
В последние пару лет я занимаюсь построением различных планировщиков, и мне пришло в голову поделиться своим нелёгким опытом с коллегами. Речь идёт о двух категориях коллег. Первые — это желающие узнать, как разработать свой scheduler за 21 день. Вторые — те, кому нужен новый scheduler совсем без смс и регистрации, просто чтобы работал. Особенно хотелось бы помочь второй категории людей.

Сначала, как водится, стоит сказать несколько общих слов. Что такое scheduler (планировщик, или, для простоты, «шедулер»)? Это такая компонента системы, которая занимается распределением ресурса или ресурсов системы по потребителям. Разделение ресурса может происходить в двух измерениях: в пространстве и времени. Планировщики чаще всего фокусируются на втором измерении. Обычно под ресурсом подразумевают процессор, диск, память и сеть. Но, что греха таить, шедулить можно и любую виртуальную ерунду. Конец общих слов.
Вместе со словом «планировщик» часто мелькают другие слова, вызывающие куда больший интерес публики: изоляция, честность, гарантии, задержки, дедлайны. Встречаются и некоторые словосочетания: quality of service (QoS), real time, temporal protection. Люди, как показывает практика, часто ждут от планировщиков магических сочетаний свойств, которые не могут быть достигнуты одновременно — с шедулером или без него. Если же нужные свойства достигаются, то обычно планировщики всё равно остаются непредсказуемой вещью в себе и во время их эксплуатации список вопросов только увеличивается. Я попытаюсь приоткрыть завесу тайны их поведения. Но обо всем по порядку.
Чтобы объяснить и предсказать поведение систем, где есть шедулер, люди написали очень много книг, а также разработали целую теорию — и даже не одну. Как минимум стоит упомянуть scheduling theory (теорию расписаний) и queueing theory (неожиданно: в русском варианте это теория массового обслуживания). Все подобные теории довольно сложные и, если честно, просто необозримые. Одних формулировок задач планирования существует целый зоопарк со специальной классификацией. Дело не облегчается тем, что про бóльшую часть задач известно, что они NP-полные или NP-трудные. Даже в удачных случаях, когда есть полиномиальный алгоритм поиска оптимального решения или его неплохое приближение, частенько выясняется: для онлайн-версии задачи (когда заранее неизвестно, какие запросы нужно шедулить или когда они появятся) оптимального алгоритма вообще не существует и надо быть оракулом, чтобы отшедулить всё «как надо». Тем не менее, дела обстоят не так плохо, как может показаться. Человечество уже очень много знает о шедулерах, а некоторые из них даже работают.
Отличная иллюстрация непредсказуемого поведения системы с шедулером — сегодняшний интернет. Это система с множеством шедулеров и абсолютным отсутствием гарантий по полосе и задержке, отсутствием изоляции и подобием справедливости в формате протокола TCP — который, кстати, даже сейчас, спустя десятилетия, изучают и улучшают, и такие улучшения могут давать значимые результаты.
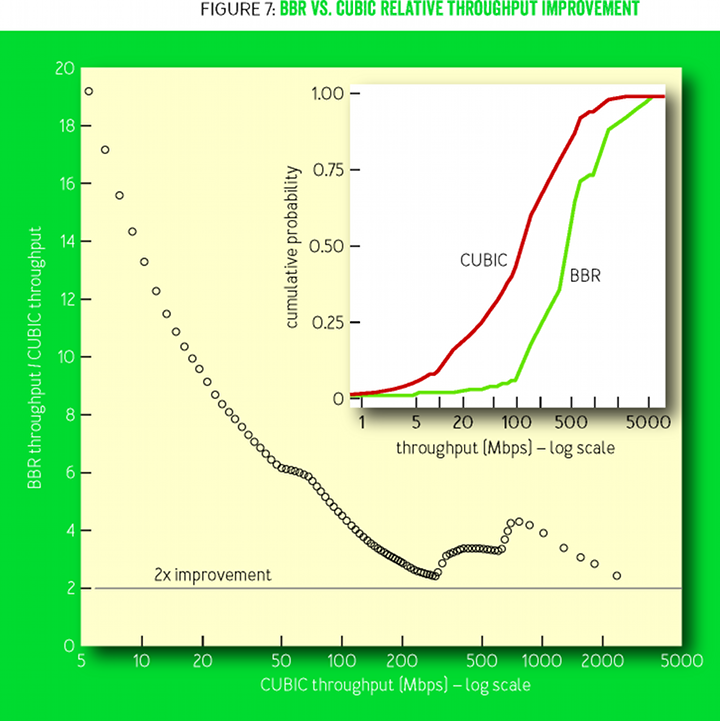
Вспомним TCP BBR от Google. Авторы неожиданно говорят, что создать TCP BBR было невозможно без последних достижений в теории управления, основа которых — нестандартная max-plus-алгебра. Вот, оказывается, куда ушло 30 с лишним лет.
Но это же всё не про шедулер, скажете вы, а про flow control. И будете абсолютно правы. Дело в том, что они очень сильно связаны. В обычных системах шедулеры ставят перед некоторым узким местом — ограниченным ресурсом. Логично: ресурс в дефиците и вроде бы его надо делить справедливо. Допустим, у вас есть такой ресурс — дорожная сеть города — и вы хотите сделать для него шедулер (условно, на выезде из гаража), чтобы уменьшить среднее время в пути. Так вот, оказывается, что среднее время в пути легко вычислить, применив теорему Литтла: оно равно отношению количества машин в системе к скорости их поступления в систему. Если уменьшить делимое, то при прежней пропускной способности время в пути падает. Получается, чтобы не было пробок, надо попросту сделать так, чтобы машин на дорогах стало меньше (ваш капитан). Шедулер с такой задачей не поможет, если нет flow control. В интернете описанную проблему называют bufferbloat.
Если бы я писал свод правил «шедулеростроения», то первое правило было бы таким: контролируй очереди, возникающие за шедулером. Самый часто встречающийся мне способ контролировать размер очереди — MaxInFlight (его продвинутая версия называется MaxInFlightBytes). С ним есть проблема: дело в том, что невозможно правильно выбрать число. Выбор любого фиксированного числа будет гарантировать вам либо неполное использование полосы (1), либо излишнюю буферизацию (2) и, как следствие, увеличение среднего latency, либо, если вам очень повезёт, таймауты и потерю полосы.
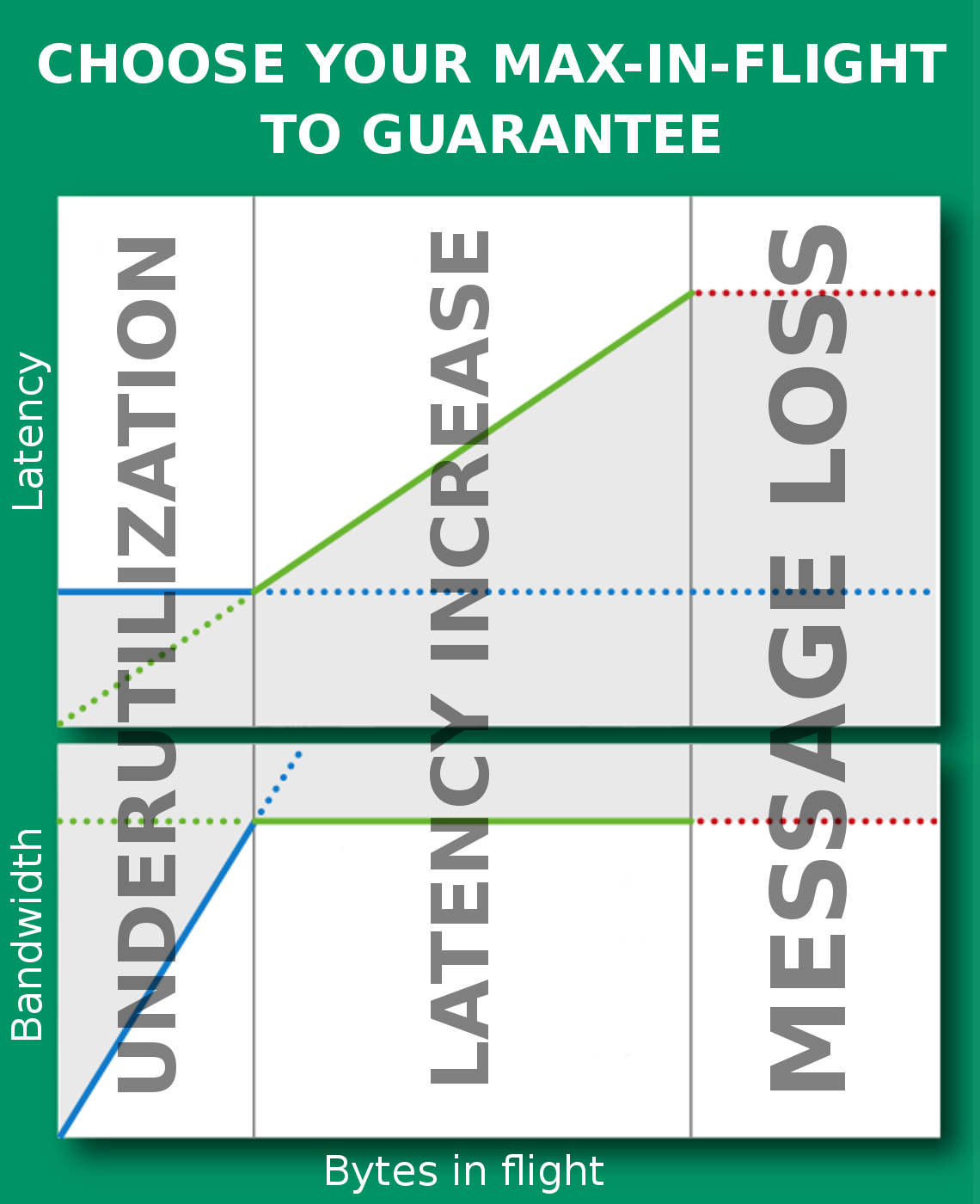
Хороший flow control должен удерживать систему в точке Кляйнрока между режимами (1) и (2), максимизируя отношение throughput/latency (см. TCP BBR).
Есть две классические области применения справедливого планирования — сеть и процессор. GPS — не система позиционирования, а идеальный шедулер, одновременно обслуживающий всех своих пользователей бесконечно малыми порциями. Такой шедулер обеспечивает справедливость max-min. Настоящие шедулеры (WFQ, DRR, SFQ, SCFQ, WF2Q) обслуживают потребителей порциями конечного размера — пакетами, если мы говорим про сеть, или квантами времени, если про процессор. Эти шедулеры разрабатывают так, чтобы их поведение было максимально приближено к идеальному и чтобы они минимизировали лаг — разницу в объёме обслуживания, полученного разными пользователями. Затем для управления выделенной полосой разработчик вводит веса пользователей и начинает говорить, будто они находятся в изолированных системах с меньшей пропускной способностью. Здесь-то и кроется обман. На самом деле изоляции нет.
Пусть у нас есть процессор, который мы хотим потенциально разделять между ста пользователями. Допустим, Витя — хороший пользователь. Он отправляет на обслуживание задачи, которые выполняются за 10 мс, и готов подождать 1 с, потому что понимает: есть еще 99 пользователей. Однако другие могут отправлять задачи, которые иногда выполняются до 1 с. Предположим, что preemption невозможен. Тогда Вите в худшем случае придётся ждать 99 с. Витя, скорее всего, захочет выйти из подобной системы.
Так неинтересно, скажете вы. Что за система такая — без preemption? Система должна уметь обижать, и будет ей счастье. Хорошо, пусть при времени выполнения запроса более 10 мс мы будем включать preemption, передавать управление следующему запросу и вообще использовать лучший из известных науке справедливых шедулеров. Увидит ли Витя ответ за 1 с, как будто он в изоляции? 10 мс (текущий запрос в обслуживании) + 99*10 мс (запросы других пользователей) + 10 мс (Витин запрос) = 1010 мс. Это максимум времени ожидания — другими словами, в такой системе дела обстоят получше.
Витя говорит — отличная система! — и отправляет запрос на 1 мс. А он опять выполняется за 1 с (в худшем случае). В идеально изолированной системе такой запрос выполнился бы за 100 мс, а здесь получилось в 10 раз хуже. Мало того, что от этой секунды никуда ни деться, так ещё и в реальной системе обязательно встретятся другие проблемы:
Получается, справедливость не обеспечивает настоящую изоляцию, зато хорошо делит полосу. Но не тут-то было. Справедливость в таких классических шедулерах мгновенная. Это означает, что, не прислав запрос, когда придёт ваша очередь, вы не получите ресурс, и он будет разделён между остальными желающими. По прошествии длительного промежутка времени (например, 24 часов) может оказаться, что ресурс съелся совсем не в той пропорции, в которой веса были заданы потребителям. В худшем случае потребители могут приходить в любых пропорциях только в те моменты, когда нет других потребителей. В результате веса и потреблённый ресурс могут оказаться вообще никак не связаны. Это шутка, скажете вы, — так никогда не бывает. Но пусть у нас есть распределённая система со своим шедулером на каждой машине. Запросы двух пользователей приходят на две разные машины и никогда не конкурируют за ресурс, потому что на самом деле здесь два ресурса.
Если вы хотите увидеть на графиках ровные линии для агрегированного потока, стоит использовать историческую (long-term) справедливость или квотирование. Но вначале спросите себя, зачем вам это надо.
Предположим, у вас есть справедливый шедулер с весами и вы хотите выделить 0,1% полосы для какого-нибудь служебного трафика, а оставшиеся 99,9% — для остального. В итоге вы получите максимальную задержку x1000. Такой феномен называется bandwidth-latency coupling. Он является прямым следствием из предыдущего рассуждения. Максимальное время задержки обратно пропорционально ширине выделенной полосы. Значит, для приоритетного трафика нужны другие механизмы.
Теорема. В любой системе, загруженной больше чем на 100%, задержка ответов не ограничена сверху никаким числом. Доказательство, я надеюсь, очевидно. Очереди будут копиться, пока что-то не лопнет. Как неправильно измерять и сравнивать временны́е характеристики систем (в том числе с шедулером), рассказывает Гил Тене (можно посмотреть или почитать). Я оставлю тут только иллюстрацию:

Если вам больше не нужен справедливый шедулер, вам, возможно, нужен шедулер, который используется в системах реального времени. Уж там-то всё наверняка хорошо и быстро. Помимо прочего, корректность работы системы реального времени зависит от выполнения задач в заданные сроки. Однако это вовсе не значит, что всё происходит быстро. Например, сроки и задачи бывают вида «сделать и внедрить новый шедулер до начала весеннего ревью». Более того — среднее время ответа в таких системах может быть очень близким к худшему случаю.
Отличительная черта RT-систем: они заранее проверяют расписание на осуществимость. «Осуществимость» здесь означает возможность соблюдения дедлайнов всех задач, а «заранее» — это, скажем, при сборке, при конфигурации системы или при запуске в ней новой задачи. Далее, есть простой способ соблюдать все дедлайны в системе, где это принципиально возможно. Речь идёт про real-time-шедулер. Например, доказано, что алгоритмы EDF (Earliest Deadline First) являются оптимальными для одного процессора. Оптимальность означает, что если для данного набора задач существует хоть какое-то выполнимое расписание, то EDF выполнит задачи до дедлайнов.
Но есть условия, при которых стройная картина мира рушится и система перестаёт укладываться в дедлайны.
Таким образом, EDF, если это возможно, выполняет дедлайны, а если невозможно — наносит процессу максимум ущерба. Скажем по-другому: минимизируя максимальное запаздывание, EDF проваливает дедлайны у максимально большого количества задач. EDF не стоит напрямую применять в условиях перегрузки — которую, как оказывается, зачастую проблематично предсказать и/или предотвратить. Однако способы борьбы всё же существуют.
Для определения загрузки (load factor) в RT-системах используется простая периодическая модель следующего вида. Есть задачи, которые поступают раз в Ti мс и требуют эксклюзивного владения ресурсом в течение Ci мс в худшем случае. Тогда load factor определяется как запрошеное время ресурса на одну секунду реального времени, то есть U = C1/T1 +… + Cn/Tn. В такой простой модели всё понятно, но как подсчитать load factor, если у нас нет никаких периодов, а есть только текущие задачи и их дедлайны?
Тогда load factor определяется иначе. Текущие задачи сортируются по дедлайнам. Далее, начав с одного запроса с наименьшим дедлайном во множестве M, проходим по всем запросам и добавляем их в это множество. М на каждом шаге содержит запросы, которые должны быть полностью выполнены к определённому моменту времени t. Делим их суммарную остаточную стоимость (если вдруг мы уже частично выполнили какие-то из них) на оставшееся время t – now. Полученная величина — load factor U множества M. Чтобы получить текущий load factor, остаётся найти максимум из всех полученных U. Найденная величина, как несложно догадаться, сильно меняется во времени и легко может оказаться больше 1. Расписание невыполнимо c помощью EDF тогда и только тогда, когда load factor > 1.
Если вам важно соблюдать дедлайны, то в качестве метрики, за которой стоит следить, нужно использовать описанный load factor, а не традиционную утилизацию (долю времени, когда система находилась в занятом состоянии).
В real-time-системах есть термин temporal protection. Он используется для описания ситуации, когда никакое поведение пользователя не может поставить под угрозу выполнимость дедлайнов операций других пользователей. По сути, за этими словами скрывается простой факт: когда задача выполняется дольше, чем мы предполагали, надо запретить ей выполняться. Для реализации этой идеи существует набор механизмов, обходящих все костыли, которые игнорируются не-real-time-шедулерами. В итоге задача сводится к резервированию полосы парой чисел (Q, P), где Q — бюджет потребителя (мс), а P — период пополнения бюджета (мс). Несложный вывод: потребитель получит Q/P ресурса. Дальше теория обеспечивает выполнение задач размером не более Q мс, приходящих не чаще чем раз в P мс, за дедлайн P мс — при условии отсутствия перегрузки (переподписки). То есть Q1/P1 +… + Qn/Pn < 1. Прекрасная теория. Есть даже различные способы раздать неиспользованный ресурс (reclaiming).
Но Витю не остановить. Он приходит даже в такую систему, причём с прежним желанием получить свои 10 мс по запросу. Кроме Вити в системе ещё 99 пользователей. Значит, мы должны зарезервировать для Вити 1% полосы, то есть Q/P = 1/100. Потребовав, чтобы значение Q было не менее 10 мс, мы обеспечим выполнение запроса за один период. Предположим, Q = 10 мс. Тогда P = Q/(1/100) = 100Q = 1 с. Это и есть гарантия нашего шедулера.
Конечно, 1000 мс — результат получше, чем 1010 мс, но ненамного. Зато если Витя придёт с желанием получить 1 мс, мы гарантированно сможем предоставить ему ответ за 100 мс. У такого шедулера нет минимального кванта, и он будет переключать контекст минимально необходимое число раз — что, кстати, очень важно для дисков. Когда никто не требует ответов за очень короткие промежутки времени, диск начинает автоматически батчить наибольшие фрагменты данных и пропускная способность возрастает.
Есть и другое важное отличие схемы с резервированием от схемы обычного справедливого шедулера. Оно состоит в том, что мы можем точнее предсказывать, когда закончится выполнение попавшего в систему запроса, и использовать это знание в других уголках системы.
Таким образом, справедливый планировщик реального времени по сравнению с обычным справедливым шедулером обладает несколькими полезными свойствами (такими как предсказуемость, минимальные накладные расходы, бо́льшая гибкость), но к их числу не относится кардинальное улучшение худшего времени ответа.

Сначала, как водится, стоит сказать несколько общих слов. Что такое scheduler (планировщик, или, для простоты, «шедулер»)? Это такая компонента системы, которая занимается распределением ресурса или ресурсов системы по потребителям. Разделение ресурса может происходить в двух измерениях: в пространстве и времени. Планировщики чаще всего фокусируются на втором измерении. Обычно под ресурсом подразумевают процессор, диск, память и сеть. Но, что греха таить, шедулить можно и любую виртуальную ерунду. Конец общих слов.
Вместе со словом «планировщик» часто мелькают другие слова, вызывающие куда больший интерес публики: изоляция, честность, гарантии, задержки, дедлайны. Встречаются и некоторые словосочетания: quality of service (QoS), real time, temporal protection. Люди, как показывает практика, часто ждут от планировщиков магических сочетаний свойств, которые не могут быть достигнуты одновременно — с шедулером или без него. Если же нужные свойства достигаются, то обычно планировщики всё равно остаются непредсказуемой вещью в себе и во время их эксплуатации список вопросов только увеличивается. Я попытаюсь приоткрыть завесу тайны их поведения. Но обо всем по порядку.
Миф №1. Что тут сложного?
Чтобы объяснить и предсказать поведение систем, где есть шедулер, люди написали очень много книг, а также разработали целую теорию — и даже не одну. Как минимум стоит упомянуть scheduling theory (теорию расписаний) и queueing theory (неожиданно: в русском варианте это теория массового обслуживания). Все подобные теории довольно сложные и, если честно, просто необозримые. Одних формулировок задач планирования существует целый зоопарк со специальной классификацией. Дело не облегчается тем, что про бóльшую часть задач известно, что они NP-полные или NP-трудные. Даже в удачных случаях, когда есть полиномиальный алгоритм поиска оптимального решения или его неплохое приближение, частенько выясняется: для онлайн-версии задачи (когда заранее неизвестно, какие запросы нужно шедулить или когда они появятся) оптимального алгоритма вообще не существует и надо быть оракулом, чтобы отшедулить всё «как надо». Тем не менее, дела обстоят не так плохо, как может показаться. Человечество уже очень много знает о шедулерах, а некоторые из них даже работают.
Миф №2. Шедулеры решают все проблемы
Отличная иллюстрация непредсказуемого поведения системы с шедулером — сегодняшний интернет. Это система с множеством шедулеров и абсолютным отсутствием гарантий по полосе и задержке, отсутствием изоляции и подобием справедливости в формате протокола TCP — который, кстати, даже сейчас, спустя десятилетия, изучают и улучшают, и такие улучшения могут давать значимые результаты.

Вспомним TCP BBR от Google. Авторы неожиданно говорят, что создать TCP BBR было невозможно без последних достижений в теории управления, основа которых — нестандартная max-plus-алгебра. Вот, оказывается, куда ушло 30 с лишним лет.
Но это же всё не про шедулер, скажете вы, а про flow control. И будете абсолютно правы. Дело в том, что они очень сильно связаны. В обычных системах шедулеры ставят перед некоторым узким местом — ограниченным ресурсом. Логично: ресурс в дефиците и вроде бы его надо делить справедливо. Допустим, у вас есть такой ресурс — дорожная сеть города — и вы хотите сделать для него шедулер (условно, на выезде из гаража), чтобы уменьшить среднее время в пути. Так вот, оказывается, что среднее время в пути легко вычислить, применив теорему Литтла: оно равно отношению количества машин в системе к скорости их поступления в систему. Если уменьшить делимое, то при прежней пропускной способности время в пути падает. Получается, чтобы не было пробок, надо попросту сделать так, чтобы машин на дорогах стало меньше (ваш капитан). Шедулер с такой задачей не поможет, если нет flow control. В интернете описанную проблему называют bufferbloat.
Если бы я писал свод правил «шедулеростроения», то первое правило было бы таким: контролируй очереди, возникающие за шедулером. Самый часто встречающийся мне способ контролировать размер очереди — MaxInFlight (его продвинутая версия называется MaxInFlightBytes). С ним есть проблема: дело в том, что невозможно правильно выбрать число. Выбор любого фиксированного числа будет гарантировать вам либо неполное использование полосы (1), либо излишнюю буферизацию (2) и, как следствие, увеличение среднего latency, либо, если вам очень повезёт, таймауты и потерю полосы.

Хороший flow control должен удерживать систему в точке Кляйнрока между режимами (1) и (2), максимизируя отношение throughput/latency (см. TCP BBR).
Миф №3. Справедливость нужна для изоляции
Есть две классические области применения справедливого планирования — сеть и процессор. GPS — не система позиционирования, а идеальный шедулер, одновременно обслуживающий всех своих пользователей бесконечно малыми порциями. Такой шедулер обеспечивает справедливость max-min. Настоящие шедулеры (WFQ, DRR, SFQ, SCFQ, WF2Q) обслуживают потребителей порциями конечного размера — пакетами, если мы говорим про сеть, или квантами времени, если про процессор. Эти шедулеры разрабатывают так, чтобы их поведение было максимально приближено к идеальному и чтобы они минимизировали лаг — разницу в объёме обслуживания, полученного разными пользователями. Затем для управления выделенной полосой разработчик вводит веса пользователей и начинает говорить, будто они находятся в изолированных системах с меньшей пропускной способностью. Здесь-то и кроется обман. На самом деле изоляции нет.
Пусть у нас есть процессор, который мы хотим потенциально разделять между ста пользователями. Допустим, Витя — хороший пользователь. Он отправляет на обслуживание задачи, которые выполняются за 10 мс, и готов подождать 1 с, потому что понимает: есть еще 99 пользователей. Однако другие могут отправлять задачи, которые иногда выполняются до 1 с. Предположим, что preemption невозможен. Тогда Вите в худшем случае придётся ждать 99 с. Витя, скорее всего, захочет выйти из подобной системы.
Так неинтересно, скажете вы. Что за система такая — без preemption? Система должна уметь обижать, и будет ей счастье. Хорошо, пусть при времени выполнения запроса более 10 мс мы будем включать preemption, передавать управление следующему запросу и вообще использовать лучший из известных науке справедливых шедулеров. Увидит ли Витя ответ за 1 с, как будто он в изоляции? 10 мс (текущий запрос в обслуживании) + 99*10 мс (запросы других пользователей) + 10 мс (Витин запрос) = 1010 мс. Это максимум времени ожидания — другими словами, в такой системе дела обстоят получше.
Витя говорит — отличная система! — и отправляет запрос на 1 мс. А он опять выполняется за 1 с (в худшем случае). В идеально изолированной системе такой запрос выполнился бы за 100 мс, а здесь получилось в 10 раз хуже. Мало того, что от этой секунды никуда ни деться, так ещё и в реальной системе обязательно встретятся другие проблемы:
- Непредсказуемое переменное число пользователей — если их окажется не 100, а 1000, то ждать придётся 10 с.
- Высокая стоимость переключения контекста. Например, если планировать запросы к HDD, то переключение между пользователями может подразумевать seektime на уровне 8 мс и, как следствие, приводить к максимальному ожиданию 800 мс, уменьшению полосы диска и росту очередей у всех пользователей.
- Часто такие Вити хотят сделать не один запрос, а присылают их помногу. Запросы скапливаются в очереди перед шедулером и ждут друг друга.
- Прочий приоритетный трафик.
- Не самый лучший из известных науке шедулер может вносить дополнительную задержку (конкретные числа и формулы ищите по ключевым словам latency-rate server).
Миф №4. Справедливость нужна, чтобы разделить полосу в соответствии с весом
Получается, справедливость не обеспечивает настоящую изоляцию, зато хорошо делит полосу. Но не тут-то было. Справедливость в таких классических шедулерах мгновенная. Это означает, что, не прислав запрос, когда придёт ваша очередь, вы не получите ресурс, и он будет разделён между остальными желающими. По прошествии длительного промежутка времени (например, 24 часов) может оказаться, что ресурс съелся совсем не в той пропорции, в которой веса были заданы потребителям. В худшем случае потребители могут приходить в любых пропорциях только в те моменты, когда нет других потребителей. В результате веса и потреблённый ресурс могут оказаться вообще никак не связаны. Это шутка, скажете вы, — так никогда не бывает. Но пусть у нас есть распределённая система со своим шедулером на каждой машине. Запросы двух пользователей приходят на две разные машины и никогда не конкурируют за ресурс, потому что на самом деле здесь два ресурса.
Если вы хотите увидеть на графиках ровные линии для агрегированного потока, стоит использовать историческую (long-term) справедливость или квотирование. Но вначале спросите себя, зачем вам это надо.
Миф №5. Выдели мне узенький канал для приоритетного трафика
Предположим, у вас есть справедливый шедулер с весами и вы хотите выделить 0,1% полосы для какого-нибудь служебного трафика, а оставшиеся 99,9% — для остального. В итоге вы получите максимальную задержку x1000. Такой феномен называется bandwidth-latency coupling. Он является прямым следствием из предыдущего рассуждения. Максимальное время задержки обратно пропорционально ширине выделенной полосы. Значит, для приоритетного трафика нужны другие механизмы.
Миф №6. Я загрузил систему на полную и начал мерить задержку
Теорема. В любой системе, загруженной больше чем на 100%, задержка ответов не ограничена сверху никаким числом. Доказательство, я надеюсь, очевидно. Очереди будут копиться, пока что-то не лопнет. Как неправильно измерять и сравнивать временны́е характеристики систем (в том числе с шедулером), рассказывает Гил Тене (можно посмотреть или почитать). Я оставлю тут только иллюстрацию:

Миф №7. Real-time scheduler может гарантировать выполнение моих дедлайнов
Если вам больше не нужен справедливый шедулер, вам, возможно, нужен шедулер, который используется в системах реального времени. Уж там-то всё наверняка хорошо и быстро. Помимо прочего, корректность работы системы реального времени зависит от выполнения задач в заданные сроки. Однако это вовсе не значит, что всё происходит быстро. Например, сроки и задачи бывают вида «сделать и внедрить новый шедулер до начала весеннего ревью». Более того — среднее время ответа в таких системах может быть очень близким к худшему случаю.
Отличительная черта RT-систем: они заранее проверяют расписание на осуществимость. «Осуществимость» здесь означает возможность соблюдения дедлайнов всех задач, а «заранее» — это, скажем, при сборке, при конфигурации системы или при запуске в ней новой задачи. Далее, есть простой способ соблюдать все дедлайны в системе, где это принципиально возможно. Речь идёт про real-time-шедулер. Например, доказано, что алгоритмы EDF (Earliest Deadline First) являются оптимальными для одного процессора. Оптимальность означает, что если для данного набора задач существует хоть какое-то выполнимое расписание, то EDF выполнит задачи до дедлайнов.
Но есть условия, при которых стройная картина мира рушится и система перестаёт укладываться в дедлайны.
- Overrun. В hard-RT-системах предполагается, что мы знаем, сколько задача будет выполняться в худшем случае. Однако в неидеальном мире это не так, и завершение задачи может потребовать больше времени. Если мы позволим задаче выполняться дольше положенного, то поставим под угрозу выполнимость других задач. В случае с EDF возникнет эффект домино.

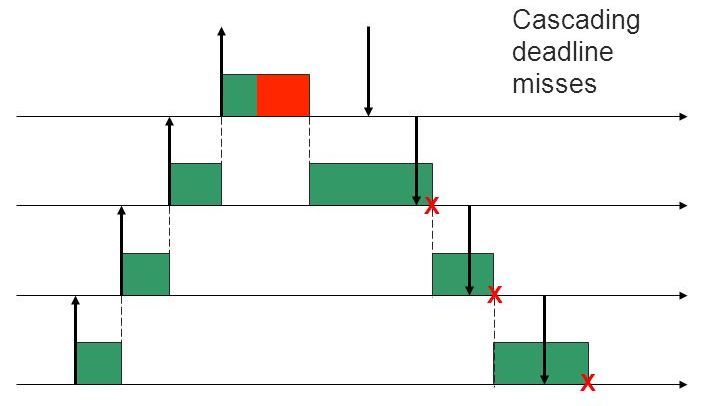
- Overload. Не исключено, что вновь пришедшая задача не укладывается в желаемые сроки. Если мы примем её к выполнению, то опять получим эффект домино. Обычно в подобных случаях констатируют перегрузку системы и принимают меры, чтобы её устранить. Например — отказывают новой или каким-то текущим задачам в выполнении. Ещё один вариант — схема с пересмотром гарантий и откладыванием дедлайнов некоторых задач.
Таким образом, EDF, если это возможно, выполняет дедлайны, а если невозможно — наносит процессу максимум ущерба. Скажем по-другому: минимизируя максимальное запаздывание, EDF проваливает дедлайны у максимально большого количества задач. EDF не стоит напрямую применять в условиях перегрузки — которую, как оказывается, зачастую проблематично предсказать и/или предотвратить. Однако способы борьбы всё же существуют.
Миф №8. Систему нельзя загрузить больше чем на 100%
Для определения загрузки (load factor) в RT-системах используется простая периодическая модель следующего вида. Есть задачи, которые поступают раз в Ti мс и требуют эксклюзивного владения ресурсом в течение Ci мс в худшем случае. Тогда load factor определяется как запрошеное время ресурса на одну секунду реального времени, то есть U = C1/T1 +… + Cn/Tn. В такой простой модели всё понятно, но как подсчитать load factor, если у нас нет никаких периодов, а есть только текущие задачи и их дедлайны?
Тогда load factor определяется иначе. Текущие задачи сортируются по дедлайнам. Далее, начав с одного запроса с наименьшим дедлайном во множестве M, проходим по всем запросам и добавляем их в это множество. М на каждом шаге содержит запросы, которые должны быть полностью выполнены к определённому моменту времени t. Делим их суммарную остаточную стоимость (если вдруг мы уже частично выполнили какие-то из них) на оставшееся время t – now. Полученная величина — load factor U множества M. Чтобы получить текущий load factor, остаётся найти максимум из всех полученных U. Найденная величина, как несложно догадаться, сильно меняется во времени и легко может оказаться больше 1. Расписание невыполнимо c помощью EDF тогда и только тогда, когда load factor > 1.

Если вам важно соблюдать дедлайны, то в качестве метрики, за которой стоит следить, нужно использовать описанный load factor, а не традиционную утилизацию (долю времени, когда система находилась в занятом состоянии).
Миф №9. Справедливый планировщик реального времени
В real-time-системах есть термин temporal protection. Он используется для описания ситуации, когда никакое поведение пользователя не может поставить под угрозу выполнимость дедлайнов операций других пользователей. По сути, за этими словами скрывается простой факт: когда задача выполняется дольше, чем мы предполагали, надо запретить ей выполняться. Для реализации этой идеи существует набор механизмов, обходящих все костыли, которые игнорируются не-real-time-шедулерами. В итоге задача сводится к резервированию полосы парой чисел (Q, P), где Q — бюджет потребителя (мс), а P — период пополнения бюджета (мс). Несложный вывод: потребитель получит Q/P ресурса. Дальше теория обеспечивает выполнение задач размером не более Q мс, приходящих не чаще чем раз в P мс, за дедлайн P мс — при условии отсутствия перегрузки (переподписки). То есть Q1/P1 +… + Qn/Pn < 1. Прекрасная теория. Есть даже различные способы раздать неиспользованный ресурс (reclaiming).
Но Витю не остановить. Он приходит даже в такую систему, причём с прежним желанием получить свои 10 мс по запросу. Кроме Вити в системе ещё 99 пользователей. Значит, мы должны зарезервировать для Вити 1% полосы, то есть Q/P = 1/100. Потребовав, чтобы значение Q было не менее 10 мс, мы обеспечим выполнение запроса за один период. Предположим, Q = 10 мс. Тогда P = Q/(1/100) = 100Q = 1 с. Это и есть гарантия нашего шедулера.
Конечно, 1000 мс — результат получше, чем 1010 мс, но ненамного. Зато если Витя придёт с желанием получить 1 мс, мы гарантированно сможем предоставить ему ответ за 100 мс. У такого шедулера нет минимального кванта, и он будет переключать контекст минимально необходимое число раз — что, кстати, очень важно для дисков. Когда никто не требует ответов за очень короткие промежутки времени, диск начинает автоматически батчить наибольшие фрагменты данных и пропускная способность возрастает.
Есть и другое важное отличие схемы с резервированием от схемы обычного справедливого шедулера. Оно состоит в том, что мы можем точнее предсказывать, когда закончится выполнение попавшего в систему запроса, и использовать это знание в других уголках системы.
Таким образом, справедливый планировщик реального времени по сравнению с обычным справедливым шедулером обладает несколькими полезными свойствами (такими как предсказуемость, минимальные накладные расходы, бо́льшая гибкость), но к их числу не относится кардинальное улучшение худшего времени ответа.
