Comments 553
А как в сравнении с Haskell?
Отлично, на самом деле. В Haskell что ни говори, тяжело писать большие приложения. Rust берёт же от хаскеля много хорошего, и при этом даёт уверенность, что у тебя не утекают от лени thunk-и, что скомпилированный код скорее всего отлично работает, что твои попытки оптимизации работают (привет, мемоизация и прочая хаскелевская муть). Rust - это быстрый Haskell с императивностью и мутабельностью в нужных местах и по делу.
Ну нет, в Расте нет типов высшего порядка
Да, конечно, раст проще. Но он отличный компромисс для эффективного программирования производительного кода с относительно высокими гарантиями безопасности.
а трэйты разве не типы высшего порядка? ну или их аналог? Также как в плюсах концепты или сфинае
расскажите подробнее или скиньте что-нибудь почитать о них в хаскель, пожалуйста
нашел только о функциях высшего порядка
Типом высшего порядка является даже обычный дженерик. Или даже ссылка (не ссылка на конкретный тип, а ссылка вообще),
Однако, когда говорят о наличии или отсутствии типов высшего порядка в языке, подразумевается не наличие или отсутствие единичных представителей, а возможность выразить произвольный тип. Вот такой возможности как раз и нет.
Очень близко к HKT подобрались ассоциированные типы в трейтах, возможно даже они и есть HKT.
К слову, в плюсах типы высшего порядка выражаются концептами и не SFINAE, а банальными typedef в шаблонах.
Я под типами высшего порядка понимаю "классы типов".
Т.е. концепт в плюсах описывает какой-то класс типов, которые ему удовлетворяют. Аналогично с трейтами в раст.
Вы наверно имеете ввиду, что ТВП, по аналогии с ФВП, являются данными?
У типов высшего порядка есть определение, ТВП - это тип рода * -> * и выше. Иными словами, это функция, аргументом и значением которой являются типы.
Например, std::vector - это ТВП, он сопоставляет любому типу-параметру T тип-значение std::vector<T>. Обратным к нему будет ТВП, который сопоставляет любому типу-параметру T тип-значение T::value_type.
Это не на Haskell тяжело писать большие приложения. На Haskell их легко писать за счет того, что язык очень сильно помогает в рефакторинге кода.
Хаскель отлично помогает своей системой типов, само собой. Но он слишком сложный для большинства программистов. Память из-за ленивости бывает сложно понять куда уходит и что с этим делать. В половине библиотек изобретают операторы, которые делают код компактнее, но приходится учить все эти закорючки, чтобы даже просто читать код.
это да. я не настоящий функциональщик, но иногда посматриваю в ту сторону. Вот на страничке Control.Lens.Operators перечисляются эти операторы:
123 оператора. Это точно надо их столько, чтобы программировать? Вот и я задаюсь этим риторическим вопросом.
Hidden text
(#%%=)
(#%%~)
(#%=)
(#%~)
(#)
(#=)
(#~)
(%%=)
(%%@=)
(%%@~)
(%%~)
(%=)
(%@=)
(%@~)
(%~)
(&&=)
(&&~)
(&)
(&~)
(=) (~)
(=) (~)
(+=)
(+~)
(-=)
(-~)
(...)
(.=)
(.>)
(.@=)
(.@~)
(.~)
(//=)
(//~)
(<#%=)
(<#%~)
(<#=)
(<#~)
(<%=)
(<%@=)
(<%@~)
(<%~)
(<&&=)
(<&&~)
(<&>)
(<=) (<~)
(<=) (<~)
(<+=)
(<+~)
(<-=)
(<-~)
(<.)
(<.=)
(<.>)
(<.~)
(<//=)
(<//~)
(<<%=)
(<<%@=)
(<<%@~)
(<<%~)
(<<&&=)
(<<&&~)
(<<=) (<<~)
(<<=) (<<~)
(<<+=)
(<<+~)
(<<-=)
(<<-~)
(<<.=)
(<<.~)
(<<//=)
(<<//~)
(<<<>=)
(<<<>~)
(<<>=)
(<<>~)
(<<?=)
(<<?~)
(<<^=)
(<<^^=)
(<<^^~)
(<<^~)
(<<||=)
(<<||~)
(<<~)
(<>)
(<>=)
(<>~)
(<?=)
(<?~)
(<^=)
(<^^=)
(<^^~)
(<^~)
(<|)
(<||=)
(<||~)
(<~)
(?=)
(??)
(?~)
(^#)
(^.)
(^..)
(^=)
(^?!)
(^?)
(^@.)
(^@..)
(^@?!)
(^@?)
(^^=)
(^^~)
(^~)
(|>)
(||=)
(||~)
Очень не рекомендую использовать лизны, да и вообще любую оптику в Хаскеле. Там проблема не только в куче странных значков, там ещё и смысл у них у всех зело мудрёный. Да и без них можно рпекрасно обходится (проблема в том, что иногда приходится читать чужой код с линзами и это боль).
Проверено, даже те люди которые сами писали с помощью этих лизн, призм и т.п. уже через пол года сами не могут прочесть и понять собственный код и что там понаписано. С линзами так - пока ты ими ежедневно пользуешься всё супер, стоит сделать небольшой перерыв и они забываются.
У других хаскельных библиотек такой фигни нет. Линзы это что-то действительно мудрёное и быстро забывается. По сути это отдельный язык в языке, со своей уникальной логикой и какими то своими парадигмами. Его отдельно изучают и по нему-же самостоятельные книги пишут.

И вот пример могучей силы оптики из этой книги:
-- Flip the 2nd bit of each number to a 0
>>> [1, 2, 3, 4] & traversed . bitAt 1 %~ not
[3,0,1,6]Круто конечно, как ловко и кратко но какой ценой! Это же надо реально изучить, врубиться и постоянно освежать эти знания.
А чтобы удобно работать с многократно вложенными друг в друга структурами данных, вместо линз лучше использовать record dot preprocessor.
В планах на изучить Haskell есть (может еще F#), но скорее для того, чтобы посмотреть ~~есть ли жизнь на марсе~~ как живется в полностью функциональном языке без доступа к мутабельности, может быть позаимствовать какие-нибудь подходы.
И там и там 2 вакансии, так что равны +-
Кстати нет. Не так давно видел вакансии на Rust в Сбере, МТС и Тиньке помимо мелких компаний и стартапов. Ну и зарубежных удаленных еще больше. И поскольку язык молодой требований из серии 5-10+ лет опыта на нем нет.
На Rust вакансий все же раз в 20 больше, чем на Haskell. С другой стороны количество Rust-истов гораздо больше Haskell-истов.
UB это на самом деле так страшно или, к примеру, в Arduino с ним никогда и не столкнёшься?
UB это страшно. В том числе и потому, что оно может быть в коде, но вы с ним не "столкнетесь" до тех пор пока не обновите компилятор или его опции, не поменяете что-то в другой части кода или просто не сложатся звёзды на небе случайным образом. От платформы это слабо зависит.
и оно может быть в коде компилятора, поэтому два откомпилированных бинарника с одного и того же кода могут быть разными. Но и в расте до... UB. Не говоря уже о уязвимостостях заложенных в генерацию кода, особенно с borrow. Забавно что на расте в отличии от плюсов гораздо легче сымитировать ошибки с обновлением кэша.
UB - это не обязательно только про обращение к неинициализированному или некорректному участку памяти. UB - это, например, переполнение знаковой интовой переменной. Да, вы можете предположить, что есть у вас signed integer и вы прибавляете к нему +1, то компилятор просто сгенерирует процессорную инструкцию инкремента или сложения, и зная как представлены числа на архитектуре предположить, что если у вас есть значение в переменной INT_MAX, вы к ней прибавите +1, то получите INT_MIN. А потом вы где-нибудь напишете if (X+n)>X, чтобы проверять не вызовет ли операция переполнение. И оно даже скорее всего так будет работать на протяжении многих лет. Но проблема в том, что стандарт языка не даёт таких гарантий! Вообще не даёт. Более того, согласно стандарту языка, такой код вообще не является корректным кодом. И если компилятор обнаружит а коде что-то подобное, то он имеет полное право в таком случае сгенерировать вообще все что угодно - вплоть до того, что этот if будет выдавать и true и false в разных частях кода для одинаковых значений X и N (пример там есть по ссылке), компилятор также что выкинуть какой-то находящийся рядом код или сгенерировать инструкции которые делают вообще не то что вы подразумевали. И то, что он не делает это сейчас, совершенно не гарантирует, что это не произойдет когда-нибудь в будущем (стоит вам обновить компилятор, изменить опции компиляции или даже поменять что-то в коде по соседству). А если у вас будет что-то типа такого в условии цикла, то бесконечный цикл может перестать быть бесконечным, или наоборот (см. пример).
И это только один из сотен примеров. UB - это не только про память и многопоточность, увы.
Довольно подробные объяснения с примерами можно найти тут:
Неопределенное поведение и правда не определено
Неопределенное поведение может привести к путешествиям во времени
То что вы пишете, скорее всего имеет место быть в языке вообще, но в конкретном применении конкретной платформе это может быть не так.
Нет, нет и ещё раз нет. UB не зависит от платформы или применения. Вообще не зависит - UB в коде либо есть, либо его нет, вне зависимости от платформы.
Случаи undefined behavior описаны в стандарте языка, их там несколько сотен. Код, в котором есть UB по определению не является корректным кодом на языке C или C++. Более того, в случае наличия UB в коде компилятор имеет полное право сгенерировать любую хрень из вашего кода, и это вообще не зависит от аппаратной платформы и ее ограничений.
Вы, кажется, не совсем верно понимаете, что такое UB. UB это не "я обращаюсь к неинициализированной переменной в куче, но на моей платформе память изначально заполнена нулями, значит в ней будет ноль". UB - это то, про что в стандарте языка явно сказано "так делать нельзя", и если компилятор увидит такое в коде, он, например, может вообще выкинуть условие if (a == 0) и все что внутри него. Имеет полное право. Если на вашей платформе инкремент знакового двухбайтового инта 32767 сделает его равным -32768 (на большинстве платформ так), то увидев if ((x+1)>x) в коде компилятор может выкинуть эту проверку и заменить везде на true, потому что согласно стандарту языка переполнение знаковых недопустимо. И так далее. Наличие или отсутствие UB в исходном коде не зависит от платформы, под которую вы компилируетесь.
Ну и полагаться на "у меня в коде UB, но для моей платформы компилятор генерит правильный машинный код" очень опасно. Сегодня генерит, а завтра что-то изменится, и уже не будет. Потому что имеет полное право.
Да, но нет. Делалось-то для переносимости, но это совершенно не означает, что на конкретной платформе все UB оказались до-определены.
Компиляторы с удовольствием пользуются некоторыми видами UB для оптимизации кода; в таком случае поведение остаётся неопределённым даже если зафиксировать платформу и версию компилятора.
По-моему в C изначально UB именно для этого и было и означало скорее implementation defined поведение. Т.е. язык как бы не при делах, но в конкретных условиях все ок. В те времена C еще можно было считать человекочитаемым ассемблером.
Сейчас же UB предназначено целиком и полностью для оптимизации, чтобы у компилятора была свобода ломать код так, как ему вздумается. Платформа здесь не имеет значения, потому что компилятор не смотрит на то, что в какой-то системе two's complement представление чисел. Для него UB это UB на любой платформе. Собственно, для него вообще платформы конечной не существует - он работает с абстрактной машиной. Поэтому как выше писали, проверка на переполнение будет просто удалена компилятором. Поэтому и версия компилятора может запросто сломать то, что работало раньше, если оно опиралось на UB.
оставляя конкретное поведение на совести компилятора.
Неа. То, что вы сказали - это не undefined behavior, а unspecified behavior, в стандарте оно тоже есть.
если конкретная платформа убирает UB из своего компилятора
Почти, обычно UB "убирает" не конкретная платформа, а конкретный компилятор. Например GCC и Clang делают исключение (точнее, расширение языка) для упомянутых выше union, разрешая в них puning простых типов. Но пользоваться таким можно только если разработчиками компилятора явно явно сказано "в стандарте C++ это UB, но мы реализуем нестандартное расширение языка, в котором это не UB". Если такого не сказано, то писать код таким образом под этот компилятор нельзя.
просто этот исходник не скомпилируется другим компилятором под другую платформу
Скорее всего скомпилируется, нередко даже без варнингов. Но никаких гарантий, что он всегда будет работать правильно уже не будет.
В этом и опасность UB - вы можете даже не подозревать, что оно есть у вас в коде до определенного момента.
Если же, как вы говорите, поменяется что-то в компиляторе, то скорее всего либо разработчики компилятора будут опираться на предшествующее отсутствие UB
Это только в том случае, если разработчики специально "определили" это конкретное UB и больше не считают его UB в своей реализации. А если в прошлой версии это UB было именно UB, то в новой версии тоже возможно все что угодно. То, что работало, может перестать работать. А может наоборот начать работать то, что раньше не работало :) на то оно и undefined
стоит проверить приведённую вами конструкцию UB в конкретной среде
Это ни о чем не скажет. Оно может отлично работать в вашей конкретной среде. До тех пор, пока вы не поменяете что-то в опциях компилятора, не обновите компилятор до более новой версии, или даже не поменяете что-то в какой-то другой части исходника.
Но пользоваться таким можно только если разработчиками компилятора явно явно сказано "в стандарте C++ это UB, но мы реализуем нестандартное расширение языка, в котором это не UB".
Это плохой пример из-за нелепости ситуации вокруг type punning'а через union. Комитет решил сломать совместимость* с C в этом месте, а разработчики (возможно, всех существующих) компиляторов - нет.
Если стандарт игнорирует реальность, тем хуже для стандарта, а не для реальности. Тут нужен ещё один пример.
Он также игнорирует реальность, когда требует поддержку исключений и RTTI во freestanding-реализациях (так на языке стандарта называется bare metal). Комитет почему-то изначально (в C++98) послал таким образом много платформ и там до сих есть люди, голосующие за сохранение ситуации**. @Tuvok спросил про Arduino, а самое первое, что можно сказать об avr-g++ и стандартности: стандарт игнорирует существование этой платформы (потому что не хочет учитывать существование -fno-exceptions).
Так проявляются некие трения насчёт совместимости с C и насчёт поддержки bare metal в комитете и в представлениях Страуструпа***. Можно с ними не согласиться, как и с мнением Страуструпа о C или C++ на 8-битных микроконтроллерах: "Probably best stick to assembler".
В общем, на это могут смотреть не как на явное расширение компилятора, а как на "вы не рискнёте по дурости комитета сломать весь софт, пользующийся этим приёмом: x265, Firefox, Qt, OpenCV, ClickHouse, Boost... (точно так же, как не добавите в компилятор для bare metal неотключаемые исключения ради соблюдения стандарта - это же глупо)".
* в стандарте C поведение описано на этой странице (ctrl+F: type punning), в стандарте C++ это уже UB.
** голоса 1 Against, 2 Strongly Against в голосовании "We support proposed removal..."
*** Страуструп 2002: "Remove all incompatibilities: This is my ideal", Страуструп 2024: "Unfortunately, unions are commonly used for type punning".
Для того, что вы описываете, в стандарте есть отдельное понятие - unspecified behaviour (да, тоже UB, но обычно когда пишут UB, подразумевают undefined behaviour). Наличие в коде unspecified behaviour означает потенциальные проблемы с переносимостью, но просто от обновления компилятора или изменения никак не связанного участка кода ничего не сломается.
А undefined behaviour это именно "программа, допускающая такое поведение, некорректна". Я слышал, что изначально при стандартизации комитет просто не захотел принимать никаких решений о том, какое поведение должно быть в этих ситуациях, а потом компиляторы научились делать крутые агрессивные оптимизации, исходя из того, что UB не может происходить, и в результате наличие в стандарте UB стало принципиальной позицией.
интересно, а есть ли у кого-нибудь примеры, когда UB реально делало что-то ужасное..
А то всегда определяют UB собственно по его название - неопределенное, а примеров отформатированного диска не слышал никогда.
Ужас уб обычно описывают со сложностью его поиска и непредсказуемости появления
Ну, например, вот: Как может вызваться никогда не вызываемая функция?
Почитал статью и так и не понял чем раст лучше, наверно это неплохой язык, но что мешает использовать пул потоков в с++, почему автор статьи считает что многопоточное программирование на с++ это потоки и мьютексы?
Мое понимание разработки на данный момент сводится к тому что можно очень долго выяснять какой язык лучше и чем на, скажем так, академических примерах, беда в том что это сильно далеко от реальной жизни. Мне не нужен язык, мне нужно программу делать, а для этого нужны библиотеки, очень много библиотек, на данный момент в составе vcpkg около 2,5 тысяч библиотек. Это код который у вас сразу и скорее всего без проблем соберется под все распространённые настольные и мобильные платформы. Не представляю что должно случиться что бы библиотека CGAL была переписана на другой язык. В нее закопаны наверно сотни человеколет работы. И это только одна библиотека из множества других. И такие библиотеки можно перечислять очень долго: SQLite, Qt, curl, boost graph, openimageio, eigen3, lua, imgui... У меня в глазах ужас при мысли как каждую из них можно было бы портировать на другой язык, не говоря уже о всех вместе.
В последнее время пишу в основном фронтенд на js. В реестре npmjs.org более 2 миллионов пакетов. Тем не менее пишу сложные веб приложения используя только 2-3 из них (кроме фреймворка), да и от тех при желании можно избавиться. Те, кто использует много библиотек через пару лет, имеет огромные проблемы с апгрейдом и поддержкой приложения
В С++ не так?
Плюс минус так же, много библиотек в проект не затянуть. Автор комментария скорее ведёт к тому что Раст просто беден на качественные библиотеки что смогли бы закрыть потребности программистов, как с этим сейчас успешно справляются плюсы
Кстати, раз уж про поддержку зависимостей заговорили. В Rust есть потрясающая возможность иметь одну библиотеку нескольких разных версий без конфликтов (если не надо между разными версиями взаимодействовать). Так что если ваша зависимость A имеет подзависимость C версии 1.0.0, а в зависимости B подзависимость C версии 2.0.0, то они спокойно продолжат работать. Можно даже импортировать свою собственную библиотеку другой версии (это используется, например, чтобы пофиксить баг только в самой новой версии, а в старых просто импортировать из новой и не поддерживать несколько версий фиксов).
Звучит, так, как будто это отличная фича, чтоб выстрелить себе в ногу.
Нет, на самом деле это офигенно и позволяет продолжать писать код, даже если прямая зависимость А уже обновилась чтобы использовать косвенную зависимость С версии 2.0, а зависимость B ещё на 1.0.
В плюсах это, я думаю, сразу ставит крест на такой комбинации - форкайте B и переписывайте на 2.0 или откатывайте А на старую версию.
Насколько я знаю, есть одну неожиданную проблему, которую это может вызвать - если все же библиотеки A и B обмениваются типами из C, то можно получить ошибку expected struct C::InnerType, found a different struct C::InnerType; note: perhaps two different versions of crate C are being used? В остальном, насколько я знаю, проблем это не вызывает.
Много раз сталкивался с такой проблемой в других языках.
Например библиотека А имеет зависиость на B 1.0, а C ссылается на B 2.0. Всегда было больно, из всех моих случаев поддержка разных версий зависимости решило бы проблему(в часте случаев так и фиксилось - пинилась старая версия какими-то костылями)
Проблема есть, я ж не отрицаю.
Но не будет ли больно искать багу, когда окажется что в каких-нибудь тестах и в разных местах программы, с виду, одинаковый код, который, совсем неочевидно, будет работать по разному ?
Можно конечно будет сказать — это %somecoder% во всё виноват, а не инструмент, но время будет потеряно.
Нет, не так, с++ очень стабилен в поддержке и всегда имеет обратную совместимость(был один или два случая когда это правило нарушилось). Наверно есть библиотеки которые могут перестать работать, но таких случаев не помню. Многие с++ библиотеки слишком большие что бы быть заброшенными. Например curl это часть операционной системы линукс и с некоторых пор виндовс. Qt развивается с 93 года или что-то около того. Многие библиотеки с++ это матрешки, которые зависят от более мелких библиотек, а те еще от более мелких. К примеру openimageio зависит от 98 других библиотек. Так же в с++ очень мало зоопарка библиотек, никто не будет писать аналог zlib(библиотека сжатия данных).
Бегло посмотрел репозиторий что вы дали, нашел интересную штуку JoltPhysics.js( A WebAssembly port of JoltPhysics) это то о чем говорил, с++ проникает условно в мир других языков через порты и обертки под эти языки, уверен есть порт для питона и других языков, но внутри там будет с++ библиотека.
Еще почему-то в подобных разговорах принято считать что программисты с++ думаю только о нем и ничего вокруг не видят, в "мире с++" вполне нормальная практика брать и вкручивать в приложение другие языки, почти все игровые движки созданные на с++ имеют внутри себя интерпретаторы(или jit компиляторы) других языков для упрощения написания логики, как правило это lua или python, Unreal Engine внутри содержит графический язык BluePrint. Qt сейчас переходит на QML это использование с++ для базовых функции и склеивание их через js.
Так же нет проблемы двигаться вниз по языковым абстракциям и спускаться до ассемблера, если есть желание использовать какие-то низкоуровневые процессорные расширения типа AVX, почти все видео кодеки туда спускаются, но это порождает определенные трудности в переносимости под другие типы архитектур.
Мой пойнт был в том, что важных библиотек (типа графических или curl), которые используются в проекте - их очень немного. И они довольно оперативно и качественно портятся на другие языки/фреймворки когда надо. А "мелочь" можно реализовать самому.
Опять же - так в мире js и npmjs
То есть утверждение, что уже написано куча либ под что-то и что нам делать и будет куча проблем при переходе на Rust - необосновано
Почитал статью и так и не понял чем раст лучше, ..., но что мешает использовать пул потоков в с++
Видимо у меня не получилось расставить акценты в нужных местах. Преимущество Rust не в том, что есть библиотека, в которой пул потоков есть (и даже не в идиоматичном варианте, когда для того, чтобы сделать код многопоточным надо добавить .par_bridge().into_par_iter() и все), а в том, что компилятор гарантирует отсутствие гонок данных. Этот пример важен не самим кодом, а текстом после, т.е. пока я писал этот пример я сделал много разных ошибок, которые бы не помешали скомпилироваться C и/или C++ коду, но помешали скомпилироваться коду на Rust. Сила Rust в гарантиях компилятора, который позволяет экспериментировать. В safe невозможно скомпилировать программу там, чтобы передать одну задачу в 2 разных потока и потом дебажить гонки данных (можно послать копию задания, но это будет просто бесполезной работой, а не UB). Я могу позволить себе попробовать написать код без мьютексов, т.к.если я сделаю в нем ошибку, код просто не скомпилируется. В большинстве других языков конкурентность связана с огромным количеством граблей, которые приходится ловко обходить.
curl
Curl не то, что бы прям переписывают на Rust, но как минимум некоторые новые части пишутся на Rust. Если интересно, можете почитать про недавнюю уязвимость в curl, там в том числе и про переписывание на Rust.
SQLite
Не уверен, насколько они production ready, но на Rust пишут и базы данных, и key-value хранилища и прочие вещи, но сам язык в 3 раза моложе SQLite, так что трудно винить в этом язык.
Все же, "переписать все на Rust" это не то, что бы реальная цель или задача. Код, который полировали десятилетия никто просто так выкидывать не будет (уж точно не в первую очередь). Я поэтому и написал, что для меня у C и/или C++ ниша одна - легаси код, который слишком долго или дорого переписать.
в составе vcpkg около 2,5 тысяч библиотек
В Cargo.io на момент записи 141,981 пакетов. Это не честное сравнение, Rust поощряет разбиение пакетов на много мелких для переиспользования и ускорения компиляции, так что это не 141к обособленных пакетов, но все же.
Rust не гарантирует отсутствие гонок.
Rust следит за некоторыми популярными проблемами с многопоточностью (за счет владения переменной), но это не исключает гонки. Точно также можно в одну переменную писать и читать, пускай и через мьютекс.
Точно также можно в одну переменную писать и читать, пускай и через мьютекс.
Смотря что считать гонкой. Corrupt Shared State получить уже невозможно т.к. мютекс или другой какой атомик - и то хорошо. В плюсах это UB:
Critical race conditions cause invalid execution and software bugs. Critical race conditions often happen when the processes or threads depend on some shared state. Operations upon shared states are done in critical sections that must be mutually exclusive. Failure to obey this rule can corrupt the shared state.
A data race is a type of race condition. Data races are important parts of various formal memory models. The memory model defined in the C11 and C++11 standards specify that a C or C++ program containing a data race has undefined behavior.[3][4]
(c) https://en.wikipedia.org/wiki/Race_condition#In_software
А логические гонки - ну, это уже на совести погромиста, тут язык мешать не должен как мне кажется.
Не невозможно. Не забываем про unsafe в Rust. Сложнее - да. Но не невозможно.
Кроме того, встречаются либы, которые просто обертки над C-либами. Что тоже не спасет от Corrupt Shared State. Впрочем, это тоже можно отнести к unsafe.
А вот свой код, особенно в рамках safe Rust - да, спасает от подобного. И это очень и очень круто. Потому как дебажить подобное очень сложно.
Гонка данных и состояние гонки это две разные проблемы, они даже подклассами друг друга не являются. Цитата из The Rustonomicon:
Safe Rust guarantees an absence of data races, which are defined as:
- two or more threads concurrently accessing a location of memory
- one or more of them is a write
- one or more of them is unsynchronized
A data race has Undefined Behavior, and is therefore impossible to perform in Safe Rust. Data races are mostly prevented through Rust's ownership system: it's impossible to alias a mutable reference, so it's impossible to perform a data race. Interior mutability makes this more complicated, which is largely why we have the Send and Sync traits.
However Rust does not prevent general race conditions.
Он строго гарантирует отсутствие гонок данных, но не может дать гарантии отсутствия гонок условий.
Не забываем про unsafe в Rust. Для unsafe никаких подобных гарантий нет.
Для unsafe подобные гарантии обязан обеспечивать разработчик (т.е. ситуация не хуже, чем в других языках).
А ещё бывают баги в компиляторе.
И кстати, если вас хоть немного заинтересовал Rust, то еще раз рекомендую лекции Алексея Кладова. Там всего 13 лекций по полтора часа, но этого с головой хватит, чтобы понять что, как, зачем и почему в Rust. Особенно по сравнению с моими мыслями, которые я кое-как собрал в статью.
Алексей ведет потрясающий блог matklad (иногда на хабре публикуют некоторые посты из этого блога). В блоге много всякого про Rust и Zig. Рекомендую!
Зачем прямо сразу переписывать существующие библиотеки на Раст, если можно сделать обёртку и подтянуть как есть? SQLite, Lua, curl спокойно подключаются, imgui и openimage переписаны "по мотивам". Qt только не будет, слишком другой менталитет.
Мне не нужен язык, мне нужно программу делать, а для этого нужны библиотеки, очень много библиотек,
По этой логике мы все до сих должны были бы писать на фортране. Однако же, не смотря на объём существующих библиотек, языки развиваются и появляются новые. Вполне естественно, что молодые языки беднее библиотеками, чем старые. Тем не менее новые языки набирают популярность и вытесняют старые, а библиотеки переписываются. Для джавы, вон, даже гит свой написали ("Отец, прости им, ибо они не ведают, что творят.") Учитывая, что в русте можно писать обёртки вокруг готовых библиотек, то ситуация даже проще.
Чем больше я читаю такие хвалебные оды расту и его преимуществам, тем сильнее у меня складывается ощущение, что фанаты раста, критикуя с и с++ за его возможность прострелить ногу, перестают понимать одну вещь - синтаксис с и с++ выстроен из неких математических абстракций вокруг архитектуры ЭВМ, он хоть и даёт возможность забыть про регистры, стек, прерывания и проч., но при этом он позволяет легко об этом вспомнить. Управление памятью, подход к разработке, определяемый компилятором - это всё наверное прекрасно, но кто уверен, что компилятор не ошибается? Ах,да, его пишут боги программирования, они никогда не ошибаются, ведь они пишут язык и компилятор, который никогда не ошибается. Возможно я сильно ошибаюсь, но разрабы, пишущие на расте, скорее всего не понимают, что там под капотом происходит, ведь "у нас самый надёжный супер пупер компилятор,который генерирует самый надёжный и безошибочный код". А потом окажется, через пять лет, что в компиляторе была дыра, которая генерировала код, в котором присутствовали сигнатуры, благодаря которым хакеры могли легко его реверсить и делать эксплойты. Да не, бред какой-то, это же самый надёжный и безопасный язык. Именно благодаря тому, что я на своих плюсах могу стрелять в ногу, и регулярно это делаю, я знаю как сделать так, чтобы мне никто другой не смог выстрелить в ногу. Ничто не совершенно, никто не совершенен.
Дыру в Rust-компиляторе найдут и исправят, фикс автоматически применится для всех Rust-программ, собранных новым компилятором.
Миллионы выходов за пределы массива, use-after-free и прочих UB в миллионах сишных программ не найдут и не исправят никогда.
могли легко его реверсить и делать эксплойты
Да вперед, большая часть кода, где "делают эксплойты" вообще в опенсорсе.
разрабы, пишущие на расте, скорее всего не понимают, что там под капотом происходит
Так в этом и плюс Rust,ты можешь позволить себе не знать, что там происходит (и использовать Rust как Python 4) и при этом писать быстрый и корректный код.
синтаксис с и с++ выстроен из неких математических абстракций вокруг архитектуры ЭВМ
Вокруг PDP-11, если быть точным
он хоть и даёт возможность забыть про регистры, стек, прерывания и проч., но при этом он позволяет легко об этом вспомнить
Зачем мне вспоминать про архитектуру PDP-11? Какое отношение она имеет к современному аппаратному обеспечению c многоядерными процессорами, алгоритмами когерентности кэша, спекулятивному выполнению и тому подобному?
Спойлер - никакого.
но разрабы, пишущие на расте, скорее всего не понимают, что там под капотом происходит
А вы понимаете что происходит под капотом у процессора, который еще раз "компилирует" инструкции для него в микрооперации?
А потом окажется, через пять лет, что в компиляторе была дыра
А потом окажется, через пять лет, что современный процессор - это не одноядерный PDP-11, во что свято верили поклонники мантры "си - это низкий уровень" и произойдет Spectre & Meltdown. Oh shi******
C Is Not a Low-level Language, your computer is not a fast PDP-11
В safe Rust UB нет (точнее, если оно есть то это баг компилятора, который надо исправить), так что мне с практической точки зрения сказать нечего. Из моего теоретического опыта UB действительно очень плохо.
Насколько я понимаю, UB - это когда компилятор считает, что у него есть какие-то гарантии, которые в реальности не выполняются. С UB компилятор может сделать все что угодно, т.к. он будет оптимизировать код исходя из неверных предпосылок. Из-за этого компилятор может, например, просто скомпилировать программу, которая делает не то, что написано в коде или удалить кусок кода с UB, т.к. в правильной программе UB быть не может, а значит этот код недостижим.
UB одновременно зависит от всего вокруг (от кода вокруг, от компилятора, от версии компилятора, от багов в компиляторе, от фазы луны и т.д.), а в другой стороны, если в коде есть UB то эта программа - не программа. Компилятор имеет право сделать абсолютно что угодно со всем кодом т.к. код просто невалиден. Вот статья с примерами UB. Я после этого даже смотреть на языки с UB не могу, там надо прикладывать какие-то невероятные усилия для правильной работы конечного продукта.
Всё УБ от оптимизаций на предположениях. С отключением оптимизации будет выполняться то, что написано.
Всё УБ от оптимизаций на предположениях
Не готов ни подтвердить, ни опровергнуть, моих компетенций тут недостаточно. Но писать на C или C++ чтобы потом код без оптимизаций компилировать вряд ли кто-то будет. Проще сразу взять более медленный, но безопасный язык.
Ну вот я пишу без оптимизации на C89 для промавтоматики и мне важно чтобы выполнялось всё как написано в коде. Как раз и медленно и безопасно!
А зачем вообще выбран Си, если нужно "медленно и безопасно"? Там и кроме UB ногострелов достаточно же...
Потому, что правильная программа на языке С делает только то что ей говорят, и только тогда когда ей говорят. У нее например не запускется сборщик мусора в момент когда тебе нужно обработать критические данные и нужна максимальная производительность.
Написание программ на ассемблере например, это не просто возможность выстрелить себе в колено, это попытка не попасть себе в ногу при каждом шаге, но его продолжают использовать, пишут на нем критически важные участки кода, потому, что ни что не дает большего контроля над железом. А Си наверное самый близкий к железу высокоуровневый язык.
Я понимаю за что современные прикладные программисты не любят С, слишком сложно, слишком много вещей надо держать в голове и не забывать контролировать, это тяжело.
Это просто не их инструмент, оставьте его системщикам, они лучше знают что им надо. Язык Cи в системном программировании "заменяют" последние лет 25 кажется, а он жив до сих пор, по моему мнению только потому, что в этой области удобнее ничего не создали. Безопаснее возможно да, удобней нет.
Так вот у Раста и цель, чтобы сделать язык, на котором можно писать программы, которые делают только то, что им говорят, только ещё без (многих из) острых углов С.
Потому, что программа на языке С делает только то что ей говорят, и только тогда когда ей говорят.
Ага, и честно выходит за границу массива при ошибке в индексе. Ну прямо то что нужно в промавтоматике - молча перетирать соседние переменные при ошибках в программе.
У нее например не запускется сборщик мусора в момент когда тебе нужно обработать критические данные и нужна максимальная производительность.
Существуют куда более безопасные языки без сборщика мусора или с отключаемым сборщиком.
Это просто не их инструмент, оставьте его системщикам, они лучше знают что им надо.
Вот именно, пусть промавтоматчики и оставят этот язык системщикам, а сами перейдут на что-нибудь более безопасное. Скажем, Rust если нужна производительность, или на какой-нибудь Python если она не нужна. Да и вообще у них даже свои собственные языки программирования есть, хотя к ним у меня отдельные претензии.
Ага, и честно выходит за границу массива при ошибке в индексе. Ну прямо то что нужно в промавтоматике - молча перетирать соседние переменные при ошибках в программе.
Мне почему-то казалось, что язык не должен исполнять роль нянечки в детсаду - ходить за каждым ребенком с платочком и вытирать ему сопли.
Или цель разработки новых языков в том, чтобы всемерно снизить порог входа, чтобы любая кухарка могла управлять государством любой прослушавший вполуха какой-нибудь инфоцыганский курс, как можно быстрее стал "суперсеньором"?
Если в индексе ошибка - оно все равно выстрелит. Не здесь, так в другом месте. Не сейчас, так потом. А так оно просто маскируется языком и вроде как все в порядке.
А если говорить о "безопасности", то решается это на системном, а не языковом уровне - любой объект в системе (а переменная - это тоже объект). должен иметь "операционный дескриптор", который в т.ч. содержит его размер. И любое некорректное обращение будет вызывать системное исключение "выход за границу объекта". В любом языке.
Мне почему-то казалось, что язык не должен исполнять роль нянечки в
детсаду - ходить за каждым ребенком с платочком и вытирать ему сопли
Люди, даже имеющие огромный опыт, ошибаются. Особенно легко ошибиться при рефакторинге. Если какие-то свойства программы можно проверить автоматически - лучше это сделать автоматически, и чем раньше, тем меньше стоимость ошибки. Именно поэтому даже в традиционно динамических Python и JS (в виде TypeScript) добавляют аннотации типов. Именно поэтому в Расте существует safe подмножество языка, в котором можно спокойно мешать код и не бояться о тысячах способов получить UB. Именно поэтому индустрия стремится отойти от языков со слабой типизацией навроде Си.
Если в индексе ошибка - оно все равно выстрелит. Не здесь, так в другом
месте. Не сейчас, так потом. А так оно просто маскируется языком и вроде
как все в порядке.
Отличное описание Си, но что же хорошего в этой маскировке?
И любое некорректное обращение будет вызывать системное исключение "выход за границу объекта"
К сожалению, мы находимся не в идеальном мире, и самые популярные архитектуры не содержат необходимых механизмов для реализации этого. Кроме того, подобные проверки решают только ограниченное количество возможных проблем доступа к памяти.
Люди, даже имеющие огромный опыт, ошибаются. Особенно легко ошибиться при рефакторинге. Если какие-то свойства программы можно проверить автоматически - лучше это сделать автоматически, и чем раньше, тем меньше стоимость ошибки. Именно поэтому даже в традиционно динамических Python и JS (в виде TypeScript) добавляют аннотации типов. Именно поэтому в Расте существует safe подмножество языка, в котором можно спокойно мешать код и не бояться о тысячах способов получить UB. Именно поэтому индустрия стремится отойти от языков со слабой типизацией навроде Си.
Я полностью согласен. Но... Если вы начнете мешать код без риска получить UB, то рано-поздно вы все равно обманете компилятор и потом долго будет думать - почему же оно работает не так ка положено, хотя никаких ошибок тут нет ни при компиляции ни при выполнении?
Или нет таких трудностей, которые мы не смогли бы себе создать. За 30+ лет в разработке в этом убедился многократно.
Отличное описание Си, но что же хорошего в этой маскировке?
Ничего. Кроме того, что любой разработчик, который понимает как оно работает внутри, даже без отладчика вам сразу скажет в чем проблема. Просто "вполглаза" глянув на код.
А вот человек, который привык во всем полгаться на язык и компилятор - да. Будет долго чесать репу.
Спросите любого хирурга - что он предпочтет - скальпель, которым можно порезаться, или пластиковый ножичек из одноразового набора для пикника, который в этом плане абсолютно безопасен.
В целом я не поддерживаю что-то одно, но считаю что каждому овощу свой фрукт. И для каждой цели свой инструмент. И нет абсолютно лучшего и универсального на все случи жизни.
Но если вы взялись на инструмент - изучите все правила безопасной работы с ним и привыкнете их соблюдать. Или, если это непосильно, делайте то, что не требует такого сложного и опасного инструмента.
К сожалению, мы находимся не в идеальном мире, и самые популярные архитектуры не содержат необходимых механизмов для реализации этого. Кроме того, подобные проверки решают только ограниченное количество возможных проблем доступа к памяти.
Ну лично я нашел себе идеальный кусочек, где это есть. Может быть не в полном объеме, но в значительной степени оно так. :-)
Ничего. Кроме того, что любой разработчик, который понимает как оно работает внутри, даже без отладчика вам сразу скажет в чем проблема. Просто "вполглаза" глянув на код.
Это только для простых случаев, типа выхода за границы массивов. А если там какое-нибудь совсем не очевидное UB, то даже с отладчиком можно просидеть много часов. Например, потому что под отладчиком и в дебажном билде все отлично работает, а без отладчика и в релизом билде уже нет.
Тут на хабре какой-то человек носил свою проблему на Fortran где он сравнивал float-ы через == и ожидал, что условия выполнятся, ведь операции и значения при расчетах одинаковые, однако же, стреляло, что не равно, когда он убирал логирование. УБ однако)
Суть была в том, что в памяти лежал 32битный флоат, а правое значение лежало в регистре 40битном, и они естественно были не равны, а при походах в логи, 40бит регистр складывал 32бита себя в стек, и поэтому работало.
А вообще эта помешанность на корректности меня сильно смущает. Число тупых логических ошибок смело 100 к 1 относительно колдунских проблем языка, где опять же не прав был я.
Дело не в нянечках и соплях, а в возможности сосредоточить внимание на действительно важных вещах.
А если говорить о "безопасности", то решается это на системном, а не языковом уровне - любой объект в системе (а переменная - это тоже объект). должен иметь "операционный дескриптор", который в т.ч. содержит его размер. И любое некорректное обращение будет вызывать системное исключение "выход за границу объекта". В любом языке.
И после этого вы ещё заявляете о вреде проверок границ, которые приходится отключать в тяжёлых расчётах?!..
Да, решить проблему на уровне платформы - идея хорошая. Только вот в чём проблема - на системном уровне этого не сделать, тут нужна аппаратная поддержка. И неслабая, поскольку хранение длины в указателе приводит минимум к удвоению его размера - а значит, для сохранения производительности нужно удваивать шину данных.
язык не должен исполнять роль нянечки в детсаду
Практика (которая критерий истины) показывает, что писать безопасно на C и/или C++ не может никто. Rust позволяет людям с меньшим опытом писать настолько же быстрые и гораздо более безопасный (уменьшение количества уязвимостей в 70 раз это слишком хорошо, чтобы от этого отказываться).
любой объект в системе должен иметь "операционный дескриптор"
Только систем таких нет. В Rust как раз по умолчанию все это и проверяется (как на этапе компиляции, так и в рантайме).
А потом говорят, что сообщество Rust токсичное. Да, токсичное тем, что признаёт человеческие слабости и пытается ради общего блага переложить заботу о технических тонкостях на машину. Не [только] для того, чтобы уменьшить порог входа, а для того, чтобы помочь и опытным разработчикам произвести больше полезной работы.
Вы всё ещё можете отключить "нянечку в детсаду", но только при этом вам придётся подумать -- а почему это мне приходится так делать? Обосновано ли это? Не подкладываю ли я себе свинью на будущее? А потом обклеить опасный участок яркой лентой и поставить табличку "осторожно, скользкий пол", чтобы в будущем было проще искать такие места.
А если говорить о "безопасности", то решается это на системном, а не языковом уровне - любой объект в системе (а переменная - это тоже объект). должен иметь "операционный дескриптор", который в т.ч. содержит его размер. И любое некорректное обращение будет вызывать системное исключение "выход за границу объекта". В любом языке.
Что характерно, защищённый режим x86 как раз про это. Но никто не заценил фишку, не воспользовался ей, не создал ни ЯП, ни ОС, которые бы использовали это в полной мере. А затем и Intel забросила и похоронила концепцию.
А до счастья оставался маленький шаг: сделать PDBR не частью CR3, а частью дескриптора сегмента, чтобы проблема фрагментации линейного адресного пространства перестала быть актуальной.
И была бы аппаратная защита от выхода за границы массивом и буферов. Buffer overflow attack не было бы как класса. Атак с шеллкодам не было бы как класса.
Я немного про другое.
Вот, например, получили вы некоторый указатель аргументов функции. И представьте, что у вас есть некое системное API которое позволяет получить информацию о том, на что этот указатель указывает - тип объекта, размер памяти, который он занимает... Т.е. к каждому объекту есть еще "операционный дескриптор" (operational descriptor, opdesc) по которому можно получить некоторую интересную информацию.
Единственное - чтобы это использовать, нужно я вно указать компилятору что требуется передача операционных дескрипторов в функцию. Для С/С++ это будет
int func (char *, int *, int, char *, ...); /* prototype */
#pragma descriptor (void func ("", void, void, ""))В данном случае для аргументов char* внутри функции всегда можем посмотреть - а что на самом деле за ними кроется - какого размера буфер?
В других языках иначе - в некоторых просто достаточно модификатора OpDesc в прототипе функции.
Тогда это половинчатое решение какое-то...
Ваш #pragma descriptor требует пояснения: я не понял, почему в прототипе int (тип возврата), а в прагме void, что означают пара пустых строковых литералов?
И ещё: в вашей концепции запрашивать информацию о размере буфера это обязанность программиста или это неявно будет делать компилятор?
Мне почему-то казалось, что язык не должен исполнять роль нянечки в детсаду - ходить за каждым ребенком с платочком и вытирать ему сопли.
Вы теперь мой любимый комментатор на Хабре: ходите по всем статьям, где упомянут C/C++, и вбрасываете порцию токсичности. Через пару комментариев не забудете упомянуть, что вы консультант по разработке и должность придумали специально для вас. А также, что вы каждый день работаете с кодом, который не правился 10 лет (видимо, на него смотрите) и ещё пару раз оскорбите программистов, пишущих на чём-то, кроме вашего любимого языка.
Так и день пройдёт)
Где вы увидели токсичность в адрес С/С++?
Написано ровно то, что написано. И ничего более. Додумать можно все что угодно, но это уже из разряда "сама придумала - сама обиделась".
К С у меня вполне себе нежные чувства при всех его недостатках. Да, это "опасный" инструмент. Но это уже из серии про дурака и стеклянный йенг.
С С++ сложнее - мне он очень нравился на заре, когда был в варианте "ОО-расширения С". Сейчас, как мне кажется, было бы правильно полностью абстрагироваться от старого наследия и развивать его как несовместимый с С отдельный язык (каковым, по сути, он уже и является). Ну и не переусложнять, пытаясь втащить туда все подряд, а сосредоточится на устранении разного рода UB (раз уж так сейчас модно "безопасно" пользоваться).
Но в целом никаких предубеждений к нему нет. Язык как язык. Не хуже и не лучше (по совокупности характеристик) многих прочих в широком классе задач (но не любых задач).
Есть некоторая предвзятость в людям, которые начинают с пеной у рта доказывать что вот они нашли язык, который самый лучший и самый универсальный для всего на свете. Такого точно не бывает. Можно найти лучший инструмент для конкретной задачи, но не для всех сразу. Получится то ли нейрохирург с бензопилой, то ли лесоруб со скальпелем. Хотя в своих областях и скальпель и бензопила работают отлично.
Где вы увидели токсичность в адрес С/С++?
Вы невнимательно прочитали: я как раз написал, что ваша токсичность направлена на людей, не пишущих на вашем любимом языке. Можно вспомнить, как вы пренебрежительно относитесь к "перекладывателям джейсонов")
Есть некоторая предвзятость к людям
Именно.
начинают с пеной у рта доказывать
Никакой пены у рта у автора не замечаю. Человек делится своими впечатлениями, притом честно даёт представление о своих компетенциях, чтобы мы могли адекватно оценить подаваемый материал. Он же не пишет: "я 20 лет писал на C, но в конец задолбался и перехожу на Rust, так как в очередной раз вылетел за границы массива", верно?
А вот у вас, кажется, что-то капает. Возможно, кровожадная слюна: жаждете выпить из молодых специалистов всю радость от профессии.
А почему тогда не Pascal, Oberon или Ada?
B&R любит С. Да и всякие PC-based тоже. Но при наличии культуры кода, руководств, правильных ограничений и отсутствия всяких "смотри как я могу", получается легко читаемый структурированный код.
В таком случае вы ходите по минному полю. Эффекты от UB обычно проявляются при включенных оптимизациях, но язык и компиляторы не дают никаких гарантий, что при выключенных оптимизациях эффектов от UB не будет. Если вы действительно таким образом пишете для промавтоматики, то я переживаю за пользователей этой автоматики, очень надеюсь что там не что-то связанное ответственными и опасными применениями.
Оптимизации никак не помешают сначала удалить указатель, а потом его прочитать. И у вас он будет правильно читаться, а у клиента SEGFAULT. Классика же.
Всё УБ от оптимизаций на предположениях. С отключением оптимизации будет выполняться то, что написано.
Покажете параграф в стандарте языка, гарантирующий это?
А покажите параграф в стандарте где должно выполняться что-то иное в противовес к директивам программы?
А покажите параграф в стандарте где должно выполняться что-то иное в противовес к директивам программы?
Не "должно", а "может". Параграф 3.64:
Permissible undefined behavior ranges from ignoring the situation completely with unpredictable results, to behaving during translation or program execution in a documented manner characteristic of the environment (with or without the issuance of a diagnostic message), to terminating a translation or execution (with the issuance of a diagnostic message).
То есть прямым текстом стандарт допускает что в случае undefined behaviour может быть совершенно unpredictable результат - в случае UB стандарт разрешает компилятору сгенерировать вообще все что угодно, даже то, чего нет в "директивах программы". Каких-либо исключений из этого правила в случае отключенных оптимизаций компилятора там нет, никаких гарантий не даётся.
А ещё есть замечательный параграф 4.1.2, где сказано
A conforming implementation executing a well-formed program shall produce the same observable behavior as one of the possible executions of the corresponding instance of the abstract machine with the same program and the same input. However, if any such execution contains an undefined operation, this document places no requirement on the implementation executing that program with that input (not even with regard to operations preceding the first undefined operation).
То есть стандарт явно допускает что программа с UB может творить любую хрень (в том числе и то, чего нет в "директивах программы") даже ещё до выполнения того места, где было UB.
Ну так это если вы сами УБ запрограммировали, то и получаете неопределённое. Тут вообще без вопросов! А вот если программировать правильно, то никакого левого поведения не предполагается.
Вы уж определитесь, левое поведение возникает из-за программиста или из-за оптимизаций. Потому что если программировать правильно - то и оптимизации отключать нет смысла.
Конечно из-за оптимизаций! Программист пишет без указателей, мусор не создаёт, память выделяет при старте, границы проверяет.
Ответ неправильный.
Если программист пишет валидный код, не содержащий UB, то стандарт гарантирует, что код будет скомпилирован корректно даже со всеми возможными оптимизациями.
Если программист пишет некорректный код, содержащий UB, то эффекты от UB в коде могут проявиться даже с полностью выключенными оптимизациями.
Всегда можно сказать "нужно программировать правильно, а неправильно программировать не надо", в стандарте C++ описано несколько сотен случаев, вызывающих UB, на почти тысяче страниц. Они далеко не только про память, указатели, мусор и границы, вообще нет. Многие из них совершенно не очевидные (их практически невозможно вывести логически, нужно именно внимательно читать стандарт и знать, что то или иное вызывает UB).
Не существует программистов, писавших в своей жизни сколь-менее сложный код и не допустивших за свою жизни при написании кода ни одной ошибки. Поэтому и про UB так думать не надо, баги вы можете отловить тестированием, а с UB это так просто уже не получится (и статический анализ тоже далеко не факт что отловит все случаи).
Многие из них совершенно не очевидные
Например?
Например, вы написали вот такой код, когда вам нужно взять быстрый обратный квадратный корень или сконвертировать значение, полученное от внешней железки (там то же самое, но наоборот):
long i;
float y;
y = number;
i = *(long*)&y;Или сделали то же самое через union, как часто делают:
union myunion {
float f;
long l;
}
myunion.f = number;
/* тут используете myunion.l */Казалось бы, все прилично. На вашей платформе размеры long и float равны. У вас один поток. Вы не выделяете память в куче, только на стеке. Вы не выходите ни за какие границы. У вас нет никакого переполнения. У вас нет никакой утечки. Но в Си первый код содержит UB, а в Cи++ и тот и тот код содержат UB. Потому что в первом случае нарушается правило strict aliasing, которое вы обязаны знать, во втором случае нарушается active member rule, которое вы тоже обязаны знать.
Пример с проверкой на переполнение вида if ((X+n) > X) ниже уже разбирался. Если X - signed, то компилятор имеет право выкинуть все такие проверки, заменив их на рандомные true и false в разных частях кода. Вы-то знаете, что для вашего процессора 0x7FFF + 1 = 0x8000, что на вашей платформе будет 32767 и -32768 соответственно, но вот компилятор имеет полное право на это наплевать и скомпилировать что угодно вместо вашего условия. Потому что это не unspecified, а именно undefined behavior.
И подобных приколов, про которые надо именно знать там довольно много.
Ну вот дичь же! Это же точно из серии "смотри как я могу". Можно еще через двойную косвенную адресацию провернуть финт. Но нафига?!
преобразование i = (long)y; разве не покатит чтобы разместить значение в переменной большей разрядности?
Я пишу платформозависимый код, знаю сколько байт мне надо и спокойно пользуюсь типами uint32_t, int64_t и иже с ними.
И зачем вообще заигрывать с адресацией *&var без причины? Байты в слове попереставлять красиво?
Если компилятор заменит проверку if ((X+n) > X) на if (true), то это конечно плохо, лучше бы подставил полный код, хотя я подсчет бы вынес в отдельное выражение и сравнивал уже результаты. Не люблю нагромождения в условиях ветвления.
UPD: хотя, постойте, i = (long)y; не покатит. Вы же хотите IEEE 754 float побайтово с мантиссой, экспонентой и всем знаками переместить в long. Но и тут вопрос, а что дальше то? Руками будете парсить, CRC считать? Тогда лучше читать память через memcpy и sizeof.
Ну вот дичь же! Это же точно из серии "смотри как я могу". Можно еще через двойную косвенную адресацию провернуть финт. Но нафига?!
преобразование i = (long)y; разве не покатит чтобы разместить значение в переменной большей разрядности?
Нет, не прокатит, оно преобразует число из флота в инт математически, а надо побайтово. Количество байт и там и там одинаковое.
Но и тут вопрос, а что дальше то?
Да я выше уже написал. Например, это нужно для очень популярного алгоритма быстрого расчета обратного квадратного корня.
Или другой вариант, у вас есть библиотечка, которая умеет читать регистры какого внешнего устройства по его специфичному протоколу. Регистры четырехбайтовые, то есть uint32_t, но конкретно в некоторых регистрах в памяти того внешнего устройства лежат float, и вам нужно работать с ним как с float.
Тогда лучше читать память через memcpy и sizeof
Да, это единственно правильный вариант, не вызывающий UB в C ++17 и старше. В C++20 добавили ещё bit_cast. Но программист, не знающий про strict aliasing напишет простой каст как в примере выше и получит UB.
Если компилятор заменит проверку if ((X+n) > X) на if (true),
Ха-ха, нет, все ещё хуже. Компилятор может заменить эту проверку не только на true, но вообще не все что угодно. Вплоть до того, что в одном месте он ее заменит на true, а через несколько строчек в другом месте такую же проверку заменит на false. Вот тут об этом есть.
Понимаете, вот именно в этом и проблема. "Выйдя за пределы буфера при записи вы можете испортить другие данные в рабочем наборе, что может вызвать непредсказуемое поведение программы" - это common sense, это прекрасно понимает любой программист, кто хоть немного имеет представление о том, как хранятся данные в памяти.
А вот "если вы где-то в программе сделаете два указателя разных типов на один и тот же адрес, то согласно стандарту языка компилятор имеет полное право сотворить в генерируемом бинарнике любую дичь даже там, где вы эти указатели не используете" - это уже не так очевидно, для этого нужно именно знать правилах написанные мелким шрифтом в глубинах стандарта языка на тысячу страниц.
Регистры четырехбайтовые, то есть uint32_t, но конкретно в некоторых регистрах в памяти того внешнего устройства лежат float, и вам нужно работать с ним как с float.
Будем считать, что они у вас отображены на память и адрес вы знаете, например uint64_t addr = 0x0e55eeff8f4;
float* pf = (float*)addr; - вот указатель на ваш регистр как на float, даже memcpy не нужен.
компилятор имеет полное право сотворить в генерируемом бинарнике любую дичь даже там, где вы эти указатели не используете
вот не нужен мне такой компилятор, мне нужна предсказуемость, а не дичь.
мне нужна предсказуемость, а не дичь.
Значит С не для вас :)
Будем считать, что они у вас отображены на память и адрес вы знаете, например uint64_t addr = 0x0e55eeff8f4;
Ахахаха, с чего вдруг "будем считать"-то? Ничто никуда по умолчанию не отображено, а сторонняя библиотека выдает вам только регистры uint32_t или массив из таких регистров. Да то там говорить, самая популярная в мире библиотека работы с Modbus libmodbus читает значения регистров только в буфер uint16_t*. Вы прочитали два регистра, и теперь вам надо перевести их во float.
вот не нужен мне такой компилятор
Компилятор всего лишь следует стандарту языка. А стандарт языка говорит, что если вы хотя бы в одном месте допустили в коде UB, то нет вообще никаких гарантий того, что итоговая программа будет корректной. Вы можете на это рассчитывать только в том случае, если в документации на компилятор прямо написано "мы реализуем нестандартное расширение языка, в котором конкретно вот это не является UB". В противном случае есть вероятность получить дичь.
Если вам "нужна предсказуемость, а не дичь", и при этом вы не готовы до мелочей знать стандарт языка и следовать ему, то, возможно, как правильно сказали выше, языки C и C++ не для вас, стоит использовать что-нибудь другое.
Вместо железа в памяти у вас значения в памяти... Какая разница в плане чтения из адреса? Можете через void* привести к float*. Страшно? Прочитали два двухбайтовых регистра, и теперь вам надо перевести их в float? Пихните прочитанные двухбайтовые значения в 4х байтовую переменную с учетом endianess (тут прям открывается свобода для программиста) и кастаните к float через reinterpret_cast. Фактически, вы говорите компилятору, что хотите работать с этими четырьмя байтами в памяти как с типом float. С чего вдруг УБ нарисуется?
Мне не стандарт надо знать до мелочей, а целевую платформу. Если уж Си компилятор будет упрямиться, то получит ассемблерную вставку и делов.
Можете через void* привести к float*
Не поможет, у вас все равно будет UB. Прочтите внимательно пункты 6, 7 параграфа 6.5 стандарта.
Пихните прочитанные двухбайтовые значения в 4х байтовую переменную с учетом endianess (тут прям открывается свобода для программиста) и кастаните к float через reinterpret_cast.
Это тоже UB:
Whenever an attempt is made to read or modify the stored value of an object of type DynamicType through a glvalue of type AliasedType, the behavior is undefined unless one of the following is true:
AliasedType and DynamicType are similar.
AliasedType is the (possibly cv-qualified) signed or unsigned variant of DynamicType.
AliasedType is std::byte, (since C++17) char, or unsigned char: this permits examination of the object representation of any object as an array of bytes.
Вот видите, вы в своих предложениях нарвались на UB. Это было совершенно очевидно, ведь правда? :)
С чего вдруг УБ нарисуется?
С того, что согласно стандарту языка это UB, и стандарт не даёт гарантий генерации корректного кода компилятором после этого. Ещё раз говорю, не путайте undefined behavior и unspecified behavior.
Мне не стандарт надо знать до мелочей, а целевую платформу.
Дожили. Человек, пишущий на языке программирования, утверждает что ему не нужно знать этот язык программирования... Впрочем, это не редкость среди эмбеддеров, увы.
Если уж Си компилятор будет упрямиться, то получит ассемблерную вставку и делов
Ха. Вы, надеюсь в курсе (выше вон уже был приведен параграф из стандарта), что в случае, если вы допустите UB в одном месте, то компилятор может сгенерировать сломанный код не только в этом месте, но в и абсолютно любом другом месте программы, и даже когда ваш код с UB вообще никогда не используется? И сломан этот "другой код" может быть таким образом, что корректность его работа будет зависить от случайных факторов? Будете каждый раз после мельчайшего изменения проверять целиком и полностью весь ассемблерный листинг всей программы, чтобы убедиться, чтобы все скомпилировадось корректно? Ну, ваше право, но не проще ли изучить язык программирования, который вы используете, и не делать в коде того, чего этот язык явно запрещает делать?
Whenever an attempt is made to read or modify the stored value of an object of type DynamicType through a glvalue of type AliasedType
Я правильно понимаю, что memcpy из int_32* в float* (в смысле, копирование четырёх байт, на которые указывает первый указатель, по адресу, на который указывает второй) сюда тоже подпадает? Или как раз это допустимо? Просто если это допустимо, тогда не совсем понятно, почему reinterpret_cast из int_32 в float (не между указателями, а именно самого значения, как transmute в Rust) недопустим - семантически-то, по идее, это то же самое: "читаем байты как тип x [которым они и являются - всё корректно], записываем в другое место как y [и x тут уже не при делах]".
Это цитата была конкретно про reinterpret_cast.
С memcpy объекта у вас уже два разных, алиасинга нет. Грубо говоря, при касте у вас сначала происходит доступ к объекту (по не-его типу), а потом копирование, а при memcpy сначала копирование, а потом доступ (по его типу).
В самом memcpy ничего криминального, у него "Both objects are interpreted as arrays of unsigned char", а с чарами стандарт явно разрешает алиаситься.
Если интересная тема, есть очень хороший разбор со ссылками на стандарты C и C++.
Если язык мне разрешает делать такие базовые вещи, при этом стандарт компиляции берет кардбланш на дичь, то тут что-то не так со стандартом, т.к. с языком всё норм последние 50 лет.
Если завтра комитет объявит УБ вообще всё, то компилятор можно будет сократить до генератора случайного кода!
С чего вы взяли, что "язык вам это разрешает"? Язык - это то, что описано референсной документации для него, в случае с C и C++ это утвержденный комитетом стандарт ISO. И он вам эти вещи делать не разрешает, там об этом прямо написано, что так делать нельзя ни в коем случае. Вы же, видимо, просто плохо изучили язык, ваш основной рабочий инструмент, раз об этом не знаете.
Если какая-то реализация языка C или C++ не соответствует стандарту, то не надо называть это C и C++. Если вы компилируете код компилятором, который соответствует стандарту (GCC, Clang, Keil, и многие другие), то не надо удивляться, что они следуют правилам и ограничениям, описанным в стандарте.
Ха. Вы, надеюсь в курсе (выше вон уже был приведен параграф из
стандарта), что в случае, если вы допустите UB в одном месте, то
компилятор может сгенерировать сломанный код не только в этом месте, но в
и абсолютно любом другом месте программы, и даже когда ваш код с UB
вообще никогда не используется?
То есть вы серьёзно считаете такое неадекватное поведение компилятора приемлемым... Дожили...
А что не так? Компилятор следует правилам и ограничениям языка программирования, код на котором он компилирует. Если вы напишите корректный в соответствии с правилами языка код, то вы получите корректный результат, никакой самодеятельности не будет. То, что из некоторректного исходного кода компиляторт вам почему-то обязан скомпилировать корректную программу, никто вам и не обещал. Добро пожаловать в мир C и C++.
Это мир не языка Си, а мир Стандарта, которого изначально не было и всё прекрасно компилировалось в соответствии с языковыми конструкциями. Комитет пошёл на поводу у каких-то хмырей далёких от программирования и превратил низкоуровневый Си в высокоуровневый Си-хрен-пойми-что, на котором нормально даже драйвер не написать, если следовать современным стандартам. Так что компилятор обязан, а иначе будет заменён на тот, который при виде УБ не будет вырезать кусками код, нарушая структурную целостность программы, да так, что программный счётчик попадает в функцию, которую не вызывали!
Так забавно спорить с Сишниками... в одной ветке отказываются принимать что стандарт -- и есть язык С, а всё остальное -- его реализации, соответствующие стандарту или делающие отсебятину. В другой ветке жалуются, что у Раста нет стандарта, поэтому он не настоящий язык, хотя его компилятор явным образом обещает не делать никакого бреда, а если делает -- то это баг, который будет исправлен.
Комитет пошёл на поводу у каких-то хмырей далёких от программирования
Комитет - это люди, которые не только теоретизируют, но и непосредственно сами занимаются программированием. Разработчики библиотек, разработчик компиляторов, разработчики железа, разработчики научного и высокопроизводительного софта.
В комитете по стандартизации C++ кроме остальных сам Бьярне Страуструп заседает. Вам, конечно, безусловно виднее, как ему стоит развивать созданный им же язык :)
котором нормально даже драйвер не написать, если следовать современным стандартам.
Что для вас "современным"? В сях подобные правила там ещё с начала 90-х годов, в плюсах с самых первых версий стандарта. И да, драйвер вам писать никто не мешает. Просто делайте это так, как вам предписывает используемый вами язык программирования, а не как курица лапой "авось прокатит". А, ну да, для этого нужно сначала этот язык изучить, одного только знания "целевой платформы" для разработки, как мы выяснили, совсем недостаточно.
Так что компилятор обязан, а иначе будет заменён на тот, который при виде УБ не будет
Компилятор вам обязан только то, что гарантировали его разработчики (то есть, реализацию стандарта языка, ну ещё могут быть какие-то нестандартные расширения). Кстати, а вы уверены, что такие существуют? Вот прямо со стопроцентными официальными гарантиями от производителя, что у этого конкретного компилятора нет undefined behavior, а есть только unspecified behavior, и что из некоторректного кода он всегда будет генерировать корректную программу? Поделитесь ссылкой, если знаете такой?
Всегда можно катить бочку на комитет, на разработчиков компилятора, и ещё черт знает на кого, но не лучше ли изучить свой основной рабочий инструмент не на уровне студента-первокурсника бездумно описывающего лабы, а на уровне, достаточном для написания надёжного и корректного кода?
Вы тут теоретизируете про рабочий инструмент и подход студента первокурсника, а в проблему погрузиться отказываетесь. Безусловно, стандарт в той части, что описывает язык Си, и есть язык Си. А вот в той части, что описывает концепцию УБ, это знатный косяк, которым воспользовались разработчики компиляторов, чтобы тупо выпиливать куски кода на основании заключения о УБ как о невозможном. В результате компилятор такой: "у вас тут указатели сравниваются на разные области памяти, а это УБ, а значит такого не может быть никогда (сфигали?) и можно код порушить вместо того, чтобы в инструкцию CMP преобразовать". Или компилятор вдруг узнал, что знаковое целое переполняется, так что инструкции ADD вы не дождётесь. Ну бред же! Ну или священный нулевой указатель, разыменовав который можно вызвать ледниковый период вызвать, вместо того, чтобы отдать данные по адресу 0x0000. То есть договор с современным компилятором о генерации понятного платформозависимого кода больше не работает. Вместо этого работает "вижу УБ - делаю любую дичь". А вы тут, ой, как же такое случилось, тупые эмбеддеры не знают свой инструмент... Они его слишком хорошо знают, в том то и дело.
То есть договор с современным компилятором о генерации понятного платформозависимого кода больше не работает.
Прекрасно работает. Пишете корректный код - получаете корректную и переносимую программу. Пишете некорректный код, нарушающий правила вашего языка программирования - получаете некорректную программу.
Они его слишком хорошо знают, в том то и дело.
Ну вот мы с вами в этой ветке комментариев нашли уже несколько базовых вещей, которые обязан знать каждый C и C++ разработчик, о которых вы даже не догадывались. Это называется "слишком хорошо знают"? Попахивает синдромом Даннинга-Крюгера.
Пишете корректный код - получаете корректную и переносимую программу. Пишете некорректный код, нарушающий правила вашего языка программирования - получаете некорректную непереносимую программу.
Акцент, я так понимаю, на том, что эти самые "правила языка" в случае стандартного Си не учитывают возможность существования корректного, но непереносимого кода.
Разработка стандарта языка всегда основывается на компромиссах. Если требование "переносимости" какой-то фичи, актуальной только на редких и специфичных платформах сломает кучу оптимизаций на других более популярных платформах, то скорее всего ее так и оставят UB. А разработчики компиляторов под конкретно те платформы сделают у себя в компиляторах расширение языка, в котором конкретно это UB не UB.
Но в этом контексте не понятен наезд именно на "современные" стандарты. Упомянутый выше запрет развменвывания нулевого указателя был в сях ещё с 70-х годов (почему именно - вопрос отдельный, скорее всего какие-нибудь исторические причины типа наследия PDP-11), это не специфика новых стандартов. Правило о том, что в случае наличия в коде UB корректность итоговой программы не гарантирована, там тоже с лохматых времён, первые версии GCC в 90-х годах вообще "Ханойские башни" на девелоперской машине запускали, когда обнаруживали в коде UB :) Короче, тут не понятен именно хейт "новых стандартов", потому что все, на что жалуется комментатор выше, было ещё и в очень старых. Я бы даже сказал наоборот, новые стандарты в этом плане лучше, в C++20 вон, например, придумали переносимый bit_cast наконец-то.
Ну хоть теперь, оглядываясь в прошлое, вы поняли, что внедрение концепции УБ поверх языка, на деле оказалось плохой идеей?
первые версии GCC в 90-х годах вообще "Ханойские башни" на девелоперской машине запускали, когда обнаруживали в коде UB
Побуду занудой: там было unspecified behaviour, то есть определяемое платформой, а не стандартом. А конкретно обработка директивы #pragma. UB (undefined behaviour) за исключением очевидных частных случаев вроде int a = *(int*)NULL; вот так вот просто детектировать при компиляции нельзя (было бы иначе - это поведение бы уже давно стандартизировали как ошибку компиляции).
вы серьёзно считаете такое неадекватное поведение компилятора приемлемым
Это не автор считает, это стандарт так считает.
О, кстати, я вам тут теорию подкину. А вы разве никогда не задумывались, почему стандарт стал считать за УБ именно то, а не что-то другое? Зачем в стандарт наваливают все больше и больше положений об УБ? Сам язык Си имеет невысокий порог входа, он структурирован и строг. Зато карта минных УБ полей на тыщщу страниц, а главное священное знание и опыт, как её читать создает вокруг языка орел непреступности. Ведь новые модные языки продвигаются не просто так. Ведь клич "А давайте перепишем всё на раст" дорого стоит! А именно - инвестиции, рабочие места, обучение, контракты, субподряды и распилы мегатонн человекочасов. И те хмыри в комитете далёкие от программирования вполне могут быть очень близки к финансам. Просто программирование перестало быть приоритетом.
О! "В том, что в сях и плюсах много не очевидных UB виноваты растоманы и гоферы, на которых работают двойные агенты в комитете по стандартизации" - это прям сильно, я думаю когда-нибудь по Рен-ТВ такую передачу покажут. Про то, что UB и вытекающие из него правила существуют в сях и плюсах с тех бородатых времён, когда никаких новомодных языков ещё в проекте не было, скромно умолчим.
Ну что вы как маленький, всё вам объяснять надо. На самом деле, раст появился ещё тогда, просто тайная жидомасонская ложа решила придержать его якобы изобретение до нужного момента, чтобы испорченный си создал потребность, и вам можно было продать раст! /жирный_сарказм
Видимо да, т.к. изначально УБ в сях был не для разрушающей оптимизации и определялся платформой. А теперь УБ эксплуатируется компиляторами, чтобы инструкции вырезать.
определялся платформой
Когда что-то определяется платформой, это не undefined, а unspecified или implementation-defined behavior, это разные термины.
А фраза про то, что undefined behaviour может привести к "...ignoring the situation completely with unpredictable results" (то есть UB в сегодняшнем понимании) была ещё в стандарте Си 1989 года, с тех пор ничего в этом плане не изменилось.
С UB встречаешься обычно при смене компилятора / платформы / архитектуры.
Если одним компилятором компилировать под тот Win x64, то шансы встретить UB пускай и есть, но они практически все всплывают еще на этапе тестирования.
Пускай опыта с C/C++ у меня совсем немного, но с UB встретился плотно один раз - когда watch дебаггера и реальное исполнение кода давали разные результаты. В итоге я очень долго отлаживал этот код, не понимая в чем проблема.
Таки Rust лучше C/C++?
Слушайте, ситуация с Rust напоминает ситуацию с ЛГБТ-повесточкой.
Я совершенно ничего не имею против тех, кто пишет быстрый, надежный и безопасный код на RUST. Молодцы. Но я просто бешусь, когда они начинают рассказывать мне как я должен писать код. Вот и все.
Ситуация действительно как с лгбт-повесточкой, а именно: в оьоих случаях противники путают информацию с агитацией. Каким образом статья на хабре может заставить вас писать иначе? Это же просто информация.
Ну да. Я ведь ровно о том же.
Вообще-то я комментировал не статью. У меня к ней нет никаких претензий. Я отвечал на откровенно провокационный комментарий. И даже процитировал ключевую его часть.
P.S.
И еще - я вместо "противники", писал "молодцы". Что уже само по себе характеризует отношение а оппоненту. Разве нет?
Аргумент одинаковый — если у вас достаточно неокрепший(детский/подростковый/студенческий в случае Rust) ум, то вас легко направить по тому или иному пути. Если вы 40-летний сеньор, то радужный раст вам нестрашон:)
Много с чем ситуацию напоминает - "холивар" это называется. Было всегда и будет ещё.
Ну да. Лучший инструмент - это тот, которым ты сегодня можешь делать продукт.
А те, кто только начинает вольны выбрать любой из представленных инструментов. В конце-концов всегда "фотографирует фотограф, а не фотоаппарат". И вообще, "Пусть расцветают сто цветов, пусть соперничают сто школ" (с)
Rust в этом плане просто быстрее внедряет желаемые вещи, пока С++ комитет решает завести новый функционал в стандарт или оставить до новой версии на подумать - в расте оно уже работает в достаточно эргономичном виде. Для примера взгляните на ту же библиотеку ренжей и вью - сколько лет до них добирались и до сих пор нет полного покрытия у всех компиляторов, в то время как в Rust часть синтаксиса языка. Причины понятны, но работать от этого легче не становится. Нормальные модули ждём по сей день.
Rust Embed вполне активен насколько мне известен и опять же эргономика и инструментарий этой экосистемы в среднем лучше чем альтернативы для C++, хотя эквивалентный код вполне можно было написать и на C++. Т.к. работа с платами в любом случае будет сопряжена с манипуляциеми с голой памятью, то на определённых уровнях так или иначе всплывёт unsafe и возможность скрафтить UB, так что с плюсами в этом плане различий меньше. Оно будет просто удобнее в среднем.
наверняка на этот счет есть линтер, но такой код просто не должен компилироваться. А про очевидность поведения zero value для разных типов мне даже говорить не хочется
Вот тут есть чоткое непонимание ситуации. Цель в том, что новое поле всегда может найтись и оно будет нулевым. Приползёт от старого сервиса. Очнётся зомби с кодом недельной давности. Придётся откатить один из сервисов. Надо прочитать файл который создали год назад. И так далее. То есть "новое поле == нечто нулевое" это норма с которой должен работать любой код. Нельзя "не скомпилировать", потому что это нормальное поведение рантайма.
Если мы поддерживаем старое API, то можем сделать это поле опциональным и обрабатывать надлежающим способом. А вот уже другие ситуации, по моему мнению, стоит рассматривать отдельно, иначе можно получить неприятные ошибки.
И не просто ошибки. Я помню истоии об уязвимостях возникшие именно так. И эксплутируемые именно на основе такого поведения "нулевого поля". По-моему именно из-за этого несмотря на существование "нулевого" поля в "google protobuf", они также ввели и опциональные , и значение по умолчанию, которое "на проводе" кодируется тем же нулем. Т.е. ноль в данных не есть ноль на выходе.
Как раз подход с молчаливой инициализацией нулями порождает ошибки, возможности для которых создатели Раста постарались минимизировать. При молчаливой инициализации компилятор не может определить, не забыл ли программист учесть то самое "легаси", про которое Вы говорите.
В Расте же стараются сделать так, чтобы программисту для учёта подобных случаев приходилось явным образом что-то добавить в код, и компилятор, соответственно, может распознать, забыл ли программист учесть то "легаси" или нет.
Приведённые Вами ситуации не означают, что нужна автоматическая инициализация нулями. Они означают, что инициализатор (конструктор), который создаёт структуру из соответствующего источника, должен явным образом обработать эту ситуацию. Если при отсутствии значения соответствующее поле должно инициализироваться нулём - ок, пусть так, но это должно быть явным образом осознанно сделано программистом, а не произойти автоматически. И именно про это говорит автор статьи.
Кроме того, что уже сказано выше про неинициализированные поля мне добавить нечего. Добавить я могу только то, что, по моему мнению, zero values в Golang это ошибка сама по себе. Это заставляет все типы иметь какое-то значение по умолчанию, хотя для типа может просто не быть такого значения.
Каналы хороший пример такого, в nil канале нет никакого смысла, у него нет и не может быть какого-то логичного поведения. Из-за этого теперь у nil канала есть очень странное поведение - создание дедлоков. Зачем вообще иметь возможность создать, по сути, невалидный объект, который при любом обращении вызывает баг?
Или разница в поведении слайсов и мап. Nil слайс на практике от слайса нулевой длины ничего не отличается. Nil мапа же почему-то не может при записи аллоцировать память и теперь у такой мапы есть 2 возможных использования: 1) узнать, что ключа (любого) в этой мапе нет; 2) получить панику при попытке ключ записать. И такой потрясающий объект можно вернуть из функции ничего не подозревающему пользователю, вот он то обрадуется.
Не касательно содержимого статьи, а в целом. Надо понимать что удобство и популярность языка ещё очень сильно зависят от документации и комьюнити. И, может быть субъективно, но у раста очень токсичное комьюнити.
Это довольно неожиданное утверждение. :) Очень грустно его видеть. Обычно напротив говорят, что растовское комьюнити - дружелюбное, гораздо дружелюбнее среднего по индустрии.
А что заставляет Вас считать обратное? Вы лично столкнулись с неадекватной агрессией, когда пришли за советом? Не расскажете подробнее?
Я потому и написал, что это субъективное суждение (меня и некоторых моих друзей). Вполне допускаю что это ошибка выжившего. Я не часто по работе пересекался с Rust программистами, но был один совместный проект в пару лет длиной. Не могу чётко сформулировать свои претензии (оценка токсичности вещь относительная), но большая часть rust программистов с которыми я сталкивался оказывались не в меру высокомерными и слишком большими адептами из разряда «кроме раста другие языки не нужны», «если всё переписать на раст, то мир станет лучше», «вы тупые потому что вы не понимаете прелесть раста», «ваш с++ говно» и так далее, в таком духе.
Вот в чем точно "недостаток" (сами решайте, насколько это действительно недостаток) так это в том, что он заставляет очень критически относится к другим языкам.
После Rust я просто не смог смотреть на Golang, там слишком много вещей, которые должны были бы быть лучше. На C++ я тем более не посмотрю (о чем и в статье написал), для меня у него нет ни одного преимущества перед Rust и огромный товарный состав недостатков.
И да, мир действительно стал бы лучше, если бы все было переписано на Rust, может наконец-то избавились бы от проблем "быстрых" языков и от медлительности всех остальных.
Я вот наоборот, с Golang работаю после Rust (правда c Golang познакомился задолго до Rust).
И с одной стороны - действительно, Rust был гораздо более выразительным и первое время было сложно. А с другой - читать/изучать код стало гораздо легче.
Так что не скажу, что после Rust на другие языки смотреть невозможно. Вопрос привычки.
P.S. подобный эффект есть и если после Golang сесть за Java. Java кажется крайне многословной.
У всех свои приоритеты, мне после Rust и про Python сильно долго думать не хочется, в то тоска одолевает. Я понял, что Golang мне абсолютно не нравится когда проходил A Tour of Go и за сколько там упражнений нашел 4 возможности отстрелить себе лишнюю конечность:
возможность читать слайс после длины;
nil map, которая не позволяет делать с собой ничего полезного (хотя nil слайс на практике идентичен слайсу нулевой длины);
поведение nil и закрытых каналов;
возможность переопределять ключевые слова (знаменитое
#define true (rand() > 10) //Happy debugging suckers).
Забыли ещё нетривиальное взаимодействие между append и изменением элементов по индексу
возможность читать слайс после длины;
Можете пояснить, о чём тут речь? Вроде же, если просто индекс вылезает за границы слайса - мы сразу получаем панику, как и в Rust?
возможность переопределять ключевые слова
Опять же, это, видимо, какой-то такой ногострел, с которым я пока не сталкивался, поясните?
Счастливый вы человек, раз не знаете. Скорее всего после следующего кода настроение у вас ухудшится, так что готовьтесь.
Чтение слайса после длины
package main
import "fmt"
func main() {
s := []int{2, 3, 5, 7, 11, 13}
printSlice(s)
// Slice the slice to give it zero length.
s= s[:0]
printSlice(s)
// Extend its length.
s = s[:6]
printSlice(s)
s= append(s, 7)
printSlice(s)
// Works just fine
d := s[0:cap(s)][11]
fmt.Printf("len=%d cap=%d d=%v\n", len(s), cap(s), d)
// Obviously this panics
g := s[11]
fmt.Println(g)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s[0:cap(s)])
}
С помощью такой техники можно создавать очень веселые гайзенбаги
package main
import (
"fmt"
"math/rand/v2"
)
type SlidingWindow struct {
s []int
offset int
size int
}
func (w *SlidingWindow) next() []int {
if w.offset > (len(w.s) - w.size + 1) {
return nil
}
t := w.s[w.offset : w.offset+w.size]
w.offset += 1
return t
}
func sliding_window(s []int, offset int, size int) []int {
return s[offset : offset+size]
}
func main() {
s2 := []int{1, 2, 3, 4, 5, 6}
if rand.IntN(10) > 5 {
s2 = append(s2, 7) // panics without append
}
sw := SlidingWindow{s2, 0, 3}
for w := sw.next(); w != nil; w = sw.next() {
fmt.Println(w)
}
}
Переопределение ключевых слов
package main
import (
"fmt"
"math/rand/v2"
)
func really_big_func() (a, b bool) {
// a lot of code
// Happy debugging, suckers
true := rand.IntN(10) > 5
false := rand.IntN(10) > 3
fmt.Println(true)
fmt.Println(false)
// a lot of code
return true, false
}
func main() {
fmt.Println(really_big_func())
}
Погодите, в go операция вырезания куска массива-слайса может этот слайс расширить?! И это не баг, а документированное поведение?
Да какого хрена?!
Кстати, вот пример короче и показательнее
package main
import "fmt"
func main() {
s := []int{1, 2, 3, 4, 5, 6}
fmt.Printf("%v\n", s) // [1 2 3 4 5 6]
s = s[1:4]
fmt.Printf("%v\n", s) // [2 3 4]
s = s[1:4]
fmt.Printf("%v\n", s) // [3 4 5]
}
Погодите, в go операция вырезания куска массива-слайса может этот слайс расширить?! И это не баг, а документированное поведение?
Не просто документированное поведение, оно прямо в Golang tour описано. И не в том смысле, что не делайте так никогда, а как просто еще одна возможность языка.
В Go массив != слайс. В данном примере вы можете слайсить массив как угодно, пока вы не выходите за границы массива. Попробуйте в этом же примере создать слайс с индексами, выходящими за пределы массива с данными, получите (справедливо) панику.
Выход за длину это как раз и есть выход за границу слайса и проблема ровно в том, что паники при этом нет, она возникает только при выходе за границу capacity.
Я знаю, что массив - не слайс, но:
во-первых, слайсы играют в Go ту же роль, которую играют массивы в программировании в целом;
во-вторых, в выражение
s[1:4]синтаксически выглядит как вырезание куска из слайсаs, а не из скрытого буфера за ним.
...мда, спасибо, первое действительно проклято. Второе-то ладно, просто кто-то явно забыл про то, как JavaScript прошёлся по граблям с переопределением undefined...
В этом моя проблема с Golang, они там очень много чего "забыли","не знали" или "проигнорировали". Не то, чтобы я считал себя умнее создателей Golang, они явно делали язык под свои конкретные нужды, но когда рандом с улицы (я) может за 5 минут найти дыру в языке, который только начал изучать, то это как-то не очень.
Да, Go разрешает определять переменные с именами, совпадающими с некоторыми ключевыми словами, или именами импортированных пакетов (это называется shadowing), но любой вменяемый редактор вам это сразу покажет. Так что, что такое "true" в любом случае будет видно сразу.
Слайс -- это тип-надстройка над массивами. Не сами массивы. Это как view таблицы в базе данных.
Так что, что такое "true" в любом случае будет видно сразу.
Только что проверил, golangci-lint run игнорирует такой код (golangci-lint has version 1.55.2):
package main
import (
"fmt"
"math/rand"
)
func main() {
true := rand.Intn(10) > 5
if true {
fmt.Println("randomly true")
}
}
Видимо потому, что true - слишком незначительная часть языка для того, чтобы true было ключевым словом.
Это как view таблицы в базе данных.
Это замечательно, только вот как мне это поможет избежать (это хотя бы можно s[:3:3] починить):
https://go.dev/play/p/7dkrDMD4v9D
package main
import "fmt"
func main() {
s := []int{2, 3, 5, 7, 11, 13}
printSlice(s)
s = s[:3] // limiting len
printSlice(s)
}
func printSlice(s []int) {
s = s[0:cap(s)] // random func ignores limit
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s)
}
Или такой гайзенбаг, когда то, упадет код или тихо будет работать неправильно зависит от того, был ли слайс переалоцирован или нет:
https://go.dev/play/p/Fud-Dmdgq1u
package main
import (
"fmt"
"math/rand/v2"
)
type SlidingWindow struct {
s []int
offset int
size int
}
func (w *SlidingWindow) next() []int {
if w.offset > (len(w.s) - w.size + 1) {
return nil
}
t := w.s[w.offset : w.offset+w.size]
w.offset += 1
return t
}
func sliding_window(s []int, offset int, size int) []int {
return s[offset : offset+size]
}
func main() {
s2 := []int{1, 2, 3, 4, 5, 6}
if rand.IntN(10) > 5 {
s2 = append(s2, 7) // panics without append
}
sw := SlidingWindow{s2, 0, 3}
for w := sw.next(); w != nil; w = sw.next() {
fmt.Println(w)
}
}
Я бы ещё добавил любовь к "программированию в комментариях". Вот уж просто минное поле.
Вот за эти высказывания вас и не любят. Скромнее надо быть :)
На несколько сообщений выше сообщество раста уже с геями сравнили за то, что "посмели" рассказывать о преимуществах своего языка. Просто для некоторых людей "токсичное" это обозначает "всё, с чем я не согласен, включая то, что я считаю навязыванием хорошего поведения".
Тут скорее зависит не от факта согласия-несогласия, а от того, в какой форме он подается
А с формой-то что не так?
Вот взять обсуждаемый пост. Вроде нормально написан же, но в комментариях всё равно упомянули токсичное сообщество. Получается что ни напиши про Rust - обвинений в токсичности не избежать. Точно ли именно Rust тут токсичен?
Ну так оно действительно токсичное. Даже автор данного поста допускает заявления типа "мир действительно стал бы лучше, если бы все было переписано на Rust".
Столь радикальные заявления это какой то детский максимализм или рвение неофитов, и у кого то вызывает лишь улыбку, а у кого то сомнения в адекватности этих коллег...
Будет ли специалист по нейросетям, разрабатывать нейросети на rust? Сильно сомневаюсь. В данной задаче язык при помощи которого загружаются данные и выводятся результаты вообще не критичен и тот же Python подойдет лучше, просто за счет того его проще изучить.
Можно ли парсер логов сделать на расте? Да. Он будет быстрым? Да. Будет ли он столь же понятен изящен и лаконичен как на питоне или прости господи perl. Полагаю нет.
Можно ли обработчик прерывания написать на раст? Можно (спасибо Филиппу Опперману). Будет ли он лучше в этом обработчика на С или ASM? Нет.
Думаю смысл вы уловили, есть около 7000 языков программирования каждый создавался для своей области применения, у каждого свои достоинства и свои недостатки, а заявления типа "твой любимый язык программирования отстой, а вот в раст..." ну выше уже вроде написали, что о таких персонажах думают.
Будет ли специалист по нейросетям, разрабатывать нейросети на rust?
Работаем потихоньку, вот примеры от самых хайповых компаний индустрии: https://github.com/openai/tiktoken, https://github.com/huggingface/candle, и в целом. Не смотря на все заявления "да питон там только клей для сишных библиотек, он ни на что не влияет" именно питон часто становится ботлнеком, даже при запуске тяжёлых нейронок, вот так да.
Можно ли парсер логов сделать на расте? Да. Он будет быстрым? Да. Будет ли он столь же понятен изящен и лаконичен как на питоне или прости господи perl. Полагаю нет.
Думаю, вы сильно удивитесь, но Rust - это один из лучших языков для написания парсеров. Наличие нормальных енумов и довольно продвинутого pattern matching'а позволяет как очень легко описывать токены, так и легко разделять логику парсера под разные токены.
Так а токсичность-то в чём? Простая же логика: язык A позволяет допустить класс ошибок N, а язык B - N-5 (условно). Если переписать программы с A на B, количество ошибок уменьшится. Меньше ошибок - лучше мир. Ну допускает автор такие вполне логичные (ему и мне и ещё некоторым людям) мысли, и что?
А вот взять ваш комментарий, так уже в третьем предложении началось "детский максимализм или рвение неофитов", "сомнения в адекватности этих коллег...".
Но токсик именно автор, а не вы, ага
Серьёзно? Это и правда очень интересное утверждение. Приведите, пожалуйста, примеры конкретные в сравнении с аналогичными ситуациями в комьюнити других языков? Мне наоборот показалось там все такие няши, что аж не верится и Линуса на них нет)
Не могу говорить за все Rust сообщество, люди там разные и бывает всякое, я точно помню как минимум несколько довольно крупных скандала в Rust комьюнити, но с другой стороны я не знаю ни одного сообщества, где не было бы ни одного скандала вообще.
Обычно, если нужна какая-то помощь, то тут и помогут, и объяснят разные варианты с их плюсами и минусами или почему это плохая идея. В обычном общении я не видел примеров токсичного поведения.
Абсолютно токсичное по отношению к остальным, сами они этого не видят. Невероятно много контента от различных авторов и комментаторов с +- одним тезисов "А Rust лучше...". Язык может и не плохой и место для него найдется. Но ребята напоминают секту, а цель этой секты весь мир на Rust переписать. А для меня например, т.к я не пишу на rust, некоторые примеры из этой статьи абсолютно не читабельны, хоть и местами смахивает на кресты. Охотно верю, что проблема в отсутствии привычки и наметанного глаза к такому синтаксису. Но многие другие языки мне удавалось читать и понимать без знаний. Например Go отлично читается любым разработчиком знакомым с С подобным языком, почти любая конструкция будет очевидной.
Мне кажется, перебор с символами пунктуации в синтаксисе языка: .|&*::-><(),_>>()?;
Это в коде еще lifetime-ов не было, количество знаков пунктуации удвоилось бы.
Существенная доля этих символов - желание сохранить определённую преемственность от C/C++, чтобы облегчить мало знакомым с Растом людям понимание кода.
Но важнее, пожалуй, понять какие есть альтернативы? Использование ключевых слов удлинило бы программу, сделав её набор медленнее, а текст менее наглядным. Вот взять тот же самый "?" - это же синтаксический сахар, который заменяет достаточно длинный код, делающий корректную обработку ошибок существенно менее напряжной!
От круглых скобок в if'е избавились - в отличие от многих языков программирования, они в Расте не обязательны (т.е. "if x > 0", а не "if ( x > 0 )" ).
От фигурных скобок можно было бы избавиться методом Питона.
От круглых скобок в функциях одного аргумента теоретически можно попробовать избавиться, но если аргументов более одного?
Мне очень интересно было бы увидеть подходы, за счёт которых можно было бы избавиться от лишних символов, одновременно увеличив выразительность кода!
Меня не особо волнует синтаксис как таковой, не Brainfuck и ладно. К любому синтаксису привыкаешь за 2 недели. Мне гораздо важнее то, что с помощью этого синтаксиса можно сделать.
Вам кажется
Появилось впечатление, что Rust сравнивался в 1ю очередь с Python. И после Python он оставил приятные впечатления.
В целом я могу согласиться, что Rust оставляет приятные впечатления. Своим синтаксисом, своими возможностями, своими абстракциями... Но это справедливо для небольших проектов. Для большого я бы его не брал. На Rust очень сложно писать - постоянно приходится бороться с компилятором. Но читать готовый код - еще сложнее. Макросы, сложный код, не всегда можно найти реализацию конкретного метода. Далеко не все библиотеки хорошего качества, что усложняет работу и так с непростым инструментом.
Лично я для большого проекта брал бы язык с более очевидным синтаксисом (и пускай с не такими чистыми абстракциями). Например, тот же Golang.
P.S. Да, статью "что не так с Golang" я бы почитал.
Но это справедливо для небольших проектов.
Как раз наоборот, Rust в полной мере раскрывается в больших, сложных или долгих проектах! Как раз основная мысль статьи в том, что Rust намного проще рефакторить, что наиболее важно как раз в больших проектах. В Rust компилятор не враг, чтобы с ним бороться, это лучший друг, которых покажет на ошибку на самом раннем этапе разработки.
К сожалению, у меня нет личного опыта подобных проектов в Rust. Мое мнение о Rust основано на опыте больших проектов в других языков, но о больших проектах говорят в Fast Development In Rust, Part One, Beyond Safety and Speed: How Rust Fuels Team Productivity, Grading on a Curve: How Rust can Facilitate New Contributors while Decreasing Vulnerabilities и нескольких реддит постах из начала статьи, так что мне кажется, что моя экстраполяция вполне валидна.
Лично я для большого проекта брал бы язык с более очевидным синтаксисом
Выше я уже отвечал, для меня синтаксис не играет большой роли. Rust позволяет мне выражать мои идеи в коде без необходимости неделю думать о UB, том, что надо создать тип Nothing чтобы отделять разные типы пустых значений и т.д.
Да, статью "что не так с Golang" я бы почитал.
Это скорее шутка, у меня, все же, слишком мало опыта в Golang, буквально 2 недели попытки его выучить и пара месяцев обсуждений с друзьями "как так оказалось, что в Golang все настолько плохо". Просто когда в официальном курсе на официальном сайте Golang я умудрился задуматься "хм, кажется это какой-то бред" (и при этом я оказывался прав) раза 4.
Но уже много кто написал такие статьи, я рекомендую I want off Mr. Golang's Wild Ride, Lies we tell ourselves to keep using Golang, They're called Slices because they have Sharp Edges: Even More Go Pitfalls, Golang is not a good language.
Для примера добавлю сюда примеры кода, который вызывает у меня вопросы в духе "а хоть кто-то при разработке над чем-то кроме GC и async рантайма думал вообще?":
Заголовок спойлера
package main
import "fmt"
func main() {
s := []int{2, 3, 5, 7, 11, 13}
printSlice(s)
// Slice the slice to give it zero length.
s= s[:0]
printSlice(s)
// Extend its length.
s = s[:6]
printSlice(s)
s= append(s, 7)
printSlice(s)
// Works just fine
d := s[0:cap(s)][11]
fmt.Printf("len=%d cap=%d d=%v\n", len(s), cap(s), d)
// Obviously this panics
g := s[11]
fmt.Println(g)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d %v\n", len(s), cap(s), s[0:cap(s)])
}
package main
import (
"fmt"
"math/rand/v2"
)
type SlidingWindow struct {
s []int
offset int
size int
}
func (w *SlidingWindow) next() []int {
if w.offset > (len(w.s) - w.size + 1) {
return nil
}
t := w.s[w.offset : w.offset+w.size]
w.offset += 1
return t
}
func sliding_window(s []int, offset int, size int) []int {
return s[offset : offset+size]
}
func main() {
s2 := []int{1, 2, 3, 4, 5, 6}
if rand.IntN(10) > 5 {
s2 = append(s2, 7) // panics without append
}
sw := SlidingWindow{s2, 0, 3}
for w := sw.next(); w != nil; w = sw.next() {
fmt.Println(w)
}
}
package main
import (
"fmt"
"math/rand/v2"
)
func really_big_func() (a, b bool) {
// a lot of code
// Happy debugging, suckers
true := rand.IntN(10) > 5
false := rand.IntN(10) > 3
fmt.Println(true)
fmt.Println(false)
// a lot of code
return true, false
}
func main() {
fmt.Println(really_big_func())
}
package main
type Container struct {
a int // old field
Items map[string]int32 // new field
}
func (c *Container) Insert(key string, value int32) {
c.Items[key] = value
}
func main() {
c := Container{a: 2}
c.Insert("number", 32)
}
Я наоборот слышал, что рефакторить сложно Rust. Особенно если где какой тип поменять надо (или его обертку). Но тут лично за себя отвечать не буду - лично не участвовал в больших рефакторингах c Rust (хотя и очень косвенно наблюдал, и по сложившемуся впечатлению - это было "больно").
Но должен сказать, что рефакторинг - в любом языке не самая простая задача. Хотя он может быть достаточно безболезненен, если код хорошо покрыт тестами.
В Rust компилятор может и друг, но далеко не всегда можно понять "а что же тебе не хватило". И в таких ситуациях лучший подход - запустить пустой проект и там последовательно воспроизвести работающий код, чтобы понять "а почему это работает".
Вопрос с большим проектом не в синтаксисе, а в читаемости кода - чуть ниже расписал. UB и Nothing - не такие уж и большие проблемы на практике, я бы сказал (уточню, что с C/C++ я очень мало работал).
"хм, кажется это какой-то бред" у меня возникал и при чтении Rust book. Но уже не вспомню толком на какие моменты.
Тип менять больно в любом языке, в котором есть типы. Rust тут, напротив, хорош возможностью заранее "подстелить соломку" в виде псевдонима для типа (type alias) - в таких языках как C# даже это невозможно (и ничего, как-то рефакторим код).
Честно скажу, этот аргумент именно что слышал в каком-то обсуждении, по существу, из своего опыта, не могу ни подтвердить, ни опровергнуть.
P.S. А рефакторить тип в языках, где нет типов - это еще веселее )))
P.P.S. Да, я знаю что "нет типов" говорить некорректно. Динамическая типизация не исключает типы.
Я бы даже сказал, что лучше не лениться и для такого использовать паттерн New Type. Это позволяет гарантировать, что невозможно вместо старого типа использовать новый. Да, иногда приходится реализовывать базовые операции над типами заново, но гарантии того стоят.
У меня в моем трассировщике как раз есть такой пример: в оригинальной статье на C++ использовались как раз алиасы для color, vec3 и point3. Я не поддаваться на эту легкость и сделал три независимых типа (заодно узнал, как писать свой derive чтобы не копипастить базовые операции над типами).
Особенно если где какой тип поменять надо
Как раз пример из статьи (где я менял t64 на свою обертку над u8), как мне кажется, должен показать, что это как раз очень просто. Компилятор сразу выдаст все места, где надо поменять тип и его невозможно забыть его поменять - программа просто не скомпилируется. Для Rust компилятор - это как набор встроенных тестов, которые гарантируют, что типы везде сошлись. Конечно, тесты на логику работы лишними точно не будут, но это уже отрезает огромную пачку возможных проблем.
Но это справедливо для небольших проектов. Для большого я бы его не брал.
Вот это высказывание меня тоже несколько удивило... По-моему, Rust как раз в первую очередь предназначен для больших проектов, в нём значительная часть фич именно на большие проекты заточены. "Борьба с компилятором" (которая с накоплением опыта исчезает, кстати), в частности, как раз помогает получить поддерживаемый код, который не "развалится" при росте кодовой базы.
Моя основная претензия к Rust - его сложно читать. Сложно изучать код библиотек, особенно если библиотека не лучшего качества. Сложно погружаться "а что там внутри происходит" при отладке, особенно если там - макрос на макросе и макросом погоняет.
Именно этот фактор ограничивает, на мой взгляд, применение Rust в больших проектах.
"Борьба с компилятором" - да, со временем становится легче, не спорю. Особенно если к одному проекту более-менее привык и уже знаешь, как с ним работать. Но не могу сказать, что этот фактор пропадает совсем. И я понимаю, что "борьба с компилятором" vs "борьба с плавающими багами" - уж лучше компилятор помучить.
Про сложность ревью кода в Beyond Safety and Speed: How Rust Fuels Team Productivity говорил Lars Bergstrom. По внутренним опросам в Google android, 50% опрошенных сказали, что код на Rust проще проверять (возможно, что это по сравнению с C++ и тогда это не то, чтобы сильно впечатляюще). Так что это дело просто привычки, вместо поиска скрытого UB можно сконцентрироваться на других вещах.
Почему мне не сложно читать код библиотек на Rust? Я профессионально программирую на Rust уже более 5 лет. Но даже в первый год его изучения я прочитал СТОЛЬКО чужого кода в библиотеках, сколько не читал за предыдущие 10 лет. Так что не спешите обобщать свои выводы на всех.
Не знаю. Может попадалось слишком много библиотек с обилием макросов и кодогенерации. Так-то простой код Rust вполне читаем, вопросов нет.
Может не всегда понятно как именно он работает в деталях (с учетом трейтов и прочей магии шаблонов Rust), но что именно в нем происходит - вполне понятно.
Я вообще не программировал на Rust всерьёз, но мне тоже не составляет труда прочитать код на этом языке.
Мне кажется, борьба с компилятором – это хорошая возможность избежать проблем в проде. В основном, это ошибки про заимствования.
Я в основном пишу сейчас на Go, но с некоторыми вещами все еще не свыкся (внимание, дальше идет только очень субъективное ощущение):
После Rust - это наличие нулевых указателей. Так что это с большой долей вероятностью вылетит в рантайме и в проде.
Нет разделения mutable/unmutable указателей.
defer решает часть проблем, но не снимает их. Например, легко представить ситуацию, когда взял lock но забыл прописать defer на освобождение.
Лбв к скр им п.
Система импортов кажется топорной, не знаю как лучше объяснить.
Использование первого символа названия для определения публичности.
Обработка ошибок очень топорная и ограниченная.
Да, я тоже с Golang работаю после Rust (правда c Golang познакомился задолго до Rust). И со всеми пунктами согласен.
Но с опытом пришло понимание, что "чем проще - тем лучше". И Golang - это именно что простой язык. Он далеко не идеальный, но за счет простоты - я могу ему простить это.
P.S. сильно веселее было раньше, когда у Golang не было еще и менеджера зависимостей )
Система импортов кажется топорной, не знаю как лучше объяснить.
А как это проявляется?
Это все субъективно, может быть в чем-то ошибаюсь, но вот что не очень нравится и кажется топорным:
Между файлами одного пакета все испортируется в неявном виде из разных файлов
Тесты обычно описываются отдельным пакетом и несмотря на то что лежит это в одной директории, импортировать и протестировать не публичный метод невозможно
Нельзя импортировать конкретные имена из пакета, можно импортировать либо сам пакет либо все его содержимое.
Нет реэкспорта
Вполне стандартная тема для многих языков. Тот же C# шарит все внутри одного неймспейса между файлами. В Go есть одна вещь, которая сильно улучшает читабельность - можно однозначно отличить, откуда символ пришел. Если у него нет идентификатора пакет, то это локальный символ из текущего пакета (опускаем dot-imports, которыми никто не пользуется). Иначе, всегда будет идентификатор пакета и по импортам ясно, откуда он пришел. Теже шарпы или Java читать намного сложнее, потому что при импорте все символы, как правило, доступны напрямую без необходимости писать идентификатор неймспейса. И хер ты без IDE поймешь, откуда взялся тот или иной класс.
Не знаю, где обычно, но обычно как раз все пишется в одном пакете. В отдельный пакет выносятся тесты обычно для так сказать более строго отделения от подробностей реализации (и поэтому очень полезно, что ты не можешь непубличный метод достать. В этом вся фишка), либо по каким-то объективным иным причинам. Например, интеграционный тесты часто туда уносят, т.к. обычно это целая гора никак не связанного с основным приложением кода. Порой еще выносят это в отдельный го модуль, чтобы не тянуть ненужные зависимости в основной бинарь.
А зачем это нужно? Ты либо импортируешь пакет, либо нет. К пакету всегда обращение через его имя, поэтому пофиг, сколько десятков тысяч символов в нем. И читается это всегда однозначно
А зачем это нужно? Ты либо импортируешь пакет, либо нет.
Для разрешения конфликтов имён. И уменьшения числа потенциальных конфликтов.
Каких конфликтов? Все внешние символы всегда используют полный квалификатор с указанием имени пакета, что как раз исключает конфликты имен. Есть проблемы только с пакетами с одинаковым именем, для чего есть переименование при импорте.
Так на словах совершенно не ясно, о каких конфликтах речь. Нужен пример. Вот в шарпах могу представить, где символы прям напрямую импортируются обычно и обращаешься к ним так, будто они у тебя локально в неймспейсе лежат.
Возникающих при dot-imports, которыми никто не пользуется.
Угу, ими и не надо пользоваться. Ниразу не видел их использования. Ни в своих проектах, ни в каких-либо зависимостях, которые смотрел сорцы. Если еще примут пропозал об их удалении из языка, то будет совсем замечательно.
У вас больше вопрос к разработке и опыту с ide, которые подерживают rust все лучше с каждым годом, но все еще не очень по сравнению с Java/Kotlin/C#. JetBrains уже отдельную ide для rust выкатили RustRover но еще в альфа релизе. А rust компилятор выводит довольно хорошие подсказки для новичков. Тем не менее после полугода работы с языком понимаешь сам без помощи компилятора, когда код собирется и как писать нужно т.е становишься продуктивнее и в плане чтения кода тоже. Библиотеки конечно бывают разные, ваша правда) Но потенциал развития довольно большой. Все частоиспользуемые либы вроде сериализаций(serde), веб фреймворков уже довольно хороши. Касательно больших проектов. Большая часть бэкенд сервисов одной крупной криптобиржи написано на rust https://blog.kraken.com/product/engineering/oxidizing-kraken-improving-kraken-infrastructure-using-rust и воочию выглядели неплохо.
Не знаю на счет RustRover, но раньше их плагин Rust основывался на LSP. И с момента прихода rust-analyzer взамен RLS стало намного лучше.
Но большой разницы с той же VS Code я не увидел - LSP и там и там.
Да, стандартная библиотека, крупные и популярные либы - выглядят очень неплохо (подозреваю, это и было фактором, определившим их популярность).
Опять же, подсказки, в большинстве, своем очень хорошие, спору нет. Но не всегда из них можно понять что именно не так и как это исправить.
После полугода с языком - может некоторое число проблем с компилятором и уходит, но не исчезает полностью. И заранее предсказывать мне так и не удавалось. Возможно тут сыграл фактор, что я работал над множеством небольших и разноплановых проектов (в большинстве своем), а не над одним большим. И к каждому проекту привыкать надо отдельно - а общего навыка под множество либ и их особенностей так и не выработалось за это время.
Большой проект из множества микросервисов - это не тоже самое, один большой монолит )
С микросервисной архитектурой Rust прекрасно справляется, спору нет. Микросервисы писать на Rust - одно удовольствие, могу подтвердить.
Не стал уточнять сразу - но в микросервисной архитектуре я Rust вполне вижу. Он действительно очень удобен в таком виде, а этап привыкания и борьбы с компилятором и либами достаточно небольшой.
Правда размер бинарников (debug), объем артефактов сборки (десятки и стони гигов), длительность компиляции (я понял, зачем мне 16 ядер и 64Gb RAM) - могут сыграть не в пользу Rust и тут ))) Но это больше вопрос техники.
раньше их плагин Rust основывался на LSP.
У них уже довольно давно своя реализация, не rust-analyzer.
Возможно.
Я скорее основываюсь на впечатлениях, а не на твердом знании "что там под капотом".
Во времена VS Code с RLS существенной разницы c Rust-плагином я не увидел (возможно совсем небольшое преимущество было за JetBrains - деталей не помню).
Во времена VS Code с rust-analyzer существенной разницы c Rust-плагином я не увидел.
В переходный период Rust-плагин JetBrains отставал, как отставал RLS от rust-analyzer.
Но я все возможности досконально не сравнивал - только подсветку типов, да авто-дополнение (то, с чем работаешь больше всего и что можно быстро сравнить). В идеале, конечно, надо было погонять IDE "и в хвост, и в гриву", для формирования более целостного впечатления.
И да, это было достаточно давно - как там сейчас обстоят дела я не скажу.
В плане веба большой монолит чаще (но не всегда) считается плохой практикой. Но вот самый большой проект на rust в одном репозитории (не веб), что я знаю это сам компилятор языка. Там по сути много маленьких crates, которые прилинкованы к корневому workspace. Кажется что лепить что-то большое можно, хоть я и не пробовал лично)
В плане "железа" для rust проектов экономить не приходится. Ведь если с нуля, то компилируются все все зависимости.
"Большой монолит" когда-то был достаточно безальтернативной практикой )
Микросервисный подход получил популярность "всего лишь" лет 10 назад... Лишь с появлением и развитием Docker он стал популярен - когда управлять кучей сервисов стало сильно проще.
Впрочем, и сейчас монолит может сильно выиграть в плане производительности - так что его век может еще и вернется...
В плане артефактов сборки - проблема усугубляется тем, что под разные версии компилятора и под разные версии зависимостей - зависимости компилируются в отдельные файлы. Поэтому со временем target только растет. А уж если использовать свежие ночные сборки компилятора...
P.S. а еще есть очень холиварный вопрос - когда микросервис перестает быть микро?
Впрочем, и сейчас монолит может сильно выиграть в плане производительности
Согласен, согласен. Тут общего мнения нет. It depends.
В плане веба большой монолит чаще (но не всегда) считается плохой практикой.
Что бы холивары не разводить, поэтому так и выразился) "Маленький/средний монолит" точно считаю нормой.
когда микросервис перестает быть микро?
А это вечный вопрос)
когда микросервис перестает быть микро?
Когда он становится монолитом?
Если вам действительно интересно и вы не хотите просто потролить.
То есть к примеру классификация Amazon где они делят все существующие решения на monolithic, SOA (сервисы) и microservices(микросервисы) и описывают где проходит грань с примерами. Естествено я допускаю что классификаций много и мнения есть другие. По этому это вечный вопрос)
А вот насчёт безальтернативности - не факт. К примеру, в той же WS-Addressing такая штука как Reference Parameters идеально подходит для передачи контекста запроса между микросервисами. Не могли же её придумать с потолка? Значит, нечто похожее на микросервисы писалось, пусть и называлось по-другому.
Могу добавить, что в CLion/RustRover была проблема с macro expansion (на примере библиотеки RTIC). Как сейчас в Nova/RustRover не тестил, подозреваю что проблемы с автокомплитом остались, в VSCode это всё из коробки работало.
Безотносительно Раста, такие статьи, подсознательно относишь как к рекламе Гербалайфа. Слишком хорошо, что бы быть правдой. Автор, конечно же не виноват, но...
Нет причин не проверить это самостоятельно, за Rust ни в какой форме денег не берут)
P.s. если кто-то хочет мне платить за рекламу Rust (хотя бы шоколадными медальками) то пишите в личку!
шоколадными медальками
Уже после этой статьи риск заработать себе диабет был бы невероятно высок, я б не торопился с шоколадными медальками)
На самом деле, поделюсь идеей. Мне как и многим было бы интересно увидеть эксперимент от Rust разработчика, по переходу на C++(Не C и не C с классами).
Хотя бы пару месяцев его по изучать, и попытаться что-то написать. Потом сделать статью с выводами и сравнением с родным языком.
Такая мысль появилась т.к практически все кто сравнивают Rust с C++ или не дай бог с C/C++(😁) не состоят в хабе C++, и по всей видимости никогда на нем ничего серьезного не писали. Это действительно было бы интересно.
риск заработать себе диабет
Уж лучше диабет, чем расстройство нервной системы. Да и не думаю, что в статье о переходе Rust -> С++ есть большой смысл. Я гарантирую, что мой C++ код будет ужасен и состоять из UB процентов на 70. Только это не докажет, что Rust лучше (или C++ хуже), а только то, что я лично не умею писать код на C++. Что очень легко прочитать, как "Rust разработчики не умею писать код на C++", что в свою очередь можно прочитать, как "Rust разработчики не умею писать код". Это уже тут в комментариях происходит, что же будет в такой специализированной статье.
Вот обратное было бы интересно. Опытный C++ разработчик пишет некий сервис на C++. Потом N месяцев учит Rust и пишет аналогичный сервис на Rust. Там можно сравнить и код, и ощущения разработчика.Я бы такое почитал. Вообще такое сделал Google и результаты для C++ неутешительные.
Вообще такое сделал Google и результаты для C++ неутешительные.
Еще бы выступавший на Rust Nation сказал что-то другое :))) Его бы туда просто не пустили. Могу сказать свои ощущения (я могу свободно писать на C++ и на расте, и еще на ряде языков) - для себя я практически не нахожу применения для раста. Он мне после C++ банально не удобен и не выразителен. Пропагандировать что-то и навязывать кому-то свое мнение я не хочу, но оно вот такое.
P.S. А, вот даже нашел свой давнишний комментарий на эту тему. С тех пор принципиально ничего не поменялось - применений для раста в своих разработках по-прежнему не вижу.
Смысл не в переходе на C++, а в том чтоб стать лучше как разработчик и поделиться опытом с остальными.
Пока что, вы доверяете собственное мнение чужим людям. И используете ссылки на мнение других людей, как аргумент, прочёл все комментарии тут.
Ну а UB в 70%, это просто странно. Используйте безопасные типы, которые предназначены для решения Ваших кейсов и все будет работать не хуже любого другого языка. Не доверяете кому-то и даже STL, пишите сами (чего делать не нужно, но можно).
У C++ много проблем, особенно что касается сборки и линковки, геморрой ещё тот. Смотришь на то как это реализованно в молодых языках, и проступает скупая слеза. Но я практически не увидел людей ссылающиеся на эти проблемы в своих доводах о преимуществе Rust.
Но я практически не увидел людей ссылающиеся на эти проблемы в своих доводах о преимуществе Rust.
Это просто само собой разумеющееся :)
вы доверяете собственное мнение чужим людям
Не вижу, что в этом плохого. Начиная от того, что мы и так доверяем огромному количеству людей, разработчики Rust тут точно даже не в первой сотне по значимости, заканчивая тем, что да, я доверяю чужим людям. И если это доверие нарушено я перестану и постараюсь переосмыслить то, чему у них доверял.
Используйте безопасные типы
Чтобы использовать безопасные типы надо знать, какие из типов безопасны, а у меня опыта нет.
Но я практически не увидел людей ссылающиеся на эти проблемы
Можете посмотреть тут, тут или тут
Про эти проблемы я читал десятки раз и я не хочу делать свою статью трехтомником для того, чтобы в неё вошли все возможные плюсы, минусы и подводные камни Rust, сравнение со всеми возможными языками, состояние экосистемы во всех нишах и т.д. Если вас это интересует, я могу вам гарантировать, что при недолгом поиске вы это найдете.
Ну я вот с плюсов ушёл на Раст, потом недавно пробовал на них писать. Очень боялся связываться с итераторами, они капец не удобные и с ними очень легко застрелиться. И в итоге все через циклы и индексы делал.
Ну и тулинг, конечно, добавил геморроя, но хотя бы зависимости через Nix получилось ставить, хоть что-то. Но даже новомодный Meson довольно сложный в настройках.
C/C++
(Naked Gun facepalm) - уважаемые эксперты в языках программирования, вы можете писать два РАЗНЫХ языка программирования раздельно? Удручает, что читатель в вводится в заблуждение таким образом. Язык C++ содержит только небольшую часть языка С (к сожалению приводящую к проблемам, когда используется не для легаси кода). Сам язык раскрывается именно, когда грамотно используются другие его части(под-языки):
Классы
Шаблоны
Метапрограммирование
см. C++ Core Guidelines и интервью Бьярна Страуструпа.
Не переживайте вы так, просто в процессе редактирования мне очень захотелось убрать C и/или C++ (а до редактирования этого было гораздо больше).
И да, эта сноска есть в статье, но она под двумя спойлерами. Из меня эксперт в языках примерно такой же, как и из табуретки. Я даже не уверен, кто сможет на большее количество вопросов правильно ответить.
Как удобненько, 40 лет говорить про возможность скомпилировать С компилятором С++ (99% кода), но как только говорят о C/C++ - так это же "как это?? как вы могли?!". Отвратительное лицемерие.
возможность скомпилировать С компилятором С++ (99% кода),
Современный C и подмножество C в C++ уже давно разошлись, и так делать нельзя. Не, ну если очень хочется, то можно, но результат вас может не порадовать. И это даже не про новые ключевые слова в свежих версиях C, нет, из самого простого, но неявного: type puning через union допустим (и очень часто используется) в C, но в C++ он является undefined behaviour потому что нарушает active member rule.
А "40 лет" обычно говорят не про "возможность компилировать", а про "возможность использовать" код библиотеки/модуля на одном языке в программе/модуле на другом языке (интероперабильность по ABI) и про лёгкую адаптацию кода если надо перенести фрагмент из одного проекта в другой (хотя вероятно такой код окажется кривым и не идиоматическим).
где вы были 40 лет?
извините
но я её так и не дочитал до конца, не говоря уже о том, чтобы «выучить» C. Как ни странно, но «виноваты» в этом холивары на хабре.
Так вот кто топит за новомодные языки и кидается фекалиями в Си. Те, кто его даже не удосужились выучить и не писали на нем ничего сложнее hello world.
Но еще больше резанули слова про хабр и холивары. Да, это эйджизм и субъективщина, но когда я представляю себе человека, делающего первые шаги в Си, до появления на свет Хабра еще лет 10—15 впереди. А тут человек добрался до Си когда Хабр не только появился на свет, но и на нём успели наплодить холиваров: то есть буквально вчера он начал программировать по меркам срока существования Си. Но уже занялся агитацией против Си.
И вот что я думаю: это поколенческое. Каждому новому поколению свойственно демонстрировать протест против предшествующего поколения: а мы слушаем другую музыку, а не это ваше старперское говно, а мы одеваемся по другому, а у нас свой непонятный родителям молодежный сленг. Такой вот бунт поколения против предшествующего поколения. И мне кажется, что появление за последние 10—15 лет кучи новых ЯП, про которые раньше никто слышать не слышал, это такой же бунт против предыдущего поколения. Мы разрушим цивилизацию наших предков и на обломках построим новый модно-молодёжный мир. И весь софт и все ОС перепишем на Rust'е, а куда не дотянется Rust — на Python'е конечно же (даром что ли реклама его курсов вставлена даже в видео про садоводство?). Заодно избавимся от мерзких master/slave, а красно-черное дерево переименуем в красно-афроамериканское. Просто подросло новое поколение программистов, и им массово чуется, что Си это язык старперов. Ну как мы можем программировать на том же, на чем программировали 35 лет назад? Это же как в 2024 ездить на машине 80-го года выпуска... Вот и начинается поиск или изобретение чего-то, что придало бы собственной идентичности и позволило бы иметь меньше общего с «динозаврами». Под соусом борьбы за все хорошее и против всего плохого, конечно же, хотя мотивы, как мне все больше и больше кажется, тут совсем другие.
Так это и в обратную сторону работает. Сидят "деды", медленно заростают мхом, а мир вокруг для них развивается слишком быстро, потому что нейроны в голове уже не настолько эффективно складываются в новые цепочки, как раньше, а тут ещё и молодёжь на пятки наступает — при таких вводных сложно признать, что какие-то "новомодные штуки" доказали свою жизнеспособность и имеют существенные преимущества перед старыми, проще обвинить во всем эйджизм и "бунт поколений во имя идентичности".
развивается
жизнеспособность
Раковая опухоль тоже развивается, и тоже показывает жизнеспособность. Демонстрация обоих этих факторов ещё не означает, что явление в целом хорошее.
Как удобно вы пропустили часть про "имеют существенные преимущества"
С точки зрения раковой опухоли она тоже имеет массу преимуществ по сравнению с обычными клетками. Те — просто жалкие отсталые тормоза в её парадигме.
Вы настолько ударились в свою дешёвую демагогию что полностью отошли от темы дискуссии.
«Существенные преимущества» — это субъективная категория, в отличие от «развивается» и «показывает жизнеспособность».
У каждого своё понимание существенных преимуществ. По мне так у Си есть существеннейшее преимущество, которое перешибает вообще всё на свете — ему сто лет в обед. Это как арабские цифры. Ими все пользуются, они укоренились в своей нише.
И тут приходит Вася Пупкин с тезисом «ваши арабские цифры гадость, потому что 3 похоже на 8, и это может иметь далеко идущие печальные последствия, и вот смотрите какие хорошие новые цифры я предлагаю вам — давайте все дружно переходить на их использование». Лет 15 назад таких революционеров посылали подальше, крутя пальцем у виска, а сейчас (увы и ах) ситуация поменялась: Вася Пупкин, агитирующий за за новые прекрасные пупкинские цифры вместо старых убогих арабских, не просто приходит, а ещё говорит: «смотрите, за мной стоит нетоксичное коммьюнити, и нас уже миллион».
Однако арабские цифры именно что пришли не на пустое место и укоренились, потому что имели существенные преимущества.
Возможно, вы думаете, что всё на свете продвигается только за счёт того, что кому-то заняться больше нечем, чем продвигать что-то новое только потому что оно новое, а не потому что новое действительно имеет преимущества (и, кстати, всё равно требует продвижения, даже с преимуществами), но это не так. Люди вкладывают усилия и энтузиазм только когда верят в это.
Да, но чтобы отнести некоторое явление к классу "раковых опухолей" - этих факторов тоже недостаточно. И даже личной неприязни к ним - тоже.
А тут человек добрался до Си когда Хабр не только появился на свет, но и на нём успели наплодить холиваров: то есть буквально вчера он начал программировать по меркам срока существования Си. Но уже занялся агитацией против Си.
Извините, а где вы тут увидели агитацию против Си? Или тут работает подход "кто не с нами, тот против нас", и агитация за любой другой язык равна агитации против Си?
Как же «где?»
В словах, что автор его так и не выучил (дескать, сложный), в словах про холивары (дескать, много отрицательных мнений), в словах про жонглировать бензопилами (дескать, даже не суйся — беда практически неминуема).
Вкладываете свои домыслы в чужие уста.
То есть если гипотетический я не смог выучить Си - я не имею права об этом говорить, потому что это будет агитацией против Си, а агитировать против Си могут только те, кто его знает в совершенстве?
Интересно, а это с любым языком работает, или только с Си?
Зачем вы передёргиваете?
Статья же не о том, что «я не смог выучить Си, пожалейте меня». И не о том, что «я не смогу выучить Си, зато смотрите, какие вещи я могу вытворять в баш-скриптах» (Си и баш-скрипты имеют разные ниши применений). А вот когда у инструментов почти одинаковые ниши применений и они рассматриваются как конкуренты, высказывания типа «я не смог овладеть X, зато смотрите какая прелесть этот Y» это именно что агитация за Y и против X.
И что плохого в агитации основанной на фактах? Даже "я не смог совладать с Х, а смог с Y" -- это факт, говорящий о том, что людям похожим на автора Y будет проще освоить, чем X.
Почему вы это воспринимаете в штыки? "Я вот освоил X и у меня ничего не болит, значит Y -- фигня" -- это у кого тут ещё агитация получается :)
Хорошо, уточню вопрос.
То есть если гипотетический я не смог выучить Си, но смог выучить Rust - я не имею права об этом говорить, потому что это будет агитацией против Си, а агитировать против Си могут только те, кто его знает в совершенстве?
Интересно, а это с любой парой однонишевых языков работает, или только с Си и Rust? Могу ли я "затыкать" любых комментаторов-сишников словами "не смейте агитировать против Rust пока сами его не выучите"?
если гипотетический я не смог выучить Си, но смог выучить Rust
Сама ситуация (даже гипотетическая) — уже надуманная, потому что Си чрезвычайно прост (и этим и хорош), Раст значительно сложнее. Поэтому это звучит как «представим число, которое меньше 10, но больше миллиона».
Но окей, представим, что так.
Имеете права писать о своих успехах в освоении языков, но писать статьи, в которые заложено сравнение и сопоставление (а оно заложено даже в заголовок данной статьи) двух языков, при этом бравируя, что одного из них вы не знаете, конечно не стоит.
Потому что иначе это получается классическое «Пастернака не читал, но осуждаю».
Си чрезвычайно прост
Мне так не кажется, у меня отдельный абзац об этом в статье.
Раст значительно сложнее
Мне так не кажется, у меня отдельная часть статьи об этом.
писать статьи, в которые заложено сравнение и сопоставление двух языков, при этом бравируя, что одного из них вы не знаете, конечно не стоит
Если вы считаете, что где-то в моей статье есть фактическая ошибка напишите, пожалуйста, я с радостью её исправлю и пересмотрю свой взгляд на этот счет.
Си не прост. Прост только синтаксис Си, но не написание и рефакторинг программ, которые очень сложны. У Раста сложнее синтаксис, и сложные правила заимствования, однако это не выдуманная сложность, и ограничения, которые накладывает борроу чекер не искусственные. То, что делает борроу чекер в Расте, по-хорошему, программист на Си должен делать руками. Понятно, что большинство не делает, и оно как-то работает.
Си чрезвычайно прост
А вот выше один спец по Си не смог пройти тест на знание UB.
Часть про "Как бы я не относился к C, все же ему больше 50 уже, не те времена были" вы, видимо, упустили. Странно было бы предъявлять к языку 1972 года претензии на счет нововведений 21 века, я этого, мне кажется, и не делаю (хотя слышал, что даже в свое время в этом плане C не блистал и Fortran и Pascal во многом уже тогда были лучше).
Было бы интересно представить мир, в котором Rust существовал был уже 30 лет, а C++ только появился и как бы тогда выглядели споры о его преимуществах.
"Смотри, ты не понимаешь, токсичный rust'оман, здесь нет единой системы сборки, всяких пакетов и т.д., надо просто использовать собственные костыли -- хочешь make, хочешь cmake, хочешь просто руками вызывай компилятор. Да, файлы просто целиком включаются в виде текста. И нужно вручную разделять на код и заголовки, ну потому что так прикольнее и гибкости больше. Ещё никаких unsafe не надо, код может везде стрелять себе в ногу. Ну естественно тут есть десять способов делать одно и тоже, зато у вас ещё больше знаков препинания в синтаксисе."
Hidden text

Простите, не удержался.
Если Rust будет придерживаться обратной совместимости как C++ то через 30 лет также обрастет кучей "старых подходов", "сахарком", "библиотеками написанными черт пойми как" и т.п. На мой взгляд любое сравнение давно существующего языка с новым которым решил какие-то проблемы которые есть в старом абсолютно бессмысленно. Через 30 лет существования Rust-а появиться новый язык который также решит какие-то проблемы Rust-а которые накопились за эти 30 лет его существования.
Конечно накопятся разные проблемы, но тех, которые заложены в сами основы языков и культуры С/С++ точно не появятся. Если конечно разработчики не сойдут с ума и не развернут эволюцию языка на 180 градусов.
Конечно накопятся разные проблемы, но тех, которые заложены в сами основы языков и культуры С/С++ точно не появятся.
Они решены на момент создания языка, конечно они не появятся. Еще раз мысль в том что 30 лет назад когда С++ стал тем кем он стал не существовало той критической массы знаний и подходов которые есть сейчас и даже цели создания были другими, С++ это продукт своего времени, да сейчас он кажется сложным/странным/неудобным/неочевидным, но через 30 лет Rust также будет таким же старым языком потому что мир не стоит на месте.
У раста есть механизм edition, позволяющий менять язык, отбрасывая груз старых проблем.
У раста есть механизм edition
Это прекрасно, и во все библиотеки накатывается автоматически? Потому что если нет то проблему старых библиотек это не решает. Рентабельность любого подобного механизма покажет себя только через годы когда будет все еще что-то написанное ниже на нцать версий языка и надо будет это что-то мигрировать на последнюю версию. Или если автор библиотеки считает что ему не нужна новая версия языка и он хочет навсегда остаться на одной.
Таки решает :) Потому что старые библиотеки вольны оставаться на старой редакции языка, и при этом могут быть спокойно использованы в новых программах, за редкими исключениями. Для программы/библиотеки в конфигурационном файле указывается, для какой редакции языка она написана, и компилятор полноценно и бесшовно поддерживает все старые редакции.
Проблемы старых библиотек не в том что они не компилируются а в том что они написаны на старых редакциях языка с использованием "старых подходов".
Так гарантии, которые предоставляет Rust, есть уже с 1.0 (2015 года). От того, что в библиотеке старые подходы она хуже работать не станет.
Тут возможна проблема тогда, когда у библиотеки не обновляются зависимости и в части из них могли найти и исправить баги. Это да, но это относится не ко всем библиотекам, многие из них нет никакого смысла переводить на новую редакцию, от самого этого факта ничего не изменится.
От того, что в библиотеке старые подходы она хуже работать не станет.
Библиотека хуже работать не станет но если Вам вдруг по каким-то причинам понадобиться открыть ее и разобраться с багом каким-нибудь или даже доработать под себя потому что ее давно не обновляли вот тогда то и начнутся трудности. И чем она старее она тем больнее с ней будет работать.
Можете, пожалуйста, привести пример, что Вы имеете в виду?
Каждая библиотека имеет свой собственный edition и т.к. каждый крейт - отдельный юнит трансляции они не страдают из-за этой разницы. Есть ещё так называемая политика MSRV - минимальная поддерживаемая версия раста. Так что каждый может писать независимо пока версия компилятора позволяет это делать.
Хоть сам и пишу на Расте сейчас в основном, но вот рассказы о его безопасности почти сразу разбиваются об огромное количество unsafe как в стандартной библиотеке, так и во всяких tokio и иже с ними.
И хоть там "мамой клянус" всё на самом деле безопасно, но доверять в итоге приходится авторам библиотеки, а не компилятору который бы это подтвердил.
Какой-нибудь async_scoped у нас используется местами, а там всё в unsafe внутри с комментариями вроде:
/// # Safety
///
/// This function is _not completely safe_: please see
/// `cancellation_soundness` in [tests.rs][tests-src] for a
/// test-case that suggests how this can lead to invalid
/// memory access if not dealt with care.На деле я редко встречался с реальными проблемами там, но это уже заслуги не языка, а авторов библиотек, которые тщательно стараются писать unsafe-блоки.
На деле я редко встречался с реальными проблемами там, но это уже заслуги не языка, а авторов библиотек, которые тщательно стараются писать unsafe-блоки.
Ну так именно в этом и идея unsafe же. В чём тут проблема-то?
В том, что он используется направо и налево. И это снижает общую безопасность, декларируемую компилятором.
Смотрите на unsafe не как на способ пострелять в ногу, а как на механизм ограничения областей, где существует возможность отстрелить ногу.
Я понимаю что такое unsafe и как им пользоваться. Но, ещё раз, его очень частое использование в самых разных крейтах снижает общее доверие к гарантиям компилятора.
А т.к. писать код без зависимостей могут только академики, да и те вряд-ли, то приходится надеятся что все пограничные случаи в unsafe-ах твоих зависимостей учтены.
Можно открыть и самому проверить эти места. Что-то я из своей практики не припоминаю проблем с unsafe в зависимостях. В основном все стремятся минимизировать число использований unsafe в своих библиотеках.
Благодаря тому, что в Расте unsafe явно отделён, то можно автоматически изучать подобные участки, определять практики, которые программисты реально используют, оценивать обоснованные ли они, предлагать автоматические подсказки по исправлению, предоставлять формальные гарантии и т.д.
приходится надеятся что все пограничные случаи в unsafe-ах твоих зависимостей учтены
Я так и делаю, когда использую зависимости в C++, потому что иначе придётся просматривать вообще весь код, а жизнь у меня только одна.
Нет, не разбиваются :). Ведь абстрактной абсолютной безопасности не обещали. Идея Раста - не связать программиста по рукам и ногам, а сделать так, чтобы стимулировать его писать беспроблемно, и в случаях, когда он выходит на "тонкий лёд", он делал это сознательно и, соответственно, осторожно.
Блоки unsafe - немногочисленны и невелики. Соответственно, чем меньше небезопасного кода, тем меньше вероятность проблем уже из чисто количественных соображений. Но вероятность пробоем ещё ниже из-за того, что unsafe - это своего рода красные флажки. Программист естественно пишет эти блоки с бОльшим вниманием, чем остальной код. Одновременно и при аудите кода или при отладке они указывают, на что имеет смысл обратить пристальное внимание.
Это касается не только unsafe, это фундаментальная парадигма. Например, можно не обрабатывать ошибки и использовать unwrap. Но это тоже красный флажок, навешиваемый сознательно.
Аналогичный подход не только с небезопасными действиями, но и с ресурсозатратными. Обычно, когда делается неочевидно затратное действие, это должно сопровождаться явно указывающим на это текстом. Классический пример этого - использование clone().
Специально для вас у меня есть ссылка (там первые минут 10 про это), которая все это недопонимание объяснит! Тот факт, что в языке и библиотеках на порядки меньше уязвимостей, чем в C и/или C++ и то, что сообщество очень пристально следит за тем, чтобы в публичных библиотеках не использовался unsafe код направо и налево дает очень хорошую гарантию. Так то никакой язык не безопасный, Python внутри на C, но при этом UB там получить крайне маловероятно.
В С++ внезапно тоже можно писать отдельно "безопасные" участки и "небезопасные", вау.
С таким же успехом можно просто сказать, что все места где *ptr и reinterpret_cast являются unsafe, к ним нужно пристальное внимание и тд.
То что я вижу - отличие исключительно на словах. Т.е. в С++ ты якобы это делать не можешь, а в Rust ты не можешь просто писать внутри каждой функции unsafe и наружу выставлять safe интерфейс
Паники - то же самое, все растеры не устают повторять, что якобы это unrecoverable error, совсем не как исключения в С++, но при этом все библиотеки написаны так что учитывают поимку паник, есть собственно возможность ловить паники, паники прокидываются из тредпула в Rayon (такого в С++ не делают по причинам адекватности), то есть на деле получается, что никакого отличия нет, просто раст назвал это по другому и якобы это лучше
Обработка ошибок: раст назвал свои коды ошибок вопросиком (?) и вместо написания ничего (использование исключений) пишет.unwrap руками в каждой строке, а потом сказал, что это не просто коды ошибок, а видите ли монады или какие там умные слова они ещё используют, такого якобы нигде не было и никогда!
В С++ проблемные места, увы, не ограничиваются разыменованием указателей и reinterpret_cast.
Ну хорошо, вот вам проблемное место:
class Foo {
// …
void bar() {
baz->execute([=] () {
this->qux++;
});
}
}
Точнее, это место является проблемным если функция baz->execute асинхронная, но не является таковым если она никуда не сохраняет полученное замыкание.
Что именно тут указывает на необходимость обратить сюда пристальное внимание?
C Rust не сталкивался ни разу, так что не буду рассуждать о нем ни в положительном, ни в отрицательном ключе.
Но вот какие мысли возникли по прочтении.
В начале был упомянут некий "mission critical". Поскольку сам работаю именно с таким кодом, то есть понимание того, что это не только безопасный и надежный, но еще и высокоэффективный код. Т.е. тот код, который по производительности, нагрузке на машину как справлялся с 25млн "условных клиентов", так и продолжает справляться когда их стало 50млн. Справляется в данном случае - укладывается в заданное временное окно, не вызывая задержек в остальных работающих в системе процессов и не вызывает критического увеличения нагрузки на машину. И в этом ключе ожидалось увидеть упоминание о нагрузочном тестировании как неотъемлемой части процесса разработки. Но... Нет. Не увидел. А без нагрузочных тестов не может быть и речи о каких-либо преимуществах в "быстродействии", "эффективности" и т.п.
Также было упомянуто что автор "боится С". Причем, боится не осознанно, а от непонимания как оно работает. В дальнейшем подтверждается мучениями с мьютексами и т.п. Т.е. просто "не знаю, не понимаю как он устроено внутри". Зато радость когда нашел библиотеку где об этом не надо думать. А есть уверенность что эта библиотека одинакова хороша на все случаи жизни? Есть понимание что "многопоточную обработку" можно реализовать не только на пуле потоков, но и на пуле процессов? И есть ситуации, когда такой подход будет предпочтительнее. И обмен данными между потоками - это далеко не всегда разделяемая память и блокировки. Есть и другие механизмы, которые таже могут быть использованы в ряде случаев. И что выбор наиболее эффективного подхода всегда зависит от конкретной задачи. Но нет - есть замечательная библиотека, дальше можно не думать.
Вообще от таких статей всегда хочется конкретного сравнительного анализа - "на этом языке это реализуется так, а на том - этак" При этом "тут используется столько-то ресурсов, там столько-то". "Тут задача выполняется за такое-то количество времени, там за такое-то". Ну что-то в этом духе.
Вместо всего этого приведена куча каких-то технических частностей.
Вообще от таких статей всегда хочется конкретного сравнительного анализа - "на этом языке это реализуется так, а на том - этак" При этом "тут используется столько-то ресурсов, там столько-то". "Тут задача выполняется за такое-то количество времени, там за такое-то". Ну что-то в этом духе.
Большинство языков одного уровня (например компилируемые, системные, допустим с натяжкой C++/Rust/Go можно в один ряд поставить) уже, мне кажется, давно на примерно одном уровне производительности и потребления ресурсов.
Поэтому на первый план выходит именно безопасность, а точнее простота написания безопасного (в каком-либо смысле или смыслах) кода.
Также было упомянуто что автор "боится С". Причем, боится не осознанно, а от непонимания как оно работает. В дальнейшем подтверждается мучениями с мьютексами и т.п. Т.е. просто "не знаю, не понимаю как он устроено внутри".
Я т.к. в этом варюсь уже лет 20+ более менее понимаю как это всё устроено, но от этого желание ручками ковырять всё на низком уровне редко возникает. Если можно абстрагироваться почти бесплатно - почему бы и нет.
Не так давно пришлось пару модулей писать под nginx на Си (впервые за много лет) - ух, как меня трясло от отсутствия давно привычных вещей вроде контроля выхода за границы массива и прочего.
И всякие (не)смешные приколы вроде того, что моя функция совпадала по названию (но не сигнатуре) с функцией из zlib , которая была слинкована с nginx . И в итоге вызывалась функция оттуда, а не из моего модуля, и всё падало. Хотя казалось бы... ни компилятор, ни линковщик не смутились.
Большинство языков одного уровня (например компилируемые, системные, допустим с натяжкой C++/Rust/Go можно в один ряд поставить) уже, мне кажется, давно на примерно одном уровне производительности и потребления ресурсов.
Если говорить о качестве исполняемого кода - наверное да. Но если говорить о идеологии и подходах...
Как пример - динамическая работа с памятью. Активное выделение-освобождение памяти на больших (десятки и сотни миллионов) выборках уже становится заметным на нагрузочных тестах. Т.е. те языки (и библиотеки), которые это активно используют тут проигрывают (сюда же - создание и инициализация объектов в рантайме, сюда же передача разного рода "безопасных копий" объектов в функции).
Если сравнивать два языка с одинаковыми подходами - разницы не увидите. Если подходы разные (в одном используется статика по максимуму) - разница в производительности будет.
Понятно, что динамическая память позволяет ее экономить. Но ценой увеличенного потребления ресурсов процессора. Дальше уже смотрим что нам важнее здесь и сейчас.
Аналогично разного рода GC. Оно тоже не даром дается.
Не так давно пришлось пару модулей писать под
nginxна Си (впервые за много лет) - ух, как меня трясло от отсутствия давно привычных вещей вроде контроля выхода за границы массива и прочего.
Если этот контроль в рантайме, то он дается ценой некоторого количества дополнительного кода. На выполнение которого требуется некоторое время. А на одном "обороте" цикла не заметите. На 100 000 000 - увидите.
Когда у вас задачки типа "сравнить два множества - одно 250 000 000 элементов, второе ~1 000 000 элементов на совпадения" (причем совпадение - это не тупое a = b, а сравнение двух поднаборов разного размера на присутствие всех уникальных элементов меньшего по размеру поднабора в большем по размеру) - тут уже приходится на каждой спичке экономить. Любой лишнее телодвижение помноженное на количество циклов становится ощутимым.
Так что когда тут используешь какие-то библиотеки, то всегда думаешь - а как оно там внутри работает? А нет ли там чего лишнего, того что для универсальности добавлено, но в данном конкретном случае нафиг не нужно...
Когда у вас задачки типа ... тут уже приходится на каждой спичке экономить
И даже тут есть горячий код, в котором лишние проверки очень мешают - и не такой горячий, в котором лишние проверки не заметны на фоне первого.
Если сравнивать два языка с одинаковыми подходами - разницы не увидите. Если подходы разные (в одном используется статика по максимуму) - разница в производительности будет.
Почти везде можно в горячих участках уйти в ручное или полу-ручное управление аллокациями. Даже в Go в проектах вроде fasthttp активно используется пулинг объектов через тот же sync.Pool, чтобы не нагружать аллокатор и сборщик мусора лишними думами.
Поэтому, на мой взгляд, возможность писать 99% кода в безопасном режиме и в 1% горячих путей взять какой-нибудь unsafe и ручками сделать хорошо - неплохой компромисс.
Если этот контроль в рантайме, то он дается ценой некоторого количества дополнительного кода. На выполнение которого требуется некоторое время. А на одном "обороте" цикла не заметите. На 100 000 000 - увидите.
Само собой, у всего своя цена. Но, опять же, см. выше, я бы хотел по-умолчанию делать удобно, а если мне нужно быстро - я переключусь в ручное управление. В том же расте есть всякие smallvec и иже с ними, которые аллоцируют вектора на стеке до определённого размера и реаллоцируются в хип только при переполнении.
В общем и целом большая часть софта не требует экономии на спичках. Но в каких-то местах это нужно и возможность должна быть, согласен.
Поэтому, на мой взгляд, возможность писать 99% кода в безопасном режиме и в 1% горячих путей взять какой-нибудь
unsafeи ручками сделать хорошо - неплохой компромисс.
Проблемы начинаются когда соотношение 99/1 меняется к наоборот - 1/99. Ну просто так сложилось - где 99/1 отдают тем кто помоложе, а где 1/99 - вам. Потому что "вы умный, вы справитесь, мы в вас верим".
В общем и целом большая часть софта не требует экономии на спичках. Но в каких-то местах это нужно и возможность должна быть, согласен.
Да. Большая часть софта (если смотреть вообще весь софт который пишется) вообще мало чего требует.
Но максимальное количество болей доставляет именно та малая часть, где все очень критично.
Проблемы начинаются когда соотношение 99/1 меняется к наоборот - 1/99. Ну просто так сложилось - где 99/1 отдают тем кто помоложе, а где 1/99 - вам. Потому что "вы умный, вы справитесь, мы в вас верим".
То есть где-то в теории, а не на практике, да?
According to Stanford, around 5% of Rust code is unsafe, including around 30% of crates. According to The New Stack, the percentage of unsafe functions in crates.io is 7.5%, while in Redox it is 1.7%, and in rustc it is 31.1%. However, if you exclude the core-arch crate, which defines 94.6% of unsafe functions, the percentage of unsafe functions in other crates is 2.7%.
Т.е. unsafe используется редко, но метко, там где не обойтись -- в работе с другими языками, железом и глубинах самого языка.
Нет, не начинаются. Потому что, во-первых, считать проценты надо по всей кодовой базе, а не по смещённой выборке. А во-вторых, ради этого же всё и затевалось-то! Чтобы можно было отдать самые сложные части самому опытному программисту, и у него не болела голова о том, что кто-то из менее опытных коллег где-то там неправильно использует то что он написал.
В Rust такая же как в плюсах идеология zero cost abstractions и стремление к твоему э такому дизайну языка чтобы не платить (в рантайме) за то, чем ты не пользуешься.
Так что он вполне подходит для написания высокоэффективного кода. Как пример, можно посмотреть на GPU драйвер Asahi linux для Apple Silicon. Он работает весьма и весьма хорошо, а его ядерная часть написана на Rust. И по словам разработчиков, выбор языка избавил их от долгой и сложной отладки. Помню была статья где они от уровня крутить шестерёнки перешли на уровень запуска KDE всего за пару дней.
К слову, этот драйвер имеет сертифицированную поддержку Opengl 4.6, в отличие от оригинального от Apple
Не согласен, что "mission critical" обязан быть высокоэффективным. Код установок для рентгеновского излучения очень даже "mission critical", но 25млн. человек ему одновременно обслуживать не надо.
Эта статья и так огромная, я половину статьи выкинул и еще половину от оставшегося засунул под разные спойлеры, чтобы их можно было пропустить если не интересно. Если я начну говорить о всем, что в Rust хорошо, то эта статья бы: 1) была бы раз в 5 больше; 2) вряд ли когда-либо вышла, мне и эти мысли оформить в статью было непросто. Про скорость работы Rust есть куча других статей, если вкратце, то он +- аналогичен по скорости с C. У меня же была другая задача, я хотел показать, что как раз кроме скорости в Rust есть очень много всего.
Как раз таки наоборот, после знакомства с Rust и более полного понимания "как же оно внутри устроено" я "боюсь" C и/или C++ еще больше. Огромное количество способов потратить недели своей жизни на поиск очередного UB в абсолютно обычном коде бизнес-логики (а не в коде супер-оптимизированных алгоритмов) для меня просто неприемлемо.
"Зато радость когда нашел библиотеку"
Видимо, я действительно неправильно расставил акценты, суть не в том, что есть чудо библиотека, в которой есть чудо из чудес - пул потоков. Суть в том, что не важно с использованием библиотеки или без в Rust невозможны гонки данных, что дает свободу экспериментировать с алгоритмами без мьютексов, атомиков и прочего. Если я ошибусь - код не скомпилируется. Если код скомпилировался - у меня есть гарантия того, что огромного числа проблем в моем многопоточном коде нет.Статей про прямое сравнение по разным параметрам тоже огромное количество, можете без особых проблем их найти. Мне не хотелось писать "тоже самое, чуть другое".
Эт не mission critical, это safety critical. Впрочем, мишн критикал действительно не обязан быть высоконагруженным.
Суть в том, что не важно с использованием библиотеки или без в Rust невозможны гонки данных
Гонки данных (и прочие дедлоки) - это прежде всего ошибка архитектуры. То, что их нет в Rust не совсем верно. Их нет в реализации конкретной библиотеки.
А если говорить о параллельной обработке, то это не всегда совместная работа с одними и теми же данными. Это может быть обработка больших объемов данных, где каждый элемент обрабатывается независимо от остальных. И там не будет никаких гонок. Но и подход будет совсем иным в плане организации потоков, их балансировки и распределения по ним обрабатываемых данных.
Или это может быть конвейерная обработка пакетов где каждый поток выполняет свою часть работы (с тем, чтобы максимально быстро освободиться для работы со следующим пакетом) и передает пакет дальше по конвейеру.
И в каждом конкретном случае наиболее эффективным будет свое решение, а не попытка натянуть одну библиотеку на все. Но для правильного выбора нужно очень хорошо понимать как оно работает. И лучше всего один раз не пожалеть времени, сделать все руками, пройтись по всем граблям, а потом уже переходить на использование библиотек.
Лет 10 назад перевел свой проект с C++ на Python чтоб убрать компиляцию. Время полной перекомпиляции проекта - более часа. На таких проектах ты дорабатываешь какой-то модуль, ну т.е. dll-ку, которая компилируется порядка минуты. Но полный цикл отладки всё равно занимает порядка 10 минут.
остановить основное приложение, чтоб оно освободило dll-ку
скомпилировать dll-ку
запустить основное приложение - это тоже порядка минуты
проверить функционал - получить сбой
подключиться дебаггером - это нужно найти все воркеры в системе, относящиеся к основному приложению
отладится - понять что что-то не учел в ответе от другого модуля
Это мало того что медленно, из-за больших пауз теряется фокус внимания. А постоянное переключение внимания сильно утомляет.
Вместо всего этого в питоне пишешь что-то типа if is_local_stend: imp.reload(<модуль>) и у тебя следующий же запрос идет с использованием нового кода. А дебагер практически никогда не нужен (он в питоне тормозной) - при такой скорости перезапуска можно просто добавлять вывод данных в лог-файл.
Недавно видел как чувак для раста сделал хот-релоад модуль. Правишь код, компилируешь, магически обновляется поведение программы.
в Rust по умолчанию CDD (compiler-driven development, разработка через компилирование). Это как TDD, только CDD;
Т.е. сначала нужно написать компилятор под свой проект?)
не успел я эту статью выложить, как оказалось, что 27 марта 2024 года на конференции Rust Nation UK 2024 было выступление с интригующим названием Beyond Safety and Speed: How Rust Fuels Team Productivity от Lars Bergstrom, Google Android Director of Engineering
Только вот незадача, это участник Rust Foundation, причём не последний, вот такой вот "независимый" эксперт
https://foundation.rust-lang.org/news/2021-04-22-introducing-lars-bergstrom/
Насчёт самого обсуждаемой его фразы, якобы раст вдвое продуктивнее С++. Если немного покопаться в том на что он ссылается, то там было переписывание с С++ на Rust, при этом второе переписывание(!!!)
А весь его доклад состоит на 100% из слов и перевираний, секция с "примерами" закрывает "выводом" весь экран и в "идиоматичном С++" у него пишут struct fd_t fds[FD_COUNT] т.е. С89 код с использованием линукс апи, а справа десять слоёв абстракции над тем же самым на расте. И даже в таком сравнении раст код там выглядит хуже (вложенность 9 слоёв)
По поводу остальной статьи:
лежит книга «Язык программирования С», но я её так и не дочитал до конца, не говоря уже о том, чтобы «выучить» C.
Тогда на основании чего вы говорите, что Rust - это "не то же самое" или лучше в чём-то? Вы думаете в С++ нет библиотек похожих на Rayon(спойлер -есть, и они гораздо лучше)? Попробуйте скомпилировать код на С++, вы удивитесь как много ошибок компилятор таки найдёт, особенно по сравнении с Python, с которым вы и сравнивали Rust
В чём незадача-то? "Независимость" эксперта вы сами придумали, сами опровергли. Удивительно, что представитель компании широко использующей язык программирования входит в состав разработчиков этого языка и на конференции по этому языку рассказывает про реальный опыт использования этого языка в компании, ого.
вот такой вот "независимый" эксперт
Учасникам Rust Foundation теперь запрещено выступать на конференциях со своими данными?
при этом второе переписывание
Ну да. После нескольких переписываний C++ кода на C++. И после этого оказалось, что так же переписать код с C++ на Rust в двое быстрее, чем с C++ на C++.
Попробуйте скомпилировать код на С++, вы удивитесь как много ошибок компилятор таки найдёт
Как только C++ не будет компилироваться в случае, когда в коде есть гонка данных обязательно попробую.
Именно. Вопрос не в том сколько ошибок компилятор найдет. Достаточно одной, которую он не найдет...
Возьмите Erlang и наслаждайтесь. «Истинная» многопоточность из коробки. Ни каких тебе мьютексов и других примитивов синхронизации.
Добавлю Erlang в список на изучение, много про него слышал, но руки не доходили. Будет интересно посмотреть на такую реализацию многопоточности.
И да, то, что Rust в каких-то местах показывает себя очень хорошо не значит, что он там лучший и, тем более, что только Rust хорошо себя показывает. У меня с Golang проблема как раз в этом, прям супер нового и уникального в Rust не много, там просто много вещей, которые хорошо работали в других языках. Что мешало добавить хотя бы часть из них в Golang для меня загадка.
Ну да. После нескольких переписываний C++ кода на C++. И после этого
оказалось, что так же переписать код с C++ на Rust в двое быстрее, чем с
C++ на C++.
Давайте говорить правильно.
Повторяйте за мной: "После нескольких переписываний конкретного C++ проекта. И после этого оказалось, что так же конкретные* люди переписали конкретный* C++ проект на Rust в двое быстрее, чем этот же C++ проект заново на C++"
После прочтения, вам не показалось что язык тут играет второстепенную роль?
Перестаньте обобщать.. То, что я напишу код на python, который выполняется в два раза быстрее, чем код на C++, не будет значить что python быстрее C++. Такого понятия просто нет. Как нет и понятия "скорость переписывания с одного языка на другой"
переписали конкретный* C++ проект
Специально пересмотрел видео, вот дословная цитата:
This is not the first time many of these systems were being rewriten
Проектов было много.
на Rust в двое быстрее, чем этот же C++ проект заново на C++
Если вас не затруднит, подскажите, что же помешало тем же самым людям, переписывающим тот же самый код с C++ на C++ на второй и, особенно, на третий раз сделать это в 2 раза быстрее?
После прочтения, вам не показалось что язык тут играет второстепенную роль?
После переслушивания выступления нет, не показалось.
скорость переписывания с одного языка на другой
Именно из-за этого Ларс в самом начале и говорит:
There is nothing that makes people more angry on the internet than talking about benchmarks. Except, talking about developer productivity.
А еще он говорит, что на переписывание кода с C++ на Rust и на последующую поддержку кода после этого нужно как минимум в двое меньше людей.
P.s. Меня поражает то, насколько Rust сообщество на самом деле скромное и критичное даже к самому Rust'у. Вы просто посмотрите на то, что люди писали в комментариях под фотографией одного слайда (с как раз вырванной из контекста фразой про то, что в Rust продуктивность в 2 раза выше, чем в C++) из выступления (про видео и, соответственно, текст выступления написали позднее). Как минимум половина комментариев ровно про то же самое! "Как они измеряли продуктивность", "А может быть это просто были очень мотивированные писать на Rust разработчики", "А насколько честное это сравнение" и т.д. Я бы хотел увидеть еще еще одно такое сообщество, куда приходят с выступлением о том, что их любимый язык в 2 раза продуктивнее, чем другой, но вместо радости они относятся к этой информации очень подозрительно.
А весь его доклад состоит на 100% из слов
И более того, в его словах есть буквы!
спойлер -есть, и они гораздо лучше
а вот с этого места поподробнее. Кроме стандартных спецификаторов для алгориитмов и либы openmp ничего настолько же универсального не припоминаю.
Rayon это буквально переписывание TBB https://github.com/oneapi-src/oneTBB
Таки и чем он лучше того же Rayon? Вот такие конструкции не могу сказать чтобы были как-то удобнее чем что-то вроде.
let result_map = (0..mapxSize+1)
.par_iter()
.map(ApplySplitOverlay)
.collect();Для С оно выглядит, конечно, неплохо, но явно не "лучше". Применение openmp страдает похожей болезнью, когда посредь кода появляются магические #pragma. Понятно почему, но непонятно почему не сделать что-то более удобное?
Т.е. те что в стандартной библиотеке для вас неудобные?)
И вы цитируете какой то конкретный код вычисления чего-то там, то же самое можно написать и на Rayon и будет криво и некрасиво, что дальше?
В отличие от раста, у С++ не одна подобная библиотека
В отличие от раста, у С++ не одна подобная библиотека
Не в отличие от. Мне даже искать не надо чтобы сказать,что еще есть, например, crossbeam.
Т.е. те что в стандартной библиотеке для вас неудобные?)
Именно так. С 23 стандарте оно может выглядеть лучше, но вот будет ли - вопрос открытый. А так параллелизация в плюсах постоянно обрастает то прагмами, то SIMD интринсиками, где ручками приходится циклы разворачивать - проблемно писать, проблемно читать, проблемно портировать в некоторых случаях. Могло быть лучше, но где-то что-то не срослось и в итоге имеем, что имеем.
В отличие от раста, у С++ не одна подобная библиотека
В Rust тоже не одним rayon едины, но исходно просьба была про покажите лучше чем хотя бы он.
А так параллелизация в плюсах постоянно обрастает то прагмами, то SIMD интринсиками
откуда взялись в разговоре про треды симд интринсики? В расте получается симд интринсики никто использовать не будет?) Или там внезапно компилятор сам всё сделает? (ах да, там тот же бекенд компилятора что и у clang...)
То же самое к развороту циклов относится.
Прагмы вообще нигде и никогда не нужны при написании чего то связанного с потоками
В расте получается симд интринсики никто использовать не будет?)
Можете те же экспериментальные std::simd::f32x16 считать интринсиками - но есть же некоторая разница между выражениями a + b и _mm512_add_ps(a, b)?
Да, я знаю (теперь) что экспериментальная simd библиотека в C++ тоже есть, но почему-то я в примерах кода видел только голые интринсики.
откуда взялись в разговоре про треды симд интринсики?
Разговор не про треды, а про удобный параллелизм, которые включает как потоковый параллелизм, делящий работу между ядрами и параллелизм данных, увеличивающий количество операций выполняемых за один такт.
Код на итераторах (filter/map/fold) без сайд эффектов с большой вероятностью будет автовекторизирован оптимизатором в llvm, аналогичный код в виде обычного цикла тоже имеет высокие шансы получить ровно такую же оптимизацию. При использовании параллельных итераторов оно заодно и по ядрам раскидает работу. SIMD интринсики использовать можно, но за счёт автовекторизации количество юзкейсов, когда это действительно нужно, заметно сужается и с большей вероятностью имеет отношение к неизбежному unsafe коду и asm вставкам.
В С++ шанс срабатывания автовекторизации заметно меньше и может требовать дополнительного шаманства с параметрами компиляции. Поэтому libomp использует прагмы, для того чтобы сообщать компилятору, чтобы вот следующий цикл точно готов к векторизации. Ну и про прочие прелести плюсового симдования вам уже рассказали.
посмотрите на качество этих библиотек честно. Они больше похожи на поделки студентов
Пример:
https://crates.io/crates/try-lock
всё что может делать "библиотека" - TryLock. Реализовано... Просто как один атомик, лок происходит через = true, проверка что залочено через == true, это всё что предоставляет библиотека. Скачиваний - 118 миллионов. Ну что ж, это уровень джаваскрипта пожалуй
Второй пример: https://crates.io/crates/parking_lot
несколько примитивов, которые якобы быстрее стд. По заявлению разработчиков, они не аллоцируют сторадж в отличие от стандартных.
Но они не говорят почему стандартный мьютекс аллоцирует. Потому что в расте нельзя запретить мув, а мьютексу нужен стабильный адрес, то есть если в этой библиотеке мувнуть мьютекс и его разлочить, то будет уб
Также замечательное апи (трейт мьютекса)

Этот метод бессмысленен, информация о том залочен ли мьютекс инвалидируется мгновенно по завершению этого метода
Дальше соседний крейт
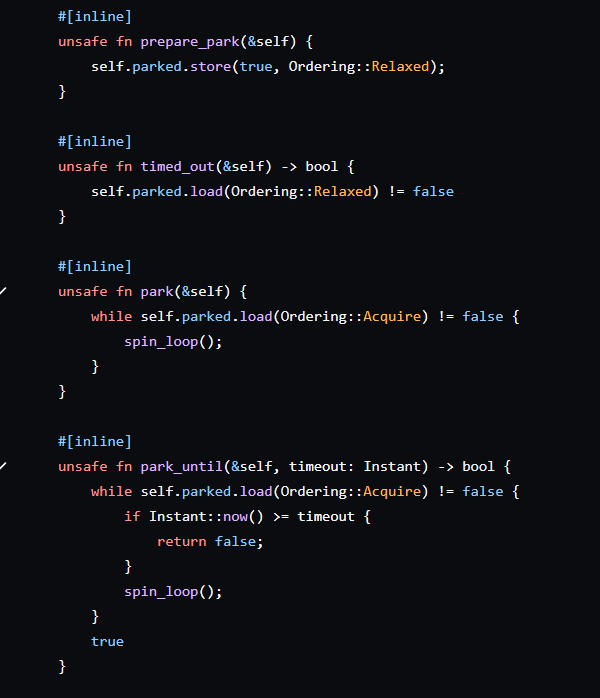
Абсолютно всё и везде unsafe, никаких объяснений что делать чтобы было safe нет, внутри самый элементарный спинлок. Скачиваний - тоже за 100 млн
Просто как один атомик, лок происходит через = true, проверка что залочено через == true, это всё что предоставляет библиотека.
Библиотека предоставляет безопасный способ работы с разделяемыми данными, не позволяя получить к ним доступ без блокировки. Смысл библиотеки именно в этом, а не в проверке на true.
Спасибо за статью, было интересно
Единственное, что смутило, это сравнение python и "многих других языков", которые прям вот отличаются от Rust
С позиции Python -> Rust, наверное яркий контраст играет свое
Но если бы это было Java(и пр. ЯП из jvm)/C# -> Rust, то тут такого контраста нет совсем
И с типизацией все более или менее в порядке, и с многопоточкой, и рефакторить вполне себе все это можно без дикой головной боли, если всё правильно написано(но думаю наговнокодить можно и в расте, да так, что потом хрен отрефакторишь)
Просто по сравнению с Java у Rust другие преимущества) Писать статью про все достоинства (да и недостатки) Rust на 7 часов непрерывного чтения я пока не готов, так что написал о том, что не представлено так ярко, как мне бы хотелось.
более или менее в порядке ... с многопоточкой
Насколько я понимаю, тех же гарантий, которые дает Rust в плане многопоточности у Java нет. Тут либо Rust, либо языки без мутабельности вообще.
Я с Rust активно познакомился уже имея существенный опыт разработки на C#/Java/Golang - и это был прямо "глоток свежего воздуха".
Rust на многие вещи смотрит по другому. Простейший пример - отсутствие null-значений и работа c enum-ами. Владение переменной - тоже очень интересный подход.
Так что контраст будет и после C#/Java/Golang. Это был очень интересный опыт.
Но рекомендовать Rust прям для всего я не буду - на мой взгляд, он очень хорош для небольших проектов (например, для микросервисов).
После C# писал на Rust, и немного расстроился от того, сколько ошибок многопоточности было в моем коде на C#/
Для бизнес приложений (например, джсон апишек) Rust менее удобен, чем C#, только отсутствием LINQ (ну и невозможностью рефлекшена в рантайме, но это нужно гораздо реже).
Пока что самое сложное в Rust начинается, когда в коде появляются всякие Cell/RefCell/Rc/Arc. Работа с односвязными списками самая большая боль и считаю, что если односвязный список появился в коде, то с большой долей вероятности кто-то что-то делает не так.
Вторая сложность - аргументирование о производительности кода. Вот эти во проблемы выбора между .iter(), .into_iter() и .iter_mut() или передача аргумента по значению/по ссылке. В одних ситуациях идея об иммутабельности типов работает и ожидаемые оптимизации срабатывают, в иных случаях производительность становится неочевидной и необходимо профилировать код даже на относительно небольших программах.
Третья вещь которая связана с рефакторингом - пока ваша программа линейная и однопоточная, то проблем с ним практически никогда не возникнет, но как только появляется асинхронность или многопоточность, а в сигнатуры начинают подмешивать лайфтаймы и границы а ля Send+Sync, то производный код быстро начинает ими "отравляться" при неаккуратном использовании и рефакторить его становится кратно сложнее. Способов решения этой проблемы имеется несколько, но подозреваю, что существуют ситуации, когда "уродливый" всё равно неизбежен.
После приблизительно 200 задач порешанных на leetcode понял, что теперь могу писать на rust скрипты так же продуктивно, как и на Python, имея при этом кратно бОльшую производителность (даром компилируемый язык) и меньшую вербозность, как если бы делал это на плюсах.
самое сложное в Rust начинается, когда в коде появляются всякие Cell/RefCell/Rc/Arc
Я бы сказал наоборот, когда начинается что-то сложное появляются Cell/RefCell/Rc/Arc. Во многих случаях правильным было бы не добавление счетчиков ссылок и interior mutability, а структурировать программу так, чтобы они не были нужны. Конечно, это не всегда возможно, но не могу сказать, что они нужны часто. Safe варианты деревьев можно так писать, а можно, например, хранить все ноды в векторе и в качестве указателя использовать позицию ноды. И универсальный совет про лекции Алексея Кладова про эту ситуацию. Вообще эти лекции очень универсальны, там можно найти ответ практически на любой вопрос. Думаю смысл жизни тоже там есть.
"уродливый" всё равно неизбежен
Тут же дело не в "уродливости" кода, а в том, что можно один вариант поменять на другой с гораздо большей уверенностью в том, что код делает тоже самое.
деревья-то понятно, один вошёл n вышло, но если это просто случайный граф да ещё и ориентированный, да ещё и с рёбрами из себя в себя, то там уже всплывают нюансы и возникает проблема "сложность" vs "количество" кода - либо будет сложно писать и убеждать компилятор, либо придётся реструктурировать код под более дата ориентированный подход с ECS и кверями, что легко и непринуждённо утроит сложную версию кода. Тут каждый решает сам по какому пути идти.
Interior mutability вполне может всплывать в многопоточном/асинхронном коде и его практически нереально исполнить как-то иначе, так что тренировка на котиках вполне оправдывает себя.
с гораздо большей уверенностью в том, что код делает тоже самое.
Это уже не столько про рефакторинг, сколько в принципе про некрасивый код, который уже оптимален по Парето - сделаешь красивее - получишь минус производительность, сделаешь быстрее - получишь нечитаемую и неподдерживаемую кашу. Говорят задачи с Advent Of Code отличный способ показать подобные ситуации, но сам не пробовал его решать.
а можно, например, хранить все ноды в векторе и в качестве указателя использовать позицию ноды.
и это почему-то считается в раст сообществе нормальным. Т.е. язык заставил сделать какую то хрень, изменить всю архитектуру приложения, получить за это потерю производительности, читаемости, поддерживаемости и тд, при этом ни один контейнер стандартной библиотеки раста не даёт стабильности ссылок на элементы, и это не случайность - такую абстракцию не способен выразить сам язык (иначе все методы были бы unsafe).
Главное, что нужно понять - на самом деле это суть раста. Все библиотеки включая стандартную и даже компилятор самого раста(фронтенд для ллвм) являются прекрасными примерами во что вырождается код при таких "разумных" требованиях языка.
То есть переход на раст даёт невозможность писать интуитивно понятный код, который работает буквально во всех других языках, но сторонники будут оправдывать это вечно (пока язык не забудут через 5-7 лет)
при этом ни один контейнер стандартной библиотеки раста не даёт стабильности ссылок на элементы, и это не случайность...
…потому что такой гарантии и правда нету.
А вот принятый подход просто использовать индексы - и правда хрень, это обход защиты вместо решения проблемы.
потому что такой гарантии и правда нету.
Так почему её нету? Потому что писатели стандартной библиотеки раста знают, что выразить это не выйдет. В С++ такая гарантия есть и для немалого количества контейнеров
Примеры, пожалуйста.
[тык](https://en.cppreference.com/w/cpp/container/vector) - Раздел Iterator Invalidation.
[тык](https://en.cppreference.com/w/cpp/container/list) -
Adding, removing and moving the elements within the list or across
several lists does not invalidate the iterators or references. An
iterator is invalidated only when the corresponding element is deleted.
изучение остальных контейнеров оставлю вам как домашнее задание)
Простите, но я не понял, что вы хотели показать в примере с вектором, там же написано следующее:
push_back, emplace_back - If the vector changed capacity, all of them;
insert, emplace - If the vector changed capacity, all of them;
resize - If the vector changed capacity, all of them.
Полагаться на то, что у ветора при добавлении не изменится capacity - это дело рискованное.
В связном списке Rust точно так же не инвалидирует итератор.
и это почему-то считается в раст сообществе нормальным
Простите мою иронию, но не могу сдержаться. Угадайте, откуда я взял такой подход для своей реализации Aхо-Корасика? Я взял его из обучающей статьи, где как раз C++. Понятия не имею, почему автор решил сделать так вместо указателей, но, очевидно, в C++ такой подход тоже используется. Видимо C++ тоже "заставил сделать какую то хрень, изменить всю архитектуру приложения, получить за это потерю производительности, читаемости, поддерживаемости и тд,".
Ни разу не видел чтобы в С++ так писали. А уж тем более AST строить на векторах и индексах (конечно же с проверками при обращении!)
А в компиляторе раста так и написано
Ну, теперь вы это видели.
Да, олимпиадники обычно именно так и пишут, потому что указателей боятся.
А в компиляторе раста так и написано
Я не поленился и посмотрел, как же в стандартной библиотеке Rust реализован двусвязный список. Не поверите, все на указателях, никаких векторов! BTreeMap и BTreeSet тоже на массивах внутри (т.к. это, собственно, BTree). BinaryHeap действительно в хранит ноды в векторе. Насколько я помню, так и рекомендуется для наилучшего использования CPU кеша.
А в компиляторе раста так и написано
Я не поленился и посмотрел, как же в стандартной библиотеке Rust реализован двусвязный список. Не поверите, все на указателях, никаких векторов!
Это лишний раз подчёркивает уровень понимания темы, вы считаете компилятор и стандартную библиотеку одним и тем же
P.S.
указателей там кстати нет (с точки зрения раста), вместо этого вот такой ужас:

Option<NonNull<Node<T> > >
marker: PhantomData<Box<Node<T>, A> >
что уж лучше может показать абсурдность раста, чем такой код
Ладно, зайдем с другого конца. Вы вот правда считаете, что вы один знаете, как правильно связные списки писать? В компиляторе Rust используется даже код сторонних библиотек, не говоря уже о стандартной библиотеке. Что-то мне подсказывает, что у них были причины на то, чтобы использовать отдельную реализацию с вектором, а не готовую из стандартной библиотеки.
В компиляторе Rust используется даже код сторонних библиотек, не говоря уже о стандартной библиотеке.
что? Использовать код сторонних библиотек при реализации компилятора (как и любой другой программы) - норма, более того, компилятор раста это практически на 100% код другой библиотеки (llvm на С++). При чём тут крейт по ссылке - я не понял
Вы вот правда считаете, что вы один знаете, как правильно связные списки писать
причём тут я? Связные списки уже лет 70 люди пишут и что-то никому ни разу (до раста) не пришло в голову сломать всю концепцию подобных списков, например до некоторой версии в std::list раста ... нельзя было удалить элемент...
Вставить в середину до сих пор нельзя ну и вообще все операции, которые свойственны списку, там отсутствуют (всилу того как устроен язык и философия писателей его стандартной библиотеки)
Как предсказуемо, что разговор про раст сведётся к связным спискам, как будто на них свет клином сошёлся. Которые и на архитектуру железа отвратительно ложатся, и используются в паре калечных ситуаций и которые можно один раз написать и (реально) везде потом использовать (потому что в отличие от великого Си не надо каждому проекту писать или копи-пастить с небольшими изменениями свои костыли).
разговор про раст сведётся к связным спискам
их сам автор зачем-то привёл в пример
на архитектуру железа отвратительно ложатся
к сожалению для раста не все задачи это числодробилка внутри одного массива. Хотя... Раст же и в этом сценарии потрясающе плох - вы даже не можете взять две ссылки на разные элементы внутри вектора
Во всех других задачах образуются графы или связные списки в том или ином виде. Более того, именно что связный список "один раз написать" не получится, потому что каждый раз он для конкретного случая свой. И используется крайне часто как раз в системном программировании, на которое (напомню) раст и нацелен. Он же позиционирует себя как системный язык
Вы распространяете недостоверную информацию. Взять две ссылки на разные элементы внутри вектора можно.
https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=c4605e4e02c328af428c7c4f32381424
Можно и без unstable тоже самое сделать.
Используя
расширение компилятора
уб с точки зрения языка
#noinline чтобы уб не сработало
чтобы это сделать всё равно внутри происходит !!! создание массив, сортировка и проверка на наличие повторений!!!
Саморазоблачение какое то
Эм, нет. Просто нет.
Unstable - это не расширение языка, это фичи, у которых еще не зафиксированно API и оно может поменяться со временем;
Тут нет никакого UB;
#[inline(never)]никак не влияет на UB и на работоспособность этого кода;Попробуйте найти тут "создание массив, сортировка и проверка на наличие повторений":
Заголовок спойлера
playground::swap: # @playground::swap
# %bb.0:
mov eax, dword ptr [rdi]
mov ecx, dword ptr [rsi]
mov dword ptr [rdi], ecx
mov dword ptr [rsi], eax
ret
# -- End function
playground::main: # @playground::main
# %bb.0:
push rbx
sub rsp, 80
movabs rax, 953482739823
mov qword ptr [rsp + 4], rax
lea rsi, [rsp + 12]
mov dword ptr [rsp + 12], 333
lea rbx, [rsp + 4]
mov rdi, rbx
call playground::swap
mov qword ptr [rsp + 16], rbx
lea rax, [rip + core::array::<impl core::fmt::Debug for [T; N]>::fmt]
mov qword ptr [rsp + 24], rax
lea rax, [rip + .L__unnamed_3]
mov qword ptr [rsp + 32], rax
mov qword ptr [rsp + 40], 2
mov qword ptr [rsp + 64], 0
lea rax, [rsp + 16]
mov qword ptr [rsp + 48], rax
mov qword ptr [rsp + 56], 1
lea rdi, [rsp + 32]
call qword ptr [rip + std::io::stdio::_print@GOTPCREL]
add rsp, 80
pop rbx
ret
# -- End function
https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=c4605e4e02c328af428c7c4f32381424
заходите сюда и смотрите на ассемблер, get_many_check_valid
Вы код в релизе (с оптимизациями) скомпилируйте и проблема исчезнет.
То есть если оно оптимизировалось, то его не было? А если не оптимизируется?) А оно не сможет, если там хотя бы 1 значение неизвестно на компиляции или значений много и тд
То ничего не изменится:
Заголовок спойлера
playground::swap: # @playground::swap
# %bb.0:
mov eax, dword ptr [rdi]
mov ecx, dword ptr [rsi]
mov dword ptr [rdi], ecx
mov dword ptr [rsi], eax
ret
# -- End function
playground::main: # @playground::main
# %bb.0:
push rbx
sub rsp, 80
mov dword ptr [rsp + 16], 111
lea rax, [rsp + 16]
#APP
#NO_APP
mov eax, dword ptr [rsp + 16]
mov dword ptr [rsp + 16], 222
lea rcx, [rsp + 16]
#APP
#NO_APP
mov ecx, dword ptr [rsp + 16]
mov dword ptr [rsp + 16], 333
lea rdx, [rsp + 16]
#APP
#NO_APP
mov edx, dword ptr [rsp + 16]
mov dword ptr [rsp + 4], eax
mov dword ptr [rsp + 8], ecx
lea rsi, [rsp + 12]
mov dword ptr [rsp + 12], edx
lea rbx, [rsp + 4]
#APP
#NO_APP
mov rdi, rbx
call playground::swap
#APP
#NO_APP
mov qword ptr [rsp + 64], rbx
lea rax, [rip + core::array::<impl core::fmt::Debug for [T; N]>::fmt]
mov qword ptr [rsp + 72], rax
lea rax, [rip + .L__unnamed_3]
mov qword ptr [rsp + 16], rax
mov qword ptr [rsp + 24], 2
mov qword ptr [rsp + 48], 0
lea rax, [rsp + 64]
mov qword ptr [rsp + 32], rax
mov qword ptr [rsp + 40], 1
lea rdi, [rsp + 16]
call qword ptr [rip + std::io::stdio::_print@GOTPCREL]
add rsp, 80
pop rbx
ret
Нет ну тут уже совсем без мата сложно с растерами, ладно взял опять релиз, ладно взял блекбокс вместо адекватного получения данных извне за счёт вызова форвард декларированной функции, так ведь отрицает базовую логику:
let mut array = black_box([black_box(111), black_box(222), black_box(333)]);
let [a, b] = array.get_many_mut([0, 2]).unwrap();Ну вот подумай ты хоть на секунду больше, неужели неясно, что чтобы доказать, что адреса разные нужно понять что индексы разные, значит нужно не значения в массиве прятать, а индексы значений в массиве
let mut array = [111, 222, 333];
let [a, b] = array.get_many_mut([black_box(0), 2]).unwrap()Тогда получается 146 строк асм против 97 когда неизвестный индекс.
https://godbolt.org/z/G1713zaPj
Вы просто показываете то что вы пришли из питона и ничего не смыслите ни в оптимизациях, ни в расте
Тогда получается 146 строк асм против 97 когда неизвестный индекс.
"создание массив, сортировка и проверка на наличие повторений", видимо, в количестве строк асма выражается, ясно, понятно. Не помните уже, с чего разговор то начался? Могу напомнить, вы в одном комментарии умудрились сделать 4 утверждения, все из который ложны (включая "создание массив, сортировка и проверка на наличие повторений" для не дебаг версии).
И без тыканий, пожалуйста, мы с вами брудершафт не пили.
"создание массив, сортировка и проверка на наличие повторений", видимо, в количестве строк асма выражается, ясно, понятно.
а в чём они в бинарном коде ещё могут измеряться?
Ты сидишь и нагло лжёшь, что "вот, ничего тут нет", я показывааю что оно тут есть и немало, ты пытаешься с темы съехать
а в чём они в бинарном коде ещё могут измеряться?
Это шутка такая? Может быть все же надо смотреть на то, какие операции происходят? А то 1 стока блокирующего сискола, оказывается, выполняется столько же, сколько и мув из регистра в регистр. Вот чудеса!
я показывааю что оно тут есть
Так покажите, где в релиз версии get_many_check_valid "создание массив, сортировка и проверка на наличие повторений". Вот конкретные строки. И при этом я пытаюсь "с темы съехать"?
"создание массив, сортировка и проверка на наличие повторений", видимо, в количестве строк асма выражается, ясно, понятно.
тогда докажи, что добавленные строки это НЕ сортировка и проверка уникальности элементов с выдачей ошибки, если они не уникальные. Это даже в иссуе на гитхабе . Ты просто отрицаешь очевидное, https://github.com/rust-lang/rust/issues/104642
буквально написано что же там проверяется
тогда докажи, что добавленные строки это НЕ сортировка и проверка уникальности элементов с выдачей ошибки, если они ен уникальные
Может мне еще заодно доказать, что он ракеты на Марс не запускает?
За минуту можно найти, что "это НЕ сортировка и проверка уникальности элементов с выдачей ошибки, если они ен уникальные":
/// This checks every index against each other, and against `len`.
///
/// This will do `binomial(N + 1, 2) = N * (N + 1) / 2 = 0, 1, 3, 6, 10, ..`
/// comparison operations.
fn get_many_check_valid<const N: usize>(indices: &[usize; N], len: usize) -> bool {
// NB: The optimizer should inline the loops into a sequence
// of instructions without additional branching.
let mut valid = true;
for (i, &idx) in indices.iter().enumerate() {
valid &= idx < len;
for &idx2 in &indices[..i] {
valid &= idx != idx2;
}
}
valid
}

Внезапно, в дебаге и релизе код эквивалентен, значит отключи релиз и в дебаге увидишь вызов функции-проверки. Ах да, ты же уже видел этот код, просто зачем то продолжаешь щитпостить
В целом вы правы, однако индексы бывают неизвестными реже элементов массива. Поэтому над синтетическими тестами можно холиварить долго, надо брать что-нибудь реальное.
Кстати, почему вы считаете black_box неадекватным способом?
к слову, обычно разработчики проводят 99% времени в дебаге
поэтому полагаться на "компилятор все оптимизирует"...
Особенно критично для геймдева
Мне кажется, что искать в дебаге производительный код несколько странно. Для этого и придуман релиз режим, чтобы при разработке можно было код быстро компилировать, а чтобы в релизе код быстро работал. При желании можно сделать свой профиль, в котором будут и оптимизации (какого-то уровня) и дебаг символы. Я так свой трассировщик оптимизировал.
Оптимизации в дебаге выключают не потому что компиляторы такие злые, а чтобы программу можно было отладить по шагам. Соответственно, проблема медленного дебага не является чем-то уникальным для Rust, она случается в любом языке где есть эти самые оптимизации.
Ну и всегда можно выключить или включить оптимизации для конкретной библиотеки: https://doc.rust-lang.org/cargo/reference/profiles.html#overrides
Вставить в середину до сих пор нельзя
А это по вашему что такое? Api не стабилизировано, но тут проблема в том, что не нужны связные списки. И я слышал мнение, что не стоило его и добавлять, только место занимает и время отнимает от действительно полезных вещей.
всилу того как устроен язык и философия писателей его стандартной библиотеки
Да нет, просто не сдались эти списки никому. Не нужны они в 99.9999% случаев. Если вот прям ну уж очень хочется связный список, то я уверен, что можно найти на любой вкус и цвет на crates.io.
Цитата из документации Rust:
NOTE: It is almost always better to use Vec or VecDeque because array-based containers are generally faster, more memory efficient, and make better use of CPU cache.
Да нет, просто не сдались эти списки никому.
интересно как так получается, что именно то что в расте не работает внезапно становится никому не нужно?
Если вот прям ну уж очень хочется связный список, то я уверен, что можно найти на любой вкус и цвет на crates.io.
вот именно что нет и я сказал почему - потому что таков язык
Цитата из документации Rust:
ну конечно, они же не могут написать, что "наш язык не смог вырзить ни одной полезной операции на связном списке, поэтому его использование бесполезно"
Раз уж решили бросаться необоснованными фактами, то скажу так)
Да не нужна никому эта ваша безопасность. Да не нужна никому такая система типов. Да не нужен вообще никому Rust
Hidden text
как и C++ и С и все остальные
P.S: не знаю над какими проектами вы работаете, но в названии статьи Rust и C, поэтому в первую очередь приходит в голову системная разработка. А там связных списков... на каждом углу
не знаю над какими проектами вы работаете
Чтобы это узнать, можете, например, прочитать эту статью.
А там связных списков... на каждом углу
Это не столько мое мнение, это то, что написано в документации к списку в стандартной библиотеке Rust, то, что я слышал в серии видео Crust of Rust: std::collections и во всех остальных видео и статьях, например, CppCon 2014: Chandler Carruth "Efficiency with Algorithms, Performance with Data Structures" .
Да, пожалуй, говорить, что связные списки не нужны совсем - преувеличение. У них есть своя ниша - удаление или добавление элемента/ов туда, где прямо сейчас находится итератор. Во всех остальных случаях у него хуже производительность и это еще надо очень хорошо протестировать, чтобы понять, что это даст прибавку в скорости работы.
Вставка в середину связного списка это О(n), что чудовищно неэффективно.
Видимо, никому оно не пригодилось, раз не добавили.
Гм, гм, если на элемент связанного списка, после которого нужно вставить новый элемент, уже есть ссылка, то операция вставки - это O(1). Если есть только порядковый индекс i, то это O(i) - нужно "пролистать" до нужного элемента. В случае вектора же это в лучшем случае O(n-i), а в худшем (требуется реаллокация) это O(n). Связные списки имеют свои проблемы, но вот скорость вставки в середину у них ничуть не хуже, чем у вектора.
https://stackoverflow.com/questions/75965687/how-to-insert-a-element-into-a-linkedlist-of-the-stdcollectionslinkedlist-li
Вот тут обсуждение проблемы, в целом, можно написать связный список в котором сделать вставку через итератор. Но в стандартной библиотеки этого нет.
Но у меня вопрос, а в какой практической задачи это может потребоваться? Просто поиск того самого места в списке после которого надо элемент вставить, и так выполняется за линию. То есть, асимптотика все равно линейная на вставку.
P.S.
Linked list allocator не предлагать, это специфический кейс, он не покрывается стандартными контейнерами.
указателей там кстати нет (с точки зрения раста),
Тогда расскажите нам, несведущим, что же такое NonNull. Или вам так не нравится то, что создатели языка сделали так, чтобы даже в их unsafe приключениях нельзя было разыменовать нулевой указатель? Вот гады то какие, о корректности заботятся.
(del - я буду читать ветку целиком)
Ты приводишь олимпиадный код алогритма на С++ как агрумент?? Ну тогда давайте весь олимпиадный код с usingamи и <bits/stdc++.h> best practices запишем
получить за это потерю производительности,
это с каких пор доступ в линейную память стал аффектить производительность?
вырождается код при таких "разумных" требованиях языка.
тут было бы неплохо какие-то примеры привести ибо за всё время не сталкивался с подобными проблемами.
То есть переход на раст даёт невозможность писать интуитивно понятный код,
эта фраза вызывает ещё большее недоумение. Более интуитивного кода чем на расте не встречал в иных языках. JS в этом плане довольно похож, только в сотни раз медленее. Даже у питона больше квирков в этом плане. Тут похоже тоже нужны какие-то примеры. Пока у вас в коде не возникает необходимость теребить сырые указатели оно даже от C++ отличаться практически не будет, а это требуется на крайне специфичных задачах - едва ли вам каждый день требуется разворачивать односвязные списки.
это с каких пор доступ в линейную память стал аффектить производительность?
С тех, когда этот доступ принудительно проверяется на выход индекса за границу.
Вот на всякий случай ссылка на то, как избегать лишних проверок выхода за границу массива в Rust. Не думайте, что все просто "забыли" или "не знали", что такие проверки могут вредить производительности. Просто они решаются другими способами и без возможности добавить уязвимость в том месте, где производительность (и цена этих проверок) не важна.
Ага, только вот именно при хранении индексов вместо указателей эти способы и не сработают.
Не помогут эти, помогут другие. Да, не получится (точнее я не знаю как) как-то хитро доказать компилятору то, что какие-то числа из рядом лежащего словаря вот 100% в границах массива. У меня в коде в части про BFS не просто так assert!(curr_node_idx < self.nodes.len()); стоит. Этой проверки хватит для того, чтобы больше обращения по curr_node_idx не проверялись, т.к. он внутри цикла не меняется. А уж одна проверка на большой цикл это не так страшно, там и так куча условий, которые, скорее всего, сломают автовекторизацию.
Оно будет стоить ровно столько же сколько и проверка указателя на выходную ноду ( node->next ли, node->left/right ли) на null. Только в случае с линейной памятью компилятор вполне может сделать предположение о попадании в границы и выкинуть проверку, либо можно самому использовать unchecked версию. Ну и в C++ вполне существуют такие штуки как flat_map , которые для пользователя выглядят как std::map, но сами ноды при этом лежат последовательно в линейной памяти, снижая фрагментацию и как следствие уменьшая накладные расходы на выделение памяти.
Hidden text
use indextree::*;
use rand::Rng;
struct Foo {
_p: [u8; 256],
}
fn main() {
let mut linked_list = std::collections::LinkedList::new();
let mut arena = Arena::new();
let query = (0..1_000_000).map(|_| rand::thread_rng().gen_range(0..1_000usize)).collect::<Vec<_>>();
for _ in 0..1_000_000 {
linked_list.push_back(Foo { _p: [0; 256] });
}
let mut last_node = arena.new_node(Foo { _p: [0; 256] });
let first_node = last_node;
for _ in 0..(1_000_000 - 1) {
let node = arena.new_node(Foo { _p: [0; 256] });
node.append(last_node, &mut arena);
last_node = node;
}
let time = std::time::Instant::now();
for i in &query {
let _ = std::hint::black_box(linked_list.iter().skip(*i).next());
}
println!("Linked list: {:?}", time.elapsed());
let time = std::time::Instant::now();
for i in &query {
let _ = std::hint::black_box(first_node.descendants(&arena).skip(*i).next());
}
println!("Indextree: {:?}", time.elapsed());
}
Linked list: 589.368393ms
Indextree: 1.937983msЗато прыгать по указателям быстро 😁
Ну вот вам пример из стандартной библиотеки, объясните в чём "интиутивность" этого кода и почему используется Option<NonNull вместо T*

Не, ну раз стандартными библиотеками меряться, то расскажите как вот это
можно считать интуитивным

Или такое. Или может 9 способов инициализации можно назвать интуитивными? Как насчёт правила пяти-трёх-ноля?
NonNull гарантирует, что данные по указателю непусты, что можно использовать как терм для borrowchk/chalk, что в свою очередь позволяет в определённых ситуациях инлайнить код и выполнять прочие оптимизации. Это сильно не рядовой код, который будут писать далеко не все, также как и глубоко шаблонный код как в стандартной библиотеки плюсов с кучей трейтов, концептов и прочих прелестей SFINAE.
Отличие в том, что за каждым словом в приведённом вами кодом есть смысл, а вот за Option<NonNull смысла нет, это просто костыль. Фантом дата тоже. А вы по сути придрались к неймингу в максимально оптимизированном цикле
смысла нет, это просто костыль
я бы сказал, что вы просто не умеете его готовить. Haskell или, прости господи, TypeScript делает аналогичные вещи постоянно, однако почему-то программирование на типах в Rust внезапно становится бессмысленным. Как насчёт плюсовых [[assume(x)]] или [[no_unique_address]]? Ровно те же костыли, только на уровне языка, а не на уровне типов. Разница лишь в том, какие проблемы решаются подобными "костылями". Rust не страдает от use after free, поэтому решает другие проблемы с временем жизни своим способом . Придумаете вариант лучше - расскажите миру.
Ну и речь шла не за нейминг, а за интуитивность кода. Это не считая того, сколько по времени имплементируются разные версии плюсовых стандартов в разных компиляторах. И это я ещё куски какого-нибудь буста не предлагал смотреть.
Ну и речь шла не за нейминг, а за интуитивность кода
а что вам так кажется неинтуивным? Я первый раз читаю его и он вполне понятный, за исключением вербозных имен.
При этом я не спорю что код плюсовой std ужасен в некоторых местах.
Это не считая того, сколько по времени имплементируются разные версии плюсовых стандартов в разных компиляторах
Ну тут сложно сравнивать с растом, потому что у плюсов есть груз ответственности за прошлое. У раста он значительно меньше.
Что тут говорить, насколько я знаю, у раста нет стабильного аби. А это ой как усложняет развитие плюсов
Я первый раз читаю его и он вполне понятный, за исключением вербозных имен.
Ну, например, почему там итератор, да ещё определённого типа который с difference_type бодается, и перемещение через iter_move, а не как выше там предлагали указатели хоба-хоба и в дамки. Из названия и кода в среднем понятно, что код делает, но сама структура алгоритма при этом далеко не самая интуитивная. И чем более шаблонный код, тем дальше мы отдаляемся от бога.
Те кто достаточно бородат, вероятно, понимают причины почему архитектура стандартной библиотеки устроена подобным образом, но многие кейсы определённо не самые интуитивные. Например, внедрение сортировки без ветвлений до сих пор у меня вызывает вопрос, а собственно, каким образом количество ветвлений уменьшилось. Застрять с разбором можно надолго. Для сравнения - исходная статья, которая сподвигла добавить это изменение. Сравните, насколько код в статье интуитивно понятнее.
Хотелось бы увидеть какой-нибудь практический пример.
Например, объект ‘from', который владеет контролами, списками групп навигации, аксессибилити метками. Контрол-список владеет несколькими элементами - тоже контролами, которые ссылаются на узлы модели данных. Формы ссылаются на сфокусированные контролы, а метки хранят ссылоки на контролы. Между моделью и элементами формы работает подписка на изменения.
Как эти структуры данных выражаются в виде умных ссылок раста. Как lifetimes и borrow checker предохраняют от случайного шарения контрола между списками, включения группового контрола в самого себя, случайного включения одной и той же метки аксессибилити два раза в форму, других нарушений логической структуры.
Как в Расте предлагается обрабатывать эту структуру данных многопоточно?
Собственно, вариантов несколько, и хороших среди них нет.
Встречный вопрос: а как это сделать на Си или на плюсах? Очевидный ответ (везде хранить указатели на контролы) не совсем правильный, потому что приводит к потенциальным use after free сценариями (собственно, поэтому на Расте это не сделать без ансейф).
Я бы сделал список или словарь контролов отдельно, и везде в дереве, подписках и accessibility метках хранил бы идентификатор контрола.
В языке программирования Аргентум это делается тривиально: владеющие ссылки из формы к контролам и из списка к элементам, перекрестные не владеющие между контролами и из модели к контролам и все работает само. Поэтому мне хотелось узнать у любителей Раста, как это делается у них. Получается, никак. Тогда непонятен хайп.
Как минимум покажите код который люди могли бы запустить. Как максимум - напишите мини тз, что программа должна делать. Потому что с большой вероятностью ваши идеи о владении одного объекта другим будут декомпозированы в Rust и будут логически выглядеть иначе, чем вы ожидаете.
Ок. Мини тз. Нужен гуй состоящий из контролов разных типов - кнопки, лейблы, списки. Списки тоже содержат контролы. Можно считать, что форма - тоже контрол. В процессе работы приложения состав контролов постоянно изменяется: списки очищаются и перезаполняются, кнопки добавляются и убираются с формы. Контролы часто ссылаются друг на друга т.к. один может фокусировать другого или дизейблть или кнопка может очищать список. На один из контролов извне ссылается менеджер фокуса чтобы передавать ему нажатые кнопки. Некоторые контролы ссылаются на битмапы и шрифты. Как эту модель данных описать в Расте?
все работает само
Язык программирования Аргентум -- это язык со сборкой мусора? Или объект хранит в себе список невладеющих ссылок? Иначе как убедится, что при удалении объекта невладеющая ссылка станет невалидной?
Так то и в Rust можно сделать, правда, с небезопасным кодом, абсолютно аналогично, ссылки ("владеющие" в вашей терминологии) на дочерние контролы, и указатели везде в других местах. Да, это можно инкапсулировать, и это тоже будет "работать само" прямо как в языке программирования Аргентум, но это все будет на совести разработчика библиотеки.
В общем случае нельзя хранить две ссылки на объект и иметь гарантии их валидности при удалении (не ну можно, конечно, хранить список всех слабых ссылок, но производительность будет под вопросом). Собственно, поэтому в Rust такие сложности с циклическими структурами данных.
Ag синтаксически различает ссылки-локальные переменные и ссылки-поля объектов и разрешает только одну ссылку-поле на mutable объект, что предотвращает циклы, утечки и нарушения логики приложения, делает нужным GC и не требует unsafe режима. Это встроено в синтаксис и систему типов и проверяется во время компиляции. Пассаж по слабые ссылки не понял, они есть в Расте и они совсем не дорогие.
Год назад вернулся на системные языки программирования после 16 лет перерыва, выбирал между Rust и C++. За плюсы у меня в первую очередь было то, что я на них до ухода в дотнет как раз и программировал. Очень заманчиво и логично было бы начать новый проект на Расте, но поискав, я понял что плюсы для проекта больше подходят(стоп, не кидайтесь помидорами, не спешите). Плюсы уже подзабыл и начало было очень болезненным, особенно после 16 лет на комфортном дотнете. Снова подумал взять таки Rust и не мучаться. Но нет, почитал, поискал опять, и купил 9 книг по плюсам и околоплюсовым темам, метапрограммированию, многопоточному программированию, структурам данных, алгоритмам на плюсах, cmake, best practices и т.д.. Шесть уже прочел, осталось три,но самое тяжелое позади, теперь начинается кайф. У меня всего год заняло нормально погрузиться в язык и экосистему, все таки многолетний опыт, в том числе с самими плюсами, очень помогает, но все ж таки год чтения толстенных технических книг не каждому по нраву, понимаю, многим хочется здесь и сейчас, просто творить и не особо сушить мозги. Однако сейчас я на Раст уже не перейду, потому что C++ - это мощнейший инструмент, даже если Rust - тоже неплохой инструмент. Некоторых больших фич, которые есть у плюсов я в Расте просто не нашел. Вот о них и хочу спросить, может я что-то не так понял, поправьте меня.
Метапрограммирование. Я так понял, в Расте есть макросы для генерации шаблонного кода, но таких вещей как спецификация темплейтов(для классов), концепты, SFINAE(это хак, но такой полезный, по сути - спецификация темплейтов для функций). Еще много чего, это большая, сложная тема - и это 1/3 языка С++. Однако это самя мощная фича плюсов, не просто так ведь вся стандартная библиотека на темплейтах и написана. Эта часть действительно очень сильно выделяет плюсы среди других языков, которые все примерно об одном и том же(как и остальные 2/3 самих плюсов), где-то чуть лучше, где-то чуть хуже, но таких мощных темплейтов нет почти нигде, кроме еще пары небольших языков, которые действительно маленькие и вряд ли "выстрелят"(Zig, например).
Все аргументы в спорах сводятся в основном к памяти. Но как я уже упомянул, треть мощи С++ - это темплейты, этой трети вообще нет в Расте, увы. Ну и по-поводу памяти, безопасность-то безопасностью, ну а как в Расте со спецификацией аллокаторов памяти? Это очень небезопасно вообще-то, но это дает мощнейший буст по производительности практически в любой системе, потому что аллокаторы по умолчанию - ни рыба, ни мясо.
Далее, очень важный аспект современного софта - многопоточность. Как в Расте вообще с атомарными данными/операциями(иногда называются volatile), как там сделано разделение на release/acquire/relaxed операции? Кстати, тут особо важно иметь возможность кастомной аллокации, потому что лок-фри структуры данных в этом часто нуждаются, а это ведь не безопасно, значит думать придется.
Еще я несовсем понял часто приводимый здесь аргумент про индекс массива и контроль языка над тем чтобы не выйти за рамки массива. А как тогда индексы проверяются в рантайме на динамических данных? Путем if(i >= 0 && i <= count) ? Если да то, извините, но это защита стоит процессорного времени, причем при каждом обращении к массиву. Если нет, тогда в чем заключается безопасность? Вы точно так же можете поломать данные, переполнить буфер(да, тоже интересный момент, а в Расте что, нельзя уйти в stackoverflow при рекурсии на динамических данных? Конечно можно, и дело тут не в Расте, а в архитектуре машин). Звучит это все для меня как обычный дешевый маркетинг, с этой вашей "безопасностью". Я за 16 лет дотнета видел уже не раз как умельцы хоть на самом безопасном языке делают такие дырявые, протекающие и падающие сервисы, что дубу даешься. А все потому - что мозги отключены, безопасно ведь, зачем думать.
Еще не раз тут видел очень важный пункт от автора статьи, что плюсы компилируются с дата рейсами. Я так понимаю в расте не развиты атомики(volatile), и я сильно сомневаюсь что компиляторы раста имеют хорошую поддержку атомиков для разных платформ. Поправьте, если что, интересно как там дела с этим. Если Раст определяет все нестыковки при работе с данными на всех архитектурах при несинхронизированных атомарных операциях, то извините, Раст это не просто лучший язык программирования, это что-то не от мира сего, на голову выше плюсов. Но что-то я сомневаюсь. Но вообще, есть статические анализаторы. И если уже взялись многопоточный код писать, то лучше уж мозги включить, чем на компилятор полагаться, а то накодите.
И самая важная фича С++ это - специалисты. Это не хайп-платформа, которая предназначена решить все проблемы мира и сразу, это очень глубоко развитая экосистема, над которой все еще работает множество специалистов высочайшего уровня. Да, меньше маркетинга, меньше хайпа, но ни С, ни С++ в этом особо и не нуждаются.
Отвечу на что смогу:
насколько я помню, все коллекции в Rust - дженерики относительно аллокатора, так что его можно менять как для отдельной коллекции, так и глобально;
в Rust атомики, насколько я понимаю, +- скопированны с плюсов, точно так же можно задавать Ordering;
ну да, +-
if(i >= 0 && i <= vec.len()). Только это нужно только для доступа по индексу, что благодаря очень хорошо развитым итераторам не нужно. А в итераторах все проверки уже сделаны, при итерировании их уже не будет;не знаю, читали ли вы статью до или после того, как я дополнил часть про "Fearless concurrency", там я более подробно расписал гарантии Rust в плане многопоточности. Вкратце, в safe Rust невозможны гонки данных (не путать с состоянием гонки), что, по моему мнению, упрощает написание многопоточного кода в разы;
Rust это уже тоже давно не про хайп. Он уже есть в Linux, он используется в Google, Facebook, Cloudflare и т.д. в тех местах, где ни C, ни C++ не справляются.
Насколько Rust "не просто лучший язык программирования, это что-то не от мира сего, на голову выше плюсов" решать вам. Я уже давно для себя решил, что Rust - это язык, который очень многие вещи делает правильно. И это делает его как минимум одним из самых лучших языков (и точно лучшим из тех, что я знаю).
Rust это уже тоже давно не про хайп. Он уже есть в Linux, он используется в Google, Facebook, Cloudflare и т.д. в тех местах, где ни C, ни C++ не справляются.
смешно, как определили что "не справляется"? Это же и есть хайп, когда пытаются везде сунуть хотя бы немного, а потом делают из этого статьи и рекламу. Никто не делает рекламу из того что гугл каждый день запускает несколько проектов на С++
Думаете все эти компании контролирует некая тайная клика фанатов раста, которая "ради хайпа" заставляет запихать то тут, то там проект на расте? Что значит "делают из этого статьи и рекламу"? Делают рекламу чему? Собственному использованию языка?
Гугл же зачем-то переписал свой сервис с C++ на C++ 3 раза перед тем, как на четвертый переписать на Rust.
А Cloudflare в том числе использует Rust потому, что Nginx слишком медленный:
As Cloudflare has scaled we’ve outgrown NGINX. It was great for many years, but over time its limitations at our scale meant building something new made sense. We could no longer get the performance we needed nor did NGINX have the features we needed for our very complex environment.
какого языка нет в Google, Facebook, ..., думаю что только Brainfuck-а :)
Если уж про Google упомянули, то думаю что Go там больше чем Rust :)
это защита стоит процессорного времени, причем при каждом обращении к массиву.
Если компилятор сможет убедиться, что код в принципе не может выйти за пределы массива, то рантаймовые проверки будут выкинуты за ненадобностью. Вот целый пост был об этом https://habr.com/ru/companies/otus/articles/718012/
Да, поэтому я упомянул что речь о динамических данных. Там как ни крути, безопасность можно реализовать только за счет рантайм проверок. Если это так, то это уже не zero cost abstraction, поэтому и интересен этот момент. Тут либо ложное чувство безопасности, либо безопасность за определенную цену, я пока не вижу других вариантов.
Ну, от языка это уже не зависит, в сишечках будет то же самое, только сишечный компилятор уже не проконтролирует корректность кода.
Если очень хочется, можно проверить длину динамического массива один раз перед работой с ним, тогда, как описано в том посте, компилятор скорее всего сможет понять, что проверка уже выполнена, и свои проверки добавлять не будет.
Если очень-очень хочется, можно использовать unsafe-методы для обращения к массиву без проверки — только вот скорее всего не нужно
концепты, SFINAE
Чисто из интереса, зачем вам нужен SFINAE, если вам доступны концепты? Есть какие-то сценарии, которые концептами не покрываются?
Согласен, там масса других фич, которые можно было бы упомянуть. По-сути концепты исключают SFINAE и делают темплейты гораздо читабильнее плюс ускоряют компиляцию и читабельность ошибок инстанциации темплейтов(все мы знаем, какая это была боль до концептов). Я пока не нашел случаев, когда мне пришлось бы применить SFINAE вместо концептов, разве что на старых проектах, но это не мой случай
Вы ими то пробовали пользоваться как следует, а не поиграться? Концепты ущербные примерно такие же как лженерики(опечатался, а потом понял что это лучшее их описание) в расте. Без сфинае с++ шаблоны вообще ни о чём. Для самостоятельного курения почему я так считаю вам стоит попробовать реализовать аналог шаблон шаблона на концептах - это не возможно. Если убрать сфинае и параметр паки из с++ то его можно в тот же день закапывать. Единственное, что у страуса получилось так это шаблоны (и то случайно) и это то на что я купился ещё студентом 25 лет назад. Не будь шаблонов, я бы даже и не сунулся в плюсы.
под "шаблон шаблона" вы имеете ввиду template<typename> typename T?
вроде вполне можно использовать в концептах, я так делал функтор кажется
Объясните на примере?
Извините, я написал ответ, а сраный хабр его куда в дев нул отправил, а писал я долго и было обидно, но переписывать это с телефона я больше не буду - код на хабре с телефона это просто невыносимая боль. В кратце да, template<template...> для концептов не завезли, что делает их просто сахаром без принципиальных новшеств и менее выразительными чем то же самое на сфинае, но ниша для них есть конечно.
Так как интересовался, я отвечу.
Аллокаторы
В некотором "неконечном" виде, при этом как будут внедрять "конечный" вид аллокаторов непонятно, т.к. это потребует смены апи, аби и прочих интерфейсов
В стандартной библиотеке аллокаторы поддержаны лишь там, где это позволил сделать язык, например на расте невыразимо rebind_alloc, поэтому мапы (например хеш таблица) не поддерживают аллокаторы
https://doc.rust-lang.org/src/std/collections/hash/map.rs.html#213-215
Модель памяти (и работы с атомиками соответственно)
Полностью скопирована с С++, но заявляется, что "придумают лучше и внедрят", как можно внедрить позже целую модель памяти - я если честно не представляю. Но вот сами атомики, это уже нечто странное. Если в С++ это шаблон, то в расте на разных архитектурах есть разные атомики, все они вручную написаны т.е. AtomicInt32 AtomicInt64 и так далее, а если атомик не является локфри, то его на платформе не будет.
Более того, есть такие прецеденты типа под линуксом у AtomicInt32 будет функция, а под windows не будет или будет у другого типа, честно говоря это как-то абсурдно
Проверка индексов в массиве
Да, просто проверяется на рантайме и бросает местное исключение. Т.е. то что в С++ можно включить флагом компилятора и работает в дебаге само. Насчёт рекурсии аналогично, бесконечная рекурсия == сегфолт в safe расте. Они пытаются это решить требуя от платформ (!!) вставлять в конец стека guard pages, но это само по себе смешно, язык требует от микроконтроллеров как то себя вести
Невозможность гонок данных
Организуется через форсирование копирования, излишних синхронизаций (шаред поинтеры, мьютексы), любой "многопоточный" код в safe вырождается либо в использование готовых функций, либо в очень неэффективный код, при этом dead lock/live lock и утечка памяти это всё ещё 'safe' код, т.е. могут произойти (я уж промолчу про то, что unsafe блоки в зависимостях могут и содержат ошибки)
Спасибо, снимает некоторые вопросы, о том как Раст работает. Я пока не зарывался в эту тему, но делаю периодически селф-чеки, чтобы понимать, на правильном ли я пути.
Еще вопрос, возможно ли в Расте получить болтающиеся указатели? Например передаем ссылку на переменную со стека в лямбду(или какой у Раста аналог лямбд?), лямбду передаем куда-то еще, удаляем фрейм со стека, вызываем лямбду и вуаля. В принципе такое легко покрывается статическими анализаторами, да и просто культурой разработки, но неужели в Расте такого не бывает? вижу три варианта: там встроенный статический анализатор, там все создается на стеке, там нельзя передать куда-либо ссылки на переменные со стэка. Резонный вариант был бы - статический анализатор, но такое и в плюсах, и в С есть.
По-поводу "невозможности" гонок данных. Примерно как я и подозревал, вся инженерия спрятана за красивым фасадом с табличкой "не влезай убьет" и сделана максимально безопасно получается(синхронизация кешей процессоров и основной памяти). Тогда как же использовать преимущества архитектур, где можно кучу времени сэкономить на несинхронных операциях?
С типами данных под каждый атомик - беда. Какая все таки мощь плюсовые темплейты. Они же - ужас, боль и страдание для новичков.
"там все создается на стеке " - я имел в виду на куче, извиняюсь
Уже раз наверно десятый я рекомендую цикл лекций Алексея Кладова. 13 лекций по полтора часа скорее всего ответят на все ваши вопросы и даже больше.
передаем ссылку на переменную со стека в лямбду
Не скомпилится, компилятор заявит, что значение не живёт достаточно долго
Резонный вариант был бы - статический анализатор, но такое и в плюсах, и в С есть.
Есть только если разработчиков заставить. А это в любом случае вероятностный процесс, человеческий фактор и вопрос культуры "да я 30 лет уже программирую, что мне этот анализатор скажет".
А тут будет из коробки и неотключаемое.
ну конкретно указатель невалидный получить можно, есть std::ptr::dangling который буквально его вам и вернёт. Для указателей все проверки отключены, они только для ссылок. "защита" осуществляется через то, что для разыменования указателя нужно написать unsafe
например на расте невыразимо rebind_alloc, поэтому мапы (например хеш таблица) не поддерживают аллокаторы
Уж точно не по этой причине. Поскольку аллокаторы Rust оперируют блоками байт, а не указателями на объект конкретного типа - им этот rebind_alloc попросту не требуется.
Более того - стандартный HashMap это обёртка над библиотекой hashbrown, в которой поддержка аллокаторов таки есть.
Организуется через форсирование копирования, излишних синхронизаций (шаред поинтеры, мьютексы), любой "многопоточный" код в safe вырождается либо в использование готовых функций, либо в очень неэффективный код, при этом dead lock/live lock и утечка памяти это всё ещё 'safe' код, т.е. могут произойти (я уж промолчу про то, что unsafe блоки в зависимостях могут и содержат ошибки)
Если вы способны писать свои собственные lock-free алгоритмы - вам никакой Rust не помешает этого делать. А если не способны - то какие у вас, собственно, альтернативы этим самым "лишним" копированиям?
На расте писать так же занимательно, как продираться сквозь спойлеры в вашей статье :)
А если серьезно, спасибо за ряд любопытных ссылок и источников — я как раз из разряда тех, которые:
Я просто иногда пишу на нем разные вещи для развлечения и смотрю умные лекции на ютубе в надежде стать умнее
поэтому некотрые материалы схоронил себе на изучение
Не могу не добавить некоторые пункты про Раст, которые не позволяют ему заменить Си (пока, надеюсь, что со временем исправят). Конечно, надо отметить, что сам стандарт Си не все покрывает, что-то есть в C++, но тоже не все, и некоторые вещи работают только с gcc/clang extension:
отсутствие likely в stable (https://internals.rust-lang.org/t/could-unlikely-and-likely-be-stabilized-in-std-hint/9795?u=lzutao). Уже пять лет, а воз и ныне там. Официальный способ - #[cold], но это не покрывыет все потребности. Нужно для избежания branch misprediction.
alignment на уровне полей структур. В принципе не критично, т.к. можно разбить на подструктуры, но это может поломать совместимость с Си. Нужно для эффективного использования CPU cacheline.
Нефиксированный порядок полей в структурах. Можно считать как плюсом, так и минусом (Rust может более эффективно упаковать поля в структуре), но для высокоэффективного кода приходится применять соответствующие аттрибуты, чтобы это отключить. Опять-таки не критично, но нужно знать.
Отсутствие некоторых высокопроизводительных функций в std, например rint (https://en.cppreference.com/w/c/numeric/math/rint). С другой стороны, `
to_int_unchecked` использует LLVM’s fptoui/fptosi (https://doc.rust-lang.org/std/intrinsics/fn.float_to_int_unchecked.html), так что это может быть не проблема.
Опять-таки, это нужно для очень высокопроизводительного кода, когда идет счет на такты процессора, для абсолютного большинства программистов это не нужно. И Раст в этом плане не так уж плох, тем более есть использовать nightly, в котором есть все что надо.
Вопрос библиотек тоже стоит, например, использовать uring_io несколько проблематично. tokio_rs добавляет кучу абстракций, которые реально замедляют код (опять-таки, для большинства будет нормально, я ссылаюсь на ситуации когда нужны гигабиты в секунду). moniui более или менее нормально, но сыроват. А напрямую binding-и писать занимает время.
отсутствие likely в stable
Для каких задач это прямо важно? Современные процессоры такие чудеса с предсказаниями творят, что диву даёшься (амд вон псевдорандомные ветки предсказывать умеет), и я думал, что эти хинты процессоры всё равно игнорируют. И разве это PGO/BOLT не позволяют подкрутить уже после компиляции, по результатам профайла реальной работы?
Не все процессоры одинаково хороши, есть и ARM-ы. И этот хинт не для процессора, а компилятора, чтобы он поменял блоки и применил другие оптимизации, чтобы был лучше fall-through rate (т.е. более вероятные блоки кода вверху, безо всяких goto/jmp). И даже у Intel могут быть проблемы (Intel® 64 and IA-32 Architectures Optimization Reference Manual Volume 1):
Since only one taken (non-fall-through) target can be stored in the BTB, indirect
branches with multiple taken targets may have lower prediction rates.
PGO не особо подходит для сложных систем или сложен к использованию (например, для прошивок). Ну а применения:
логгирование и трассировка, которые включаются в ран-тайм, нам никогда не нужно чтобы они были в приоритете;
маловероятные ошибки (например, eventfd_read в горячем коде);
маловероятные внутренние состояния подсистемы.
И да, это не нужно абсолютному большинству программистов, но есть те, кому это нужно. В ядре Линукс:
$ grep --include "*.c" -rni "unlikely(" ./ | wc -l
19878
Спасибо за подробное объяснение, я был уверен, что подобные оптимизации давно уже на автомате компилятор находит и делает, но видимо те, кто меня в этом убедил могли ошибаться.
Позвольте еще немного добавить, т.к. немного покопал этот вопрос в ARM. Они поддерживают разные предикторы, и не все эффективно работают: https://developer.arm.com/documentation/100965/1120/Timing-Annotation/Timing-annotation-tutorial/Modeling-branch-prediction/Impact-of-branch-misprediction-on-simulation-time Думаю, выбор предиктора влияет на электопотребление, так что не всегда можно рассчитывать, что будет хороший предиктор.
И небольшое уточнение по прошлому посту. eventfd_read - это плохой пример, т.к. это тяжелый syscall, и branch misprediction на его фоне не будет так важен. Но в целом для горячего пути, особенно если много ветвлений и/или медленный/устаревший процессор, это может пригодится.
А там оно разве не по порядку следования веток оптимизирует? Просто писать самые вероятные ветки сверху и будет счастье?
Не будет, компиляторы достаточно свободно меняют порядок кода внутри. GCC использует собственные эвристики: https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html#index-fno-guess-branch-probability Rust тоже реорганизует код, не могу найти официальную документацию, но вот тут небольшая дискуссия: https://users.rust-lang.org/t/how-to-keep-pattern-match-branch-order/66363
В общем случае, лучше не делать выводов по порядку исполнения кода по тексту на высокоуровневом языке программирования (и Си - это высокоуровневый, низкоуровневый - это ассемблер или LLVM IR). Более того, даже машинный код может выполняться не по порядку из-за out-of-order execution (и это причина для memory ordering у атомиков).
Я пишу код больше 20 лет, разрабатываю сейчас cloud application на Go, поклонник unix way и не могу придумать зачем мне, как тех лиду, нужен rust на проектах.
Если говорить про работу в команде и синтаксис языка, то в идеале "код должен быть таким что бы смотря на него не было ясно кто его написал", на rust можно написать один и тот же код, кучей разных способов, как по мне это минус.
Если говорить про коммерческую разработку, тут важна не только скорость разработки, но и количество людей доступных на рынке и сложность поддержки проекта. Скорость разработки в том числе зависит от количества надежных библиотек вокруг языка.
На момент написания комментария на хабр карьере 5 вакансий rust разработчика и 197 вакансий на go разработчика.
Немного про async IO
node.js и Go из коробки поддерживают асинхронный ввод вывод (epoll, IOCP) надеюсь скоро в Go включат поддержку io_uring. Причем сам разработчик об этом и не знает, все происходит нативно. В rust же нужно использовать стороннюю библиотеку tokio.
Go из коробки имеет "горутины", которые автоматически масштабируются по количеству доступных процессоров. Если кто-то здесь изучал "параллельное программирование" тому известно что такое "переключение контекста" на уровне ОС и сколько это стоит. В rust насколько я понял используются системные потоки, со всеми вытекающими, а асинхронность Future однопоточная? Ну и немного цитаты из документации "Migrating from threads to async or vice versa typically requires major refactoring work"
Немного про shift-left-security
Мы в "компаниях" хотим безопасное по, для этого нам нужен SAST, DAST, SCA. SCA для go это govulncheck от самих создателей языка, SAST golangci-lint причем многие утилиты от самих создателей языка. Есть ли в rust подобная экосистема?
Закон Парето гласит, что во многих случаях 20% усилий дают 80% результата и я не вижу, где я могу применить rust в своей работе, что бы это было оправдано чем-то кроме "а давайте всё перепишем на rust". Надеюсь вы сможете меня переубедить :)
Надеюсь вы сможете меня переубедить :)
Да не зачем, вы отлично справляетесь, не обязательно всем быть первопроходцами. Вон у гугла, майкрософта и амазона ресурсов много, они и вкладываются.
Есть ли в rust подобная экосистема?
Конечно. И наверное одна из самых серьезных среди всех языков. Выше уже упоминали доклад про "безупречный" Раст для критических систем, там как раз рассказывают про всю обвязку для создания софта, ошибки в котором могут кого-нибудь убить.
Это оффтопик, и я точно признаю, что на Go иногда приятнее и быстрее писать, но есть нюансы, которые меня от него в свое время оттолкнули, и возвращаться к нему без необходимости я бы не стал (но приходится):
до generic, повсеместное использование
interface{}. Новый тип данных, но старый алгоритм - либо copy-paste, либоinterface{}.работа с модулями конечно стала удобнее, но все-равно не так удобно, как в том же Rust. `go mod vendor`, `go mod tidy` и т.д., все это не выглядит удобно по сравнению с другими системами.
goroutine не 100% безопасны, у нас были и leak-и и другие проблемы с ними.
неконтролируемый GC, проседания производительности на ровном месте, особенно если интенсивная работа с памятью.
большие бинарники (если статическая сборка). Правда Rust тоже не отстает, но его бинарники можно оптимизировать.
Но переписывать на Rust я бы 100% не убеждал. Мне в свое время зашел Zig, но там документация и сам проект достаточно сильно хромает, тоже нельзя рекомендовать. Плюс, есть CGo, который покрывает решения, где чистый Go может иметь проблемы.
кучей разных способов,
Тут вы правы - много способов, да ещё и без чтения манов риск написать некоторую дичь.
на хабр карьере 5 вакансий rust
Так начните вы нанимать.
node.js и Go из коробки поддерживают асинхронный ввод вывод
асинхронщина теперь есть у раста нативно, экзекуторов кроме tokio вагон и маленькая тележка (например smol), а вообще за состоянием этой экосистемы можно смотреть вот тут. Кстати, io_uring тоже уже можно использовать в какой-то степени.
Из минусов - говорят у раста проблемы с красными-синими функциями и действительно в определённых ситуациях придётся делать рефакторинг. Есть костыли которые пытаются с этим бороться, но я с асинхронкой в Rust особо не работал, поэтому детальнее про такое не расскажу.
которые автоматически масштабируются по количеству доступных процессоров
Вот это кстати очень забавный момент - опросы крупных игроков показали, что с большей вероятностью заспавнится однопоточный инстанс микросервиса в докере, нежели кто-то станет заморачиваться с многопоточным скейлингом в го.
В rust насколько я понял используются системные потоки, со всеми вытекающими, а асинхронность Future однопоточная?
По-умолчанию да, у многопоточности там обычные треды и каналы для общения. А вот асинхронность целиком зависит от экзекуторов, которых сходу штуки четыре-пять могу вспомнить (типа того же smol что выше). Какие-то умеют в многопточные пулы, какие-то прикидываются javascript рантаймом. Касательно цитаты - нужно уточнить от какого она года. Возможно сейчас ситуация заметно изменилась.
SAST, DAST, SCA
Сам компилятор как раз в качестве SAST. Есть варианты тестов, которые используют солверы для доказательства некоторых вещей, как например kani или proptest. Есть cargo-audit который смотрит на потенциально уязвимые зависимости. Возможно есть что-то более специфичное для SCA о чём я не слышал. Есть обёртки над AFL для фаззинга - часть DAST покрывает. Так что с безопасностью относительно неплохо обстоят дела. Даром все эти криптаны так бодро адаптировали Rust в своё время. Так что да, сесурити экосистема в наличии, причём часть этой экосистемы может применяться и для других языков.
где я могу применить rust в своей работе
всё зависит от задач. Если ваши облачные облака про перекладывание json и бесхитростные CRUD и при этом нет проблем с потреблением ресурсов, то Rust вам разве что экспериментов ради нужен. Go is your dude.
Постараюсь ответить на некоторые ваши вопросы
на rust можно написать один и тот же код, кучей разных способов
Слышал и видел обратную версию, из-за того, что нет такого слоя легаси, обычно только один явный способ что-либо сделать. Возможно вы имеете ввиду про функциональный(итераторы) или императивный стили, но тут более или менее понятно, если надо возвращать что-либо из функции, используем обычные конструкции if, match, for, иначе же можем использовать map, for_each(а когда, уже больше зависит от контекста).
количество людей доступных на рынке
Из-за того, что на рынке разработчиков Rust больше желающих на нем работать, чем самой работы, довольно трудно найти себе на нем работу, но если вы хотите нанять кого-нибудь, я думаю, это не составит большого труда. А если что-то пойдет не так, всегда можете заходить в тг чат по rust jobs (https://t.me/rust_jobs), там полно желающих)
количества надежных библиотек вокруг языка
Как говорили и в других комментариях, с этим всё неплохо. Могу добавить, что для тех же веб сервисов есть целая экосистема, тот же крейт Axum, который находится под Tokio, или же actix, который разрабатывается другими людьми. У actix были проблемы с unsafe кодом с предыдущим мейнтейнером, но их уже решили, поэтому теперь там его по-минимуму.
В rust же нужно использовать стороннюю библиотеку tokio.
Tokio де-факто стандартный рантайм для асинхронных приложений на Rust. В основном, люди считают это за плюс, что он не встроен в язык, так как всегда можно выбрать другой, который больше подходит под ваши цели (ну или вообще не использовать райнтайм, если вы пишите что-то низкоуровневое).
В rust насколько я понял используются системные потоки, со всеми вытекающими, а асинхронность Future однопоточная
В Rust вы можете использовать все варианты, которые хотите. Если у вас CPU-bound задачи, используют Rayon (нет overhead'а из-за асинхронности), если же у вас обычный веб-сервис, то используют tokio, который по-дефолту мультипоточный (пул потоков) и асинхронный (еще может перекидывать задачи с одного потока на другой).
Migrating from threads to async or vice versa typically requires major refactoring work
Если вы сразу же начнете писать в асинхронном стиле, проблемы это не составит.
Закон Парето гласит, что во многих случаях 20% усилий дают 80% результата и я не вижу, где я могу применить rust в своей работе, что бы это было оправдано чем-то кроме "а давайте всё перепишем на rust". Надеюсь вы сможете меня переубедить :)
Если у вас есть рабочий код, которые выполняет все, что от него требуется, и не требует постоянного рефакторинга, добавления новых фичей, то лучше его не трогать 😁. А если серьезно, то кмк стоит попробовать хотя бы для того, что лучше реализуются на самом Rust'е (микроконтроллеры, крипта, WASM, и т.д.). Возможно, если вам нужен будет супер-пупер производительный веб-сервер, да так, чтобы еще GC не портил статистику (привет, Discord), то это тоже неплохой выбор. Также, в интернете часто пишут, что работать с Rust более приятно, что у него лучше DX, чем у того же Go (обработка ошибок, и т.д.), но конкретно тут тяжелее объяснить преимущество для бизнеса, нужно пробовать самому и оценивать возможность использования по ситуации)
Подскажите, скомпилить Rust для микроконтролеров с 8К RAM выйдет? Так чтоб килобайт 6 под разные буферы осталось
Да, посмотрите на https://embassy.dev/.
Асинхронный (async/await) код работы с датчиком MPU6050, с прерываниями и DMA у меня занимает 800 байт RAM (не считая буферов). Микроконтроллер STM32F030.
К сожалению, не являюсь экспертом в Rust Embedded, но предполагаю, что теоретически возможно повторить всё то, что можно сделать на C. С таким малым количеством памяти, придется отказаться от std библиотеки раста, а ещё может быть и от core и alloc. Аллокатора либо в принципе не будет, либо какой-нибудь кастомный. Ещё пишут, что llvm должен быть в состоянии скомпилировать под эту платформу, а сам код на Rust можно будет скорректировать по ходу. Есть много информации в интернете, можно узнать информацию по конкретным микроконтроллерам. А вот несколько общих ссылок:
1) Rust Embedded Book: https://docs.rust-embedded.org/book/
2) Is Rust Ready for Microcontrollers?: https://www.elektormagazine.com/articles/is-rust-ready-for-microcontrollers
3) Rust as an alternative to C++ in microcontrollers: https://www.reddit.com/r/rust/comments/fpfmtv/rust_as_an_alternative_to_c_in_microcontrollers/
4) Using std in embedded Rust (для микроконтроллеров побольше и посовременней): https://blog.timhutt.co.uk/std-embedded-rust/index.html
5) Чат в телеграмме для железяшников Rust'а: https://t.me/embedded_rs <-- думаю, там гораздо лучше разбираются в данной теме и смогут ответить на такие вопросы
tokio, который по-дефолту мультипоточный (пул потоков
По дефолту онтоднопоточный... Многопоточный рантайм это opt-in фича
Ну да. Си и раст очень разные языки. Не понимаю зачем их сравнивать.
По-моему раст более верно сравнивать с плюсами.
И тут половина ваших фактов не имеет смысла, а остальная половина спорна
Кстати...
В Rust обработка ошибок крутая: если наловчиться, она позволяет писать код так, как будто этих ошибок вообще нет, но при этом они никуда не исчезают и всегда проверяются. В качестве примера приведу вот такой код:
Заголовок спойлера
let installed_apps: HashSet<String> = fs::read_dir(steam_library)?
.map_ok(|entry| entry.path())
.filter_ok(|path| path.is_file())
.filter_map_ok(|path| {
path
.file_name()
.and_then(|file_name| file_name.to_str())
.and_then(|name| name.strip_prefix("appmanifest_"))
.and_then(|name| name.strip_suffix(".acf"))
.map(|app_id| app_id.to_string())
})
.collect::<Result<_, _>>()?;Это ужасный код... В раст настолько крутая обработка ошибок, что у вас кода их обработки больше, чем логики программы. Как бы раст не пытался посыпать это сахаром, все равно смотрится как каша
Хотя бы ваш код внутри `filter_map_ok` . Сравните с чистой логикой
path.file_name()
.to_str()
.strip_prefix("...")
.strip_suffix("...")
.to_string()И нет, мне не нравятся неявные исключения как в C++. Я бы предпочел этот функциональный путь. Но этот код говорит только в минус обработке ошибок в расте.
У меня есть мысли по поводу этого. В плюсах непонятно откуда вылетает ошибка, а в раст чтобы было понятно создается новый контекст и вместе с ним отступы. В итоге получается лесенка.
У меня пока нет идей как создавать этот контекст, но при этом оставить код читаемым. Возможно это ограничений, которое не преодолеть не избавившись от кода в виде plain text.
И тут половина ваших фактов не имеет смысла, а остальная половина спорна
Можете привести примеры?
Это ужасный код
Красота в глазах смотрящего.
у вас кода их обработки больше
Мы, наверно, считаем "код для обработки ошибок" очень по-разному. Можете, пожалуйста, мне пальцем показать мне весь код, который как вы думаете отвечает за обработку ошибок. Я могу суммарно символов 10 указать.
Сравните с чистой логикой
Можете перечислить все возможные исключения, которые могут возникнуть в подобном коде на C++? Желательно всего кода, а не только той части, где нет ошибок и только опциональные значения.
Можете привести примеры?
### Ну вот ваш код на расте распаралеленный
Hidden text
let rows = img.rows_mut().collect::<Vec<_>>();
std::thread::scope(|scope| {
...
for (y, chunk) in rows.into_iter().enumerate() {
scope.spawn(move || {
...
for (x, pixel) in chunk.enumerate() {
let mut color = Color::default();
for _ in 0..samples_per_pixel {
...
}
*pixel = color.as_rgb(samples_per_pixel);
}
...
});
}
});
img.save("image.png").unwrap();На плюсах это пишется не сложнее. Примерно так:
std::ranges::for_each(std::execution::par,
rows | std::views::enumerate,
[](auto const i, auto const& el){
// logic
});Такая простая параллельность не будет сложнее даже если забыть про execution policy и написать на создании тредов как у вас. Скоуп решает растовскую проблему. В плюсах сделаете { } просто и в конце jthread сделает join().
В более старых плюсах есть тот же openmp, где через #pragma тоже легко делаются такие простые примеры распараллеливания.
Думаю тут не осталось сомнений, что в таком простом варианте, у плюсов и раста примерно одинаковые удобства и безопасность.
### Обработка ошибок
через монады есть и в плюсах. В стандарте в 20 и 23 вроде, в библиотеках много раньше.
Какие проблемы у монад я написал в первом комментарии. Это присуще и плюсам и расту - обработки больше чем логики(дальше покажу пальцем где обработка ошибок). Кажется более красивое решение я видел в haskell, где код с монадами превращается в обычный императивный наподобии C++ с исключениями, но с той же обработкой ошибок. С haskell я не очень хорошо знаком, поэтому возможно там свои нюансы.
### Факты
— Rust-команды настолько же продуктивны (как в разработке кода, так и в
поддержке), как и Golang команды и более чем в 2 раза более продуктивны,
чем C++ команды;
Слишком мало контекста. Какие команды, как измерялась продуктивность, это одни и те же люди в C++ и в Rust команде или разные.
Может и так. Тут могу только предположить что, так как раст молодой довольно, то и кодовая база его более молодая, а значит имеет намного меньше костылей/легаси/трудно поддерживаемого кода.
— 2/3 опрошенных разработчиков сообщили, что
спустя 2 месяца (или меньше) были достаточно уверены в знании Rust для
участия в проектах;
Какой у них бэкграунд? Многие C++ разработчики переходят на Rust. Очевидно, что опытный разработчик на C++ перейдет на Rust довольно быстро. Ведь Rust много и из C++ позаимствовал и многие ошибки C++ пытался решить.
По моему опыту - буквально все концепции раста были поняты мной очень быстро засчет бэкграунда в C++. Тут многие говорят, что в Rust есть лайфтаймы, которых нигде больше нет. И тут я отвечаю - в плюсах тоже есть лайфтаймы, в плюсах тоже приходится думать про время жизни. Да, они там неявны, но концепция знакома, поэтому в Rust легко понимается.
— 85% опрошенных разработчиков сообщили, что у
них выросла уверенность в корректности кода по сравнению с другими
языками программирования.
Я тоже вхожу в эти 85% . Тут все просто - Rust навязывает и заставляет писать правильный код, в отличии от большинства других языков. Те же C++ дают вам полную свободу - вы можете писать по указателю, который только что прочли из stdin, и при этом рядом же обрабатывать ошибки монадами как в раст. Полностью ваш выбор. Тут все завязано на good practice. То, что Rust навязывает их, я думаю, хорошо. Для опытных разница не особо велика. Для новичков сразу исключает шанс дезинформации/устаревшей информации о практиках.
### время компиляции
С чем действительно сложно спорить, так это с тем, что большие Rust-проекты компилируются долго. Иногда очень долго.
Тут все также с плюсами. Единственное что можно предположить, это то, что у C++ более долгая история решения этой проблемы. А значит Rust может заимствовать опыт и учиться на ошибках C++.
По сравнению с Си, в этом пункте и Rust и C++ проигрывают в треск.
### сложность
Что C++ что Rust сложны. Сложны по-разному. C++ имеет кучу подводных камней и неочевидных поведений, многое из этого унаследовано и с этим ничего не поделаешь из-за совместимости. Rust сложным, насколько я понял по множеству статей, кажется людям, которые переходят с языков вроде python. И причины тут очевидны.
Насчет Си - наверно под "маленький" имеются ввиду концепции в языке. В Си их очень мало. Когда я читаю код на Си, то я чаще всего сразу понимаю что он значит (я не о смысле в контексте задачи, а о смысле, который конструкция играет в семантике языка). Где-то тут видел код Option<NotNull<Node<T>>>. Не сразу понятно что он вообще значит. Ок, NotNull говорит что Node<T>* не NULL скорее всего, но зачем тогда Option, если там всегда есть объект. А если он есть не всегда, тогда зачем NotNull? А что вообще значит ситуация, когда Option == None , если там всегда есть объект?
Вообщем нужно покопаться, чтобы понять причины написанного. Тоже самое с PhantomData или Marker (как-то так называется). Неочевидный смысл, в Си такого не встретишь.
Можете, пожалуйста, мне пальцем показать мне весь код, который как вы думаете отвечает за обработку ошибок.
Я под обработкой ошибок понимаю считай весь код, который есть в вашей версии, но нет в моей. Ну то есть, вместо того чтобы писать плоский код, приходится добавлять and_then(|| ... ) . Это не я думаю, он и правда отвечает за обработку. Потому что если ее не делать(допустим это возможно), то код бы выглядел как в моем сниппете.
Можете перечислить все возможные исключения, которые могут возникнуть в подобном коде на C++? Желательно всего кода, а не только той части, где нет ошибок и только опциональные значения.
Поэтому я и сказал, что мне не нравятся исключения в C++. И добавил что предпочел бы функциональный путь Rust'а. Но он тоже не идеален. Я уже говорил о haskell, где код выглядит как в C++ с исключениями, но работает как Rust с монадами. Наверняка и ваш код на Rust можно сделать более красивым при этом сохранив всю обработку - тот же and_then не заменить на ? . Тут ошибаюсь возможно, не пишу на Rust на постоянке.
Параллельный код. Это (без иронии) замечательно, что в C++ можно написать так же удобно.
А вот про безопасность давайте поговорим отдельно. "В плюсах сделаете { } просто и в конце jthread сделает join()". А что будет, если не "сделать { }"? И что будет, если не "конце jthread сделает join()"? Потому, что в Rust это нельзя не сделать, код не скомпилируется. В обычные потоки (не scoped) нельзя передать не 'static объект (объект, который живет всю жизнь программы). И не в смысле пока жив main, но и после этого;
Что же из этой части в моей статье "не имеет смысла", а что "спорно"?
Обработка ошибок через монады
"Обработка ошибок через монады есть и в плюсах" И надо поддерживать как обработку ошибок монадами, так и исключениями одновременно;
"Какие проблемы у монад я написал в первом комментарии" Да не то, чтобы написали, кроме "Это ужасный код ... все равно смотрится как каша". Дело ваше, чувство прекрасного у всех свое. Меня же больше интересует практическая сторона вопроса, чем эстетическая;
Что же из этой части в моей статье "не имеет смысла", а что "спорно"?
Рефакторинг
"система типов в плюсах не слабее, чем в расте. Думаю с этим спорить бессмысленно". Не готов спорить, у меня нет достаточных компетенций в C++;
"Перечисления в плюсах это std::variant, паттерн матчинг это std::visit". То же самое, не готов спорить, но первый комментарий из первой ссылки из гугла, которую я открыл, с этим не согласен;
Что же из этой части в моей статье "не имеет смысла", а что "спорно"?
Факты
"Слишком мало контекста". Ответы на все эти вопросы вы могли бы получить просто посмотрев выступление, из которого эти тезисы;
"Rust навязывает и заставляет писать правильный код, в отличии от большинства других языков". Ужас то какой, заставляет писать правильный код. Как жить то после такого;
Что же из этой части в моей статье "не имеет смысла", а что "спорно"? Где хотя бы противоречие или несогласие, раз уж вы решили написать почти полторы тысячи символов по этому поводу?
Время компиляции
Видимо хоть в чем-то мы согласны, это уже неплохо;
Что же из этой части в моей статье "не имеет смысла", а что "спорно"?
Сложность
"Rust сложным, насколько я понял по множеству статей, кажется людям, которые переходят с языков вроде python. И причины тут очевидны" Причины настолько очевидны, что их и указывать не надо? И, кстати, будем знакомы, я как раз начал изучать Rust после Python. И я считаю, что Rust - простой;
"Насчет Си - наверно под "маленький" имеются ввиду концепции в языке". Это ему не помогает, в C приходится думать о слишком большом количестве вещей и из-за этого никто не способен писать безопасный код на C и/или C++;
"
Option<NotNull<Node<T>>>". Насколько я знаю, в стандартной билбиотеке плюсов код гораздо более нечитаем, тут же просто по переводу можно довольно точно понять, что происходит;"если там всегда есть объект". Потому, что не всегда там есть объект;
"А если он есть не всегда, тогда зачем NotNull?". Чтобы нельзя было разыменовать нулевой указатель;
"А что вообще значит ситуация, когда Option == None". Что объекта там нет;
"Я под обработкой ошибок понимаю считай весь код, который есть в вашей версии, но нет в моей". Допустим, мне вообще не кажется это важным;
"Поэтому я и сказал, что мне не нравятся исключения в C++". Тогда я не понимаю примера в вашем первом комментарии. Вы не хотите писать "ужасный код" для обработки ошибок как значений и вам не нравятся исключения. Вы хотите жить в мире, где ошибок просто не существует? Я тоже был бы не против, только пока такого не предвидится;
"Наверняка и ваш код на Rust можно сделать более красивым". В данном случае можно т.к.
filter_map_okпринимает замыкание, которое возвращаетOption. Получилось вот так:Заголовок спойлера
.filter_map_ok(|file_name| { file_name .file_name()? .to_str()? .strip_prefix("appmanifest_")? .strip_suffix(".acf") .map(|app_id| app_id.to_string()) })Мне по большому счету все равно. Код с
and_thenлучше тем, что ему не надо быть в функции, которая возвращаетOption. Может быть когда стабилизируют try_blocks так будет удобнее во всех случаях. Для меня большой разницы нет,Optionвсе равно придется как-то проверить и никакая магия не поможет избавиться от последнегоmap.
В итоге, вы написали очень много слов про C++. У меня в статье C++ упоминается 7 раз. 5 из них это цитаты (или перефразирование цитат) и еще 2 во вступлении. Так что я не очень понимаю, к чему эта гора текста про C++, про который я в статье не говорю? Кто ж виноват в том, что в статьях, из которых я брал тезисы, очень много сравнений с C++.
Я отвечал на пункты по мере прочтения и только в конце понял, что вы мне не противоречите нигде, кроме эстетической составляющей кода. На эту тему дискутировать я не хочу, мне в большой степени все равно, как оно выглядит. Пусть каждому нравится свой стиль кода, я не против.
А что будет, если не "сделать { }"? И что будет, если не "конце jthread сделает join()"? Потому, что в Rust это нельзя не сделать, код не скомпилируется
Ну если мы будем рассматривать ситуации "а что если", то можно рассмотреть и unsafe раст. Вообщем это бессмысленно.
Я говорю что в плюсах это можно сделать также безопасно и удобно как в раст и привожу пример кода. Очевидно, что хоть в раст хоть в плюсах можно сделать unsafe.
Но и тот и тот дают возможность писать безопасный код.
Поэтому ваш поинт про безопасность и удобство в этом конкретном случае для плюсов не имеет смысла.
И надо поддерживать как обработку ошибок монадами, так и исключениями одновременно;
почему же? я работаю над проектом, в котором отключены исключения.
Опять же, все зависит от кодовой базы..
Я лишь говорю что и плюсы это позволяют, поэтому этот поинт тоже не имеет смысла.
Да не то, чтобы написали
Hidden text
И нет, мне не нравятся неявные исключения как в C++. Я бы предпочел этот функциональный путь. Но этот код говорит только в минус обработке ошибок в расте.
У меня есть мысли по поводу этого. В плюсах непонятно откуда вылетает ошибка, а в раст чтобы было понятно создается новый контекст и вместе с ним отступы. В итоге получается лесенка
Я уже показывал сравнение чистой логики и вашего кода с обработкой ошибок. Вам кажется что второе выглядит лучше? И лучше читается?
Если да, то это правда ваше "чувство прекрасного".
но первый комментарий из первой ссылки из гугла, которую я открыл
нельзя сделать return, break, continue
да, не поспоришь)
а в чем проблема внутри лямбды писать эти if? Все равно они в раст тоже не учитываются при проверке:
Note that the compiler won't take guard conditions into account when checking if all patterns are covered by the match expression.
с первой же ссылки про guard clauses в раст.*
считать недостаток сахара проблемой? да ладно...
А теперь интересное - о том, что "variant это match из rust для бедных".
В std::visit я могу матчить типы нетолько просто по ==, но и по концептам/SFINAE. По-моему в расте так нельзя. Если у вас два варианта енама имеют одинаковый метод, то вам придется вызывать его для обоих вариантов отдельно.
Вообщем - что раст что плюсы имеют недостатки и преимущества в этом.
Поэтому, очевидно, этом пункт, как минимум, спорный. А, как максимум, учитывая что это лишь один пунктик про рефакторинг, и он - пунктик - почти одинаковый что в плюсах что в раст, то бессмысленный.
Ужас то какой, заставляет писать правильный код. Как жить то после такого
Вроде бы я высказал свое одобрение по этому поводу. Поэтому ваш сарказм тут не уместен, как минимум)
В итоге факт 1, 2 спорны, потому что это исследование. Вряд-ли кто-то проверял его правильность, а я этим заниматься не хочу уж точно.
Но посудите сами. Фраза "Rust-команды настолько же продуктивны ... и более чем в 2 раза более продуктивны, чем C++ команды" уже звучит как рекламный лозунг.
По-моему, не имеет смысла спорить с этими утверждениями. Пусть о таком думают менеджеры.
В итоге отступлю - факты наверно имеют смысл. По крайней мере, спорить с этим я не хочу.
Что же из этой части в моей статье "не имеет смысла", а что "спорно"?
про время компиляции*
мой комментарий к этому не относится. Я же сказал про сравнение C++ и Rust
Причины настолько очевидны, что их и указывать не надо? И, кстати, будем
знакомы, я как раз начал изучать Rust после Python. И я считаю, что
Rust - простой;
Вам неочевидны? Python засахаренный, с duck typing, без управления памятью.
Да, я видел что вы тоже на python писали. Но я сказал "многие" по своему опыту прочтения статей. Вы может исключение, а может и правило) Что толку спорить об этом, это снова исследования.
Про сложность в сравнении с Си мой комментарий первый тоже не относится. Он про сравнение с C++. А я просто пытался вам объяснить почему люди считают Си "простым". Безопасность тут вообще не причем. Таким же простым является Forth, хоть ни чуть не безопаснее, вроде бы.
Допустим, мне вообще не кажется это важным;
Ну.. чистый код читается легче. По-моему важно. Но оставим на ваше "чувство прекрасного".
Вы не хотите писать "ужасный код" для обработки ошибок как значений и
вам не нравятся исключения. Вы хотите жить в мире, где ошибок просто не
существует?
Я хочу жить в мире, где ошибки обрабатываются также как в вашем коде, но выглядит это примерно как в моем :) . Способа это сделать я не предложил. Может это мое "чувство прекрасного" или моя бессмысленная мечта.
В данном случае можно т.к.
filter_map_okпринимает замыкание, которое возвращаетOption. Получилось вот так:
Ну вот видите - выглядит также чисто как и мой сниппет. Вот в таком мире я хочу жить. Жаль только есть нюансы(
к чему эта гора текста про C++, про который я в статье не говорю
...печаль, и зачем я это писал
Я же сказал - ваша статья во многом сравнивает Rust с Си (или зачем такое название). Потом указал что это, как мне кажется, неправильно и предложил сравнивать с C++. Потом сказал что в сравнении с C++ ... "бессмысленны или спорны".
Вы ведь сами попросили примеры....
Я отвечал на пункты по мере прочтения и только в конце понял, что вы мне
не противоречите нигде, кроме эстетической составляющей кода
Ну да. Я ведь сказал, что Rust и Си слишком разные, чтобы сравнивать. Только глупец будет спорить с вашими фактами в таком виде.
Поэтому я предложил сравнивать с C++, а в таком виде большинство из них уже не являются "преимущестом Rust"
можно рассмотреть и unsafe раст.
Нельзя.
Принципиальное отличие раста от сишечек в том, что для написания небезопасного кода нужно СПЕЦИАЛЬНО, находясь в здравом уме и твёрдой памяти, приложить усилия и осознанно написать в коде слово «unsafe» — а «токсичное» Rust-сообщество ещё и заставит написать рядом «SAFETY:» комментарий с доказательством, почему этот unsafe не нарушит безопасность.
В сишечках можно написать небезопасный код СЛУЧАЙНО — по недосмотру, по невнимательности, по забывчивости, по неаккуратному рефакторингу. Так и появляется большинство багов и уязвимостей от простых сегфолтов до heartbleed.
Так всё-таки что будет, если СЛУЧАЙНО не выспаться и забыть "сделать { }"?
Так всё-таки что будет, если СЛУЧАЙНО не выспаться и забыть "сделать { }"?
покажите мне как вы случайно забудете скоп переменной, очевидно тоже не понимаете о чём речь
._.
что значит нельзя? Вы мне запрещаете?
Есть два языка, оба языка позволяют писать и безопасный и небезопасный код.
Но почему то в одном надо рассматривать ситуацию, когда какой-то недотепа допускает глупую ошибку, но в другом можно на это не обращать внимание, ведь там есть слово, которое его ТОЧНО остановит.
Послушайте. Если допустить ошибку можно, то она будет допущена.
Правду вы сказали про токсичность похоже)
Я тут даже не пытался никому доказать, что безопасность плюсов >= безопасность раста. Но всегда найдутся желающие похоливарить
«какой-то недотепа» в принципе не станет использовать unsafe в своём Rust-коде, потому что нафиг оно ему надо?
Я тут даже не пытался
Вы тут сами unsafe зачем-то приплели, хотя вас всего лишь про «сделать { }» спросили
простите, пожалуйста, что посмел возразить на ваш идол..
Я искренне извиняюсь и обещаю больше никогда не разговаривать с фанатиками ставить никакой язык на одну ступень с Rust.
Он поистине божественен, а я грешник и место мне в аду, где на каждом шагу меня поджидает segfault, а местный дьявол - C++ - не дает мне и шанса написать безопасный код)
Аминь
Вы бы определились уже со своей позицией, а то я только в комментариях к этой статье видел:
Есть два языка, оба языка позволяют писать и безопасный и небезопасный код и неявное продолжение, что ну раз можно, то и разницы нет;
что в таком простом варианте, у плюсов и раста примерно одинаковые удобства и безопасность к слову о "Я тут даже не пытался никому доказать, что безопасность плюсов >= безопасность раста" и несмотря на "В плюсах сделаете { } просто и в конце jthread сделает join()" вместе с отсутствием ответа на вопрос "что будет, если ... забыть 'сделать { }'?";
Я тоже вхожу в эти 85% . Тут все просто - Rust навязывает и заставляет писать правильный код, в отличии от большинства других языков. Те же C++ дают вам полную свободу 85% это про "85% опрошенных разработчиков сообщили, что у них выросла уверенность в корректности кода по сравнению с другими языками программирования", т.е. вы сами считаете, что Rust безопаснее.
Это Rust сообщество токсичное и фанатичное, конечно.
Особенно это смешно, если проследить за последовательностью событий:
что в таком простом варианте, у плюсов и раста примерно одинаковые удобства и безопасность вместе с "В плюсах сделаете { } просто и в конце jthread сделает join()".
увиливание от ответа на вопрос "что будет, если ... забыть 'сделать { }'?";
сравнение возможности "забыть { }" с unsafe Rust;
Я правильно понимаю, что этот код настолько же безопасен, как "безопасен" и unsafe Rust?
Но почему то в одном надо рассматривать ситуацию, когда какой-то недотепа допускает глупую ошибку, но в другом можно на это не обращать внимание, ведь там есть слово, которое его ТОЧНО остановит
А вы попробуйте привести пример, когда человек случайно не просто unsafe блок напишет, но еще и случайно напишет такой код, который UB вызовет (спойлер: unsafe блок не выключает никакие проверки, даже если его случайно написать, то ничего не изменится).
Но почему то в одном надо рассматривать ситуацию, когда какой-то недотепа допускает глупую ошибку, но в другом можно на это не обращать внимание, ведь там есть слово, которое его ТОЧНО остановит.
Потому что ситуации разные. В Расте можно не писать unsafe, и определенные ошибки будет контролировать компилятор. В Си ошибку можно получить в обычном коде, неудачно выполнив небольшое изменение.
то можно рассмотреть и unsafe раст
А можно и не рассмотреть. Unsafe не появится если забыть что-то сделать.
"variant это match из rust для бедных"
Не знаю, как у вас получилось, но вы проигнорировали самое важное предложение в середине комментария:
The match statement here will ensure, at compile-time, that I correctly enumerate all 4 possible combinations
Действительно, "что раст что плюсы имеют недостатки и преимущества в этом", вообще никакой разницы.
В итоге факт 1, 2 спорны, потому что это исследование
Просто замечательно. Я даже не знаю, как это прокомментировать.
ваша статья во многом сравнивает Rust с Си (или зачем такое название)
Ответ находится во втором абзаце моей статьи.
Вы ведь сами попросили примеры
Примеры "половины фактов, которые не имеет смысла, а остальная половина спорна", а не сравнения Rust с C++.
Поэтому я предложил сравнивать с C++, а в таком виде большинство из них уже не являются "преимущестом Rust"
Меня вы в этом не убедили.
Не знаю, как у вас получилось, но вы проигнорировали самое важное предложение в середине комментария:
позабыл как это прокомментировать
плюсы тут ничем от раста не отличаются, насколько я знаю - https://godbolt.org/z/o471ee66h
могу только восхититься что это реализовано не за счет компилятора, а за счет метапрограммирования.
Примеры "половины фактов, которые не имеет смысла, а остальная половина спорна", а не сравнения Rust с C++.
Похоже вы меня неправильно поняли, ну или же я неправильн объяснил.
Ваши факты, в основном, бесспорны и имеют смысл*
* в контексте темы статьи - Rust не просто безопасный Си.
Я имел ввиду что "половины фактов, которые не имеет смысла, а остальная половина спорна" в контексте сравнения с C++, потому что считаю сравнение Rust и Си бессмысленным и просто неправильным.
То есть, вы считаете, что эта статья о сравнение Rust и C (даже проигнорируем тот факт, что я так не считаю, просто часто это то, как люди воспринимают Rust. С Python и Golang сравнений больше), подменяете его своим аргументом "в контексте сравнения с C++, потому что считаю сравнение Rust и Си бессмысленным и просто неправильным" и пытаетесь разбить уже свой собственный аргумент? Да это же соломенное чучело.
У вас в названии написано Rust и C.
Мне ничего не нужно считать - это простое понимание или недопонимание
Я в первом же комментарии написал, что считаю некорректным сравнивать Rust и C, но вы почему-то указали на это только сейчас.
Я в первом же комментарии сказал, что считаю более корректным сравнивать с C++, и что в этом сравнении ваши факты намного более хрупкие. И вы попросили привести примеры, а теперь обвиняете меня в подмене понятий...
Если вы так не считаете, то и не просили бы примеры и не тратили бы наше время
плюсы тут ничем от раста не отличаются, насколько я знаю - https://godbolt.org/z/o471ee66h
Ну как сказать... https://godbolt.org/z/oxfz8vqcq
все еще не вижу отличий - https://godbolt.org/z/6znjoKq3n
лишь то, что плюсы в паттерн матчинге дают еще больше возможностей, чем раст
Это не возможности, это грабли.
Если я расширяю перечисление в Rust - язык мне подскажет все конструкции match которые мне требуется обновить. Если я расширяю вариант в С++ - язык мне ставит подножку и приводит что угодно куда попало.
Ну и сравнение количества "закорючек" в match и visit внезапно не в пользу C++.
Если я расширяю перечисление в Rust - язык мне
ничего не говорит, потому что стоит default
А вырожденные случаи можно выдумывать вечно, вопрос только зачем вы их написали
что значит "что угодно куда попало"
в коде ошибки написано все что нужно знать
вы либо не пишете на C++, либо для вас бы не было количество закорючек внезапностью)
конечно это не такие красивые ошибки как в новеньких языках, да и сахара в C++ поменьше, но что поделать, если таково бремя совместимости
когда-нибудь нам не придется писать на C++ и тогда все вздохнут с облегчением, но пока этого не произошло)
В плюсах сделаете { } просто и в конце jthread сделает join()". А что будет, если не "сделать { }"?
с каждым сообщением всё смешнее и смешнее. Покажите мне как вы сделаете переменную без скоупа)
Да по вашим комментариям можно целый курс по черри-пикингу сделать. Я даже название придумал - "Краткий курс черри-пикинга или как проигнорировать контекст дискуссии так, чтобы выставить своего оппонента максимальным идиотом".
Если вы забыли (или не знали) контекста и этой дискуссии, то давайте я вам (и всем, кто будет читать это после) расскажу:
у меня в статье есть пример кода, который использует потоки:
Заголовок спойлера
let rows = img.rows_mut().collect::<Vec<_>>(); std::thread::scope(|scope| { ... for (y, chunk) in rows.into_iter().enumerate() { scope.spawn(move || { ... for (x, pixel) in chunk.enumerate() { let mut color = Color::default(); for _ in 0..samples_per_pixel { ... } *pixel = color.as_rgb(samples_per_pixel); } ... }); } }); img.save("image.png").unwrap();Там же указаны гарантии языка для этого кода:
Заголовок спойлера
в этом коде нет гонок данных;
невозможно написать эту программу так, чтобы получить пересекающиеся задачи;
невозможно написать эту программу так, чтобы в момент
img.saveхоть один из потоков был бы еще жив.
feelamee на это пишет, что "На плюсах это пишется не сложнее" и "Думаю тут не осталось сомнений, что в таком простом варианте, у плюсов и раста примерно одинаковые удобства и безопасность". Если "В плюсах сделаете { } просто и в конце jthread сделает join()." с таким кодом:
Заголовок спойлера
std::ranges::for_each(std::execution::par, rows | std::views::enumerate, [](auto const i, auto const& el){ // logic });На это я отвечаю " А что будет, если не "сделать { }"? И что будет, если не "в конце jthread сделает join()"? Потому, что в Rust это нельзя не сделать, код не скомпилируется". Потому, что я точно знаю, что если не сделать
join()для обычного потока, то это чтение и запись без синхронизации, т.е. это сразу UB и сделатьjoin()автоматически при выходе из скоупа это, насколько я знаю, плохая идея.
В контексте все немного по-другому выглядит, не находите? Хотя кого я обманываю, даже в этой статье вы не раз, не два, не три, не четыре, не пять, не шесть, а семь раз пишете либо фактически неверные утверждения, либо манипулируете не знающим контекста читателем.
либо я вас неправильно понял
либо вы неправильно поняли мой изначальный комментарий
в моем сниппете с std::ranges::for_each не нужен никакой скоуп и забыть там ничего не получится.
Скоуп нужен если написать все создание потоков вручную примерно так, как это делает в вашем сниппете.
Так и написали бы об этом. Все, что в вашем примере кода говорит о том, что там уже есть многопоточность - это три буквы par. А, как в статье и написано, у меня 0 опыта в C++, я понятия не имею, что эта штука сделает. Вместо обвинений в токсичности лучше бы написали такой комментарий, он был бы гораздо полезнее для всех.
да вроде так и написано:
Такая простая параллельность не будет сложнее даже если забыть про execution policy и написать на создании тредов как у вас.
Ну ладно, наверно правда из-за вашей неопытности в C++
Вас я в токсичности не обвинял, я отвечал другому человеку, который сам о токсичности сообщества раста и сказал)
Хотя бы ваш код внутри
filter_map_ok. Сравните с чистой логикой
Да на самом деле можно примерно так и написать:
path.file_name()?
.to_str()
.strip_prefix("...").ok_or(...)?.
.strip_suffix("...")ok_or(...)?
.to_string()
Такой код не скомпилируется. to_string возвращает строку, а замыкание в filter_map_ok должно возвращать Option. Но можно сделать еще лучше:
Заголовок спойлера
.filter_map_ok(|file_name| {
let f = file_name
.file_name()?
.to_str()?
.strip_prefix("appmanifest_")?
.strip_suffix(".acf")?
.to_string();
Some(f)
})
Тема не раскрыта! В Расте, кроме всего этого, ещё и восхитительные дженерики, невероятно удобные и гибкие, а про это не рассказано.
Первое и второе, что сразу напрягает в Расте - отсутствие стандарта и длинный список зависимостей с номерами версий, начинающимися на ноль. Третье, что паттерны из С++ не годятся, надо переучиваться.
Первое и второе, что сразу напрягает в Расте - отсутствие стандарта
Есть референс https://doc.rust-lang.org/reference/
По нему фронт для GCC написан
длинный список зависимостей с номерами версий, начинающимися на ноль
Это хорошо или плохо?
Третье, что паттерны из С++ не годятся, надо переучиваться.
"Бесит программирование, надо постоянно учиться"
Разницу между описанием языка и стандартом, надеюсь, понимаете.
Библиотеки версий 0.х в промышленную эксплуатацию? Ну, что ж, удачи в отладке стороннего кода.
Не учиться, а переучиваться "отринув прежнее". Переход с Си на Си++ позволял учиться новому, не бросив на произвол судьбы тонны существующего кода.
Разницу между описанием языка и стандартом, надеюсь, понимаете.
Рекомендую использовать словарь для непонятных иностранных слов:
https://wooordhunt.ru/word/reference
тех. эталон, стандарт
Библиотеки версий 0.х в промышленную эксплуатацию? Ну, что ж, удачи в отладке стороннего кода.
Рекомендую прочитать что означает версия 0 в системе семантического версионирования: https://semver.org/lang/ru/
Да и в целом для чего вообще оно нужно.
Мажорная версия ноль (0.y.z) предназначена для начальной разработки. Всё может измениться в любой момент. Публичный API не должен рассматриваться как стабильный.
А какая разница между описанием языка и стандартом? Разве стандарт это не просто описание, которое какой-то формальный огран (типа ISO) сделал "официальным"?
Описание языка (референс) - текущее состояние с привязкой к компилятору. Стандарт (спецификация) - официально зафиксированный слепок на конкретный момент времени, которому должны соответствовать компиляторы, заявляющие о совместимости "на уровне стандарта ХХХ".
Описание языка (референс) - текущее состояние.
и
Стандарт (спецификация) - официально зафиксированный слепок на конкретный момент времени
Ух как приходится извиваться и добавлять новые сущности, чтобы разделить то, что является одним и тем же и использовать аргументы пятилетней давности, даже не открывая предоставленных ссылок. Выглядит плохо.
Переизобретение слов, вместо использования словаря тоже не оч демагогический прием.
Да и к тому же просто вранье:
которому должны соответствовать компиляторы, заявляющие о совместимости "на уровне стандарта ХХХ"
Имеено это и объявлено: The latest release of this book, matching the latest Rust version, can always be found at https://doc.rust-lang.org/reference/. Prior versions can be found by adding the Rust version before the "reference" directory. For example, the Reference for Rust 1.49.0 is located at https://doc.rust-lang.org/1.49.0/reference/.
текущее состояние с привязкой к компилятору
Опять вранье или "не читал, но осуждаю"
Similarly, this book does not usually document the specifics of rustc as a tool or of Cargo. rustc has its own book.
Finally, this book is not normative. It may include details that are specific to rustc itself, and should not be taken as a specification for the Rust language.
Неужели без вранья, манипуляций и изобретения сущностей из ниоткуда нельзя рассказать какой прекрасный и нерушимый С++?
Как раз про Раст и разницу между стандартом (спецификацией) и описанием (референсом): "What is the difference between specification and a reference for programming languages?".
Ребята ведь начали пилить RFC, хотя референс есть. Казалось бы, зачем, да? :)
Всего вам доброго
Это формальные определения от какого-то официального органа или неформальное понимание? И я уточнял разницу между стандартом и описанием. Стандарт и спецификация -- это одно и тоже?
Это хорошо или плохо?
Справедливости ради, тема действительно проблемная - есть довольно много библиотек, которые де-факто уже production-ready, но всё ещё имеют версию 0.x.y, которая воспринимается как экспериментальная. В результате становится непонятно, как помечать собственно экспериментальные версии.
С 0.X.Y версиями ситуация получается странная - даже если библиотека уже готова для использования в продакшен среде, то переход на 1.0.0 создаст много проблем с не очевидными выгодами. Менять мажорную версию без нарушений обратной совместимости странно, т.к. cargo автоматически не обновит версию с 0.X.Y до 1.0.0, что заставляет всех пользователей библиотеки делать это вручную. А из плюсов только то, что версия 1.0.0+ выглядит солиднее.
Надо как-то решать эту проблему. Если библиотека готова к промышленной эксплуатации, то версия не должна быть 0.х. Я общался с ребятами, которые делают сетевую среду с брокерами, "сообщники" им просто не дают поставить "единичку".
1.х тоже еще не признак зрелости, но хоть что-то. Оракл в свое время начал выпуск СУБД с версии 2, мотивируя тем, что никто не хочет пользоваться первой версией.
P.S. Никогда никого не "минусую"
Оракл в свое время начал выпуск своей СУБД с версии 2, мотивируя тем, что никто не хочет пользоваться первой версией
Так в этом и проблема. Сам по себе номер версии вообще ничего не значит. Изменение минорной версии не гарантирует, что у кода не изменилось API (хотя для этого есть помощники). Можно тогда просто на версии с датами перейти (вроде 2024.04.1), код надежнее это не сделает, зато выглядит солидно.
Пример Оракла единичен и, скорее, относится к профюмору.
Есть история версий, клиентская база и возможности поддержки (в т.ч. платной). Стандартная логика пользователей такая: 0 - ребята пока пилят что-то на коленке, можно даже им помочь, если есть силы, 1 - появились первые промышленные применения, 2 и далее - продукт оказался нужным и развивается
Согласно SemVer, до версии 1.0.0 совместимость имеет право сломаться в любой момент. Даже если изменилась только последняя цифра
Для простоты, можно считать все версии крейтов в Rust начиная с 0.1.0 (без суффикса -alpha. -beta) готовыми к продакшену. Обычно не только коммьюнити, но и мейнтейнеры считают, что могут еще переписать какую-либо часть проекта, а уже под версиями 1.0.0+ можно считать проекты, которые уже авторы и коммьюнити считают готовыми (и опять же, тут нет строгих рамок, как это считать). Ещё бывает, что когда версия переваливает через 1.0.0, то для каждой последующей начиная с первой (1.*.*, 2.*.*, 3.*.*) объявляют lts, давая еще большие гарантии стабильности для продакшена. А так, если честно, обычно кроме каких-то простых крейтов, где можно один раз написать код, и он будет работать, более сложные крейты требуют доработки в течение длительного времени, потому что часто выходят новые спецификации, делаются багфиксы, обновления зависимостей, поэтому и понятно, почему здесь так распространен ZeroVer (https://0ver.org/), особенно держа в уме, что многие крейты не так уж и давно начали разрабатываться.
В реальной жизни удобно ставить ограничение по мажорной версии, аля `crate_name = "0.6"`, что помогает получать багфиксы, новые фичи, при этом не получая breaking changes, которые возможны только при изменении той самой мажорной версии.
Но при этом уже есть отдельные библиотеки и фреймворки с версиями выше 1. Когда их критическая масса созреет, вопрос отпадет сам собой. Из того что я видел вживую, ребята пилят версию 0 за денежки корпорации, но потом корпорация меняет планы выпуска своего оборудования, библиотека больше им не нужна, она остается в гитхабе "сами разбирайтесь, если надо".
Rust — это не «memory safe C»