Comments 42
Дорогой друг, вы просто ничего из исходной статьи не поняли и написали кучу непонятных слов с непонятной интенцией. Но зато ваша статья по модулю имеет шансы набрать то же количество минусов, что и плюсов исходная.
Статья о GIL и его поведении. Поинт автора был в том, что даже атомарная операция тип +=, казалось бы исполняемая в одном цикле блокировки GIL все равно не атомарная и без синхронизации мютексом не обойтись, как могло бы показаться неопытным разработчикам. В общем, как то так, а не вот так, как у вас. К сожалению, гора родила мышь.
Поскольку у вас и ссылка на исходную статью битая, позволю себе: https://habr.com/ru/amp/publications/764420/
Если ваша ВКП за окошками не использует потоки или процессы - это не параллельное программирование, а в лучшем случае конкурентное, если же использует - вы наглый обманщик :)
Дорогой друг, вы ...
Дорогой друг (хоть один друг есть при наличии 16-ти врагов на текущий момент) , параллельное программирование, как и последовательное, не привязано к платформе реализации. Это как минимум - микро, как максимум - макро. Но лучше не микро. Последнее это как уровень ассемблера. Микро можно связать с языком высокого уровня, макро - уровень визуальной среды. Последнее, чтобы было понятно, это типа LabVIEW, MATLAB, SimInTech и т.д. и т.п. Это достаточно наглядно показано чуть ниже на уровне LabVIEW. Что там "под капотом" - уже не столь важно. Важен результат. Чтобы даже по нему Вы, мой друг, не смогли сказать параллельная это программа или последовательная, реализована она на потоках или на чем-то еще. Поскольку Вы про мою реализацию ни чего такого тоже сказать не можете, а лишь только гадать, то это даже меня радует, т.к. защищает от наглых обвинений в чем-то, что к параллельному программированию не имеет отношения.
Мой друг, параллельное программирование - это прежде всего параллельная вычислительная модель. Многопоточность, конкурентность и то, что Вы считаете, насколько я могу судить, параллельным или конкурентным к алгоритмической вычислительной модели ни как не относится. От слова, как нынче модно говорить, совсем. Все это может использоваться, как средство реализации той или иной вычислительной модели (например, data flow в LabVIEW или автоматные параллельные вычисления в ВКПа), где все это скрывается под капотом, но и не более того. Вот такое, я бы сказал, минимальное введение в начала теории алгоритмов и программ... В том числе и параллельных. Но ... не спешите благодарить. Вам - по дружески :)
Спасибо что объяснили. От этого Ваш опус не становится более релевантным или адекватным исходной посылке. Человек про GIL писал, а Вы - не знаю Python, но «осуждаю», а вот вам мое «кто о чем, а лысый о расческе». Вам бы расслабиться и не гонориться про введение в алгоритмы, Вы же ничего о моем образовании не знаете, да и неадекватных статей я не пишу.
Человек про GIL ...
Человек написал прежде все про то, как он решал элементарную казалось бы параллельную задачку... В этом смысле я ни кого и ни за что не осуждаю да и не обсуждаю. Я привел свое решение той же задачи. Вот только, если Вы обратили внимание, в завершение у меня возникли сомнения, а той ли задачи. А что мы должны были получить в идеале?
В конце статьи, если Вы заметили, я привел свой ответ на вопрос, изначально поставленный автором статьи. Вот почему-то на его счет нет ни возражений, ни согласия с ним. А ведь это то, с чего надо было начать автору статьи. GIL ни GIL, потоки или что иное, Python, C++ или LabVIEW. Все это бессмысленно, если нет четкого понимания - а что должно быть? И вот тут появились определенные сомнения, т.к. то, к чему стремился автор не есть тот результат, который должен быть в идеальном параллельном решении (специально не говорю - программы). И свой вариант ответа я и привел...
А потому конкретный вопрос - а что, например, ожидали бы Вы - Х или X*К или промежуточный между этими значениями результат? В принципе я получил их все. Но вот только какой правильный? ;)
Процитируем же автора:
В данной статье я покажу на практическом примере как устроена многопоточность в Python, расскажу про потоки, примитивы синхронизации и о том зачем они нужны.
И еще:
Изначально я планировал что это будет простая и короткая заметка, но пока готовил и тестировал код нашел интересный неочевидный момент связанный с внутренностями CPython, так что не спешите закрывать вкладку, даже если уверены что знаете о потоках в Python всё :)
Это вообще не о том, как сделать многопоточный счетчик.
Вы ушли от ответа. Пусть автор обсуждает что угодно, но он это обсуждение базирует на конкретном примере и ждет от него какой-то результат. Выбрал ли он корректный пример, тот ли он получил результат, который ждал получить. Но самое интересное - а верны ли его ожидания. Судя по статье, то он ожидал все же ровно X*K. Но поскольку исходная постановка - абсолютно одинаковые параллельные процессы и переменная-счетчик, к которой ни как не оговорен режим доступа. И тут - или неверное представление о решаемой задаче или просто неверное представление о том результате, который он должен был бы получить по его замыслу.
Повторю еще раз. Я тоже могу заблуждаться... Но хотелось бы все знать, а что ожидали Вы, лично? Какое значение счетчика должно быть? Судя по всему, Вы все же на стороне автора и, наверное, лучше меня понимаете его замысел... Или, может, автора на сцену? Если он, конечно, отслеживает наше общение ;)
"Крайняя статья". Даль и Ожегов в гробу перевернулись.
Крайними бывает только мера, Север и плоть.
Даль и Ожегов в гробу перевернулись.
Зато парашютисты одобрительно закивали ;)
...Даль и Ожегов в гробу перевернулись.
Тоже неплохо. Лежать все время - скука скучная :) Вы не поняли - это все шутка юмора. См. ниже про парашютистов. А есть еще летчики и другие рисковые профессии. Программисты - менее рисковая работа, а потому, возможно, им и не очень понятен такой "профессиональный юмор" (судя по минусам парашютистам)... Задорнова им на их голову... :)
Окошки напоминают Windows, Windows система многопоточная, скорее всего запущена на многоядерном проце, вряд ли у вас Pentium 1. Что такое ВКП и почему оно без потоков?
Что такое ВКП и почему оно без потоков?
См. здесь на Хабре Автоматное программирование: определение, модель, реализация
Уважаемый Вячеслав, у Вас есть удивительнейшая способность изложить материал так, что полёт мысли будет понятен очень немногим.
Вообще говоря, параллельное программирование родилось не сегодня, есть устоявшиеся паттерны. Состояние гонки, семафоры, рандеву, критические секции, очереди и всё такое - всё это хорошо известно и обсуждается в любом учебнике.
Если хочется эзотерики, её тоже есть у меня. Возьмём LabVIEW, нарисуем два параллельных for цикла, инкрементирующих одну и ту же переменную по тысяче раз:

Это классическое состояние гонки (race condition), мы не можем сказать в какой момент произойдёт чтение и запись, циклы не синхронизированы, результат выполнения на выходе неопределён, будет где-то между 1000 и 2000 (типичная ошибка, которую почти все новички делают, кстати).
Что мы можем сделать - добавить семафор, блокируюший критическую секцию:

Вот теперь всегда будет выполняться код либо сверху либо снизу (кто первый захватит семафор), и результат будет всегда 2000 - каждый инкремент отработает.
Если нужно получить 1000, можно воспользоваться рандеву, тогда будет так (этот паттерн редко используется, но тем не менее):

Теперь я торможу оба цикла перед записью и мне уже без разницы, отработает один или оба - они теперь синхронизированы и результат на выходе будет строго 1000.
Теоретически можно и автоматы можно навесить с синхронизацией переходов, но зачем?
В случае ПЛК есть своя специфика - там жёсткий реалтайм и циклическое выполнение кода, где происходит чтение переменных/работа с ними/запись, хотя и там можно состояние гонки сделать, если очень захотеть, а можно действительно сделать "потокобезопасный" код без использования общепринятых методик.
Уважаемый Вячеслав, у Вас есть удивительнейшая способность изложить материал так, что полёт мысли будет понятен очень немногим.
Вы же знаете - "лучше меньше да лучше".
В случае ПЛК есть своя специфика ...
Причем здесь это. Для кого-то это, видимо, новость или даже нонсенс, но есть модель параллельных вычислений, в которой ни слова про потоки. От слова совсем. Есть даже ее реализация в форме ВКПа. На каком языке сделана, на какой платформе - дело, можно сказать, случая. Главное, что есть и демонстрирует свои возможности. И в ней, как можно убедиться, нет проблем потоков. Наоборот - все много проще и несравненно надежнее. Но... перечитайте еще раз статью Ли про потоки. Там все сказано. Про потоки, конечно. Это важно, а о том, чем их заменить, несколько, на мой взгляд, не то.
Да, LabVIEW, конечно, хорошая среда. Но у меня она не прошла тест на моделирование RS-триггера. Было это правда давно. Но не думаю, что что-то изменилось...
Что касается ПЛК, то мне просто подумалось, что вы с этим явно связаны, поскольку слишком глубокое погружение в этот мир вызывает определённую, хммм, скажем так - "профессиональную деформацию", но это я по себе сужу, у меня случай вдвойне тяжёлый - я ещё и на LabVIEW больше двадцати лет программирую.
На самом деле у Ли, как мне кажется, проблема несколько надумана. Сейчас в общем нет особых проблем с параллельным программированием, современные средства весьма неплохие и развиваются. Я по жизни занимаюсь машинным зрением в реальном времени и мне постоянно приходится распараллеливать вычисления, чтобы добиться требуемой производительности и "выжать" всё из современного железа. И есть несколько уровней параллелизации - я могу использовать SIMD команды (AVX, AVX2, AVX512 и FMA) и обсчитывать несколько пикселей буквально одной командой процессора. Или же я могу разбить изображение на блоки и уже их обрабатывать несколькими потоками, ну или построчно. Или ещё на уровень выше - если идёт видеопоток, то каждое изображение на своём процессоре. Я это называю для себя нано-, микро- и макро- параллелизацией.
LabVIEW сама по себе весьма неплоха в этом смысле, вы же знаете, как там устроена модель потоков данных - вот если я хочу сложить две картинки, а другие две вычесть, а затем результат перемножить, то я просто делаю вот так:

И сложение и вычитание будут осуществляться параллельно. Там, под капотом действительно будут созданы два потока, в кадом вызовется DLL, но я от ручного создания потоков избавлен. Равно как избавлен и от синхронизации - умножение "дождётся" результатов этих двух потоков и выполнение продолжится только после их завершения - мне и тут не надо прилагать никаких усилий, это гарантирует модель потоков данных (ну та, что data flow).
Более того, используя Timed Loop я могу даже управлять тем, на каком процессоре будет выполнен мой код, вот два while(true); цикла без пауз:

Ну и вот, два процессора с номерами 1 и 2 загружены под завязку:

При использовании С/С++ я могу параллелить всё через OMP, просто написав перед циклом
#pragma omp parallel forЭто избавит меня от низкоуровневой возни с потоками. В общем всё не так плохо (опять же статья эта 2006 года, с тех пор много что поменялось в лучшую сторону).
вот если я хочу сложить две картинки, а другие две вычесть, а затем результат перемножить, то я просто делаю вот так:
Если я заменю картинки на обычные переменные, то LabVIEW тоже распараллелит?
Это хороший вопрос. И да и нет. "Да", потому что с точки зрения стороннего наблюдателя код будет выполняться как бы параллельно. "Нет", потому что код параллелится далеко не всегда. Технически LabVIEW разбивает код на "чанки", которые исполняет параллельно, но внутри одного чанка код исполняется последовательно и если он не связан потоками данных, то порядок выполнения неопределён. В случае тривиальных скалярных переменных накладные расходы на создание потоков столь велики, что выгоднее выполнить код последовательно.
Ну вот примеры:

Тут я сложил инкременты в один цикл, а не в два. Вроде бы результат по-прежнему неопределён, но на практике результат Numeric будет 2000, потому что тут один поток и инкременты работают последовательно. Но на самом деле модель потоков данных и тут работает, стоит лишь вставить структуру последовательности после инкремента. В последних версиях сделали malleable инструменты, на его основе сделали Synchronize Data Flow.vim, удобная штука:

Или вот:

Глядя на код, можно предположить, что Numeric будет 0 или 1 или 5 или 6. На самом деле будет всегда 6. Но стоит сложить этот код в диаграмму последовательности (технически вообще ничего не изменится) и станет 5. Будучи положенным в for цикл с одной итерацией - снова станет 6, а вот если в case структуру, то опять 5. Просто код перекомпилируется по-разному.
Таким образом возникает "обманчивая" детерминированность, при этом небольшие изменения кода могут изменять результат, либо приводить к неопределённому разультату, что в общем и произошло в статье, на которую Вы ссылаетесь.
Вы ожидаете от параллелизма абсолютной атомарной синхронности, то есть в данном случае одинаковый код в нескольких процессах должен исполняться пошагово синхронно - сначала все прочитают состояние счётчика, затем на следующем "шаге" все инкрементируют его в теневой памяти, затем запишут новое значение в результат, что даст в результате абсолютную детерминированный результат, и я верю, что примерно так и работает среда разработки, пара скриншотов из которой приведены в статье, но в других инструментах это работает чуть иначе.
Спасибо за подробный ответ. Приятно общаться по делу... Но есть пока один вопрос:
Тут я сложил инкременты в один цикл, а не в два. Вроде бы результат по-прежнему неопределён, но на практике результат Numeric будет 2000, потому что тут один поток и инкременты работают последовательно. Но на самом деле модель потоков данных и тут работает, стоит лишь вставить структуру последовательности после инкремента.
А какой результат получился, когда "вставили структуру"? Это очень интересно (мне - точно)
Если вставить структуру последовательности, вот так

то снова будет 1000. Эта структура служит "синхронизирующим барьером", выполняя роль рандеву - слева от неё чтение переменных может произойти в разные моменты, но исполнение продолжится только когда придут данные от обоих инкрементов, они будут одинаковы, которые записываются обратно в переменную, при этом новая итерация цикла начнётся только после записи, поэтому всегда будет ровно 1000. Synchronize Data Flow на скриншоте в предыдущем комменте делает ровно тоже самое, просто более компактно выглядит.
У меня в далёких планах на досуге посмотреть Active Oberon применительно к параллельности (я в прошлой жизни на Модуле-2 немного программировал) и вот ещё Раст интересен - там по идее потокобезопасность ещё на этапе компиляции должна отслеживаться, но я пока совсем новичок в этой области.
...то снова будет 1000.
Таким образом, моя версия ответа (в конце статьи) уже выглядит совсем правдоподобной :) Но чтобы в LabVEW повторить автоматное решение нужно, похоже, поставить барьер и на чтение.
С реальными процессами такой результат, конечно, не будет, т.к. временные характеристики у них будут разные. Ну, и еще должна работать соответствующим образом запись в переменную.
Но для меня автоматное решение все же точнее отражает картину абстрактных параллельных процессов: я создают один процесс, затем десять копий его и все - работаем. Барьеры в явном виде здесь не нужны, т.к. все это обеспечивает параллельная вычислительная модель. Т.е. решение получается более гибкое.
По поводу планов. Я прошел этап поисков и среди них многопоточности места нет. Точнее ее можно использовать, но только на уровне тяжелых (скажем так, массивных чанков :) слабосвязанных процессов...
"А не замахнуться нам на Вильяма нашего Шекспира", т.е. на создание RS-триггера на LabVIEW? Пройдет ли сейчас LabVIEW уже нынче такой тест на параллелизм? Можно ли LabVIEW параллельной средой? Или, по-другому, многопоточность - это совсем не необходимое условие для наличия параллельной вычислительной модели.
"А не замахнуться нам на Вильяма нашего Шекспира", т.е. на создание RS-триггера на LabVIEW? Пройдет ли сейчас LabVIEW уже нынче такой тест на параллелизм?
Сакральный смысл "RS-триггер теста" от меня честно говоря несколько ускользает, но тем не менее, классически "защёлки" реализуются в LabVIEW при помощи неинициализированных сдвиговых регистров. Вообще говоря модель потоков данных не позволяет мне завести выходы обратно на входы, но в простейшем случае это ограничение обходится вот так:

Если заменить сдвиговые регистры фидбек нодами, то всё будет совсем красиво, почти как в учебнике:

Но! Это абсолютно детерминированный код, он никогда не вывалится в метастабильное состояние (а насколько я понимаю, это и является критерием "правильности" реализации триггера, или нет?), поскольку здесь происходит неявная синхронизация, вызванная двумя проворотами цикла. Чтобы избавиться от навязанного детерминизма мне нужно ввести небольшие искусственные задержки обратного распространения сигналов. Самое простое решение - как-то вот так, что ли, одной спонтанной миллисекунды в таймауте мне вполне хватит:

Я тут стрелочками показал, как происходит перехлёст сигналов. Теоретически можно и одним циклом обойтись, просто его крутить надо больше и скорее всего будет больше обвеса и меньше элегантности. Вот теперь по крайней мере при переходе обоих входов в низкое состояние после высокого уровня мы будем спонтанно получать сигнал на одном из выходов, как-то так. Но по большому счёту если мы возьмём полный по Тьюрингу язык (каковым и LabVIEW является), то мы ведь можем реализовать вообще любую логику поведения триггера, включая симуляцию метастабильности (хотя с ней обычно стараются таки бороться), в зависимости от внешнего воздействия и предыдущего состояния как в однопоточном, так и в многопоточном окружении, разве нет?
Операции CAS в Питоне возможны?
Сакральный смысл "RS-триггер теста" от меня честно говоря несколько ускользает, ...
У меня есть, что сказать по этому поводу ;) Это статья в которой даже есть подзаголовок - Почему RS-триггер? А в статье расписана формальная модель и формальные операции в ее рамках для доказательства ее свойств... В рамках автоматной модели я могу умножая компоненты параллельных программ приводить их к последовательной форме. В LabVIEW? насколько я понимаю, подобного нет.
И зачем избавляться от детерминированности. К ней, наоборот, нужно стремиться.параллельные программы должны, даже, обязаны быть детерминированными.
Спасибо за модели. Чувствуется рука мастера ;) Но... Что значит "метастабильность" да еще "на одном входе". Хорошо бы иметь диаграммы, чтобы в этом разобраться однозначно. А еще лучше бы проверить работу триггера так: соединяем входы триггера. В эту общую точку подаем 1 для триггера на ИЛИ-НЕ. у Вас, похоже, именно такой. А затем, спустя какое-то время, этой же точке присваиваем 0. Смотрим, что получится на выходах триггера. Что должно быть известно (см. хотя бы упомянутые мои статьи), но вот будет ли это?
Но по большому счёту если мы возьмём полный по Тьюрингу язык (каковым и LabVIEW является), то мы ведь можем реализовать вообще любую логику поведения триггера, включая симуляцию метастабильности (хотя с ней обычно стараются таки бороться), в зависимости от внешнего воздействия и предыдущего состояния как в однопоточном, так и в многопоточном окружении, разве нет?
Можно все сделать. Только какие усилия на это надо потратить, чтобы получить нужный результат. В автоматном программировании все это реализует сама модель (в силу своего сакрального смысла). Ну как это обеспечивает калькулятор, например, умножая числа. В ВКПа фактически среда "умножает программы", чтобы получить верный результат. В многопоточной среде нужно 1) знать какой результат должен быть (в ВКПа не надо) 2) обеспечить получение нужного результата поставить где надо барьеры, семафоры, мьютексы и т.п. (в ВКПа, пожалуй, достаточно синхронизации, используя состояния).
По поводу Тьюринга. Эта машина чисто последовательная. LabVIEW без параллелизма ей должен соответствовать по определению. Но только Вы начинаете использовать потоки, то это соответствие может испариться. Особенно, если в программе, как я могу догадываться, появляется метастабильность.,
Вы промазали уровнем комментария, но давайте продолжим здесь. Я помню эти статьи, и там обсуждалась тема генерации, поэтому я и привёл пример с имитацией метастабильности. В реальности этого нет, конечно же.
Что касается диаграмм, то прежде чем я расчехлю генератор и осциллограф, я слегка модифицирую код. Дело в том, что мне не нужно два сдвиговых регистра, чтобы хранить один бит информации (я это сделал выше просто для наглядности), поэтому в реальной жизни будет как-то так (обычно и инвертированный Q не нужен, но пусть будет):

Второе изменение, которое я сделаю - это явная обработка "запрещённого" состояния, когда оба входа активны. Здесь я добавлю выход ошибки, а сигналы с обоих выходов буду просто убирать на время ошибки (они сами восстанавливятся обратно после возврата в нормальное состояние):

Вот теперь осциллограмма:

При первом "включении" сигнал Q неактивен, а инвертированный - установлен, это валидное состояние, почему бы и нет. Затем я устанавливаю вход S, - устанавливается Q, защёлкивается и держится и после снятия S. R снимает его обратно. При установке обоих R и S в активное состояние взводится выход ошибки и сигналы Q и ^Q снимаются (так обычно делают, хотя я могу их и оставить если надо). Что касается момента перехода из R=S=1 в R=S=0, то ни о какой метастабильности тут речи не идёт - триггер просто восстанавливает своё предыдущее состояние.
Что касается машины Тьюринга и параллелизма, то я считаю, что параллелизм не отменяет полноту по Тьюрингу, но это больше вопрос философский.
Вот что получается у меня. Но сначала схема триггера и описание ее работы из книги Фрике:
Схема триггера

Выдержки из нее:
Описание работы триггера по Фрике


В своей статье я доказываю это по другому, но в целом формальные результаты совпадают.
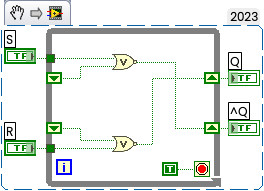
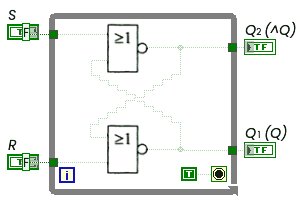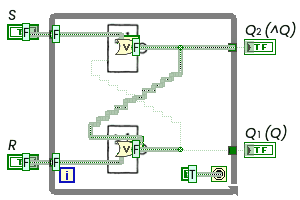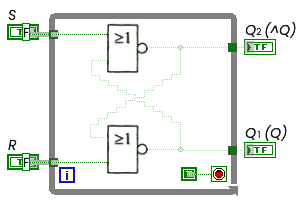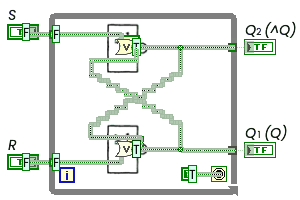
А вот что получилось реально в ВКПа
Триггер в ВКПа

Здесь два варианта. Верхний - триггер с нулевой задержкой элементов. Следующий - с задержками (у меня по 5 тактов дискретного времени на переходах в 0 и 1. Задержки транспортные. С задержками видно, что триггер при переключении проходит через запрещенное состояние выходов - 00 (см. также выше граф автомата Фрике). У Вас, похоже, переключение элементов проходит мгновенно.
Обратим внимание на "хвост" осциллограмм: триггер входит в режим генерации (см. также Фрике). Попыток "отсечь" ошибочную комбинацию на входах нет, как ее нет и в схеме триггера.
Да. До самой левой "отсекающей линии" - это установка триггера в такое же исходное состояние, как и у Вас.
А, теперь понял, ну конечно – я ж кручу цикл дважды, чтобы передать сигналы с выходов на входы, а эти осцилляции, они на каждый такт возникают, и я их благополучно подавляю. Я уберу логику для обработки "запрещённого" состояния (всё равно выходы свалятся в низкий уровень), и верну второй сдвиговый регистр, но сделаю только один проход:
И вот, теперь я вижу проход через запрещённое состояние (я ещё сдвину R и S на графике на полтакта влево для наглядности), а также вход в режим генерации и выход из него:

А если я буду делать три итерации (могу ещё сброс для первого старта добавить):

то фронты выходов сядут друг на друга, а всё остальное останется:

Вот теперь паззл сложился.
Код, которым генерировался график

Мог бы и сразу догадаться так сделать. Старею, наверное.
...Старею, наверное.
Да... Но от этого страховки нет :( Но в процессе, ведь, что-то и приобретается... Тот же опыт... Так что не все так печально ;) Но... продолжим.
Вы приблизились к идеалу. Тут, как говорится, мастерство не пропьешь. Но вопросы еще остались. Во-первых, все же хотелось видеть решение, которое структурно как "почти как в учебнике". А еще лучше чтобы просто "как в учебнике". Что-то похожее было возникло (см. выше), но потом ушло... Из последней схемы, как я понял, есть "обвес", который и реализует обратные связи. И все было бы хорошо, если бы его можно было спрятать и рисовать схемы "как в учебнике",
В ВКПа тоже есть "обвес" - это ее ядро, но при этом схемы, как учебнике. Последнее то, к чему надо стремиться, реализуя модель параллельных вычислений. Семафоры, мьютексы и т.п. - "многопоточный обвес", который присутствует в программах в явном виде. При этом, что совсем "фигово", он не формирует вычислительную модель, как те же автоматы в ВКПа. Все это "наколеночные механизмы" :) Стоит, например, в готовое решение добавить еще одну параллельную компоненту и все сыпется...
Например. Выше мы создали триггер и казалось бы добились идеала. А что будет если в решение ввести еще один элемент ИЛИ-НЕ, входы которого подключить к выходам триггера. Что в этом случае будет на его выходе при той же диаграмме процессов? Попробуем? :) Так проверяется "обвес". Его универсальность. В ВКПа сетевая автоматная модель универсальна, теневая память тоже. Да, приходится использовать другую форму алгоритма - автоматную, переменные, которые используются и во внешней среде, помещать в теневую память. Но все это достаточно просто. А автоматная форма - так совсем хорошо.
Давайте проверим Ваш "обвес", добавив в решение еще один процесс (см. выше про еще один элемент ИЛИ-НЕ). Мне бы хотелось на это посмотреть (хотелось бы, чтобы это было интересно и Вам). Во-первых, можно увидеть насколько это просто, во-вторых, будет ли при этом желаемый результат. А каким он должен быть известно. По крайней мере, - мне :)
Ну я конечно могу снова переключиться на feedback node, задвинуть их под ИЛИ-НЕ примитивы, а сверху набросить оригинальные иконки, не поленюсь даже натыкать диагональные проводочки:

Уж и не знаю — куда аутентичнее. Но я очень редко так делаю, поскольку, если скажем включить подсветку исполнения кода, то вот так сходу будет неясно, откуда возникают осцилляции:
Не говоря уже о том, что код этот способен вынести мозг любому LabVIEW программисту.
Куда понятнее вот так:

Что касается элемента ИЛИ-НЕ, подключённого к выходам триггера — то тут я совсем не понял — этот элемент будет честно отрабатывать логику в соответствии с таблицей истинности:

Для наглядности я возьму триггер, показывающий проход через запрещённое состояние - в этот момент на графике будут короткие всплески:

Что касается параллельности, то триггер этот — потокобезопасный (просто за счёт того, что реентерантный), я могу вызывать его из многих асинхронных потоков и он будет корректно работать безо всяких дополнительных семафоров, притом абсолютно параллельно, не блокируясь.
Да... Чувствуется рука мастера (в LabVIEW) :) Лично у меня была несколько иная реализация триггера ;) Правда, может, и таких возможностей в той версии не было (было это лет 10-15-ть назад). По крайней мере, до элемента (см. рис. ниже) дело не дошло. А, кстати, немного поясните, что это за элемент и что будет, если его исключить? Все же у реального триггера подобной "обвески" нет....
С ним Ваша реализация напоминает универсальную схему реализации автоматов. Это когда автомат представляется в виде двух блоков - комбинационной схемы и памяти. Похоже, эта "обвеска" и выполняет роль памяти. При этом, как правило, нужен еще тактовый генератор их синхронизирующий и, наверное, он "спрятан" внутри LabView.
Так это или примерно так?

Что касается элемента ИЛИ-НЕ, подключённого к выходам триггера — то тут я совсем не понял — этот элемент будет честно отрабатывать логику в соответствии с таблицей истинности
В данном случае ее роль - индикация запрещенных состояний триггера (стандартный прием в асинхронной схемотехнике). У Вас он, вроде, с этим справляется.
Вопрос: от чего зависит длительность его импульса? Понятно, что от времени переключения триггера. И тогда уточняющий вопрос - чем определяется время переключения триггера?
Не, этот элемент (Build Array) к триггеру не имеет отношения, он просто собирает пять битов (два входных, два выходных и ИЛИ-НЕ) в массив, который потом конвертируется для отображения на цифровом графике. Если его убрать, то триггер работать не перестанет, просто мы графика лишимся.
Длительность импульса - просто один такт. Тут крутится for цикл, никакого другого тактового генератора здесь нет. Мне проще на Си показать, вот практически полностью эквивалентный код (длины массивов я захардкодил, мы ж не в продакшене):
#include <ansi_c.h>
#include <stdbool.h>
BOOL RS_Trigg (BOOL S, BOOL R, BOOL *Q, BOOL *_Q)
{
static BOOL q = false;
static BOOL _q = true;
BOOL s = !(q || S);
BOOL r = !(_q || R);
*_Q = _q = s;
*Q = q = r;
return !(q || _q);
}
void main (int argc, char *argv[])
{
int s[12] = {0,1,0,0,0,1,0,0,0,0,0,0};
int r[12] = {0,0,0,1,0,1,0,0,0,0,1,0};
BOOL S[72], R[72], Q[72], OrNot[72], notQ[72];
for (int i = 0; i < 12; i++){
for(int j = 0; j < 6; j++){
S[i * 6 + j] = (BOOL)s[i];
R[i * 6 + j] = (BOOL)r[i];
}
}
for (int i = 0; i < 72; i++) OrNot[i] = RS_Trigg(S[i], R[i], &Q[i], ¬Q[i]);
printf("\n S:"); for (int i = 0; i < 72; i++) printf("%d", S[i]);
printf("\n R:"); for (int i = 0; i < 72; i++) printf("%d", R[i]);
printf("\n Q:"); for (int i = 0; i < 72; i++) printf("%d", Q[i]);
printf("\n NotQ:"); for (int i = 0; i < 72; i++) printf("%d", notQ[i]);
printf("\n OrNot:"); for (int i = 0; i < 72; i++) printf("%d", OrNot[i]);
}Ну а результат:
S:000000111111000000000000000000111111000000000000000000000000000000000000
R:000000000000000000111111000000111111000000000000000000000000111111000000
Q:000000011111111111000000000000000000101010101010101010101010000000000000
NotQ:111111000000000000011111111111000000101010101010101010101010111111111111
OrNot:000000100000000000100000000000111111010101010101010101010101000000000000Это ровно то, что на графике выше изображено.
Вообще LabVIEW нынче бесплатна для некоммерческого использования в виде Community Edition, а по всем вопросам можно на форум LabVIEW Portal обращаться - там очень доброжелательные ребята и всем охотно помогают, я тоже там бываю.
Отдельное спасибо за код! ;) Он помог заметить то, что я не заметил, даже зная, что это должно быть (комментарий к самому коду я, надеюсь, напишу еще отдельно). Речь об импульсе, который выдает элемент - индикатор запрещенного состояния. Диаграмма-то должна быть такая (импульс сдвинут на такт вправо):

В ВКПа, чтобы получить такую же диаграмму (см. график OR-NOT), как у Вас выше, надо еще постараться ;) Или, по-другому: параллельная модель, как хороший калькулятор, должна всегда выдавать правильный результат. ;).
Если по какой-либо причине требуется задержка на один такт, то это элементарная модификация, что в Си, что в LabVIEW. Вообще правильный результат можно где угодно получить, это больше вопрос усилий, затраченных для его получения, ну и постановки задачи, естественно.
У меня возникает затык со временем, так что я больше не буду так активен, но хочу поблагодарить за приятное и конструктивное общение, спасибо!
...но хочу поблагодарить за приятное и конструктивное общение, спасибо!
И Вам... большое спасибо!
Добавлю еще немного блочного state-конструктива :) Это пример того, как, имея только один блок - типа ИЛИ-НЕ, можно создать уже любую схему - RS-триггер и т.п.
state-технология для С/С++
#include <QCoreApplication>
#include <stdbool.h>
static int aState[3] = {0,0,0};
static int aTmpState[3] = {0,0,0};
void OR_Not (int nState[], int nTmpState[], bool x1, bool x2)
{
if (*nState==0 && !x1&&!x2) { *nTmpState = 1; }
else if (*nState==1 && x1) { *nTmpState = 0; }
else if (*nState==1 && x2) { *nTmpState = 0; }
}
void CopyState () { for (int i=0; i<3; i++) { aState[i] = aTmpState[i]; } }
void RS_Trigg (bool S, bool R)
{
OR_Not (&aState[0], &aTmpState[0], S, aState[1]);
OR_Not (&aState[1], &aTmpState[1], aState[0], R);
}
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
int s[14] = {1,0, 0,1,0,0,0,1,0,0,0,0,0,0};
int r[14] = {1,1, 0,0,0,1,0,1,0,0,0,0,1,0};
bool S[70], R[70], Q[70], OrNot[70], notQ[70];
for (int i = 0; i < 14; i++){
for(int j = 0; j < 5; j++){
S[i * 5 + j] = (bool)s[i];
R[i * 5 + j] = (bool)r[i];
}
}
for (int i = 0; i < 14; i++){
for(int j = 0; j < 5; j++){
Q[i * 5 + j] = 0;
OrNot[i * 5 + j] = 0;
notQ[i * 5 + j] = 0;
}
}
for (int i = 0; i < 70; i++) {
RS_Trigg(S[i], R[i]);
OR_Not (&aState[2], &aTmpState[2], aState[0], aState[1]);
Q[i] = aState[1];
notQ[i] = aState[0];
OrNot[i] = aState[2];
CopyState();
}
printf("\n S:"); for (int i = 0; i < 70; i++) printf("%d", S[i]);
printf("\n R:"); for (int i = 0; i < 70; i++) printf("%d", R[i]);
printf("\n Q:"); for (int i = 0; i < 70; i++) printf("%d", Q[i]);
printf("\n NotQ:"); for (int i = 0; i < 70; i++) printf("%d", notQ[i]);
printf("\n OrNot:"); for (int i = 0; i < 70; i++) printf("%d", OrNot[i]);
printf("\n");
return a.exec();
}
В рамках такого подхода без каких-либо усилий мы получим строго правильный результат. Наоборот, чтобы получить неправильный, нужно потратить массу усилий.
Соответственно смотрим на результат работы
Результаты работы

Понятно, спасибо. Теоретически, пользуясь конечными автоматами можно создать любую схему, это так.
Кстати, мне несколько лет назад понадобился конечный автомат на чистом Си, и я, помнится, позаимствовал пару идей вот здесь:
ну или если на плюсплюсах:
Код получается гибким и расширяемым, его логику легко понять, даже в случае сложного автомата.
...Теоретически, пользуясь конечными автоматами можно создать любую схему, это так.
Насчет любой. Тут надо быть осторожным и уточнять - какая теория, какие автоматы... Порой далеко не все, да могут быть большие проблемы и сложности. Особенно, если смотреть на классические автоматы и их теорию.
А вот за ссылки отдельное и большое спасибо. Однако... вчера прочитал "по диагонали" и возникли вопросы. С утра решил вникнуть в содержимое и ... не смог :) Ну, у меня совсем другое представление об автоматах. Из-за этого, честно, просто нет сил вникать, т.к. думаешь, - ну, и надо мне это?
А вот в чем отличие я попробую показать на примере модели того же двигателя. На том же С++, но только в ВКПа. Но чуть позжее... как только сделаю ;)
После прочтения этой статьи понял анекдот про программистов))
Летят Холмс с Ватсоном на воздушном шаре. И спят в полете. Просыпаются
над какой-то незнакомой землей, видят - внизу какой-то хрен коров пасет.
Снизились они и спрашивают мужика:
- Скажите, сэр, где мы находимся?
- На воздушном шаре.
- Спасибо, сэр! - и летят вверх. Холмс задумчиво говорит:
- Интересная местность, Ватсон! Программист пасет коров!
- Холмс, а с чего вы взяли, что он программист?
- Это элементарно! Во-первых, он долго думал над ответом. Во-вторых, его
ответ был абсолютно точен. И в третьих - абсолютно бесполезен!
Спасибо, что прочитали статью, но ...
Думаю, что программист ответил бы - в корзине воздушного шара. Поэтому или Холмс плохо разбирается программистах, или ... не исключен вариант, когда Холмс и Ватсон непосредственно как-то "прилепились" к поверхности воздушного шара. Но все же это как-то маловероятно... Поэтому на мой взгляд это был обычный пастух, но с определенным чувством юмора. А вот у Холмса и Ватсона, похоже, с этим - юмором проблема ;)
Ну, а теперь к вопросам о полезности и точности...
Вы, надеюсь, програмист и, возможно, понимаете суть проблемы, которой посвящена исходная (см.[1]) статья и моя. Мой вопрос Вам - каким должно быть значение счетчика, который ОДНОВРЕМЕННО изменяют множество АБСОЛЮТНО ОДИНАКОВЫХ и ОДНОВРЕМЕННО запущенных ПАРАЛЛЕЛЬНЫХ процессов?
имеющий для меня пользу и практическую ценность ответ был в 1й статье "Результат зависит от версии Python на которой был запущен скрипт".
Остальное - для увлекающихся теоретиков.
ps: да, в оригинальной версии анекдота как раз было "в корзине воздушного шара в 20 метрах над землей". Абсолютно точный ответ))
Семен Семеныч?! Ну так это ж совсем другое дело :)))
Остальное - для...
... программистов, которые понимают разницу между просто программой "имеющей практическую ценность" и программой, выдающей точный и предсказуемый результат. И отличие между этими программами, как отличие в сути оригинальной версии анекдота от версии в Вашем изложении.
Я, думаю, именно "практические программисты" написали программу для прилунения последнего (крайнего) нашего спутника, который врезался лихо в поверхность луны. Ну или, что более вероятно, руководили ими "практические экономисты", которые совсем уж далеки даже от "практического программирования", не говоря уж о нормальном программировании, у которого есть своя теория, которую нельзя нарушать. Иначе "врежешься", что и произошло на деле...
И так будет с каждым практиком, кто не уважает теорию.
А на мой вопрос у Вас точного ответа нет. Т.е. ситауция, как в том анекдоте про грузинского мальчика на уроке математики... :)
Параллелизм без потоков: очевидно и вероятно