данный момент лучшим местом для поиска ответов на свои вопросы является раздел о машинном обучении на stackexchange.com. Также есть сабреддит: /r/machinelearning. Присоединяйтесь к каналу по scikit-learn на Gitter! Еще стоит обратить внимание на обсуждения на Quora и большой перечень материалов по науке о данных от сайта Data Science Weekly.
Другие вещи, которые полезно знать
- Наука о данных: статья Джона Формана (John Foreman), специалиста по обработке и анализу данных в MailChimp.
- Статья: одиннадцать факторов, ведущих к переобучению, и как их избежать.
- Достойная статья: «Машинное обучение: накладные расходы, которые влечет за собой технический долг» («Machine Learning: The High-Interest Credit Card of Technical Debt»). Цель данной статьи: определить специфические факторы риска при машинном обучении и создать шаблоны, с помощью которых можно их избежать.
- Джон Форман: «Опасный мир машинного обучения».
- Kdnuggets: «Издержки систем машинного обучения».
Вам нужна практика. Пользователь с ником Olympus на Hacker News отметил, что для этого необходимо участвовать в конкурсах и соревнованиях. Kaggle и ChaLearn – это платформы для исследователей, где можно попробовать свои силы, участвуя в различных состязаниях. Здесь вы найдете примеры кода для конкурса Kaggle. Еще вариант: HackerRank.
Послушайте и почитайте, что победители конкурсов Kaggle говорят о предложенных ими решениях. Например, почитайте блог «No Free Hunch».
Конкурсы или состязания лишь один из способов попрактиковаться. Вы можете начать проводить исследования:
- Начните с вопроса. «Самая важная вещь в науке о данных – это вопрос», – говорит доктор Джефф Лик (Dr. Jeff T. Leek). Начните с вопроса, затем найдите реальные данные и проанализируйте их.
- Огласите результаты и обратитесь за экспертной оценкой.
- Устраните найденные проблемы. Поделитесь своими открытиями.
Подробнее о научном методе вы можете узнать здесь и здесь.
Вот еще парочка руководств по машинному обучению:
- Машинное обучение для разработчиков: машинное обучение и библиотека Smile для Java и Scala.
- Материалы для изучения машинного обучения от Джека Симпсона (Jack Simpson).
- Гидеон Вульфсон: как обучить машину.
- Доктор Рэндал Олсон (Randal Olson): примеры машинного обучения, упражнения и руководство. Богатый раздел с дополнительной литературой.
