Comments 21
Первая статья плохо настроила обучение — они берут плохие настройки sgd и потом говорят, что в то же время можно обучить много моделей, но с хорошими настройками. Ну как бы да, экспоненциальный decay — наше все, он сильно все ускоряет по сравнению с линейным. После чего они сохраняют N снэпшотов из одного запуска и делают тест в N раз медленнее.
Ко второй статье основная критика это что она 1 — не так то и ускоряет. 15-20% это ерунда, нужно ускорение на порядок как минимум, чтобы начать утверждать, что оно стоит того. см. batch normalization, там ускорение больше, чем на порядок. 2 — не везде работает. это значит, что просто взять и вставить нельзя — надо тюнить. Если надо тюнить, то надо больше запусков. Больше запусков — вся разработка дольше. Так что непонятно.
ПС — какой к черту «отжиг»? Переводить текст из довольно узкой области и вставляеть непонятные термины в гуглоперевод это как-то так себе.
По поводу гуглоперевода, коллега, попросил бы не бросаться обвинениями.
В теории, если взять слишком малый шаг, нас мало выбьет из локального минимума и мы вновь скатимся к тому же. Как правильно выбратьправильный цикл? Не надёжнее ли на практике действовать как деды и просто снижать шаг? И сравнение берётся с заранее фиксированным временным бюджетом, быть может с другим бюджетом будет уже не так, это на совести авторов статьи, которую ещё предстоит проверить.
А что не так с термином "отжиг"?
По поводу второй статьи, автор на Reddit поясняет, что она была сделана за несколько дней в формате "индивидуального science-хакатона". Там же начали обсуждать, как быть с тенденцией публиковать и ссылаться на пусть и не до конца проверенные, но самые свежие идеи и результаты на arXiv: это плохо или хорошо?
В том контексте, в котором annealing используется в литературе про диплернинг, это явно не химический процесс отжига. С другой стороны, если он изначально был введен по аналогии с этим процессом, то да, я не прав.
Гуглоперевод, говорите…
Про первое — по мне, главная практическая проблема, что часто bottleneck — это скорость inference, а не тренировки, особенно финальной. А тут inference все еще в N раз медленней.
А они сравнивали качество ансамбля, которые получается их техникой, с тем, который достигается полной тренировкой несколько раз? Ну и да, если плохо тренировать бейзлайн, много пейперов написать можно…
Про второе — AFAIR, часто первые слои жрут намного больше вычислений, поэтому если первую половину выкинуть, то должно быть ускорение сильно больше, чем в два раза.
Тем не менее, из разряда идей «хозяйке на заметку» — обе статьи интересные.
Все-таки скорость обучения тоже важна если данных много, GPU не топовый, модель сложная, идей много надо проверить…
ResNet-110, Cifar-10
Оригинальная статья авторов архитектуры ResNet
Смотрим таблицу 6: ошибка классификации на CIFAR-10: 6.43 (6.61±0.16)
Статья про «отжиг» (ансамбль снимков модели): Фигура 1.2 — ошибки классификации CIFAR-10
Resnet-110 Single Model: 5.52 (по оригинальной статье)
Resnet-110 Snapshot Ensemble: 5.32
Остальные результаты тоже можно проверить.
Спасибо за разбор!
По первой статье не очень понятно, чем их схема принципиально лучше нескольких рестартов из разных начальных точек с одновременным уменьшением числа шагов на каждый рестарт (до периода косинуса). Судя по тому, что training loss каждый период всё равно раздергивается почти до исходного, по сути получаем те же рестарты, но рядом с предыдущим локальным минимумом. Есть соображения, почему так предпочтительнее?
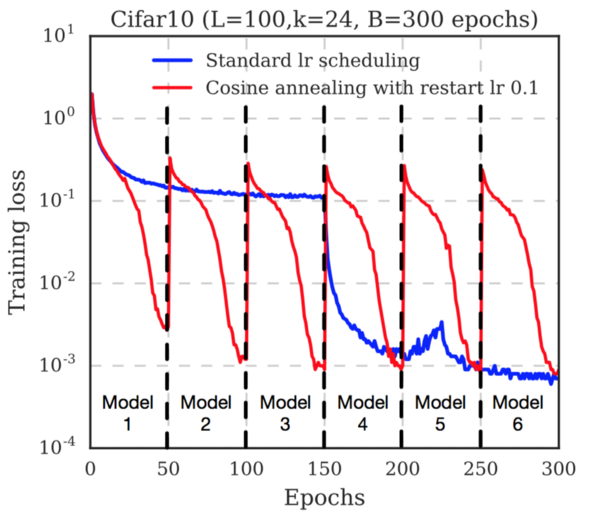
Синий график, где явно криво настроен learning rate, игнорируем, смотрим на их красный график. Там видно, что каждый раз, когда LR увеличивается (т.е. каждый период косинуса) training loss прыгает вверх до ~5e-1. По первому сегменту видно, что с нуля этот loss достигается за ~10 эпох при периоде косинуса в 50. То есть получаем от силы 30% ускорение, что на сильно быстрее на мой взгляд не тянет, особенно учитывая резервы по настройке learning rate.
Поэтому вопрос, что лучше (и главное почему) — их схема или, например, взять их LR schedule за первые 50 эпох, обучить 6 моделей по 50 эпох с нуля с разными инициализациями и сделать ансамбль из них, — остался открытым. Во втором случае индивидуальные модели будут похуже, но если за счет разных инициализаций они окажутся более разнообразными, то их ансамбль может сработать лучше.
Я бы применял их схему чуть попозже, после первоначального грубого обучения. Например, первые слои уже обучились типовым фильтрам Габора. Но это только мое предположение, все надо проверять. В этом и заключается эмпирический подход.
Отжиг и вымораживание: две свежие идеи, как ускорить обучение глубоких сетей