Comments 327
Очередной беребезчик, добро пожаловать в функциональный лагерь, у нас есть плюшки.
Может кто-то пояснить нубу, как всё вот это ФП применить, ну хотя бы к такой вещи, как построение интерфейса? Вот я понимаю ООП: вот у нас класс кнопки, вот класс окна. Вот у класса окна метод: добавить кнопку, а вот у кнопки метод: нажать. Потому что пример с Report это круто, но тут понятно: имеем поток данных на входе и поток на выходе — посередине функция. Как ФП работает с UI (если работает, конечно)?
Но на ООП я смогу сделать и отчет, и поток обработать. А на ФП, выходит, не могу? То есть чтобы создать не консольную программку, а что-то посерьезнее, мне нужно два языка?
Но на ООП я смогу сделать и отчет, и поток обработать. А на ФП, выходит, не могу? То есть чтобы создать не консольную программку, а что-то посерьезнее, мне нужно два языка?
А много вы промышленных языков знаете, которые умеют ФП и не умеют ООП или наоборот?
И в чём тогда преимущества F#, если со львиной долей задач он ничем не поможет?
И в чём тогда преимущества F#, если со львиной долей задач он ничем не поможет?
В смысле? Я чот не понял наверное.
F# как раз поможет со всеми задачами, в которые, например, C# умеет.
И многие решает проще.
Выше по ветке написано, что
Никак, потому что ФП не про UI, а про бекенд. Как раз таки UI — это ООП. Если у тебя в руках сова — не надо все превращать в глобус
Если мне нужен UI не на веб-стеке, будет ли для меня выгода от использования F# выше чем затраты на его обслуживание?
Во-вторых, независимо от того, веб у вас или десктоп, в приложении есть бизнес-логика. Ее удобней делать на чистых функциях, как я и написал в статье. Потому что это стабильней и легче тестировать. Сам слой презентации вы можете описать на C#, если вам так больше нравится. Они с F# нормально уживаются даже в рамках одного солюшена.
Если мне нужен UI не на веб-стеке, будет ли для меня выгода от использования F# выше чем затраты на его обслуживание?
Я UI не занимаюсь вообще, поэтому это не ко мне :) Знаю что его на F# делают. Ссылки в каментах.
А если вообще — да, плюсы от использования F# могут перекрыть затраты на поиск разрабов F# / перевоспитание C#-истов. Но не для малого бизнеса имхо.
Вы исходите из предпосылки, что F# — это только про ФП. А между тем там есть и ООП-штуки, и некоторые из них очень интересные — object expressions, например, которых временами не хватает в C#.
Я прошу прощения, но F# в силу своих истоков является мультипарадигменным. Т.е вы можете в рамках F# комбинировать традиционные и новые подходы.
У меня в команде фронты божаться что пишут все в функциональном стиле, но в коде их не ковырялся, не могу подтвердить.
Ну возьмите хотябы Реакт в качестве примера с единонаправленным потоком данных — UI — это чистая функция зависящая только он входных данных (в данном случае props, state и context) — результатом этой функции является HTML
Каждый компонент реакта — это класс как бы
Да это класс (но может быть и чистая функция, с пропсами на входе), но классом он только является чтоб иметь доступ к некоторому внутреннему состоянию и метода лайфсайкла. Тем не менее, результатом является вызов render(), хоть пропсу и стейт не подаются в эту функцию явно.
в функциональном программировании вы тоже можете добится внутреннего состояния функции (например с помощью замыканий или монад).
Не каждый: React поддерживает и функциональные компоненты.
Как ФП работает с UI (если работает, конечно)?
Да вот сразу пример (с гифками):
https://github.com/Zaid-Ajaj/tabula-rasa
В некоторых фронтенд фреймворках UI реализован в функциональном стиле.
Там есть иммутабельное хранилище состояния, из которого путем приложения функций с шаблонами прямо выводится текущее состояние интерфейса. Чтобы поменять интерфейс, опять же, чистые функции меняют состояние (точнее, создают новое).
Наличия семантических объектов, к слову, это не отрицает. Просто это не мутабельные объекты, а иммутабельные структуры данных.
Пример: связка React-Redux в мире JS.
Пример: связка React-Redux в мире JS.
В React-Redux состояние мутабельное и работа с ним ведется при помощи классического мутабельного сценария. Ничего иммутабельного там нет и не пахло даже.
Устал уже это повторять.
Если коротко, есть глобальная переменная state, в которой лежит глобальный стейт приложения, когда ее надо обновить, то делается, условно, state = calculateNewState(state), странные люди по неизвестным мне причинам считают, что у них что-то иммутабельно там, функционально и все такое.
Вопрос только в том, в пользовательском коде она находится или в библиотечном.
Вопрос в том, какое апи используется для работы с ней. В редаксе используется обычное процедурное апи, никакого функционального кода там просто нет. Пользователь библиотеки берет и совершенно процедурным образом вызывает процедуру setState(state) которая меняет стейт со вполне процедурной семантикой, еще и колбек может вторым аргументом принимать ("после того как поменяли стейт — сделайте еще вон ту штуку"). Функциональщина изо всех щелей прямл.
В любом случае, исходно вы говорили про мутабельность — а вот это точно мимо. Что API react, что API redux построены на том, что объект, хранящий текущее состояние, неизменяем.
setState используется в React, а не в Redux.
Да, конечно. Сути не меняет — в Redux у вас будет dispatch(action) — тоже процедура :)
Функциональным подход бы был, если бы dispatch возвращал новый стейт (или новый стор, в котором лежит новый стейт, допустим), и это было бы единственным способом данный новый стейт получить. По факту же диспатч меняет стейт внутри текущего стора.
В любом случае, исходно вы говорили про мутабельность — а вот это точно мимо.
Ну как же мимо? У вас мутабельное хранилище состояния. Вы, конечно, можете попытаться вывернуть все и сказать, что у вас хранилище иммутабельно, просто вы не состояние в нем меняете, а само хранилище меняете :)
Но это будет просто софистика. От того, что вы врапнули один объект в другой иммутабельности не появляется.
Софистика — это то чем занимаетесь вы, а иммутабельность — это свойство структуры данных, а не всей программы в целом.
Ну так структура данных, с которой мы работаем (стор), не иммутабельна, в ней есть поле, которое меняет значение (стейт), конец истории.
Вы, конечно, всегда можете взять мутабельную структуру завернуть ее во враппер и потом менять целиком внутри враппера. Появится ли так иммутабельность? Ну конечно нет, это просто перекладывание из пустого в порожнее.
Пользовательская структура данных — state — иммутабельна. Что внутри у библиотечной — детали реализации.
Пользовательская структура данных — state — иммутабельна.
Не-не-не, слушайте. Пользователь работает не со стейтом, он работает со стором. Он на сторе вызывает getState и dispatch, это и есть апи редакса. Это и есть та самая структура, с которой он взаимодействует.
Вот если у вас есть, например, строка, вы берете и делаете к ней запрос подстроки str.substring(n, m) (аналог getState) или замену подстроки str.replace(n, s) (аналог dispatch) — иммутабельность результата substring и аргумента stringReplace не имеет никакого отношения к тому, что сама строка, к которой вы эти методы применяете, мутабельна. Аналогичная история с редаксом.
Именно стор является хранилищем состояния, как объект, предоставляющий апи для запросов и апдейтов. А то, что стор возвращает, когда вы у него требуете текущее состояние — это лишь результат запроса к хранилищу.
Опять же, если вы из бд будете получать иммутабельную коллекцию строк — можно ли сделать вывод, что ваша бд является иммутабельным хранилищем или что состояние, которое в бд хранится — иммутабельно? Нет! Это мутабельное хранилище с процедурным апи.
Вот только строки в рамках общепринятых определений — иммутабельны.
В рамках каких общепринятых определений? В сишке null-terminated string с каких пор иммутабельными стали?
Иммутабельным оно будет ровно тогда, когда операции вроде replace будут возвращать вам новую строку, а не модифицировать старую. dispatch же не возвращает новый стор — он модифицирует старый.
Если бы dispatch возвращал новый стор — redux был бы с иммутабельным апи, все верно. Но это не так.
Строки в javascript, java и c# в рамках общепринятых определений считаются иммутабельными.
Да ради бога, но, еще раз, они иммутабельны потому, что когда вы выполняете операцию вида replace или похожую, то вам возвращается новая строка. А старая остается как была. Если же replace меняет текущую строку — то строки у вас мутабельные.
Так вот, dispatch в редаксе меняет текущий стор, не создает нового.
Вот только строки в рамках общепринятых определений — иммутабельны. Но вы можете продолжать выдумывать свои определения.
И что? Иммутабельные строки можно изменять процедурно? Ну вот есть функция
dispatch(targetString)Как функция должна быть написана, чтобы строка поменялась?
Нет, иммутабельные строки нельзя изменять процедурно. Точно так же как нельзя процедурно изменить иммутабельное состояние, только заменить его новым.
Точно так же как нельзя процедурно изменить иммутабельное состояние
Но в редаксе я через диспатч меняю состояние. Вывод? Оно мутабельно.
только заменить его новым.
скажите, вы когда в бд запись обновляете — это изменение имеющегося состояния или создание нового? Как отличить два этих варианта по поведению?
Нет, вы через дистатч заменяете состояние новым. Старый объект состояния остается в неизменном виде.
Какой старый объект? С чего вы взяли, что он вообще есть? Редакс вам не дает никаких гарантий по поводу того, как именно хранится состояние. Он дает гарантии лишь по поводу того, что вернет getState. Возможно, ваш объект формируется ровно в тот момент, когда вызван getState, а до этого ег ов принципе не существует. Конечно же он каждый раз будет новый. Точно так же как каждый раз у вас будет новой строкой результат ф-и substring. Но строки при этом как были мутабельные так ими и остаются, если replace работает мутабельно. Важно поведение replace, а не поведение substring, понимаете?
Повторяю вопрос про бд — вы когда там данные обновляете, то вы их заменяете на новые или модифицируете существующие?
Но строки при этом как были мутабельные так ими и остаются, если replace работает мутабельно.
Я бы в качестве примера привел массивы в JS. Да, у них есть куча иммутабельных методов. slice(), map(), но ведь есть и мутабельные, такие как sort() или splice(). И если мы пользуемся только иммутабельными, то да, мы массивами пользуемся словно иммутабельными. Но как только мы начинаем менять элементы в самом массиве — он перестает считаться иммутабельным, даже если до этого мы 10 раз воспользовались иммутабельными методами.
const array = oldArray
.map(/* ... */)
.filter(/* ... */)
.reduce(/* ... */);
// Да, пока мы им пользуемся в ФП стиле
array[5] = null;
// Плевать, как мы раньше пользовались, теперь это обычная процедурщина, пускай и с элементами ФП.Девушке вполне достаточно один раз переспать с мужчиной, чтобы перестать быть девственницой, даже если до 16-ти она ни разу ни с кем не целовалась.
Э-э-э, нет. Редакс именно что дает гарантии что это будет новый объект, а старый останется на месте (при условии соблюдения контракта всеми редьюсерами).
А я что сказал? Редакс вам дает гарантии того, что возвращается из getState, точно так же, как в случае строк, даются гарантии того, что возвращается из substring. Только это все не имеет отношения к иммутабельности. К иммутабельности имеет отношение то, как работает dispatch (aka replace). В случае иммутабельных строк replace возвращает новую строку, оставая неизменной старую, а в случае dispatch — вам возвращается что угодно в зависимости от упоротости миддлеваре и при этом старый стор оказывается измененным (в частности, если на старом сторе вызвать getState, то он вернет не то, что раньше).
Редакс вам дает гарантии того, что возвращается из getState
Никаких гарантий Редакс не дает, это ведь процедурный фреймворк. Вот пример. Открываем доку thunk, берем их пример и смотрим, что возвращает getState().
function incrementAsync() {
return (dispatch, getState) => {
const state1 = getState();
setTimeout(() => {
const state2 = getState();
dispatch(increment());
}, 1000);
};
}getState вроде как один, вроде как чистая функция, а возвращает совершенно разные стейты, если они поменялись за эту секунду.
Во-вторых, это пример процедурности — грязно мутируется глобальная переменная. И процедура getState() — не чистая функция.
Так зачем этот процедурный фреймворк называть функциональным?
Не вижу каким образом ваш пример демонстрирует отсутствие иммутабельности state1 или state2.
При чем тут state1/state2 если мы обсуждаем стор?
Потому что стор является хранилищем состояния в редаксе.
Напомню про исходный тезис:
В некоторых фронтенд фреймворках UI реализован в функциональном стиле.
Там (в Redux) есть иммутабельное хранилище состояния, из которого путем приложения функций с шаблонами прямо выводится текущее состояние интерфейса.
Это неверно, ничего иммутабельного в редаксе нет. Ничего функционального нет тоже.
Нет, иммутабельные строки нельзя изменять процедурно. Точно так же как нельзя процедурно изменить иммутабельное состояние, только заменить его новым.
Стоп. Но я ведь вызываю процедуру dispatch и состояние меняется.
Ну вот, допустим, хочу покрыть тестами. Как это выглядит в ФП:
const newState = dispatch(data, oldState);
// старый стейт остался старым
checkIsOld(oldState);
// новый стейт стал новым
checkIsNew(newState); Как это делается в процедурном редаксе:
// мне тут даже не надо передавать стейт, это грязная процедура!
dispatch(data);
// опа, поменялась глобальная переменная!
checkIsOld(globalState); То есть одна из немногих функций редакса, его core, который мы постоянно используем в клиентском коде:
1. Зависит не только от аргументов
2. Имеет серьезные побочные эффекты
3. Является недетерминированно
Теперь я открываю википедию, статью «Функциональное программирование» и читаю:
понятия «функции» в императивном программировании заключается в том, что императивные функции могут опираться не только на аргументы, но и на состояние внешних по отношению к функции переменных, а также иметь побочные эффекты и менять состояние внешних переменных. Таким образом, в императивном программировании при вызове одной и той же функции с одинаковыми параметрами, но на разных этапах выполнения алгоритма, можно получить разные данные на выходе из-за влияния на функцию состояния переменных. А в функциональном языке при вызове функции с одними и теми же аргументами мы всегда получим одинаковый результат: выходные данные зависят только от входных
И, если имеем хоть каплю критического мышления, чтобы снять с ушей маркетологическую лапшу, то понимаем, что Редакс — обычная процедурщина, которая косит под ФП, но противоречит его основным принципам.
Ну, модульные тесты как бы должны тестировать ваш код (редьюсеры), а не библиотечный (стор).
Но даже если вы при тестировании редьюсера используете стор — ничего не мешает старый объект сохранить:
const oldState = store.getState();
dispatch(data);
const newState = store.getState();
// старый стейт остался старым
checkIsOld(oldState);
// новый стейт стал новым
checkIsNew(newState);Но даже если вы при тестировании редьюсера
А при чем ту тестирование редьюсера, если речь о тестировании кода, который работает с хранилищем?
Но даже если вы при тестировании редьюсера используете стор — ничего не мешает старый объект сохранить:
Вы не тот объект сохранили, надо:
const oldStore = store;
store.dispatch(data);
const newStore = store;
checkIsOld(oldStore.getState());
checkIsNew(newStore.getState()); А при чем тут тестирование кода, который работает с хранилищем, когда я говорю о работе с состоянием?
Вы не тот объект сохранили
Нет, это вы не тот объект сохранили. Потому что иммутабельным является состояние, а не стор.
А при чем тут тестирование кода, который работает с хранилищем, когда я говорю о работе с состоянием?
Каким состоянием? У вас есть хранилище и в нем хранятся данные. Вы эти данные можете запрашивать через getState(). getState() вам возвращает некоторую структуру. Опустим тот факт, что данная структура мутабельна, и зададимся вопросом — при чем тут вообще ее свойства?
Еще раз, вы делаете запрос к бд, вам возвращается иммутабельная коллекция иммутабельных строк. Ваше состояние в бд иммутабельно? Да или нет?
Но даже если вы при тестировании редьюсера используете стор — ничего не мешает старый объект сохранить:
Я понимаю как тестировать процедурный код, спасибо.
Не знаю что обсуждаете вы, но я спорю вот с этим:
В React-Redux состояние мутабельное
let store = Redux.createStore( ()=> [1,2,3] )
someWildFunc( store.getState() )
console.log( store.getState() ) // [3,2,1]
function someWildFunc(a) { return a.reverse() }Состояние вы, конечно, можете не менять, но именно редакс вам никаких гарантий не даёт. Более того, он даже не узнает о том, что состояние где-то поменялось, что приведёт, странного вида глюкам, когда состояние в сторе одно, а реактивно зависимая от него вьюшка показывает другое. И сиди, ищи концы, где кто забыл вызвать slice перед reverse.
Иммутабельность — оно про невозможность изменений, а не про только лишь их отсутствие в конкретном месте в конкретное время.
«состояние в редакс иммутабельное»
Мне непонятно, зачем вообще обсуждать, мутабелен или нет объект, который возвращается из getState()? Какое это отношение к делу имеет? Допустим, он мутабелен, но при этом getState() бы возвращал глубокую копию внутреннего _state. Что-то вообще бы изменилось, кроме перформанса и принципиальной невозможности сломать этот внутренний стейт, в отличии от имеющейся ситуации?
Если вы в нёдра рантайма отдаёте функцию State -> State, то всё чисто, ага.
Ну нет, если functionalSetState(f) = setState(f(getState())) то ничего чисто тут не будет. Вопрос в том, можем ли мы заметить то, что где-то что-то было мутировано (понятное дело в js нету способов это надежно обеспечить, по-этому речь о том что мы это не заметим, если сами себя ограничиваем и используем библиотеку идиоматическим способом).
Так если ваш язык чистый, и вы отдаёте функцию с упомянутой сигнатурой, то заметить, что что-то там мутируется, вы не сможете.
В данном случае мы можем, т.к. у нас есть точка входа, которая предоставляет апи (store), у которой мы просим состояние (getState()) и оно разное до и после store.dispatch()
Ну как в хаскеле, вы отдаёте набор IO-экшонов, которые абсолютно чистые (потому что это описание), а рантайм чё-то там потом мутирует и всё такое.
В хаскеле мы, формально, в ф-ю засовываем World и возвращаем новый World, а монадический интерфейс гарантирует, что старый World потрогать не удастся. По-этому мы и не можем выяснить, изменился старый World или нет. Тут у нас ситуация такая:
const oldState = store.getState()
store.dispatch(f) //передаем в стор чистую ф-ю
const newState = store.getState()
// oldState != newState, newState = f(oldState)в принципе такой диспатч ничем не отличается от:
const oldState = store._state
store._state = f(oldState)
const newState = store._state
// oldState != newState, newState = f(oldState)с-но диспатч внутри что и делает — применяет f к стейту и заменяет новым старый
Пример: связка React-Redux в мире JS.
Меня так забавляет, когда люди процедурный фреймворк приводят в пример в качестве функционального.
В комментариях советуют Elmish, но я бы порекомендовал взглянуть на Elm.
У него введение лучше. Возможно из него станет понятно как писать UI в функциональном стиле — An Introduction to Elm.
Посмотрите в сторону функционального реактивного программирования.
Для UI есть Functional Reactive Programming (FRP).
Вот здесь, например, весь UI и весь WebGL код написан на Haskell (скомпилирован в JS через ghcjs).
UPD: прошу прощения, не заметил что продублировал ответ других пользователей.
Кстати, описывать событие как метод который зовёт бибилиотека и а прикладной разработчик переопределяет — исключительно плохая идея. Это крайне затрудняет обработку сценариев о которых авторы библиотеки не подумали и отличный способ запутать построение интерфейса с реакцией на события. Например QT видели эту проблему еще в середине 90х, и несмотря на некоторую ангажированность языка сделали более функциональную систему сигналов и слотов. Пользуясь случаем хочу передать горячий привет авторам андроида :)
Спасибо за еще одну статью о ФП на F#, последнее время они все чаще начали меня радовать(субьективно кажеться, что раньше реже такие материалы писали).
Интересно было бы посмотреть на тесты производительности функционального и ооп подхода на .net платформе.
Буквально сегодня добавил в проект расширение:
public static class Extensions
{
public static T With<T>(this T @object, Action<T> action)
{
action?.Invoke(@object);
return @object;
}
}Думаю, как же удобно менять свойства объекта или вызывать несколько методов подряд, некий аналог builder паттерна. Оказалось сделал как в F#.
А зачем вы делаете вызов через?..
— Модифицировать как?
— Никак
Не модифицирую.
github.com/nlkl/Optional
но не хватало еще только в каждый тип добавлять string ErrorMessage & bool IsSuccess.
Тем не менее, это вполне работающая практика. В golang так делают, в некоторых проектах в nodejs тоже принят такой стиль обработки ошибок. И этот подход можно использовать почти везде, даже в языках, где ООП нет вообще. Не самый удобный способ (напоминающий реализацию монады Maybe вручную), но работающий, простой, понятный и приводящий обработку ошибок к единообразному стилю.
Тем не менее, это вполне работающая практика. В golang так делают, в некоторых проектах в nodejs тоже принят такой стиль обработки ошибок. И этот подход можно использовать почти везде, даже в языках, где ООП нет вообще.
В Go не от хорошей жизни так. Как только в языке появляются человеческие типы-суммы об этом ужасе надо забывать. Зачем брать в пример неудачные реализации?
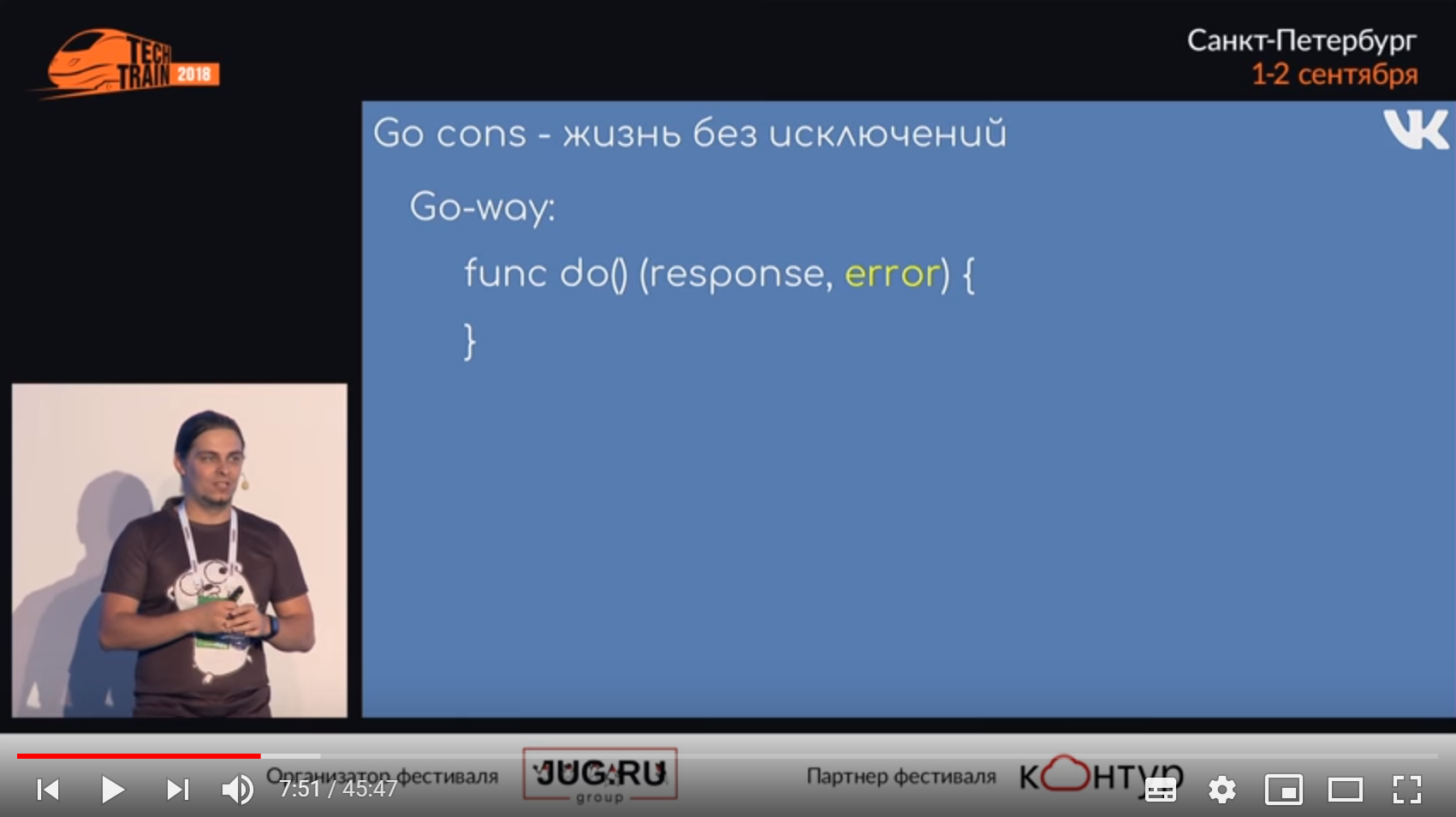
2. «Простой» — нет. Он путает два разных объекта и два пути исполнения. Еще полезное упражнение представить что ваша предметная область аудит логов, в которых есть удачные и неудачные записи и сообщения об ошибках :)
3. «Понятный» — нет. Он даёт возможность создавать объекты с неоднозначным состоянием в которых заполнены и поля данных и поля ошибок. Нужно разрабатывать соглашение что мы с ними делаем, как ищем источник, его надо доносить до всей команды, держать в голове.
4. «Приводящий обработку ошибок к единообразному стилю» — во снах CTO возможно. В коде — это гарантия бардака.
Immutability, Structural Equality, Structural Comparison…
Скоро завезут в C# records (с выходом восьмерки или десятки)
Документация
Обсуждение
Вот выходит на хабре очередная статья по некоторой технологии, которая в какой-то мере считается элитной в силу своей нераспространённости или сложности.
Приходит некоторое количество новичков, которые вроде как готовы в это ввязаться и задают вопросы о том, чем указанная технология может быть полезна им для решения их повседневных задач. И получают ответы, что технология вообще не для них, не для их задач, а для обучения плаванью сферических слонов в вакууме, притом всё это обильно посыпается минусами спрашивающих (видимо, с мыслью «ну тупыыыыые!»). Какие выводы он сделает? Логичные: да нафиг ему нужна непонятная технология с токсичным сообществом? А ведь он был почти готов присоединиться.
Доколе? Доколе сообщества адептов «элитарных» технологий, к коим функциональщики себя бесспорно относят, будет публикация статей для почёсывания эга и пинание раздумывающих новичков?
Однако несколько людей в том вопросе начала отвечать нейтрально с точки зрения дружелюбия. Не стоит судить сообщество по отдельным товарищам.
Впрочем, сам вопрос "как применять ФП" ужасно большой, сравним с "как применять ООП" или "как программировать". На него трудно дать ответ в комментарии. Это притягивает тех, кто ответ на собирается давать.
Нейтральные ответы — это конечно хорошо, но кроме нейтральных ответов — человеку прилетел и вполне себе конкретный "минус", который, скажем так,"энтузиазм несколько поубавил". А ну как прийдёт кто и ещё до кучи карму гробанёт? Сидишь и думаешь: нуево нафиг вопросы задавать. А нет вопросов — нет и аплогетов.
В C# это обычно выглядит так:
int a = 0; if(someCondition) { a = 1; } else { a = 2; }
Вообще-то в C# есть (1) тернарный оператор, (2) контроль ветвей, не инициализирующих данные. Если в первой строке не делать инициализации, то компилятор код без else не пропустит. Если, конечно, данные эти кому-нибудь нужны.
Вообще-то в C# есть (1) тернарный оператор
Ну такое. Это не компилируется:
var flag = true;
var _ = flag? Console.WriteLine("true") : Console.WriteLine("false");Такое почему-то тоже
var a = 0;
var b = flag ? { Console.WriteLine("true"); a = 1; }
: { Console.WriteLine("false"); a = 2; };Так что тернарный оператор в C# конечно уступает expression-based if из F#
Если сильно хочется, то
Console.WriteLine(flag ? "true" : "false")Во втором примере вообще желание чего-то странного, я даже толком мысли не понял.
Во втором примере вообще желание чего-то странного, я даже толком мысли не понял.
Это пример того что C# это всё же язык про стейтменты. Нельзя куда угодно засунуть какой хочешь экспрешн.
В if-стейтменте можно делать что хочешь (явные блоки { }), но это не выражение, оно ничего не возвращает (поэтому проверки типов у разных веток if нет и быть не может).
В ?-операторе ничего делать нельзя (явные блоки { } не поставишь), но оно обязано возвращать, а т.к. C# не умеет в unit/Void, то писать в ?-операторе unit/Void операции нельзя.
Все пропозалы — это требования того, чего нет в спецификации. Если этого не требовать, язык перестанет развиваться.
Все кто пишут пропозалы — странные?
Любой язык имеет свою семантику и странно требовать забить на всё и подстроить его семантику под хотелки приверженцев других семантических оборотов.
type Employee = { Id: Guid Name: string Email: string HasAccessToSomething: bool HasAccessToSomethingElse: bool }
Вот теперь действительно нет ничего лишнего.
Двоеточия и знак равенства лишние, можно ведь усугубить (скажем, в каком-нибудь F##)
type Employee {
Guid Id
string Name
string Email
bool HasAccessToSomething
bool HasAccessToSomethingElse
}Вот теперь действительно нет ничего лишнего, но думаю и дальше можно урезать.
Employee
G Id
s Name
s Email
b HasAccessToSomething
b HasAccessToSomethingElse
На правах шутки юмора :)
Добавим чутка скобочек и вот он LISP!
С сокращениями названий для типов F# может помочь :-)
type s = string
type b = boolВот есть у нас тип и значение:
type Employee =
{ Id: Guid
Name: string
Email: string
HasAccessToSomething: bool
HasAccessToSomethingElse: bool }
let employee =
{ Id = Guid.NewGuid()
Name = "Peter"
Email = "peter@gmail.com"
Phone = "8(800)555-35-35"
HasAccessToSomething = true
HasAccessToSomethinElse = false}
В каком месте здесь происходит сопоставление сущности с типом? Только вывод типа компилятором? Тогда почему этот код не может поломаться при неумелом рефакторинге?
Здесь компилятор F# идёт вверх по коду и ищет первый подходящий объявленный record (в нём обязаны совпадать все поля). И неявно выводит тип Employee у идентификатора employee.
Оно может поломаться если между объявлением
type Employee =
и созданием
let employee = ...
объявить другой рекорд с ровно теми же полями. Тогда компилятор неявно выведет этот самый другой тип у этой же переменной.
Это конечно поломает код (строгая типизация жеж) и вы сразу заметите ошибку в IDE, так что проблем нет. Если такой шадоуинг типов не ломает билд, то значит предыдщий рекорд ничего полезного не делал :)
type Celsius =
{ Value : float }
type Farenheit =
{ Value : float }
let v = {Value = 36.6 }
Что тут будет?
Что тут будет?
Здесь выведется последний объявленный тип. Неоднозначность можно явно разрешить при необходимости.
Для конкретно вашего случая (чтобы не путать единицы измерения) очень удобно использовать single case discriminated union:
type CustomerId = CustomerId of int // define a union type
type OrderId = OrderId of int // define another union type
(Пример взяла отсюда)
deleted
Про проблему останова пока ничего не могу сказать, не очень понял о чём речь.
Добавьте вложенные ссылочные поля, и теперь ваш { get; } ничего не гарантирует — вы можете изменить поля этого поля.Фшарп тоже не гарантирует иммутабельность вложенных объектов, как и любой другой CLR-совместимый язык:
type Test = { Values: int[] }
let x = { Values = [| 1; 2; 3 |] }
x.Values.[0] <- 5
при случайно выбранном инте статистически более вероятно попасть в «исключительную» ситуациюОткуда тут вообще взялся случайно выбранный int? Это наглое жонглирование статистикой в пользу вашего утверждения.
В C# это обычно выглядит так:И явно тип переменной указали, и скобки расставили, и про тернарный оператор условия тактично умолчали. Только обычно такое записывают как
int a = 0; if(someCondition) { a = 1; } else { a = 2; }
var a = someCondition ? 1 : 2.Ну и так далее в этом духе. Потенциальных пользователей такие толстые приемы скорее оттолкнут.
Видимо, я неточно выразился.
Во-первых, F# точно не является серебрянной пулей: система типов в хаскеле, например, мощнее, а в C# есть nameof, partial classes, которые делают его более удобным для генерации code behind. Я, например, не знаю как F# работает с WPF — не пробовал.
Во-вторых, я использовал упрощенные примеры, просто потому что так проще писать статью.
Да, в F# можно объявить обыкновенный мутабельный класс, и тогда компилятор не защитит это поле в рекорде или в DU. Мой поинт не в том, что F# покроет все магической защитой, а в том, что F# позволяет легко создавать и работать с неизменяемыми структурами, в отличие от C#. Да, массив все еще изменяемый, но из коробки в F# есть неизменяемые List, Set & Map.
По поводу случайного инта — я, конечно, ни в коем случае не ожидаю, что кто-то будет случайным образом пихать аргументы в индексатор, в конце концов, проверка длины массива — одно из первых правил, которое выучивает юный программист. Я лишь добавил это как демонстрацию того, насколько функция далека от тотальности. Тем не менее, несмотря на то, что мы научнены жизнью и делать так не будем, факт остается фактом: функция написана так, что бОльшая часть диапазона входных параметров вызовет исключение.
Что касается примера с if/else, я знаю про тернарный оператор, да. И про var, я без всякой задней мысли поставил там int, ошибся, сорян. Опять-таки, пример упрощен, и я там говорю про добавление веток в будущем. Можно сделать вложенные тернарные операторы, но я так делать не люблю из-за плохой читаемости.
Давайте сделаем пример более боевым:
let myResult =
if condition then
let a = myFunc arg1 arg2
let b = myFunc2 arg3
a + b
elif condition2 then
myFunc arg4 arg5
else
myFunc2 arg3 При большом желании можно это запихать в тернарные операторы, но обычно так не делают и теряют эту проверку ветвей.
В такиз случаях заводится неинициализированная переменная myResult. При чтении из нее компилятор проверит что значение ей было присвоено во всех ветвях исполнения.
Я, например, не знаю как F# работает с WPF — не пробовал.
Работает прекрасно
Знакомство с Gjallarhorn.Bindable.WPF (F#) на примере выполнения тестового задания
Давайте сделаем пример более боевым:
let myResult = if condition then let a = myFunc arg1 arg2 let b = myFunc2 arg3 a + b elif condition2 then myFunc arg4 arg5 else myFunc2 arg3
И он сразу становится кандидатом на рефакторинг даже в F#
Соответствующий код на F# выглядит так:
type Employee = { Id: Guid Name: string Email: string HasAccessToSomething: bool HasAccessToSomethingElse: bool }
А если захотите добавить проверку, к примеру что Email не null и не пустая строка?
Разные способы есть. Если email по бизнес логике обязателен, то, например, можно вернуть ошибку с помощью DU еще до создания этого экземпляра, но мне нравится вот такой подход:
module Email =
type EmailAddress =
private
| ValidEmail of string
| InvalidEmail of string
let ofString = function
| "validEmail" -> ValidEmail "validEmail"
| invalid -> InvalidEmail invalid
let (|ValidEmail|InvalidEmail|) = function
| ValidEmail email -> ValidEmail email
| InvalidEmail email -> InvalidEmail email
open Email
let invalid = Email.ofString "invalid"
let valid = Email.ofString "validEmail"
match invalid with
| InvalidEmail invalid -> printfn "invalid was InvalidEmail %s" invalid
| ValidEmail valid -> printfn "invalid was ValidEmail %s" valid
match valid with
| InvalidEmail invalid -> printfn "valid was InvalidEmail %s" invalid
| ValidEmail valid -> printfn "valid was ValidEmail %s" validТут мы убрали возможность создавать мыльник напрямую, но оставили возможность матчить валиден ли он или нет.
По поводу функциональщины, у меня был обратный опыт. Поигравшись со скалой где-от год (написав небольшой проект а не тупо туториалы), я лишь понял насколько я люблю С# и импиративщину. Иммутабельность, чистые функции, отсутствие состояния это все прекрасно, но оно и в С# доступно и обильно используется. Монады это тоже хорошо на первый взгляд, на простых примерах, но стоить копнуть глубже, написать что-нибудь сложнее и все, complexity побеждает здравый смысл. Вообще не покидало ощущение что у меня постоянно связаны руки тогда как импиративщиа и в частности С# дают полную свободу действий.
Полная свобода действий иллюзорна.
Можешь заставить программу делать все что хочешь, но не знаешь что ты он нее хочешь?
Потому что если знаешь — декларируй с помощью декларативного программирования. Главный плюс — ты автоматически доказываешь правильность ее работы.
Но есть и минус: иногда модель может быть слишком перегруженной для реальной программы. Тогда ты сделал очень много, но это никому не надо.
Короче говоря — надо балансировать.
Касательно же .net — как по мне, f# более выразителен. А "ООП"из него дергать просто.
Зачем жить с половиной слабореализованных фич, если можно получить полный набор?
Кроме того, про DU в сишарпе вообще пока ничего не слышал. Expression-based он тоже вряд ли станет когда-нибудь, верно? Обе эти фичи сильно способствуют стабильности и самодокументируемости кода.
Для скорости лучше писать просто на Си
В большинстве случаев спасает переиспользование объектов, т.к. все композитные структуры включают друг-друга по указателю, а не по значению. Сборщики мусора могут быть реализованы совсем по-другому, когда известно что вся память иммутабельна.
Есть ещё всякие оптимизации типа линейные типов для минимизации расхода памяти (обсуждение для Haskell).
$employee = [pscustomobject]@{
Id = [guid]::NewGuid()
Name = "Peter"
Email = "peter@gmail.com"
Phone = "8(800)555-35-35"
HasAccessToSomething = $true
HasAccessToSomethinElse = $false
}> $employee.Name.GetType().ToString()
System.String
> $employee.Id.GetType().ToString()
System.Guid
> $employee.HasAccessToSomething.GetType().ToString()
System.Boolean
Тулинг, обилие библиотек и размер сообщества я сейчас в расчет не беру
Не берёте потому, что иначе пришлось бы рассказать про печальный для F# расклад с сообществом, тулингом и библиотеками, что свело бы нет восторженные интонации статьи. А именно:
— библиотек F# для типичных задач бизнеса практически нет, а те что есть маргинальные one man поделки, которые стрёмно использовать. Вот такой вот суперский язык F#, на котором почему то ни кто не хочет или не может написать ничего полезного. Но язык суперский. (поэтому юзаются С#-повские библиотеки, сводящие на нет все плюшки, описанные автором. Поскольку ни о каком ФП стиле и DSL в них естественно речи не идёт). Я уже молчу о таких прелестях, как депрекейтнутые версии либ для более старых версий net — у меня ни один проект F# под net 4 не собирается без ручной правки зависимостей
— туллинг так же отвратительный. Все .net-овские либы и фреймворки (asp, wpf, wcf, win, uwp, .NET Native) написаны для C# и VB, F# можно разве что с боку прикрутить. Для сборки проектов и управления зависимостями рекомендованы маргинальные утилиты, которые ни каким нормальным ide естественно не поддерживаются.
Внимание вопрос — а кому в 18-м году нужен язык сам по себе, без тулинга, библиотек и большого дружелюбного сообщества? Очевидно мазохистам и бездельникам, не решающим ни каких практических задач.
Далее, говоря о преимуществах ФП, автор забыл отметить недостатки:
— проблемы эффективности функциональных и неизменяемых структур данных
— неоправданный рост когнитивной нагрузки на чтение и понимание кода.
— функциональный код невозможно нормально отлаживать
А в чём у вас проблемы возникают?
А в том, что программа на F# — это последовательность инструкций, как и программа на С#. В C# любая инструкция доступна из отладчика, на ней можно ставить точку останова и заводить выполнение внутрь её тела. В F# благодаря таким прекрасным вещам как вычислительные выражения, цитирование, каррирование, кастомные операторы и проч. способы написать офигеть какой короткий и декларативный код — отладчик бессилен (на самом деле это не проблема, потому что F# практически ни где в реальной жизни не используется, соответственно и отладчик не нужен). Плюс в C# есть такая полезная опция, как реверсинг на лету и go-to-definition в библиотечный код, который так же можно дебажить. Программист на F# нервно курит в сторонке или рассказывает что дебагер нинужен
отладчик бессилен
Эту чушь от тебя я уже опровергал в какой-то из прошлых статей про F#, где ты рассказывал то же самое.
Даже ссылку оставлю, освежить тебе память.
F# практически ни где в реальной жизни не используется, соответственно и отладчик не нужен
А ещё можно зажмуриться и повторять себе — F# не существует. Поможет.
Плюс в C# есть такая полезная опция, как реверсинг на лету и go-to-definition в библиотечный код, который так же можно дебажить. Программист на F# нервно курит в сторонке или рассказывает что дебагер нинужен
Декомпиляторов из IL в F# нет, это правда. Или я таких не знаю.
Нервно не курю, дебагером пользуюсь.
Речь о том, что промежуточное значение контейнера в цепочках вычислений с оператором |> в отладчике увидеть нельзя, в том числе и вашем примере — значение, которое получает Seq.iter скрыто от всех — и программиста, и отладчика.
Вот ещё пример точки останова, которая никогда не сработает
query{
for c in ctx.Main.ProductType do
if c.GasName = "O₂" || c.GasName = "NO₂" then
yield c.ProductTypeName.Value // здесь брекпойнт ставится но не работает
} |> Seq.iter (printfn "%s") А ещё можно зажмуриться и повторять себе — F# не существует. Поможет.
К вашим способам рефлексировать ни каких вопросов нет, жмурьтесь и повторяйте дальше. А мне достаточно сюда заглянуть чтобы сделать вывод что F# ни кому не нужен — из всех языков гитхаба только Elixir, fortran, haxe, racket и logos более мёртвые чем F#. Или коллег поспрашивать как они к F#-у относятся, может быть кто-то пишет на нём что-то полезное (нет, ни кто не пишет)
Когда мне говорят, например, что после перехода на F#
- кол-во кода сократилось на 60%
- производительность в таких-то сервисах упала на 4-7%
- кол-во аллокаций выросло на 15%
время реализации новых фич упало с 1 месяца до 1-2 недель, да плюс кол-во багов уменьшилось
я вижу четкую картину, конкретные цифры и понимаю, чего стоит ожидать от перехода на этот язык. Я вижу объективные утверждения.
Когда я читаю комментарии, подобные вашим, я вижу сплошную субъективщину и эмоции.
- Библиотек у F# нет? Giraffe, Hopac, Rezoom.SQL, FsharpLu.Json Json/Xml/Csv type providers и так далее. С чего это они маргинальные? Если проект поддерживает 1-2 человека, это не значит, что он плох. Может быть, просто язык настолько хорош, что вам не нужна армия мейнтейнеров? А может быть, библиотека не так уж сложна? Или автор дьявольски умен?
- Тулинг отвратительный? Это ложь. Тулинг хуже, чем у C#, но не настолько, чтобы скулить об этом под каждой статьей и уж тем более не настолько, чтобы заниматься промышленной разработкой было нерентабельно.
- Все либы написаны под сишарп? Это ложь, ссылки выше.
- F# в эти либы можно только сбоку воткнуть? С чего бы? F# умеет ООП не хуже C#, да и ООП вообще тут не при чем, используй себе и ОРМ, и автомаппер, и ASP.NET, если не хочешь жираф, суаве или сатурн. Код бизнес-логики это вообще не затрагивает.
Сборка проектов маргинальными утилитами? Это вообще блин о чем? Проекты собираются и классическими средствами ровно так же, как и C#. К слову, на нашем C# проекте используется FAKE. - Функциональные структуры данных не такие эффективные? Да у нас тут преждевременный оптимизатор в треде. В C# коде чаще всего фигурируют
IEnumerable<>&List<T>. Самая частая операция с ними —foreach. Давайте, расскажите мне, как форыч по листу в миллион раз эффективней форыча по связному списку.
Далее, поиск по функциональной мапе медленнее, чем по хеш таблице, да. Только кто заметит эту разницу на словаре, в котором 10-20 элементов?
А вот там, где действительно нужна высокая скорость работы, можно использовать императивные коллекции, никто не мешает это делать. Получается, в F# у вас есть выбор между функциональными и императивными коллекциями, а в C# нет. Ну, если не считатьCollections.Immutable, который все ругают. - Неоправданный рост когнитивной нагрузки при чтении ФП кода? Это чистая субъективщина, не подкрепленная вообще ничем. Когнитивная нагрузка при чтении ваших бездоказательных утверждений для меня выше, чем при чтении качественного ФП кода.
- ФП код невозможно дебажить? Хорошо, что я не знал этого, когда дебажил ФП код. Слава богу, приходится его дебажить гораздо реже, чем ООП, иначе невозможное пришлось бы творить слишком часто.
кол-во кода сократилось на 60%
я вижу четкую картину, конкретные цифры и понимаю, чего стоит ожидать от перехода на этот язык. Я вижу объективные утверждения.
У вас очень странный взгляд на вещи. Я в таких случаях вижу человека, который звездит.
F#, конечно, не хаскель, а C# — не C++, но опыт с сокращением количества кода почти на порядок между хаскелем и плюсами у меня есть.
Ну такое сравнение это примерно как не миллион, а тысячу, не в лотерею — а в карты, и не выиграл — а проиграл.
Ну и да, код мерили как? Размер зип-архива?
Странно что у вас такие сомнения по этому заявлению.
Переход на более высокий уровень абстракции убирает часть кода (потому что мы, очевидно, от него абстрагируемся).
Переход с Assembly на C++
Переход с C++ на Хаскель
Переход с C# на F# не такой резкий чтобы прям на порядок уменьшить, но раза в 2 вполне. Я говорю за себя точно (был опыт переписывания с С# на F# одного крупного проектов и несколько мелких), так же есть опыт других людей.
Этот опыт переписывания не такой обширный потому что в последствии понимаешь что проще сразу на F# писать чем потом переписывать.
Переход на более высокий уровень абстракции убирает часть кода (потому что мы, очевидно, от него абстрагируемся).
В случае С# -> F# нет никакого перехода. F# имеет некоторое количество синтаксического сахара, и на это все.
Конечно, если у вас весь код — это объявление кучи discriminated unions, то тут получится выгадать ~30%, а логика примерно одинаково выглядит в обоих языках, т.к. примитивы одинаковые.
F# имеет некоторое количество синтаксического сахара, и на это все.
Так можно про любой язык сказать: Haskell это просто набор синтаксического сахара над Асмом (или Лиспом). Это ж всё Тьюринг полные языки и при должном старании и времени все абстракции одного могут быть выражены в другом.
Называйте как хотите, код на F# в разы меньше кода на C#. Благодаря ли синтаксическому сахару, ML синтаксису или каким-то абстракциям (экспрешны, алгебраические типы, карирование и всё такое прочее).
Так можно про любой язык сказать:
Нельзя.
Называйте как хотите, код на F# в разы меньше кода на C#.
Ну не в разы. процентов 10-30%, думаю, можно на практике срезать. Чем больше проект — тем меньше эффект, конечно же.
Ну не в разы. процентов 10-30%, думаю, можно на практике срезать. Чем больше проект — тем меньше эффект, конечно же.
Если просто 1 в 1 переписать на F# (прям в C# стиле, со всеми этими интерфейсами, наследованием и пр) уже будет больше 30%
Скрины слайдов:
https://imgur.com/a/Ghxapve
Где C# перенял из F# (LINQ, async/await, expression-bodied methods/properties etc), уже выглядит более-менее одинаково.
А если начать использовать F# на полную (да хотя бы DU объявить на 3 строчки вместо портянки из наследуемых классов) там сокращение кода уже на порядок.
Если просто 1 в 1 переписать на F# (прям в C# стиле, со всеми этими интерфейсами, наследованием и пр) уже будет больше 30%
Как показывает практика, обычно в таких сравнениях берется няшный идиоматический код на F# и сравнивается с диким ужасом на C#. А если код на C# переписать из дикого ужаса в адекватном виде — то ВНЕЗАПНО разница падает на порядок.
Или, еще один вариант (это уже как на вашем слайде) идет экономия за счет каких-нибудь незначимых токенов вроде кавычек. На которые всем плевать.
Как показывает практика, обычно в таких сравнениях берется няшный идиоматический код на F# и сравнивается с диким ужасом на C#. А если код на C# переписать из дикого ужаса в адекватном виде — то ВНЕЗАПНО разница падает на порядок.
Я ж слайды привел. Что там ужасного в С#? Обычный такой C# справа. И обычный такой F# слева (на самом деле не очень обычный, это просто калька кода из C#). Даже expression-bodied юзаются где можно
Я ж слайды привел.
На ваших слайдах 90% "экономии" — это фигурные скобки. То есть вообще не экономия. С-но если даже по строкам считать — там и получается ~30%, но если считать нормально, по зипу, то число резко упадет. Это, еще раз, если таковую экономию в принципе имеет смысл счиать (не имеет, конечно же).
На ваших слайдах 90% "экономии" — это фигурные скобки. То есть вообще не экономия. С-но если даже по строкам считать — там и получается ~30%, но если считать нормально, по зипу, то число резко упадет. Это, еще раз, если таковую экономию в принципе имеет смысл счиать (не имеет, конечно же).
Окей, перепишите мне 1 в 1 на С# пожалуйста эти 117 (включая пустые) строчек:
https://gist.github.com/Szer/fe0579aa7f5d780c3eecec3000c64447
IUserService реализовывать не надо.
Естественно с сохранением типизации реквестов/респонсов чтобы я потом мог наворачивать поверх типов сложную доменную логику по обработке ошибок или разных типов респонсов.
С-но вот:
https://pastebin.com/fcAXL6mD
предварительные замечания:
конкретную реализацию task я не знаю, типов тоже там нет, так что кое-где я догадывался по семантике, но на размер сколько-нибудь существенно исправления на реально работающий вариант не повлияют. Match и With считаем библиотечными ф-ми, пишутся один раз, по-этому не вижу причин их учитывать (иначе тогда логично учитывать библиотечные ф-и и в f#), рабочую реализацию этих ф-й я могу предоставить, если требуется. Сразу можно отметить по linq — опять-таки, монады task и maybe считаем реализованными в библиотеках (что верно и для кода на f#). exhaustive check в реализации на c# ясное дело, отсутствует, это следует сразу оговорить, но на практике это, с-но, не особенно нужная фича. Дв, еще там при вставке кое-где отступы маленько побились, но в общем несущественно это.
В итоге имеем:
по loc 134 строки c# против 93 на f# (я удалил ненужные куски из кода на f# для более корректного сравнения, по-этому меньше), что, с-но, и есть 30%, о которых я изначально говорил.
при этом 24 строки приходится на "лишние фигурные скобки", если их не учитывать разница будет 110 вс 93, то есть ~15%, и, как видно, сосредоточена она в основном в определении классов, логика по loc переписывается почти 1к1.
Соотношение размеров по рарникам: 1017 байт вс 1224, что составляет ~17% (и согласуется с измерением в ~15% без кавычек).
Выводы:
реально ожидаемый выигрыш f# по лок составит 10-30% от изначального кода. Основная часть этого выигрыша (примерно половина) придется на фигурные скобки, вторая половина — объявления классов. Минимум — на логику. Чем больше в проекте соотношение логика/объявления классов — тем меньше выигрыш.
ЗЫ: кстати в исходном коде в processRequest можно было бы заменить все на map, то есть:
CreateUser user -> userService.createUser(user).Select(UserCreated)вместо
CreateUser user -> task {
do! userService.createUser user
return UserCreated }если монадка там норм написана, конечно
match & with это не библиотечные функции, это языковая конструкция, так же как и if/else или switch case в сишарпе. И работает этот матч не только с заданными типами, а вообще с чем угодно. Так что справедливо было либо переписать на if else / switch case либо указать реализацию ваших функций Match & With. Кстати, в них будет пусть и небольшой, но оверхед, но это мелочи.
Exhaustive check не особо нужная фича? С чего бы? Это ворнинг нахаляву (а при warning as errors ошибка компиляции) вместо юнит теста. Нихера себе ненужная фича.
Да, а еще у вас нет null safety.
Кстати, будет ли работать ваш from-select, ведь эти методы возвращают не IEnumerable?
В итоге даже в таком примитивном примере, где нет ни многопоточности, ни сложной смены состояний, ничего вообще интересного, мы получили больше строк кода (кстати, не забудьте либо переписать на if else / switch либо добавить реализацию функции Match+With), а решение менее надежное. Что и требовалось доказать.
match & with это не библиотечные функции, это языковая конструкция
Нет разницы. Смысл в том что это не относится к клиентскому коду.
Exhaustive check не особо нужная фича? С чего бы? Это ворнинг нахаляву (а при warning as errors ошибка компиляции) вместо юнит теста. Нихера себе ненужная фича.
При желании можно добавить, поправив реализацию Match/With и добавив кодировку кейзов, например, параметрами генерика. В клиентский код добавится по паре строк на тип примерно, но это все по факту неинтересно.
Да, а еще у вас нет null safety.
Это уже тоже к делу не относится, речь же о переписывании конкретного кода.
Кстати, будет ли работать ваш from-select, ведь эти методы возвращают не IEnumerable?
linq работает с любыми монадами, которые вам захочется, не обязательно IEnumerable. Я не знаю насколько актуальная реализация task в f# подходит, но у нее гарантированно есть эквивалентная монадическая, с которой linq будет работать.
В итоге мы получили больше строк кода (кстати, не забудьте либо переписать на if else / switch либо добавить реализацию функции Match+With), а решение менее надежное. Что и требовалось доказать.
Мы получили эквивалентное решение с ~30% оверхедом в кейзе специально построенном так, чтобы этот оверхед был близок к максимальному. То есть ровно то, что и утверждалось изначально:
Конечно, если у вас весь код — это объявление кучи discriminated unions, то тут получится выгадать ~30%, а логика примерно одинаково выглядит в обоих языках, т.к. примитивы одинаковые.
И точная оценка в 30% — это не чудесное совпадение, просто я уже не первый раз участвую в спецолимпиадах, посвященных f#, и прекрасно знаю, какой код во что переписывается и с каким оверхедом.
По-этому, если кто-то говорит про экономию в разы — это 100% ложь. Уменьшить код на треть — это то, что у вас выйдет сделать в лучшем случае на определенных кусках, которые наиболее оптимально ложатся под сахар f#. В реальном, большом проекте — даже никаких 30% не будет и близко.
Почему так происходит? Да из-за того, на что я указывал выше — f# просто не предоставляет какие-либо средства, которые могли бы серьезно помочь в сокращении кода. Ну нету там таких средств. discriminated unions можно проще объявлять, деконструкцию в паттернах быстрее делать и экономить за счет сложных дслей в computational expressions — список закончился.
Скоро в c# добавят сахарок для рекордов и нормальный паттерн-матчинг (и nullable типы нормальные) и, с-но, все, до свидания, основные преимущества f# будут покрыты.
Нет разницы. Смысл в том что это не относится к клиентскому коду.
Есть разница, и я сразу написал, в чем она. Раз уж меряем код — давайте мерять честно.
При желании можно добавить, поправив реализацию Match/With и добавив кодировку кейзов, например, параметрами генерика. В клиентский код добавится по паре строк на тип примерно, но это все по факту неинтересно.
Довайте добавим, если мы хотим полный эквивалент.
И точная оценка в 30% — это не чудесное совпадение
Это не точная оценка, много чего опущено.
Это уже тоже к делу не относится, речь же о переписывании конкретного кода.
Еще как относится. Когда в проде вылетает нуллреф, ни пользователей, ни бизнес не волнует, в клиентском коде это случилось, или в недрах либы.
Конечно, если у вас весь код — это объявление кучи discriminated unions, то тут получится выгадать ~30%
Там объявлено 2 юниона. Это 11 строк из 117, которые там есть. Если вы думаете, что приведенный пример это специально надроченный семпл, чтобы показать максимум лаконичности, вы глубоко заблуждаетесь.
И мой поинт все еще остается в силе — в F# меньше кода (даже по вашим приуменшенным оценкам), и код надежней.
Скоро в c# добавят сахарок для рекордов и нормальный паттерн-матчинг (и nullable типы нормальные) и, с-но, все, до свидания, основные преимущества f# будут покрыты.
Nullable типы будут не нормальные. На уровне рефлекшна никакой разницы не будет между string * string?, так что это уже хуже, чем Option<'T>.
Record types — посмотрим, добавят ли подобие with синтаксиса.
f# просто не предоставляет какие-либо средства, которые могли бы серьезно помочь в сокращении кода. Ну нету там таких средств. discriminated unions можно проще объявлять, деконструкцию в паттернах быстрее делать и экономить за счет сложных дслей в computational expressions — список закончился.
Вы даже тут уже сами себе противоречите. Хотите преуменьшить возможности F# изо всех сил, но даже у вас набрался список из 3 серьезных пунктов, хотя говорите, что средств нету. Клоунада.
Есть разница, и я сразу написал, в чем она. Раз уж меряем код — давайте мерять честно.
Я и померbл честно — клиентский код с клиентским кодом. Если хотите учитывать код библиотек — можете считать с кодом библиотек, я не вижу в этом смысла, особенно учитывая тот факт, что бОльшая часть библиотек f# написана на c#.
Довайте добавим, если мы хотим полный эквивалент.
Он и так полный.
Еще как относится. Когда в проде вылетает нуллреф, ни пользователей, ни бизнес не волнует, в клиентском коде это случилось, или в недрах либы.
Это не относится к обсуждаемому вопросу с размером кода.
Там объявлено 2 юниона. Это 11 строк из 117, которые там есть. Если вы думаете, что приведенный пример это специально надроченный семпл
Именно так и есть.
И мой поинт все еще остается в силе — в F# меньше кода (даже по вашим приуменшенным оценкам), и код надежней.
Конечно меньше. На 30%, половина из которых фигурные скобки.
С этим же никто и не спорил, напоминаю свое утверждение:
Конечно, если у вас весь код — это объявление кучи discriminated unions, то тут получится выгадать ~30%, а логика примерно одинаково выглядит в обоих языках, т.к. примитивы одинаковые.
Я это утвержедние доказал. С-но, что дальше обсуждать тут можно?
С-но вот:
https://pastebin.com/fcAXL6mD
Спасибо большое! Нет, без дураков, спасибо. Я не ожидал что Вы попытаетесь :)
Удивлён что был заюзан тот же Giraffe.
Пара комментариев:
- Сам класс User конечно надо дополнить на Value Equality, что сразу добавит десяток строчек
- Базовый абстракный Request не совсем корректен, т.к. он не запрещает добавление новых Request к этому множеству и компилятор вам не скажет что вы обработали не все виды запросов. Для этого типы-суммы и нужны (закрытые множества).
- task — это монадка в F# для работы с тасками. Её прямой аналог async/await методы. F# просто позволяет монадический стиль и объявление где угодно, а не только в заголовке всего метода/функции.
- .Match/.With вполне допускаю, видел такую реализацию в глубинах Akka.Net, но опять таки это только матчинг по ТИПАМ, без рекурсивного деконстракта, патернам листов, массивов, литералов и просто патернам. Аналог был бы switch/case (хотя в нём маловато всего, а рекурсивный патерн матчинг подъедет только в C#8)
- фишку с применением Linq (from x in ...) я много раз видел, считаю синтаксис вырвиглазным, костыльным, сбивающим с толку, да и эти методы не реализуют итератор. В общем, мимо.
- последний вопрос — это компилируется на C#?)
Added:
Хорошая попытка, но получили менее качественный код с чуть большим кол-вом строчек.
Чтобы получить похожее качество кода необходимо немного рефакторинга:
- Обмазать всё хотя бы JetBrains аннотациями NotNull и иже с ними
- Сделать Request sealed классом, чтобы нельзя было докинуть внешним пользователям кейсов, внутри него реализовать набор из вариантов. Это будет похоже на закрытое множество хотя бы. Каждый кейс кстати должен реализовывать ValueEquality.
- Заменить Match With на switch case, всё равно switch case УЖЕ поддерживает тайп паттерны
- Убрать неясно как работающий from x in CallAsync() select x. Не, серьёзно, за такой код надо сразу леща давать. Я ничерта не понял.
- Добавить ValueEquality в User класс
Тогда будет уже ближе к передиранию 1 в 1, хоть и с мелкими недостатками.
Если Вы ещё не поняли, то передирание 1 в 1 без потери фич, но с повышением качества и уменьшением кол-ва кода ИЗ C# В F# возможно.
Обратное преобразование даже с потерей половины функционала (null check, value equality, exhaustive matching) увеличивает кодобазу.
Написать так же хорошо как на F#, у вас займёт в разы больше места. Если вообще получится.
P.S. И говорить что фича Х не нужна, поэтому я её реализовывать не буду — забудьте. Вас попросили сделать 1 в 1. Будьте любезны.
Сам класс User конечно надо дополнить на Value Equality, что сразу добавит десяток строчек
Зачем? Value equality на практике не используется, с-но и добавлять не надо.
task — это монадка в F# для работы с тасками. Её прямой аналог async/await методы.
async/await работает только для async/await (в последнем шарпе добавили возможность добавлять свои варианты обработки, но это не совсем тривиально), так что я воспользовался аналогом — linq является универсальной монадической нотацией, точно так же как универсальной нотацией являются computational expressions. То есть это более "близкий" перевод. Но, да, при желании можно было бы записать через async/await.
Аналог был бы switch/case
Он тоже структурно не матчит.
считаю синтаксис вырвиглазным, костыльным, сбивающим с толку, да и эти методы не реализуют итератор. В общем, мимо.
Синтаксис изоморфен синтаксису в f#, то есть нет возможности объективно считать один вырвиглазным и не считать вырвиглазным другой. Они де-факто одинаковые :)
Итераторы с linq никак не связаны, linq — монадическая нотация. Для любой монады. Та же maybe например.
последний вопрос — это компилируется на C#?)
Ну в таком виде нет, т.к. там ошибки связанные с тем, что я не знаю все типы и не знаю точно семантику некоторых моментов в f# коде + есть ряд ф-й, которые конкретно из f# (тот же choose или Bind для maybe). Если эти ф-и дописать и пофиксить пробелмы с типами, то скомпилируется и заработает :)
P.S. И говорить что фича Х не нужна, поэтому я её реализовывать не буду — забудьте. Вас попросили сделать 1 в 1.
Ну это совсем бессмысленная игра. На каждом языке есть некоторые особенности, которые трудновыполнимы (или вообще невыполнимы) в рамках другого языка, в результате чего переписать код ВОТ ЧТОБ ПРЯМ 1в1 ИДЕАЛЬНО просто невозможно. И это никак не связано с выразительностью.
Я могу написать на c# класс с protected, и вы аналог на f# сделать не сможете, это будет корректно? Нет. Вот и ваши требования с nullsafety и exhaustive некорректны.
Штука в том, что мы обсуждаем размер кода, так вот ull safety или exhaustive check не делают код меньше. Они делают его более надежным — но не делают меньше. С другой стороны — вот структурный матчинг делает код меньше.
По-этому, например, требование "вот здесь я в f# херакс-херакс паттерн сделал, а ты теперь на своем c# ручками говнякай" — корректно вполне.
Рассуждения о том, что Value Equality не нужно на практике (почитайте что ли про DDD и Value Objects vs Entities) — это детский сад. Оно не нужно такой ценой, оторой достается на C#, но нахаляву этому будут рады все.
Рассуждения о том, что null safety и надежность отношения к задаче не имеют — это тоже детский сад. В реальных проектах код умения пройти позитивный сценарий недостаточно, это уровень студенческой лабы.
Если вы считаете, что тот семпл специально надроченный, нуштош, попробуйте транслировать вот эти два файла.
Сразу скажу, что цели насрать сишарпистам я себе не ставил, просто писал так, чтобы было удобно.
Рассуждения о том, что Value Equality не нужно на практике (почитайте что ли про DDD и Value Objects vs Entities) — это детский сад.
Это не детский сад — это факт. Value Equality встречается эдак раз на сотню тысяч строк кода. То етьс на практике этой фичей практически никогда не пользуются. Есть огромные проекты в которых она не юзается ни разу.
Рассуждения о том, что null safety и надежность отношения к задаче не имеют — это тоже детский сад.
Это не детский сад, это доказанный факт. Вы можете, конечно, глаза закрыть и притвориться, что вы в домике, но реальность это не отменит.
Мы обсуждаем размер кода, а указанные вещи не влияют на размер кода.
Ну и да, покажите мне тогда код на f# с protected. Сколько там строк будет?
Если вы считаете, что тот семпл специально надроченный, нуштош, попробуйте транслировать вот эти два файла.
Я же уже показывал, как такой код транслируется почти без потерь по размеру. Поскольку объявлений типов там нет, а есть только логика, то перевод будет с оверхедом ~15% (можете сами перевести и проверить), из них больше половины — скобки, то есть указанный вами код на c# по факту записывается с эффективным оверхедом около ~5%, примерно 128 строк вместо 121 (если брать второй файл, например). Как видно, ни о каком "f# позволяет писать на порядок меньше кода" говорить нельзя, экономия в 7 строчек из 128 — это детский сад.
Это не детский сад, это доказанный факт. Вы можете, конечно, глаза закрыть и притвориться, что вы в домике, но реальность это не отменит.
Не хочу показаться грубым, но вы че несете-то? Кто и что доказал? Надежность — это такая же важная характеристика, как и функционал. Не знаю, как вы, но я предпочту, например, мессенджер, который работает как часы, но без видеозвонков, превьюшек ссылок и тд, вместо чего-нить напичканного перделками, но постоянно падающего, лагающего и жрущего ресурсы как не в себя (привет слак).
Я же уже показывал, как такой код транслируется почти без потерь по размеру. Поскольку объявлений типов там нет, а есть только логика, то перевод будет с оверхедом ~15% (можете сами перевести и проверить), из них больше половины — скобки, то есть указанный вами код на c# по факту записывается с эффективным оверхедом около ~5%, примерно 128 строк вместо 121 (если брать второй файл, например). Как видно, ни о каком "f# позволяет писать на порядок меньше кода" говорить нельзя, экономия в 7 строчек из 128 — это детский сад.
Вы первый файл смотрели? Там ТОЛЬКО объявления типов. Кстати, у вас с каждым следующим комментом заявленный оверхед магически уменьшается. Сначала было 30% с учетом скобок и 15% без, потом 15% с учетом скобок и 5% без.
Да, киньте в меня плз ссылкой, где вы показывали это, сорян, если я в танке сижу и пропустил.
Мне не нравится заставлять/предлагать вам переписать на C# то, что у меня есть на F#, но я не вижу другого выхода, раз вы кидаетесь громкими утверждениями и с потолка берете 121 строку и 5%.
Если таки возьметесь за переписывание этих двух файлов — давайте облегчим задачу: необязательно транслировать 1 в 1. Просто реализуйте ту же логику: классическая змейка + перки на атаку и скорость с кулдауном. Потом сравним надежность, лаконичность и читаемость.
Надежность — это такая же важная характеристика, как и функционал.
Мы не обсуждали надежность, мы обсуждали размер кода.
Если вы хотите обсудить надежность — это можно, конечно, сделать, но это будет уже отдельное обсуждение, которое никакого отношения к текущему не имеет и на выводы повлиять не может.
Надежность — это такая же важная характеристика, как и функционал.
Юнионы идут первые 30 строк, остальное — классы с методами, то есть логика, которая переводится практически без оверхеда, как уже было показано.
Кстати, у вас с каждым следующим комментом заявленный оверхед магически уменьшается.
Ничего не уменьшается, просто вы невнимательны. 30% — оверхед с значимым количеством юнионов, из которого примерно половина — скобки и примерно половина — юнионы. Убираете один из факторов (как в случае второго файла, где юнионов нет) и получаете примерно 15%, то есть половину.
Мне не нравится заставлять/предлагать вам переписать на C# то, что у меня есть на F#, но я не вижу другого выхода
Я вам указал универсальный метод переписывания и привел оценки оверхеда для этого метода. Вы свободно можете воспользоваться этим методом для любого кода и сами проверить, что получится. Я на 100% уверен, что для вашего кода мои оценки не будут отличаться сколько-нибудь существенно т.к. это просто такой же код. Почему на аналогичном коде должно что-то измениться? Другое дело, если бы в вашем коде использовались какие-то другие примитивы, которые бы потребовали дополнительной работы по переводу (и, возможно, дали бы большой оверхед), но в ваших файлах их использовано не было.
Если же вы сомневаетесь — вы можете провести всю работу и расчет сами, вся требуемая информация для выполнения этой задачи у вас есть, так что я не вижу какой-либо проблемы.
Это не детский сад — это факт. Value Equality встречается эдак раз на сотню тысяч строк кода. То етьс на практике этой фичей практически никогда не пользуются. Есть огромные проекты в которых она не юзается ни разу.
У вас странный код. У меня Reference Equality встречается раз на сотню тысяч строк кода (в очень коварном месте где по-другому никак). И для него вполне хватает Object.ReferenceEquals, а всё остальное время сравнивать структурно.
Это не детский сад, это доказанный факт. Вы можете, конечно, глаза закрыть и притвориться, что вы в домике, но реальность это не отменит.
Плохо что вы скатились в такую ахинею — утверждать что null safety не увеличивает качество кода. Все языки к этому идут (C#8 тоже), один Druu останется и будет корячиться с NullReferenceException
Ну и да, покажите мне тогда код на f# с protected. Сколько там строк будет?
Больше, да. Protected не реализован специально (чтобы не упрощать наследование реализации, а предпочитать композицию), если передирать 1 в 1, то придётся погемороиться с public / private.
Я вам сразу скажу чтобы вы не мучались в поисках контр-примеров — goto в F# тоже нет.
Я же уже показывал, как такой код транслируется почти без потерь по размеру.
Нет, не показывали. Вы показали некомпилирующийся код, который потерял по дороге кучу фич. И всё равно он был больше по размеру.
, а всё остальное время сравнивать структурно.
Зачем вообще где-то что-то может понадобиться сравнивать структурно?
Плохо что вы скатились в такую ахинею — утверждать что null safety не увеличивает качество кода.
А зачем вы перевираете мои слова? Мы обсуждали размер кода, я вообще ничего не говорил про качество. Если хотите обсудить качество — можно обсудить качество, но это будет отдельный независимый от текущего разговор.
Больше, да.
Ну и какой в этом смысл? Это было бы некорректным требованием, еще раз. Это то, что не влияет ни на логику самого рассматриваемого кода ни на логику кода клиентского (если бы речь шла о какой-либо библиотеке).
Нет, не показывали.
Показал, там сверху ссылка.
И всё равно он был больше по размеру.
Конечно, никто и не говорил что он не будет больше. Я сразу указал конкретные оценки, на сколько код f# получается меньше экевивалентого кода на c#.
Если ваш код на F# — трансляция из C# один в один, то да, краткости не выйдет. Но при правильном применении абстракций кол-во кода сокращается. Временами, за счет оверхеда — и аллокаций больше, и перфоманс может просесть. В общем, все признаки перехода на более высокий уровень абстракции.
А то, что F# ничего кроме сахара не имеет — ну, называйте это как угодно. Сахар, кодогенерация — не важно. Кучу бойлерплейта убирает, и головной боли меньше. Скорость разработки растет, стабильность кода тоже. Что еще нужно?
Если ваш код на F# — трансляция из C# один в один, то да, краткости не выйдет. Но при правильном применении абстракций кол-во кода сокращается.
Так в F# нету никаких новых абстракций, по сути. То есть тут надо про обратное говорить — если дан код на F#, то вы можете его переписать на C# с минимальным разрастанием по объему.
С чего это они маргинальные?
Погуглите что значит «маргинальные», может хватит ума понять что они соответствуют этому понятию. За исключением Girafe, которая не даёт сверх asp net кроме костылей и оверхеда. Фактически то же самое, что C# asp net + F#.
По поводу Hopac. Если бы она действительно работала как заявлено — её бы использовали абсолютно все, кто делает хайлоад на net. Даже несмотря на кастмные операторы в стиле «доктор таблеток забыл привести». Вы лично написали на Hopac хоть одну строчку боевого кода чтобы другим её советовать? Очень сомневаюсь
По поводу Rezoom.SQL — провайдеры не работают и об этом знают все F# программисты начиная с миниального проф. левеля.
Дальше у вас, извините, дичь какая-то, блаженный бред и прямое игнорирование того, что я написал в других ветках. Лень отвечать даже.
Интересно, как вы себе представляете ссылку на реальный проект? Что кто-то откроет свои исходники, сохраняя при этом легаси, ради того, чтобы Паша с хабра успокоился?
И не стыдно её приводить в пример офигеть какой полезной библиотеки на F#?
Реальный — это тот, который используют за пределами того ЯП, на котором софт написан. В объёмах, достойных упоминания. Глючный орм, врапер aspnet и либа для сериализации тормознутых списков Microsoft.FSharp.Collections.list в json к реальным проектам не относится. Вы видать совсем далеки от программирования коль спрашиваете очевидные вещи. clickhouse, sqlite, мускул — исходные коды открыты, все используются чуть менее/чуть более чем везде, а не только фанбоями того ЯП, на котором они написаны, вроде вас. etcd, докер, serf, consul, кубернетиз, vitess — тоже самое, но при этом написаны на языке (языках) с GC. Да даже при создании net core и aspnet ни кому из разработчиков почему то и в голову не пришло заюзать F#, что видимо для вас свидетельствует о высокой полезности этого языка
Тулинг отвратительный? Это ложь. Тулинг хуже, чем у C#, но не настолько, чтобы скулить об этом под каждой статьей и уж тем более не настолько, чтобы заниматься промышленной разработкой было нерентабельно.
А вот как это выглядит на практике
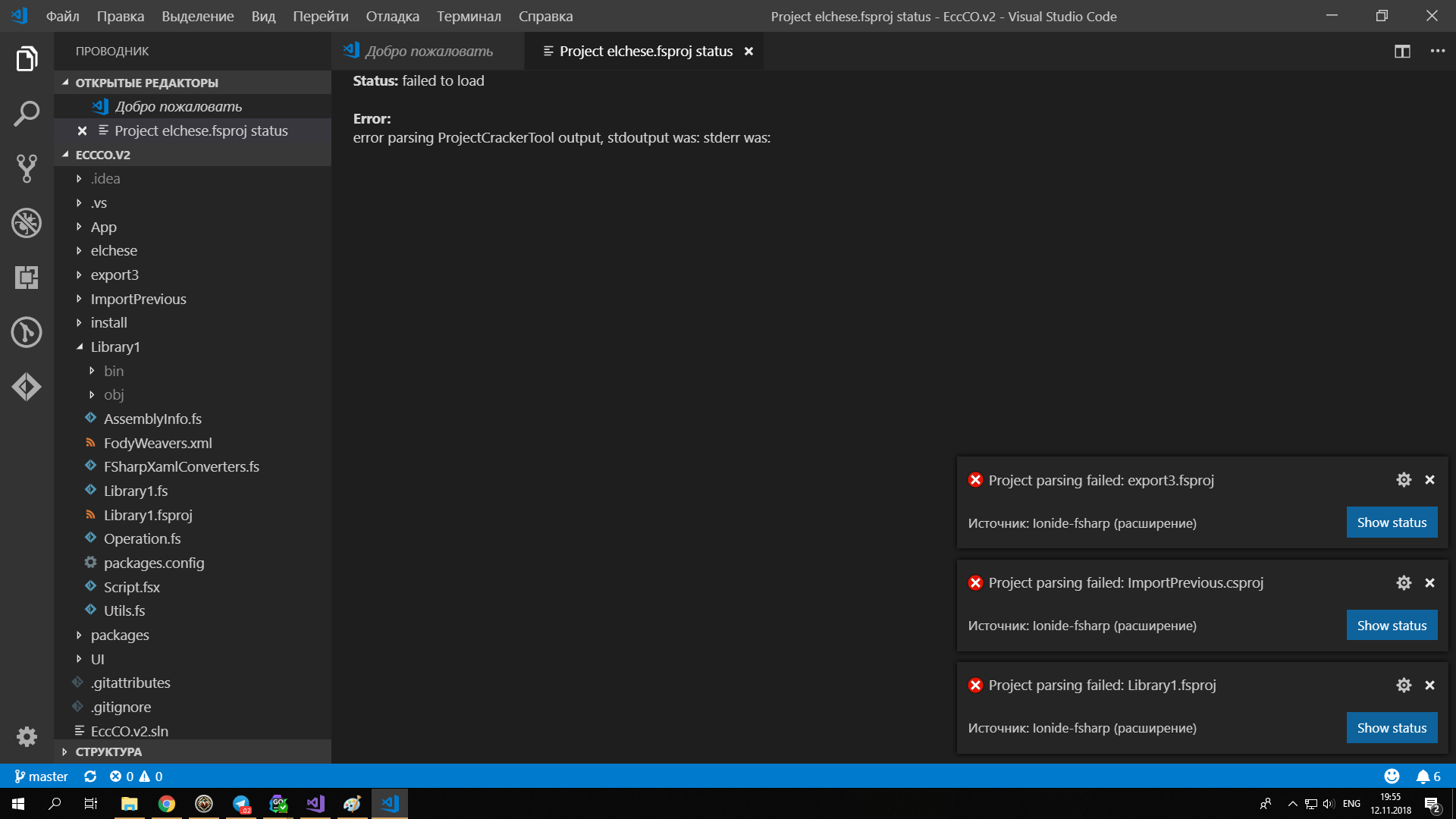
Status: failed to load
Error:
error parsing ProjectCrackerTool output, stdoutput was: stderr was:
Польский пан, который раз в месяц правит эту ide левой ногой, видимо счёл излишеством выдавать текст объясняющий, что именно не так пошло при загрузке проекта. Сами придумают что-нибудь, не маленькие. Вот такой вот он, промышленного уровня тулинг для F#
Где тут промышленный тулинг и IDE?
Однако, вы ничего не сказали про Visual Studio & Rider. Когда вы уже успокоитесь и перестанете строчить свои поверхностные субъективные желчные комменты? Ведете себя так, словно F# материализовался и лично насрал вам в миску.
И о боже мой он дерьмово работаетСпикеры на конфах, активисты сообщества в блогах и чатах, рассказывая про F#, показывают именно ionide. Видимо они не в курсе, что он дерьмово работает. При случае передам им эту вашу на удивление здравую оценку.
Однако, вы ничего не сказали про Visual StudioТам те же проблемы — периодически всё ломается и не работает. Сообщения об ошибках не пустые, да. Но от этого они не на много более информативные. Работа с F# периодически сопровождается ручной правкой xml файла проекта и гуглением почему всё отвалилось. Впрочем, вы же сами признались, что не знаете что такое реальный проект — откуда вам знать какие проблемы возникают при его разработке.
Когда вы уже успокоитесь и перестанете строчить свои поверхностные субъективные желчные комменты?Вы бы лучше аргументации добавили, а не эмоционального накала и ярлыков.
Впрочем, признаюсь, я собираю материал для доклада на тему почему F# отстой. И вы мне изрядно подсобили, спосибо.
Ведете себя так, словно F# материализовался и лично насрал вам в миску.Ваша с юзером Сзер риторика соответствует моим представлениям о типичном фанбое F# — хамоватом студенте неудачнике.
VS Code уже давно полноценная ide
Все с вами ясно
Спикеры на конфах, активисты сообщества в блогах и чатах, рассказывая про F#, показывают именно ionide. Видимо они не в курсе, что он дерьмово работает.
Не перевирайте мои слова, я говорил про большие проекты. Еще он, например, не может прожевать проекты Xamarin. И спикеры, кстати, нередко говорят, что Ионид хорош только для пет проектов (потому его и используют для презентации новичкам — не надо ставить ничего тяжеловесного, чтобы попробовать).
Там те же проблемы — периодически всё ломается и не работает. Сообщения об ошибках не пустые, да. Но от этого они не на много более информативные.
На сишарпе студия тоже временами вылетает, и на интелли сенс бывает виснет к чертям, а бывает, он вообще умирает. Но вам об этом невыгодно заикаться, так хейтить тяжелее.
Ваша с юзером Сзер риторика соответствует моим представлениям о типичном фанбое F# — хамоватом студенте неудачнике.
Лол. Я не знаю, что должно происходить в жизни человека, чтоб он с маньячным упорством приходил под каждую статью про F# и рассказывал всем, как все вокруг неправы. Ну ладно на хабре, где статья может в несколько хабов попасть, но прийти в тематический телеграм-чат и там всем заливать — вы уверены, что в этой истории неудачники мы?
Если кому-то кажется, что все вокруг идиоты, варианта два: либо он невероятный гений, либо он сам идиот.
Ну, может быть, вы и правда гений. История нас рассудит.
если в рейтинге активности на гитхабе F# на 44 месте?
Не смущает что статистика устарела на 4 года?..
Чукча не читатель, понимаю.
Добавьте вложенные ссылочные поля, и теперь ваш { get; } ничего не гарантирует — вы можете изменить поля этого поляАвтор наверняка Вы ведь слышали про инкапсуляцию, что Вам мешает в С# только в конструкторе переопределять поля, и сделать их приватными?
Но уже больно смотреть на старый код…
Серьезные портянки функциональной тарабарщины по неэстетичности и мракобесию уступают только плюсовым шаблонам.
В конечном итоге после прочтения кода ты иногда понимаешь, что всё очень здорово друг с другом соотносится и взаимовытекает, но нихрена не понятно, что же все-таки оно делает и как.
Портянки тарабарщины трудны в прочтении независимо от парадигмы. А так — в каждой парадигме свои устоявшиеся абстракции, и если у вас есть несколько лет опыта в ООП, но в ФП его гораздо меньше — не стоит удивляться, что когнитивная нагрузка для вас субъективно выше. Это вовсе не значит, что все воспринимают ФП так же, как вы.
А вообще в вашем утверждении можно поменять "функциональной" на "оопэшной", и суть не изменится — субъективщина без аргументов.
Мне больше всего понравился этот сайт.
Имел в виду знакомых с C#, но незнакомых с F#
Я бы посоветовал книгу "Программирование на F#". С тех пор F# изменился, но база — основные типы и сам функциональный подход все тот-же и описывается очень понятным и доступным языком.
Также есть восхитительный сайт F# for fun and profit. И, конечно, присоединяюсь к рекомендации worldbeater — "Domain Modelling Made Functional". Сам я эту книгу еще не читал, но это как раз тот случай когда можно советовать "не глядя"
Факт в том, что современные яООП (от C# до Javascript) сильно преобразились за последние годы, впитав в себя многие ценные фишки ФП. C# может и в лямбды, и в каррирование, и в иммутабельность (struct, readonly уже отменили?).
Примеры, что вы приводили (в частности, if (… ) {… } else {… }) — рука-либо. С таким «глубоким» пониманием C# и таким изысканным стилем кодирования, который вы приписываете абстрактному ООП-кодеру, мне кажется, в ФП ему рано.
Или вот, скажем,
Name: string VS public string Name { get; set; }
Нас волнует краткость? Тогда зачем нам свойства, там, где, можно предположить по логике автора, достаточно public — переменной? Да, модификатор public остается — беда….
Из разряда — «шах и мат, аметисты» (уже не к автору):
Такое почему-то тоже
var a = 0; var b = flag ? { Console.WriteLine("true"); a = 1; } : { Console.WriteLine("false"); a = 2; };
…
Так что тернарный оператор в C# конечно уступает expression-based if из F#
Учите матчасть:
var a = 0;
(flag ? new Action(() => { Console.WriteLine("true"); a = 1; })
: (() => { Console.WriteLine("false"); a = 2; })).Invoke();
Но фиг с ними, синтетическими примерами. Надо боевой код сравнивать.
var _ = flag ? Ternvoke(() => { ... }) : Ternvoke(() => { ... });
...
public static Action Ternvoke(Action a)
{
a();
return a;
}
Но, думается, некоторая «избыточность» кода C# в сравнении с F# картины ничуть не портит. А вот будет ли нетривиальная бизнес-логика столь же «читаема» в коде F#? Как ни крути, в продакшн не обойтись без сонма классов, без многоуровневой иерархии объектов в домене приложения…
Потому — соглашусь с апелляцией к «боевому» коду. Мне интересно было бы почитать разбор мало-мальски сложных проектов на F#, решающих задачи «реального» мира.
И тут можно наступить на родовую болезнь C# — отсутвие unit/Void.
Перегрузить Ternvoke для работы с Func<> не получится (вход можно, а выход — нет).
Пример из продакшна. В пайплайнах есть функция tee, которая просто делает сайдэффект над передаваемым аргументом и возвращает его же.
F#:
let tee f x =
f x |> ignore
xC# :
public static class Extensions
{
public static T Tee<T>(this T x, Action<T> f)
{
f(x);
return x;
}
}Предположим у нас есть функция saveToDb: 'a -> bool (принимает что-то, сохраняет в бд, возвращает успешно или нет)
F# пережовывает что угодно:
"abc"
|> tee Console.WriteLine
|> tee saveToDb
|> ...C# уже не очень:
"abc"
.Tee(Console.WriteLine)
.Tee(saveToDb)//упс, компайл еррор
...Added:
А было бы неплохо объявить на C# так:
public static T Tee<T>(this T x, Func<T, _> f)Но увы
Но, думается, некоторая «избыточность» кода C# в сравнении с F# картины ничуть не портит. А вот будет ли нетривиальная бизнес-логика столь же «читаема» в коде F#? Как ни крути, в продакшн не обойтись без сонма классов, без многоуровневой иерархии объектов в домене приложения…
Потому — соглашусь с апелляцией к «боевому» коду. Мне интересно было бы почитать разбор мало-мальски сложных проектов на F#, решающих задачи «реального» мира.
Обойтись без сонма классов очень даже можно. Отказываться от них полностью бессмысленно, они полезны. Но строчить классы для ВСЕГО — так же глупо, как всё засовывать в чистые функции.
Про избыточность C# по сравнению с F# неплохо сказано в свежих докладах Антона Молдована и Вагифа Абилова:
https://www.youtube.com/watch?v=4eXthLWzYrk
https://www.youtube.com/watch?v=4x9slVi_RBo
Сам пишу прод на F#, экономит тонну времени.
Про избыточность C# по сравнению с F# неплохо сказано в свежих докладах Антона Молдована и Вагифа Абилова:
Если вы не в состоянии показать избыточность C# по сравнению с F# в нескольких словах на понятном языке, значит либо избыточности нет, либо вы не владеете вопросом.
Если вы не в состоянии показать избыточность C# по сравнению с F# в нескольких словах на понятном языке, значит либо избыточности нет, либо вы не владеете вопросом.
Есть еще варианты кроме перечисленных вами.
В статье был приведен простейший пример, на всякий случай скопирую его снова:
C#:
public class Employee
{
public Guid Id { get; }
public string Name { get; }
public string Email { get; }
public string Phone { get; }
public bool HasAccessToSomething { get; }
public bool HasAccessToSomethinElse { get; }
public Employee(Guid id, string name, string email, string phone, bool hasAccessToSmth, bool hasAccessToSmthElse)
{
Id = id;
Name = name;
Email = email;
Phone = phone;
HasAccessToSomething = hasAccessToSmth;
HasAccessToSomethinElse = hasAccessToSmthElse;
}
}type Employee =
{ Id: Guid
Name: string
Email: string
HasAccessToSomething: bool
HasAccessToSomethingElse: bool }Для определения одного и того-же объекта в F# варианте затрачивается меньше времени. В рамках одного типа разница не столь значительна, но все изменится когда вы увеличите их количество в разы.
И это только самый тривиальный случай. F# код намного лаконичнее чем аналогичный на C#.
let newEmployee id name email hasAccessToSomething hasAccessToSomethingElse =
{ Id = id
Name = name
Email = email
HasAccessToSomething = hasAccessToSomething
HasAccessToSomethingElse = hasAccessToSomethingElse }2) Надо ли делать неизменяемыми поля объекта, который реально занимает ~30 байт — зависит от задачи. В 99.99% случаев — нет. Достаточно сделать его обычной структурой и передавать по значению, а не по ссылке. В этом случае код будет проще значительно, поскольку поля структуры не обязательно определять в конструкторе, они имеют разумное значение по умолчанию, которое не нужно указывать. HasAccessToSomething = false и т.д.
public struct Employee
{
public Guid Id;
public string Name;
public string Email;
public string Phone;
public bool HasAccessToSomething;
public bool HasAccessToSomethinElse;
}Так делали много лет за долго до C#, делают сейчас и будут делать дальше. И ни кого это не напрягает. В связи с эти у меня вопрос — чего ради пихать иммутабельность туда, где её ни кто не просил?
Мне трудно с ходу представить задачу, где 30 байт по значению а не по ссылке скажется на производительности. Может быть какое-то кеширование кликхауса, или что? Хотелось бы такую задачу увидеть вместе с бенчмарками
1) Вы пытаетесь схитрить, сделав вид что в F# не нужна функция, конструирующая Employee
let newEmployee id name email hasAccessToSomething hasAccessToSomethingElse = { Id = id Name = name Email = email HasAccessToSomething = hasAccessToSomething HasAccessToSomethingElse = hasAccessToSomethingElse }
Это лишь показывает твой невысокий уровень знания F#.
Да, эта функция не нужна.
Если ты так писал (или пишешь) неудивительно что у тебя так горит с языка.
Я попробую немножечко спасти ситуацию с уважением, подпорченную предыдущим комментатором.
В F# можно написать так, без использования конструктора:
type Employee =
{ Id: int
Name: string
Email: string
HasAccessToSomething: bool
HasAccessToSomethingElse: bool }
let newEmployee = {Id: 1, Name: "pawlo16"}В принципе, это написано везде, и скорее всего утверждение о необходимости конструктора действительно доказывает невысокий уровень знания F#.
Чтобы сохранить объективность, следует сказать что нам все еще нужны функции для преобразования и валидации. Впрочем, они не называются "конструкторами", а являются либо фабриками, либо просто участвуют в пайплайнах с помощью changeset-ов.
let newEmployee = {Id = 1; Name = "pawlo16"}let newEmployee =
{ Id = 1
Name = "pawlo16"
Email = ""
HasAccessToSomething = false
HasAccessToSomethingElse = false
}
Если кому то такое нравится, так это стокгольмский синдром в чистом виде.
Вопрос — кто после этого плохо знает F#?
Приведенная вами выше функция так же требует всех его полей. Разве нет? Но в c# без этой функции вроде как нельзя, а в f# — вроде как можно.
let x = newEmployee (Guid()) "name" "email" false falseА вот как создаёт Employee юзер Сзер:
let y = { Id = Guid(); Name = "name"; Email = "email"; HasAccessToSomething = false; HasAccessToSomethingElse = false }Почувствуйте разницу
В первом варианте легко перепутать местами параметры одного типа, к тому же он хуже читается.
Единственный бонус — карринг. Но вы сами постоянно пишете, что карринг не нужен.
То есть с одной стороны, вы утверждаете, что F# код хреново читается, с другой стороны сами пишете менее читаемый код, чем можно было бы. Говорите, что фшарписты продают душу лишь бы кода поменьше писать, но сами этим грешите там, где это совсем не нужно.
Может быть, дело не в языке?
В первом варианте легко перепутать местами параметры одного типа, к тому же он хуже читается.
Ну вы сейчас явно выдумываете, первый вариант объективно лучше. В том же js даже специальный сахарок есть, чтобы писать { field } вместо { field: field }.
Ну вы сейчас явно выдумываете, первый вариант объективно лучше.
Ну вы сейчас явно выдумываете, первый вариант объективно хуже.
Чем он хуже, если менее удобен и менее читабелен?
Там перечисляется информация, которая в данном случае совершенно не нужна. Какая мне разница, как поля у структуры называются?
Второй вариант вообще эквивалентен
let employee = new Employee();
employee.Name = "name";
employee.Email = "email";
...удобство через край плещется
let name = "name"
let email = "email"
let has1 = true
let has2 = false
let emp1 = newEmployee id name email has1 has2
let emp2 = newEmployee id email name has2 has1Оба варианта скомпилируются. Так вероятность ошибиться выше, чем при нормальной инициализации. Кроме того, на ревью ошибку заметить тоже тяжелее.
Так вероятность ошибиться выше, чем при нормальной инициализации.
Почему выше? Точно также можете has1 и has2 перепутать и все прекрасно скомпилируется.
Потому что вы видите сопоставление имени поля и имени переменной, которую собираетесь туда присвоить.
Я и в первом случае вижу, мне иде имя аргумента подсвечивает.
а ещё в C# вы бы просто сделали struct Employee — и даже не знали бы про геморой с созданием объектов. Ведь нормальному человеку и в голову бы не пришло делать такую структуру неизменяемой просто так чтобы была и потому что можно. И чтобы при создании объектов потом перечислять все её поля. И в этом вся суть языка F# — выдумать проблему и потом хвастаться как она там героически решается, гремя костылями. Точно так же работают все остальные фичи языка, которые автор статьи столь пафосно превозносит.
В том же js даже специальный сахарок есть, чтобы писать { field } вместо { field: field }.
Но там нет сахарка чтобы писать { false } вместо { field: false }. Догадайтесь почему...
Хорошо, пример с if/else неудачный, черт с ним.
Меня тут несколько раз уже носом ткнули в это, вы не первый. Как насчет всего остального, что есть в статье?
Далее. readonly? Хорошо, но кода надо написать все еще гораздо больше, чем в F#.
И это важно, потому что это влияет на решение разработчика о том, как он будет писать код. Все предпочитают двигаться по пути наименьшего сопротивления, все хотят писать меньше кода для решения одной и той же задачи.
У разработчика есть выбор:
1) Написать обычную изменяемую структуру, которая всем понятна и является дефакто стандартным решением этой задачи, набрав X символов
2) Написать неизменяемую структуру, набрав 3X символов, объяснять на код ревью, почему было принято такое странное решение, писать больше кода каждый раз, когда хочешь поменять 1-2 поля в ней, и, скорее всего, научить JsonConvert парсить ее, потому что дефолтного конструктора нет.
Кто в здравом уме выберет второй вариант?
Не забывайте, написать на C# неизменяемую структуру на принцип, чтобы доказать кому-то что-то, это совсем не то же самое, что писать так каждый день на работе.
То же самое относится к вашему "учите матчасть". Так сделать можно, но никто так делать не будет.
Что насчет неизменяемых коллекций в C#? Да, есть Collections.Immutable, но их все ругают за тормознутость, я ни в одном проекте не видел их использование.
Кстати, Equality & Comparison все еще надо самостоятельно реализовывать.
Покажите, пожалуйста, как выглядит каррирование на C#. Я честно не знаю.
public static Func<A, Func<B, R>> Carry<A, B, R>(this Func<A, B, R> f)
{
return a => b => f(a, b);
}
Func<double, double, double> log = (n, b) => Math.Log(b, n);
var log3 = log.Carry()(3);
var c = log3(9);
Ну вы же понимаете, что это непрактично для продакшна? А если мне нужно другое количество аргументов? А если это не Func, a Action?
Сравните теперь с каррингом в F#, где он нативный, и делать не надо ничего вообще.
let inline add x y z = x + y + z
let add5 = add 5
let add5then7 = add5 7Math.Log(base, n);Можно написать через карирование. Ну, например, как-то так:
var log10 = Math.Log.Carry(10)Но, значительно более читабельный вариант — такой:
var log10 = n => Math.Log(10, n)Конечно, вариант с каррированием на пару символов короче (на два, если быть точным), но, без сомнения, хипстота на следующем афтепати будет в восторге. А если аргумент в правильном порядке, а не специализированном под ФП, то как тогда?
Math.Log(n, base);
// =>
var log10 = n => Math.Log(n, 10)
// =>
var log10 = Math.Log.Carry(???)Даже в F# используется лямда в таких случаях. Так зачем вообще каррирование, если код без него более ясный и универсальный?
На самом деле вопрос скорее в том, зачем нужно каррирование на C# да и вообще, зачем оно необходимо на практике.
Потому что явная запись, без каррирования — это не кашерно. Не вписывается в концепцию EDD (Emotion-Driven Development). Естественно речь идёт об эмоциях узкого круга лиц.
log(n: number, base: number)Разве
`log` 10 не подставит в качестве аргумента n, хотя надо base?Смотря как вы смотрите на функции. map f — это не map, частично применённая к f, это просто функция, которая принимает список и возвращает список с f, применённой к каждому элементу.
Но отличается это от частичного применения только в том случае, когда map объявлена как принимающая ровно один аргумент.
`log ` 10 даст вам нужную функцию. Если мы говорим об ФП вообще, конечно.А вот это уже частичное применение функции, а не каррирование.
Но необязательно же для этих целей делать его автоматически или вводить по умолчанию в языке для всех функций.
Ваше сравнение паттернов с ФП — манипулятивная картинка для глуповатых программистов. Чистой воды демагогия. Специально для хипстоты, которая любит кричать: «ааа, ооп — такое глупое, не то, что фп», но при этом не очень любит думать.
Точно такой же бред можно сочинить и в обратную сторону:
— Функции высшего порядка / Класс
— Каррирование / Класс
— Композиция функций / Класс
— Предикат / Класс
— Функтор / Класс
— Лифт / Класс
— Моноид / Класс
— Монада / Класс
И так далее из списка «жаргона ФП»
Паттерны — это просто примеры некоторых общепринятых подходов, при помощи которых можно решать задачи. И таких не существует разве что в тех парадигмах, которыми никто не пользуется.
Особо смешно, что сперва автор приводит эту картинку, которая показывает, как все просто в ФП решается просто функциями, а потом зачем-то пишет статью с кучей практик (их можно назвать даже паттернами, лол). Странно, что у него мозг не взрывается от такого диссонанса. Шапку в мороз носите и выбирайте теплую, а не красивую.
1) имя «n» — полохое. Лучше либо никакое, либо нормальное
2) уже на пятерке строк pipeline у вас начнет рябить в глазах
В C# аналогичный синтаксический сахар — это static extension методы.
и, скорее всего, научить JsonConvert парсить ее, потому что дефолтного конструктора нет
И как же эту задачу будет решать F#? :-)
Что насчет неизменяемых коллекций в C#? Да, есть Collections.Immutable, но их все ругают за тормознутость, я ни в одном проекте не видел их использование.
Вы так пишите, как будто неизменяемые коллекции F# работают как-то принципиально по-другому...
F# имеет аттрибут [<CLIMutable>]. Он позволяет мутацию, но не из вашего F# кода.
и, скорее всего, научить JsonConvert парсить ее, потому что дефолтного конструктора нет
Мне тоже не совсем понятно что вы имели ввиду. Какой конструктор использовать можно указать с помощью [JsonConstructor]/[<JsonConstructor>]. К тому-же у структур есть конструктор по умолчанию.
Сложные приложения вряд-ли многие захотят выкладывать в открытый доступ.
WPF работает исправно. Полная F# поддержка для UWP скорее всего будет не скоро, но положительные сдвиги в этом направлении уже есть. Если по каким-то причинам вам нужен WinForms, то можно использовать, например, TrivialBehinds раз уж нет конструктора форм.
Xamarin.Forms поддерживает F#, для более удобной работы есть дополнительные библиотеки, такие как Fabulous, который здесь уже не раз упоминался.
Сложные приложения вряд-ли многие захотят выкладывать в открытый доступ.
Тем не менее в открытом доступе овердофига десктопных UI приложений на C# и почти ни одного на F#. Совпадение?
WPF работает исправно
WPF в F# ?? Вы в данном случае себя обманываете или окружающих?
VS не содержит шаблона проекта F# для WPF.
Xaml редактор не умеет генерировать F# код и привязывать его к разметке.
Если у вас вся исправность работы F# с WPF сводится к прикручиванию сборки, написанной на F#, так это смех.
Тем не менее в открытом доступе овердофига десктопных UI приложений на C# и почти ни одного на F#. Совпадение?
Нет, не совпадение. Не очень понимаю что именно вы хотите оспорить. C# намного, намного более популярный и востребованный язык чем F#. OpenSource разработчику десктопного UI приложения (да и не только десктопного) не выгодно писать на F#, просто по той причине, что проект не встретит той поддержки, которую мог бы получить аналогичный на C#. Все это должно быть достаточно очевидно. Но раз уж зашла речь об очевидных вещах, то если кто-то и задумается над написанием WPF приложения на F#, то он должен быть готов к тому, что хороших материалов не так уж и много.
WPF в F# ?? Вы в данном случае себя обманываете или окружающих?
Ни себя, ни окружающих я не обманываю. Вы просто говорите о другом. Поддержка F# в VS значительно уступает поддержке C# и проблема отсутствия шаблона для WPF далеко не в вверху списка того, что было бы здорово добавить.
Xaml редактор не умеет генерировать F# код и привязывать его к разметке.
Вы абсолютно правы в том, что поддержки для code-behind в F# проекте в том виде в котором она есть для C# нет, просто по той причине что в F# нет такого понятия как partial.
Если у вас вся исправность работы F# с WPF сводится к прикручиванию сборки, написанной на F#, так это смех.
Вы ошибаетесь. Хотя нет ничего смешного в том, чтобы определить View часть в C# проекте, тогда как все остальное переложить на F#.
Вы абсолютно правы в том, что поддержки для code-behind в F# проекте в том виде в котором она есть для C# нет, просто по той причине что в F# нет такого понятия как partial.
Отсутствие partial конечно осложняет, но не делает задачу невозможной. Если бы они очень захотели, то придумали бы врапер со ссылкой на реализацию (как вариант). Либо производили бы кодогенерацию в определённое место исходного файла, обозначенное тегами в комментариях. Вариантов много, но это ни кого не интересует — инвестиции в такой функционал не окупятся. Поэтому не проще ли честно признать, что вот этот вот вариант с десктопным UI на F# — маргинальщина и отстрел ног? Я пробовал если что.
нет ничего смешного в том, чтобы определить View часть в C# проекте, тогда как все остальное переложить на F#
Не всегда приемлемо держать модели в отдельном проекте. Кроме того модели на практике вряд ли будут в ФП стиле, потому что должны быть совместимы с сугубо ООП-шными вещами на подобие IPropertyChanged. То есть писать всё то же ООП, но только не C#, а на F#, чтобы потом связать его из С#. Это несколько странно.
По моему опыту использования F# в нём ничего этого нет, потому и проектов на нём нет в количестве, достойном упоминания.
Можно узнать по-подробнее о вашем опыте с F#? Впервые встречаю человека с реальным опытом с F# и который бы утверждал что "F# не нормальный язык".
Отсутствие partial конечно осложняет, но не делает задачу невозможной. Если бы они очень захотели, то придумали бы врапер со ссылкой на реализацию (как вариант).
Возможно, конечно. Даже FsXAML предоставляет совсем базовую поддержку для code-behind.
Поэтому не проще ли честно признать, что вот этот вот вариант с десктопным UI на F# — маргинальщина и отстрел ног?
Проще, да, но не честнее. Код на F# пишется быстрее. Даже для демонстрации проблемы или наоборот решения какого-то вопроса использовать его намного удобнее. В тех случаях когда не требуется красивый и сложный UI с большим количеством code-behind возможностей F# точно хватит.
Не всегда приемлемо держать модели в отдельном проекте.
Разве? Вы не могли бы привести примеры?
Кроме того модели на практике вряд ли будут в ФП стиле, потому что должны быть совместимы с сугубо ООП-шными вещами на подобие IPropertyChanged.
В том то и дело что используется другой подход. F# в первую очередь функциональный язык программирования, а не чисто функциональный. Если лучше и удобнее применить другой подход, то его и стоит применять.
Можно узнать по-подробнее о вашем опыте с F#?
Опыт приличный, и он достаточно стандартный для F# — от малого к бОльшему. Изучил в 12 году будучи начинающим программистом на волне интереса к ФП, доверия к втирающим про world bank type provider и из-за вещей, которых в C# на тот момент не было, в частности, async и MailboxProcessor. Область применения — круд сервисы в монолитных проектах и вебморды. В данный момент инспектирую чужой код и переписываю F#-лигаси монолит на другой язык программирования — думаю понятно какой. Были определённые ожидания, связанyые с websharper и ui.next, но к сожалению они так и не вышли из маргинальной ниши. Все остальные фреймворки (например hopack, suave, fable как самые изветсные), как показала практика, можно выкидывать, не дочитав readme. В чём любой желающий может легко убедится: вместо документации — имитация оной, 1.2 контрибьютера, поддержка околонулевая, шизофреничные стрелочки в качестве кастомных операторов, в продакшене нет, количество звёздочек на гитхабе красноречиво намекает что проект никому не нужен
Код на F# пишется быстрее.
При этом читается хуже, потому что нет жестких гайдлайнов, развитых линтеров и единого форматирования. F# — типичный write-only ЯП. Возвращаться к своему коду тяжело, читать чужой невыносимо больно — вне зависимости от уровня квалификации того, кто этот код написал. Ну и работат код на F# значительно медленнее, чем C#.
В тех случаях когда не требуется красивый и сложный UI с большим количеством code-behind возможностей F# точно хватит.
Если задача проста, то и F# соёдёт и даже иногда C++.
Не всегда приемлемо держать модели в отдельном проекте.
Разве? Вы не могли бы привести примеры?
Усложняется сборка. Линтеры не могут почекать имена пропертей. А иногда модели вообще не нужны, достаточно старого доброго smart ui.
F# в первую очередь функциональный язык программирования, а не чисто функциональный. Если лучше и удобнее применить другой подход, то его и стоит применять.
Если лучше и удобнее применить ООП, то лучше и удобнее применить C#, поскольку F# в планее ООП не даёт ничего сверх C#. object expression — это мелочи и легко решается закрытыми вложенными классами.
Не надо свой опыт 6-ти летней давности втирать людям как актуальный.
- Linter — fantomas
- Тулинг — обычный Net Core SDK (dotnet build и погнали). F# компилятор нынче в него включён, ничего ставить не надо, если неткор стоит.
- Про отсутствие доков, это конечно же прогон. В Hopac дока просто гигантская. Giraffe (на мой взгляд самый перспективный веб фреймворк, т.к. поверх asp.net core) прекрасно документирован.
- Скорость кода F# медленнее C#? У меня другие данные
Если что, pawlo16 известный в комьюнити F# хейтер. К его словам надо с пудом соли относиться. Ходит по всем F# статьям на хабре и рассказывает как он когда-то не осилил, а Go эт просто космос :)
Ходит по всем F# статьям на хабре и рассказывает как он когда-то не осилил
А как на счёт показать где это я рассказывал что не осилил F#?
Расскажите какие именно мои высказывания в топике про F# вы интерпретировали как «Go эт просто космос»
Не надо свой опыт 6-ти летней давности втирать людям как актуальный.
Вот только опыт не шестилетней, а недельной давности. Не надо выдавать свои фантази за факты. Перечитайте написанное выше, может с n-ого раза дойдёт
Linter — fantomas
для тех, кто пробовал R#, это не линтер, а одно лишь название. Про какую ещё пионерскую поделку расскажете?
В Hopac дока просто гигантская.
так у вас качество доки определяется количеством строк? ну-ну. Вы ещё расскажите о том какая в fable хорошая дока, посмеёмся
Скорость кода F# медленнее C#? У меня другие данные
Видимо левель у вас низковат, иначе бы вы не сравнивали синт. тесты с боевым кодом. С чего бы F# быть медленнее на синтетических тестах, если он почти в точности переписан с C# и использует в основном Array и mutable?
Были определённые ожидания, связанyые с websharper и ui.next, но к сожалению они так и не вышли из маргинальной ниши.
Сам я далек от веб-разработки, но WebSharper с самого начала показался несколько странным.
Все остальные фреймворки (например hopack, suave, fable как самые изветсные), как показала практика, можно выкидывать, не дочитав readme.
Вы, наверное, вместо Hopack хотели написать Giraffe?
Можно уточнить что вы имеете ввиду под "как показала практика"?
В чём любой желающий может легко убедится: вместо документации — имитация оной, 1.2 контрибьютера, поддержка околонулевая, шизофреничные стрелочки в качестве кастомных операторов, в продакшене нет, количество звёздочек на гитхабе красноречиво намекает что проект никому не нужен
С документацией да, есть некоторые проблемы. Но сообщество достаточно активное чтобы быстро получить ответ на искомый вопрос.
В продакшене Suave используется, хотя сейчас, насколько мне известно, большую все популярность набирает SAFE.
Что касается звездочек и контрибуторов, то это все есть в открытом доступе:
Suave: 1015 Star / 86 contributors
Fable: 1,437 Star / 90 contributors
Giraffe: 939 Star / 46 contributors
Я уверен, что здесь достаточно больше количество звездочек чтобы считать заявление, цитирую "проект никому не нужен" безосновательными. Решительно не понимаю почему вы прибегаете к подобной риторике.
При этом читается хуже
Дело вкуса или привычки. Мне, например, читать F# код значительно проще чем C#. И тут дело не в самом синтаксисе, а в строгом порядке файлов. В F# все зависимости четко прослеживаются, тогда как в C# проекте крайне сложно ориентироваться в виде хаотичного расположения файлов.
При этом читается хуже, потому что нет жестких гайдлайнов, развитых линтеров и единого форматирования.
Жестких нет, но есть рекомендации
The F# Component Design Guidelines
F# style guide
Возвращаться к своему коду тяжело, читать чужой невыносимо больно — вне зависимости от уровня квалификации того, кто этот код написал.
Не нужно распространять ваш негативный опыт на всех
Усложняется сборка.
Сложно представить проект в котором модель и UI смешаны в одном проектном файле по причине сложности их сборки. Можно увидеть ссылки или статьи подтверждающие ваши слова ?
А иногда модели вообще не нужны, достаточно старого доброго smart ui.
Мне такое сложно представить :-)
Если лучше и удобнее применить ООП, то лучше и удобнее применить C#, поскольку F# в планее ООП не даёт ничего сверх C#.
Абсолютно
Сам я далек от веб-разработки, но WebSharper с самого начала показался несколько странным.
Так потому и показался что далёк.
Вы, наверное, вместо Hopack хотели написать Giraffe?
Нет, я имел ввиду Hopac.
Я уверен, что здесь достаточно больше количество звездочек чтобы считать заявление, цитирую «проект никому не нужен» безосновательными
А я нет. Например, Suave делают 2 человека, отнюдь не 86. Для сравнения беру первый пришедший в голову проект на Го — маргинальный, ведомый одним человеком на досуге потехи ради, исключительно под windows desktop, хайпа ноль — 2900 stars. Потому что проект полезен в своей нише. И вот таких либ, знаете ли, много. А Suave существует давно, обсуждается в сообществе весьма активно, на волне некоторого хайпа мог бы и больше звёздочек собрать. Впрочем, не навязываю, это субъективная оценка.
Мне, например, читать F# код значительно проще чем C#
А приходилось ли вам инспектировать чужой код на F#?
в C# проекте крайне сложно ориентироваться в виде хаотичного расположения файлов
Не разу не сталкивался с такой проблемой. Обычно иерархия модулей проекта определяется архитектурой и понятна из названий каталогов и файлов проекта. Хаос означает, что были использованы кривые абстракции, либо забили на DI, либо архитектурные косяки. И, наоборот, постоянно думать о порядке файлов в проекте страшно выбешивает.
Не нужно распространять ваш негативный опыт на всех
Что плохого в том, чтобы предостеречь начинающих от некачественного инструмента? Тут у нас вроде бы место для дискуссий, и даже можно высказывать мнения, не совпадающие с автором статьи. Или об F# либо хорошо, либо ничего, как о покойнике (в комьюнити именно так и принято, благо нет возможности сжигать еретиков на кострах)?
Сложно представить проект в котором модель и UI смешаны в одном проектном файле по причине сложности их сборки. Можно увидеть ссылки или статьи подтверждающие ваши слова?
Вам сложно понять почему один проект лучше чем два при прочих равных? тогда я сдаюсь. Модель, которая постоянно меняется в процессе разработки, и чтобы из основного проекта увидеть изменения эти изменения, нужно пересобрать вспомогательный. Если вас это совершенно не напрягает, то у меня ни каких вопросов нет.
Для сравнения беру первый пришедший в голову проект на Го
Сравнение неуместно, при чем здесь любой другой язык?
А Suave существует давно, обсуждается в сообществе весьма активно, на волне некоторого хайпа мог бы и больше звёздочек собрать
У F# репозитория всего 1,406 звезд. Хотя тут наверное организация сыграла роль, так как F# Core находящийся в FSharp организации намного более популярен — 177.
А приходилось ли вам инспектировать чужой код на F#?
Приходилось. Кроме того, мой первый PR был сделан как раз в F# библиотеку.
Обычно иерархия модулей проекта определяется архитектурой и понятна из названий каталогов и файлов проекта
Да, но если речь идет об OpenSource проекте, то разбираться в чужом коде, чтобы исправить баг или даже просто локализовать проблему бывает проблематично (время-затратно)
И, наоборот, постоянно думать о порядке файлов в проекте страшно выбешивает.
Не нужно думать о порядке файлов, он автоматически линейный.
Что плохого в том, чтобы предостеречь начинающих от некачественного инструмента?
Вы меня превратно поняли. Я лишь попытался вас предостеречь от громких безосновательных утверждений. В вопросе полноты изложения — указывать не только на плюсы, но и на недостатки я вас полностью поддерживаю, но хотелось бы что-бы они были обоснованы.
Я действительно благодарен вам за ответы.
(в комьюнити именно так и принято, )
Насколько я могу судить, в F# сообществе принято говорить правду.
Модель, которая постоянно меняется в процессе разработки, и чтобы из основного проекта увидеть изменения эти изменения, нужно пересобрать вспомогательный.
Shrug. Все-таки не на C++ пишем, сборка занимает не так много времени.
Сравнение неуместно, при чем здесь любой другой язык?
А с чем сравнивать-то? на F# нет проектов, которые были бы кому то интересны за пределами F#.
Да, но если речь идет об OpenSource проекте, то разбираться в чужом коде, чтобы исправить баг или даже просто локализовать проблему бывает проблематично (время-затратно)
В таком случае это либо косяк ведущих разработчиков, не документировавших архитектуру и общие правила для контрибьютеров, либо пулреквестера, который не стал в это унфу вникать
Не нужно думать о порядке файлов, он автоматически линейный.
Да ладно, ещё как нужно постоянно смотреть в какое место файла вставить кусок с функцией и в каком месте проекта должен фал находится. В C# каталог соответствует пространству имён, файл -классу, классы в пространстве имён друг друга видят, что весьма удобно. А в F# надо постоянно классы в файле и сами файлы переставлять местами, чтобы соблюсти нужный порядок, при котором каждый класс видит то, что ему нужно. Это на самом деле утомительно.
// a.fs
namespace Y
type A() =
let _ = B() // ошибка компиляции
// b.fs
namespace Y
type B() =
let _ = 0Насколько я могу судить, в F# сообществе принято говорить правду.
Но мне постоянно врут в этом топике. А на предложение ответить за слова — молчат. Что характерно, спикеры на конфах так же себя ведут.
Все-таки не на C++ пишем, сборка занимает не так много времени.
Отвлекаясь на такие мелочи как сборка проекта модели, разработчик теряет концентрацию и мысль уходит безвозвратно.
Я действительно благодарен вам за ответы.
Мне наставили минусов, поэтому я не могу отвечать. Учитывая идиотскую систему минусования, введённую идиотами, владеющими хабром, пожалуй, это будет мой последний сюда визит.
А с чем сравнивать-то? на F# нет проектов, которые были бы кому то интересны за пределами F#.
Вынужден напомнитm вам ваш первоначальный тезис:
"количество звёздочек на гитхабе красноречиво намекает что проект никому не нужен"
А в F# надо постоянно классы в файле и сами файлы переставлять местами, чтобы соблюсти нужный порядок, при котором каждый класс видит то, что ему нужно.
В F# не нужно постоянно переставлять местами файлы и классе. В отличие от C# здесь нет рекомендации каждый класс выделять в отдельный файл.
Но мне постоянно врут в этом топике.
Вы заблуждаетесь. Скорее всего происходит банальное недопонимание. Просто уточните что имеет ввиду собеседник прежде чем делать скоропалительные выводы и уж тем более переходить к обвинениям.
А на предложение ответить за слова — молчат.
Возможно они не хотят повторять одно и то-же?
Что характерно, спикеры на конфах так же себя ведут.
Можно увидеть примеры?
Отвлекаясь на такие мелочи как сборка проекта модели, разработчик теряет концентрацию и мысль уходит безвозвратно.
Если разработчику понадобилось изменить модель при разработке UI части возможно то, что мысль ушла, даже хорошо ;)
Предлагаю оставим эту тему хотя бы до тех пор пока вы не предоставите ссылки подкрепляющие вашу точку зрения.
Мне наставили минусов, поэтому я не могу отвечать. Учитывая идиотскую систему минусования, введённую идиотами, владеющими хабром, пожалуй, это будет мой последний сюда визит.
Позвольте дать небольшой совет. Перечитайте свои комментарии к этой публикации (и вероятно к другим тоже). Они в большинстве своем чрезмерно эмоциональны. Я не берусь утверждать насколько они обоснованы, но, правда, сложно себе представить, что называя людей идиотами вы получите "+" в карму и за комментарий.
Вы тратите много времени здесь, комментария статьи. Вместо того чтобы раз за разом обрушивать на F# спорную критику можно было бы направить энергию в конструктивное русло.
Плохая документация? Внесите улучшение.
Не хватает какой-то фичи? Предложите ее добавить.
Видите проблему? Вынесите на обсуждение.
Мне наставили минусов, поэтому я не могу отвечать. Учитывая идиотскую систему минусования, введённую идиотами, владеющими хабром, пожалуй, это будет мой последний сюда визит.
Боже, как же мы без вас? Кто придет в статью про F# и расскажет, какое он дерьмо, кто придет на хабр и откроет нам глаза, что хабр сделан идиотами? Потеря.
Но я вас понимаю, постоянно хейтить F# дело трудное и неблагодарное, даже с вашим опытом.
Возможно, язык приятнее для программиста, но мы знаем, что приятное далеко не всегда полезно.
Ага, ведь на каждом языке/фреймворке стоит правдивый лейбл "Я принесу вашему бизнесу 273 доллара за 2 недели". C# занял свою нишу, на нем написана куча проектов и программистов на нем гораздо больше на рынке. Внедрение новой технологии это всегда риск, и каждый бизнес сам решает, насколько он охотно идет на это. Посмотрите на обилие легаси проектов с древними технологиями и ужасным кодом — для бизнеса было бы просто чудесно по щелчку пальцев превратить этот код в хороший: и фичи быстрее делаться будут, и багов будет меньше, и текучка кадров упадет, и басфактор тоже снизится. Но бросить все и написать с нуля — это риск и гарантированный простой продукта. Переписать все на новый язык с новой парадигмой — это еще больший риск. А потом же обязательно стоит учесть момент с количеством кадров — сейчас мы перепишем, а нанимать кого будем?
В долгосрочной перспективе, конечно же, лучше писать на F# (на мой взгляд, по крайней мере). Но в долгосрочную перспективу не все умеют, а если и умеют, не всегда ее выбирают.
Который пишет в ФП стиле сервисы для миллионной аудитории, и потому его мнение в этом вопросе хоть что то стоит.
Что-то мне не удаётся проследить причинно-следственную связь в этом выражении. Типа если человек работает в компании, какими-то из сервисов которой пользуются много людей в день, то его мнение что-то стоит. А если человек работает в мелкой компании, которая делает софт для пары десятков человек в мире, то не стоит ничего?
Если человек работает в мелкой компании, которая делает софт для пары десятков человек в мире, то не стоит ничего?
Насколько я понимаю здесь имелось ввиду высокая надежность Haskell и FP в целом что безотказно работает для высоконагруженных систем. Но то, что один язык хороший не делает другой автоматически плохим или непригодным :shrug:
Хотя с причинно-следственной связью там есть определенные проблемы. Тезис, который pawlo16 предположительно пытался оспорить следующий:
"F# хороший выбор для тех кто только начинает знакомство с функциональной парадигмой. Как минимум тем, что дальнейший переход на чистый Haskell будет намного проще чем его изучение с 0."
Вот только приведенные аргументы относятся к чему-то совсем другому:
Единственное, что опытный хаскелист с практикой посоветует фишарписту — это забыть F# и ни когда не вспоминать.
Ссылаться на мнение штангиста — не лучший аргумент. Да и это 100% инфа, что он вообще на хаскеле в яндексе пишет? Быстрогугление заставляет усомниться.
F# меня испортил, или почему я больше не хочу писать на C#