Comments 158
Благо мы живем не в 2010, а в 2022, когда уже есть CMake, кросскомпиляция, компиляторы которые умеют генерировать код под любую платформу, куча открытого софта и библиотек, если в 2010 годы было вообще непонятно как обеспечить поддержку проекта в хкоде и вижуалстудии, то сейчас это делает щелчком пальца, ну почти. Сложность разработки кроссплатформенных программ понизилась в разы, если не на порядки. Даже для внутренних программ поддержка мака и виндовс считается чем-то самой собой разумеющимся. Так что если будут две конкурирующих платформы станет только лучше. Добавить RISC-V, MIPS и прочее станет значительно проще, чем при переходе от одного монополиста. Сейчас даже поддержка линукса, с его мемными 1,5% процентами пользователей, становится чем-то само собой разумеющимся, не у всех и не всегда, но тем не менее. Даже микрософт уже пилит софт для линукса. Я считаю, и с этим можно спорить, что устойчивость в многообразии.
Пусть расцветают сто цветов, пусть соревнуются сто школ!
Лишь бы не оказалось, что это часть истории под названием «Пусть змея высунет голову»... :)
Однако для рядового потребителя эти "сто школ" выливаются в такие муки выбора "правильной" техники. Пусть уж лучше 2-3, и голова не болит. И найдут техническиу и моральную поддержку и там и там. А если сто?
А рядовой пользователь и так не выбирает, а берет то, что советует реклама и друзья
Да, в том и дело, что большинство мук выбора в жизни людей - это навязываемые маркетологами муки :).
У вас есть другой вариант, который на выходе обязательно лучший результат выдаст? Думаю уже тысячелетиями доказано, что конкуренция делает это лучше. И да, иногда этой конкуренции может быть и много, как например с приложениями по всевозможным темам.
Не очень понял, чему именно вы возражаете. Мы живём в эпоху перепроизводства, когда предложения уже не удовлетворяют потребности, а стимулируют спрос. Конкуренция, по сути, идёт "за цвет упаковки" (эмоцию приобретения), это немного не потребительские качества, это лечение психоза, который маркетологами же и вызван. Такова жизнь, и эта ситуация - ни для кого не секрет :).
Большинству пользователей на самом деле "подошёл" бы любой современный процессор, прям вообще любой, но искусственные маркетинговые ограничения (в том числе пресловутое запланированное устаревание) задают постоянный градиент "роста". Человечество разогнало экономику, и не в силах её остановить :).
(Поймите меня правильно, это просто грустная философия, а так я и сам пишу этот комментарий с ноутбука на M1-Pro, и мне приятно похвастаться этим :))
Я вас понимаю. В этом-то и загвоздка, что мы думаем, что можно любую какашку разрекламировать и всё - рынок захвачен. А оно не так. Часто для этого приводится пример с IE, и тем, как Microsoft пропихивала его везде. Но IE выполнял свои функции и удовлетворял пользователей.
Как бы мы не думали про других невысоко, но в общем своём люди выбирают в своей массе то, что их потребности удовлетворяет, а не то, что им кто-то втюрить хочет. И да, на рекламу уходит много денег. Но ведь и в приватной жизни так.
Большинству пользователей на самом деле "подошёл" бы любой современный процессор, прям вообще любой,
Нам кроме 7 маек и трусов летом ничего и не надо. Но нет - покупаем шорты, рубашку поло, очки итд. и обязательно с каким-нибудь брендом. Рациональность в нашей жизни только меньшая часть нашего поведения. Большая- это эмоции и чувства. Это было всегда. Булочку в средневековье покупали уверен чаще, если запах из пекарни на всю улицу 'слышен' был, а не там, где по составу она тоже кусок теста была, но с меньшим запахом. Поэтому конкуренция самоопределяется. Количество игроков регулируется само. Как? В каждом случае по разному.
В этом-то и загвоздка, что мы думаем, что можно любую какашку разрекламировать и всё - рынок захвачен.
Нет, я так не думаю :). И мысли мои вовсе не о "невысокости" людей, вы явно не со мной спорите, а с каким-то очень чётко кем-то нарисованным чучелом, за которое вы меня принимаете :).
Извиняюсь, просто ваши слова
Человечество разогнало экономику, и не в силах её остановить :).
мне не понятны вообще никак. Что такое разогнали? Я уверен, что Вы не думаете, что IPhone, Боинг или квантовый компьютер с потолка подают? Каждые новый продукт новая технология или методика - это жестокая конкуренция, это уйма вложенных денег и времени. И Ваши последние слова доказывают неспособность Вами-же высаазанной идеи, приведённой мною выше.
И ещё. Зачем экономику останавливать? Когда такое требование вообще ставилось на нашей планете, что его невозможно исполнить? Вы не хотите ещё лучших процессоров, лучших фраймеворков, лекарств, ещё быстрых коммуникаций, и например боллее удобных и безопасных транспортных средств? Ответ почему-то могу себе представить.
Вы не хотите ещё лучших процессоров, лучших фраймеворков, лекарств, ещё быстрых коммуникаций, и например боллее удобных и безопасных транспортных средств?
Да вообще-то не особо хочу, мне бы существующие потребить хоть когда-нибудь, успеть похотеть их. Моя жизнь не такая насыщенная, как ваша, видимо :).
Сам себе каждый день в голове говорю, что надо меньше есть, а потом накрывается стол и....я не могу себе отказать. 😉
Но вас понимаю. Можно себя отдельно взятого сдерживать и не покупать 10 лет новый мобильник, и на машине ездить пока совсем не заржавеет. И некоторые это делают. Знаю таких. Другие вообще пренебрегают любыми новшествами. Их меньше. Но и таких тоже знаю. Но. Ведь мы не остановим этим прогресс. Он будет с нами или без нас. Но, он будет идти безостановочно вперёд. И ожидать, что жить без прогресса или почти без него захотят все - такому не быть. От слова никогда.
Но каждый из нас вправе это делать. Но ожидать от других то, что сами не делаем - так себе предложение.
когда уже есть CMake, кросскомпиляция, компиляторы которые умеют генерировать код под любую платформу, куча открытого софта и библиотек
А в результате, все просто пишут код на javascript для браузера/электрона (что тот же браузер)
Все это было и в 2000, а если исключить CMake (кроме него существовал давно automake/autoconfig) то и в 90x с кросскомпиляцией проблем не было. Наоборот скорее общее число поддерживаемых архитектур с того времени заметно уменьшилось...
Кросскомпиляция возникла чуть позже вообще компиляции. Каждая новая машина разрабатывалась на другой машине, и комплятор для новой машины пишется одновременно с разработкой железа, потому что новая машина без <кросс>компилятора и минимального набора ПО не нужна наверное с 80х. Ну может 90е, с тех пор как одним ассемблером стало невозможно реализовать минимальный набор ПО новой вычислительной системы.
Все так, только вот сложность этого занятия была значительно выше. Собрать что-то написанное с использованием autoconfig тот еще квест.
Кстати, интересно сравнить 2020 год и arm против rysen:
У райзена в десять раз меньше транзисторов, но при этом в два раза больше ядер, кеш 64 Мб и в семь с лишним раз больше энергопотребление. Отличие в 70 раз на транзистор!
Мне кажется, подвох в том, что эппл выезжают на количестве транзисторов и как-то его разменивают на низкое энергопотребление.
+ оперативная память.
вы так говорите как будто у x86 нет видео, пачки декодеров, avx/sse/mmx, кешей и т.д.Имхо не совсем корректно отказываться от сравнения по транзисторам.
вы так говорите как будто у x86 нет видео, пачки декодеров
А это на самом деле очень спорный вопрос. У эппла как минимум есть что-то аппаратное для тренировки нейросетей - Neural Engine. Есть, вероятно, и другие специфические фичи, которые нужны были девелоперам от эппл. Но если брать тот же UVD от AMD, то его поддержка софтом сильно различается. И вообще пока все выглядит так, что в x86 напихана куча всего на все случаи жизни, а в условный M1+ забиты аппаратные блоки под специфический форкфлоу целевой аудитории маков. И последний вариант это сорт оф читерство.
Важно не количество транзисторов, а то, как ты ими пользуешься :D (где-то в недрах МЦСТ)
Энергопотребление примерно пропорционально кубу частоты. Так что зарезая частоту можно нехило повышать энергоэффективность.
К примеру на ноутбучных видеокартах количество вычислительных блоков больше, чем на такой-же десктопной. Именно для того, чтобы при меньших частотах получить более-менее равную производительность.
так а где эти самые дешевые и производительные убийцы x86 на ARM ? Вы сравниваете апле и интел. Аппле еще дороже чем интел.
И греются ноуты у аппл на арм даже сильнее чем на интел, сколько там было 108 градусов цельсия на новеньком М2 в работе)))))
Если подразумевается последняя модель Air-а 2020 года с топовым для air-а i7-1060NG7 на борту, то чисто по процессорной мощности разница 6971 против 15181 попугаев, а если взять со стоковым i3-1000NG4, то у того вообще 3827 попугаев, а еще можно сравнить видеокарты, там еще больше разницы будет.
Так что как-то странно говорить что слабые, относительно новых М2, интелы греются меньше чем в разы более производительные М2.
Но и такие новости имеют место быть. Интересно, из чего состоят эти термо-прокладки. Возможно, достаточно пропатчить ноут простой термопастой.
А в чём смысл проектировать и выпускать после тестов ноутбук, который троттлит?
Вот только за счёт меньшей температуры 2-е устройство будет ещё и жрать электричества меньше.
Да и цена радиатора не так уж велика по сравнению с кремнием.
Так что большой вопрос какой вариант лучше.
Про цену радиатора, если честно, не понял.
блин, я неправильно прочитал ваш предыдущий пост.
Тогда мой ответ будет проще: лучше тот, на котором не экономили на радиаторе. И он всегда может работать на 100%. Но конечно возможны варианты, исходя из ограничений к целевому устройству.
Ну вот у них и есть устройства с нормальным активным охлаждением(MacBook Pro), кому нужно что-то серьезное делать со стабильной нагрузкой, а есть с пассивным(MacBook Air), кому нужен максимально тонкий и легкий вариант и кто не планирует на нем видео рендерить 24/7.
Первый попавшийся сайт говорит что самые дешевые air стоит 120к, про стоит 160к. Разница 33%.
разница в весе 1290 против 1400грамм. разница 8%
Складывается впечатление что охлаждение урезали не чтобы сделать ноутбук аж на 8% легче, а чтобы те, кому нужно нормальное охлаждение заплатили на 33% больше.
Победа маркетинга над здравым смыслом
Я смотрел для M1, чтобы характеристики были более схожими. А на сайте эпла цену для pro на M1 не показывает.
Посмотрел ещё на других сайтах pro вроде как 1300 официально стоил, аир 1000, итого теже 30% разницы.
Из кардинальных отличий — у Pro сенсорный экран вместо ряда F-F1-F12 кнопок.
вы про м2? там экраны разные и размеры чуть разные, поэтому я м1 сравнивал.
В следующей статье буду рассматривать конкретные процессоры. Не забываем, что годы монополии x86 дают о себе знать, но видимо мы еще застанем время, когда можно будет купить мать от какой-нибудь MSI или ASUS с сокетом под ARM процессор Qualcomm или даже MediaTek.
Монополия была из-за того, что x86 довольно успешно решал задачу "возьми данные не знаю какие данные посчитай их так не знаю как". Остальные архитектуры были рассчитаны на более узкий круг задач, и довольно долго в них были предпочтительнее. С поправкой на стоимость решения, а она зависила от тиража.
Это ж получается, что в распространении г*кодеров виноват интел?! Процессоры слишком уж эффективно переваривали плохо написаный код. Или все было наоборот? Так как плохого кода стало слишком много, то набрал популярность процессор для обработки этого кода?
Китайцы (и прочие) лет через пять вполне могут подвинуть обоих RISC-V. Идеологически он выглядит перспективнее. А ARM потихоньку готовит софтовую почву "массовая программа может выполняться на разных процессорах" (понятно, что специализированный софт давно компилируют под что попало, лишь бы влезло и время отклика устраивало)
Актуальный сейчас ARM64 (aarch64) не более RISC чем x86. Т.е. точно такой же CISC.
VLIW ... У неё ещё более длинные инструкции, чем у x86
Hexagon объединяет инструкции в пакеты. Размер инструкции фиксирован, 4 байта. Размер пакета от 1ой до 4х инструкций, в зависимости от их типа. Т.е. от 4 (совсем не повезло с содержимым пакета) до 16 байт (супер повезло) Типичное значение 8 или 12 байт. При этом максимальная длина инструкции (без читерства с бесполезными префиксами) на x86 составляет 15 байт.
они выбирают x86. Там более длинные команды, на обработку которых уходит больше энергии, но зато сложность вычислений выше, а потому на x86 есть более точный и узкоспециализированный профессиональный софт.
Какая феерическая чушь! Дальше читать не стал.
Так же подумал и в голове сравнение- экскаватор против кучи, но маленьких и энерго-малозатратных лопат.
Актуальный сейчас ARM64 (aarch64) не более RISC чем x86. Т.е. точно такой же CISC
По каким признакам вы делаете такие выводы?
Как раз AArch64 даже ближе к «эталонному» RISC чем AArch32.
ARM — load/store архитектура, где основную массу составляют команды регистр-регистр.
Имеет фиксированную длину команд.
Load-op для обычных операций отсутствует, но есть некоторые специализированные load-op команды, как и CAS.
Дальше читать не стал.
Вот тут соглашусь.
Те, кто пишут подобную бредятину («Там более длинные команды, на обработку которых уходит больше энергии, но зато сложность вычислений выше») обычно слабо представляют себе что это значит вообще.
mvv-rus
А она там таки разная (на ARM -более слабая, обеспечивающая меньше гарантий)
А вы под одну гребёнку не гребите =)
ARM разные бывают. Например на ядрах Nvidia Carmel — Sequential Consistency. Более строгая чем у х86.
По каким признакам вы делаете такие выводы?
Как раз AArch64 даже ближе к «эталонному» RISC чем AArch32.
Строго по определению. Reduced - это когда набор инструкций небольшой. Если у armv7 все инструкции можно было в одну небольшую табличку записать (и ещё одну для Thumb),. то у Aarch64 их просто дохрелион.
Вот прямо сейчас открыл Instruction Set. Для 32 битного перечисление базовых команд занимает 1,5 (полторы) страницы. Я их даже сосчитал - 34 штуки.
Для 64 битного 10 (десять) страниц. Их я тоже сосчитал 346 штук. Разница впечатляет ?
И ещё 11 страниц инструкций FPU. Их я уже считать не стал.
Имеет фиксированную длину команд.
Hexagon тоже имеет, но RISC он от этого не становится.
Reduced — это когда набор инструкций небольшой
Если это утверждение верно, то i8086 был CISC в момент выпуска, а после выпуска 80(1|2|
3|…)86 внезапно стал RISC.
Очевидно, что это не так.
Следовательно, вы исходите из неверной трактовки. Скорее всего, из-за незнания истории термина.
Но вам это много раз объясняли, впрочем.
Безрезультатно.
Если это утверждение верно, то i8086 был CISC в момент выпуска,
Да, CISC. С поправкой на технологии того времени (тысячи, максимум десятки тысяч транзисторов. Против миллионов в 90-х, и сотен миллионов в 00-х).
Давайте достанем линейку, да померяем ?
Если отбросить все вариации с флагами, размерностями, то у i8086 можно насчитать 68 базовых инструкций.
Теперь рассмотрим его современника, MOS 6502. У этого процессора прямо в инструкции закодированы операнды. Например TAY это аналог MOV A, Y, а TSX аналог MOV SP, X. Будем подобные дубликаты также считать за одну команду. Итого 26 команд.
Или вот ещё сравнение. У 6502 количество всевозможных опкодов, без imm параметров, всего 153 штуки. ВСЁ! Больше нету!!! А у i8086 их 65536 штук.
По-моему вполне наглядно, даже не смотря на то, что термины CISC/RISC тогда только "закладывались в проект".
Да блин! У 6502 даже сложения-вычитания без учёта переноса нет! Всего 3 регистра. Никакой ортогональности. Транзисторный бюджет в 10(!!!) раз меньше чем у i8086. Оголтелый примитивизм на марше.
а после выпуска 80(1|2|3|…)86 внезапно стал RISC.
386 стал RISC ? Это когда такое случилось ?
Следовательно, вы исходите из неверной трактовки. Скорее всего, из-за незнания истории термина.
Или нет
Но вам это много раз объясняли, впрочем.
Безрезультатно.
Вы меня с кем-то путаете.
Да, CISC.
С этим никто не спорит.
386 стал RISC? Это когда такое случилось ?
Контекст. Не стоит выдергивать кусок из фразы.
то **i8086** был CISC в момент выпуска, а после выпуска 80(1|2| 3|…)86 внезапно стал RISC.
Из вашего определения, опирающегося исключительно на размер ISA — это напрямую следует. С новым поколением все прежние CISC должны становится RISC — и этому было любопытно, как такая мысль укладывается у вас голове.
Как и ожидалось, с кучей само-собой разумеющихся подпорок.
Или нет
Хотите фокус?
Вы уверены, что значение имеет Complex/Reduced (length of) Instruction Set.
И не допускаете мысли, что речь может идти о Complex/Reduced (smth) Instruction Set.
Wiki, между тем, вполне однозначна:
The goal of any instruction format should be: 1. simple decode, 2. simple decode, and 3. simple decode. Any attempts at improved code density at the expense of CPU performance should be ridiculed at every opportunity.[22]В источниках так же легко находится связка reduced instruction и one-clock executing
Отсюда явно следует что опущенное слово — decoding complexity. Reduced (decoding complexity) Instruction Set.
Сложность, а не длина набора. Длина никак не оговаривается ни в одном случае, и может быть любой.
Как и количество поддерживаемых наборов, кстати.
Но сокращать сложность путем сокращения длины набора — первое, что приходит в голову и сразу дает эффект. Поэтому это заблуждение сильно распространено даже в англоязычной среде.
Вы меня с кем-то путаете.
Возможно, обознался. Мои извинения, коль так.
Строго по определению. Reduced — это когда набор инструкций небольшой.
Нет. Reduced это уменьшенный (урезанный), а вовсе не «небольшой».
А различие тут кардинальное. Нет никакого ограничения по количеству команд.
Небольшое число команд на заре RISC было вызвано лишь недостатком транзисторов.
Уменьшен набор был разделением операций на вычислительные и операции работы с памятью и как следствие выкидыванием ненужных команд load-op и rmw.
Это помогло создать более простое и эффективное кодирование инструкций, увеличить число регистров, что до сих пор является признаками RISC.
Я их даже сосчитал — 34 штуки.
А FPU/NEON/TZ/Thumb/JZL вы посчитать забыли?
Ух ты, какая избирательная забывчивость…
Вы не понимаете, к примеру, что MUL/MADD/MSUB/MNEG это одна и та же команда?
Просто чуть по другому конфигурируется блок умножителя.
Не нужно из-за этого заявлять о превращении RISC в CISC.
К RISC-V можно прикрутить хоть миллиард инструкций на все случаи жизни (благодаря VLE, кстати). Покуда они реализованы на RISC-принципах, никаким CISC он не станет.
Вот 6502, который вы описали выше — классический CISC, хоть и примитивный.
Как я и писал количество инструкций тут не играет никакой роли.
ADC
Add Memory to Accumulator with Carry
(indirect,X) ADC (oper,X) 61 2 6
(indirect),Y ADC (oper),Y 71 2 5*
Вот таких инструкций на RISC нет.
Даже на топовых чипах с десятками миллиардов транзисторов.
Потому что она противоречит принципам RISC.
Парадоксально, но факт — процессор с 3500 транзисторами выполняет более сложные команды чем процессор с 59 миллиардами транзисторов :)
Hexagon тоже имеет, но RISC он от этого не становится.
Как и чёрная кошка не становится чёрной BMW.
Одного признака недостаточно.
Тот же ARMv7 имеет VLE кодирование Thumb2.
PS: Ещё раз стоит упомянуть что RISC/CISC это характеристика ISA.
Внутри такие (по крайней мере OoO) процессоры сейчас устроены одинаково.
Я думаю этот спор обусловлен тем, что сугубо рекламное определение risc (кочующее по интернетам до сих пор) пришло из 80-х, где "простота декодера" и "малое число инструкций" шли рука об руку как непосредственные элементы первых risc-дизайнов (при том, что сделать больше инструкций - как бы не было и тогда запрещено). И непосредственность воспринималась порой как неотъемлемость. Утверждалось естественно, что "так победим", и конечно для примера евангелистам надо было высмеять всякие страшные штуки типа шестиадресных команд (кажется в microVAX). Так оно всё и закрепилось... Это ещё сейчас не так часто вспоминают такое "обязательное достоинство risc", как ортогональность системы команд, а то ещё и по этому признаку можно было бы разгонять неверных.
Имхо со стороны, на истину в присутствии таких специалистов, как вы, само собой не претендую.
Взгляните для разнообразия на набор инструкций микроконтроллерного ядра Cortex-M4.
Reduced - это когда набор инструкций небольшой.
Читал в одной книге. Упоминается, что часто путают трактовку слова reduced в данном контексте. И утверждается, что на самом деле это не сокращённый, а упрощённый. В данном контексте больше смысла. Так как в RISC убраны ряд видов операций, которые характерны только для CISC. А также отсутствует очень сложный декодер команд (широко встречается у Intel и AMD). Но число команд может быть большим.
Например, в статье забыто сравнение моделей памяти в плане синхронизации порядка записи из кэша нескольких процессорных ядер. А она там таки разная (на ARM -более слабая, обеспечивающая меньше гарантий), и это много нам открытий чудных готовит при использовании на ARM неблокирующих алгоритмов, выполняющихся параллельно на нескольких ядрах.
и это много нам открытий чудных готовит при использовании на ARM неблокирующих алгоритмов
Некорректно написанных неблокирующих алгоритмов, вы хотели сказать.
Тут речь идет об алгоритмах, некорректных для модели памяти ARM, но вполне корректных и, главное, работающих много лет на x86 c ее более сильной моделью памяти.
А при переносе могут вылезти сюрпризы. Причем, в силу предметной области искать и отлаживать такие сюрпризы будет, мягко говоря, трудно.
Поэтому чем больше разработчиков об этом будут знать, тем лучше. А вот в статье об этом аспекте не сказано, и это жаль.
Тут речь идет об алгоритмах, некорректных для модели памяти ARM, но вполне корректных и, главное, работающих много лет на x86 c ее более сильной моделью памяти.
Строго говоря, корректность многопоточных программ на, как минимум, C и C++ рассматривается относительно модели памяти этих языков, а она у них таки слабая. То, что эти старые алгоритмы работали, как положено, говорит лишь о том, что их пользователям в каком-то смысле повезло.
Это не так работает. Как правило, конечным пользователям не нужно ни железо, ни софт, ни уж тем более алгоритмы по отдельности. Пользователю нужно решение его задачи. Связка х86+вот эта программа на этом компиляторе решает его задачу, ARM+эта же программа дает непредсказуемые сбои, причем очень тяжело отлавливаемые.
Если уж говорить про С и С++, то в их стандартах (и компиляторах) заложено слишком много implementation depended для безболезного перехода с одной архитектуры на другую. Даже переход gcc <-> llvm в рамках одной архитектуры не всегда проходит гладко.
При попытке работать с моделью памяти языков вы упрётесь в зависимость от компилятора и всё равно потеряете кросс-платформенность, т.е. перейдёте к учёту модели памяти конкретной платформы. На том же C++ написать понастоящему кросс-платформенный многопоточный код только с учётом модели памяти языка практически невозможно. Всё равно найдутся платформы (вроде многопроцессорных ARM, PowerPC, и всяких интересных вариантов SPARC), где вы не сможете написать сколько-либо эффективный код не прибегая ко всяким intrinsic фишкам, pragma, аттрибутам и прочему. Даже если код можно будет написать без использования этого всего, то его эффективность будет сразу ниже на порядок или несколько порядков, и такой код не будет иметь практического смысла.
Даже Java на всём обилии платформ не может гарантировать свою модель памяти и на всяких экзотических реализациях рекомендует использовать те или иные подходы и примитивы, иначе или модель памяти не гарантируется, или потеря производительности такая, что использование некоторых примитивов не имеет смысла.
Advanced RISC Machine
ARM это больше не акроним.
ARM это просто РУКА?
Так в чём заключается
Скандальное разоблачение
я полагаю вот в этом =)))
Титанических различий в архитектуре x86 и ARM под капотом не так уж и
много. Это всё те же миллионы и миллиарды транзисторов, с помощью
которых выполняются логические операции.
До самого скандального так и не докопались – на атомарном уровне все процессоры сделаны из атомов кремния, которые неотличимы друг от друга.
Почему-то в статье автор обошёл вниманием тот факт, что x86 это ещё и громадная legacy архитектура из большого количества древних команд, которые тянут ради совместимости с прошлыми версиями. Мне кажется, что именно это сейчас является одним из основных препятствий для развития данной архитектуры.
Какие конкретно команды вам не нравятся?
Да хотя бы fwait. А ещё были какие-то двоично-десятичные операции из 4х битного калькулятора, которые, к счастью, в amd64 выкинули.
fwait ведь давно удалена, и является синонимом nop сейчас. Каким образом она является одним из препятствий для развития архитектуры?)
Так ведь процессоры её должны поддерживать? Это как минимум лишние транзисторы.
Даже если fwait заменяется компилятором на опкод nop, есть ещё замечательные (в своё время) инструкции типа fadd, fmul, fstp и т.д., которые сейчас - хлам. 80-битные вещественные числа, к обработке которых открывают доступ эти старые инструкции (по сравнению с современными), нужны не очень часто. В arm их вовсе нет.
Так ведь процессоры её должны поддерживать? Это как минимум лишние транзисторы.
Это наверняка что-то вроде нескольких байт в таблице декодера опкодов.
80-битные вещественные числа, к обработке которых открывают доступ эти старые инструкции (по сравнению с современными), нужны не очень часто
Ну то, что в ARM их нет, означает только то, что компилятор при случае навалит гору кода для корректной работы с такими числами)
Маркетинговый наброс
ARM это типичная "подрывная технология" из известного учебника по бизнесу. Когда гиганты не обращают внимание на новую технологию , потому что она не приносит много прибыли. Когда обращают, оказывается, что корпорация слишком большая, "распилов" много, управлять трудно, поэтому она не может работать на новом фронте так же эффективно, как компании-новички.
Собственно у Intel тут был выход купить уже готовую компанию и проинвестировать в неё. А если бы они сами стали развивать ARM , то привнесли бы в своё подразделение неэффективность(для новой технологии) всей корпорации.
В своё время Kodak разработали первый цифровой фотоаппарат, но это не помогло им преуспеть в этом направлении.
В своё время Kodak разработали первый цифровой фотоаппарат, но это не помогло им преуспеть в этом нанаправлении.э
Это часто больше тупость или недальновидность отдельно взятых менеджеров и как в кодак случае ещё и нежелание убивать свой уже рабочий основной бизнес.
У Intel была линейка StrongARM в своё время. В пору расцвета КПК и первых коммуникаторов. Но - предпочли продать Marvell-у.
а встретить человека с семилетними смартфонами — непростая задача.
ну почему же.. - вот он я.. (Lenovo S660)
))
Samsung Note 10.1 N8000
Но как же он тормозит :(
Ну это уже ретро почти :)
"Но как же он тормозит"
Ради интереса попробуйте удалить обновления для системного приложения "Google Services" (если я правильно помню название. одно из главных системных приложений в Android).
Когда мой Philips Xenium W6500 начал тормозить все больше и больше, я пытался найти причину и как-то раз добрался до удаления обновлений у всяких системных приложений (где-то в настройках приложений Android у каждого приложения была кнопочка "удалить обновления" для возврата приложения к заводскому варианту).
И как только я удалил обновления этого "Google Services", то, помимо того, что само приложение "похудело" с 650+Мб до ~50Мб (а это высвободило заметное количество места), телефон внезапно стал летать (!). Все приложения стали шевелиться невероятно быстро.
Но был и сайд-эффект: некоторые свежие приложения стали ругаться, что им нехватает каких-то функций и отказывались работать без обновления этих "Google Services" до более свежей версии.
Дата анонсирования 2014-02-24. Он у вас восьмилетний. Вы не подходите в выборку =). Как и я с ZenPhone 2.
Ну зачем вы бьёте по больному. Сейчас такую технику не выпускают (к сожалению)...
Эх, были времена :-)
Это же как раз на Intel Atom девайс был, ЕМНИП :) Как работает? Живой ещё?
Как вы это делаете? В среднем живет два года. Каждый раз новая причина замены.
Самое время обновляться :)
Lenovo S660
Lumia 950 XL, October 6, 2015.
Уже не основной телефон, но используется активно.
У меня как второй аппарат Lumia 640ds, главное на нее не ставить обнову от 2019 года а то начинает так тупить, что ужас. Так бы и юзал до сих пор, если бы не отвалившийся Whatsapp и странные клиенты телеги
В своё время ходил с Lumia 920, тоже очень нравился, но со временем отказался из-за обнов и софта
В своё время ходил с Lumia 920
Lumia 920 у меня третий аппарат — на случай, если я забуду дома первый и второй :)
Лежит в ящике на работе и ждет своего часа, зарядить — дело нескольких минут.
Забавно, что все основные функции смарта отлично выполняет, в отличи от второго айфона и нокии 2009 года — по тем можно только звонить :)
Главное, чтобы аккум не умер, лучше держать заряженным на 50-80% :)
лучше держать заряженным на 50-80%
Да, я в курсе, спасибо. Заряжаю раз в месяц, держит заряд хорошо.
А вот с Lumia 950 XL все хуже — акк таки дохнет, заряжать надо ежедневно.
(с заменой сложно — мой конкретный аппарат хочет работать только с родными аккумуляторами, с китайцами начинает глючить, самопроизвольно выключаясь после нескольких часов работы)
Любая компания может купить у ARM лицензию на готовые ядра или архитектуру и создавать свои SoC
Простите, больше не любая
Да уж, ну вы и замахнулись. Все современные высоко производительные ядра процессоров, построены по схеме в которой главным компонентом является Out-of-Order engine. По сути, он отвечает за спекулятивное исполнение всего, что только можно(предсказание ветвлений, параллельное выполнение независимых веток инструкций, префетчинг дотсупа к памяти и т.д). И внутри этот движок оперирует некоторыми микро-инструкциями в которые транслируются исходная ISA(instruction set architecture, то что по русски называется набором команд или ассемблером процессора). Поэтому CISC, там или RISC, не имеет никакого решающего значения, влияет это всего лишь на транзисторный бюджет декодера, который и так достаточно минорный. Что имеет значение, так это то насколько продвинутый OoO движок вам удалось сделать. Intel и AMD в этом условно говоря "собаку съели". Но вот и Apple подтянулось в их клуб, при этом какую бы ISA они ни взяли, вопрос с точки зрения производительности - глубоко вторичный. Сила RISC и ARM в частности, это когда никакой слишком высокой производительности на такт не надо, и можно сделать тупой и простой процессор который будет оперировать ISA, без каких либо OoO прослоек. Тогда действительно мы получаем, и уменьшенный транзисторный бюджет, и меньшее энергопотребление, и относительно более высокую частоту, а так же производительность.
Поэтому CISC, там или RISC, не имеет никакого решающего значения
Давайте представим, для простоты, что в декодеры разом загружается кеш-линия.
ISA влияет, грубо, тем, сможете ли вы это сделать, или будете загружать по одной команде.
Во втором случае получается, что добавить еще один декодер — нужно вылизать остальные настолько, чтобы их не хватало. Или добавить больше сложных инструкций и сделать конвейры длинее, что неминуемо скажется на производительности. И это без учета сложностей остальной внутренней кухни.
В первом — вы просто клепаете больше декодеров, пока ядро справляется.
Каждый, кто занимался разгоном, знает, что зависимость мощности от частоты — степенная.
Поскольку функция степени растет быстрее чем произведения, то незначительно сбросив частоты вы можете увеличить ширину ядра вдвое, оставшись в том же теплопакете.
Другими словами, в первом случае вы можете разменять частоту на транзисторный бюджет, и загрузить большее количество (хоть и менее частотных) ИУ, получив гораздо больше производительности на ватт.
Происходит так потому, что CISC-инструкция должна пройти не менее одной стадии конвейра, прежде, чем во второй декодер станет возможно загрузить вторую инструкцию — пока не будет считана инструкция, не будет понятно, где она заканчивается.
Четвертый декодер вступит в игру, когда первый, возможно, уже выпустит декодированную команду с конвейра.
В то время как RISC-декодеры начинают декодировать все загруженные в них инструкции одномоментно. И, благодаря своей простоте и вытекающему из нее меньшему количеству стадий, примутся за вторую кеш-линию, тогда, когда CISC только-только пережует одну простую инструкцию.
Именно в этом проблема CISC-декодера. Он очень туго масштабируется. Нельзя загрузить в пучок декодеров сразу всю кеш-линию, если вы не знаете, какой декодер откуда должен начать читать данные.
Ох... В исходном посте ясно же описано, что ISA никакой современный производительный процессор не исполняет. ISA преобразуется один раз декодером в микро-инструкции, микро-инструкции сохраняются в кэше микро-инструкций, когда OoO ядро надо получить данные по инструкциям они берутся из кэша. И естественно, даже декодирование исходной ISA происходит, ни так как вы описываете. Декодер должен быть один, так как вам нужно пройтись по всем инструкциям и получить из них один "поток исполнения". И работает он примерно так - на вход загружается буфер, на выходе за счет "параллелизма логических элементов"(то есть скорость декодирования гораздо выше чем инструкция-такт), получается нужный связанный набор микро-инструкций. Для CISC из-за переменной длины инструкций сделать хороший декодер, сложнее чем для RISC, что выливается в некоторый дополнительный транзисторный бюджет. Но на фоне остальных блоков эффект от увеличения достаточно минорный.
ISA преобразуется один раз декодером в микро-инструкции, микро-инструкции сохраняются в кэше микро-инструкций
Это вы описали uOPs cache. Но он не всеобемлющ, это всего лишь очень маленький кеш.
Декодер должен быть один
Или вы под декодером понимаете сразу всю конвейерную группу, или застряли во времена 486. Потому как два конвейерных декодера уже были в Pentium, четверть века назад.
В любом случае, присущая RISC регулярная структура набора команд позволяет декодировать параллельно любое количество инструкций, хватило бы мощей все это корректно выполнить.
то есть скорость декодирования гораздо выше чем инструкция-такт
Синхронный конвейр на дюжину стадий с производительностью декодирования гораздо выше чем инструкция-такт?
Знаете, если вы смогли решить проблему сброса конвейра, фатально бьющую по производительности, просто декодером, без хитрых эвристик и нейросетей в предсказателе ветвлений, спекулятивного исполнения и прочего, и прочего — то почему ваши процессоры еще не взорвали рынок?
И работает он примерно так — на вход загружается буфер, на выходе за счет "параллелизма логических элементов" <…>
Ну, с этим параллелизмом обратно к синхронному конвейру, зависимостям данных и вычислимым частям CISC-инструкций.
Нет, вы правы в том, что аппаратные компараторы используются при декодировании и работают они асинхронно. Но только в этом.
Для CISC из-за переменной длины инструкций сделать хороший декодер, сложнее чем для RISC
Вы буквально на несколько предложений выше сказали: скорость декодирования гораздо выше чем инструкция-такт. А теперь говорите о большой сложности.
>Это вы описали uOPs cache. Но он не всеобемлющ, это всего лишь очень >маленький кеш.
"Маленький" зависит от вероятности необходимости повторного декодирования и связанных с этим задержками. 2К uop это совсем не маленький.
>Или вы под декодером понимаете сразу всю конвейерную группу, или
> застряли во времена 486. Потому как два конвейерных декодера уже были в
> Pentium, четверть века назад.
Pentium был классическим супер-скаляром, в котором если была возможность две соседние инструкции могли исполнится параллельно. Опять же никакой абстракции над исходной ISA, в виде OoO(хотя бы register renaming) и построения динамического графа исполнения там не было. Все это начали подвозить только в Pentium III. Под декодером я понимаю функциональный блок который на входе получает буфер, а на выходе выплевывает микро-инструкции удобоваримые остальными частями OoO движка.
>Синхронный конвейр на дюжину стадий с производительностью декодирования >гораздо выше чем инструкция-такт?
Не понимаю о чем вы говорите. Давайте условимся, что рассматриваем некоторый современный процессор с развитым OoO. Это означает, что у вас по определению есть:
некоторый механизм построения динамического графа исполнения (зависимостей инструкций)
качественное предсказание ветвлений с средней вероятностью по больнице где-то 99%. Применяя предсказания ветвлений, программа разворачивается в граф исполнения
есть некоторое окно инструкций, которые еще "в воздухе", то есть декодированные и к которым применен первичный механизм разрешения зависимостей в графе исполнения. Если мы говорим про классику, то это будет register renaming, с регистровым файлом от 100 элементов. Соответственно, примерно столько же инструкций внутри этого окна.
front-end дополняет этот граф исполнения сверху, то есть делает префетч на подгрузку инструкций и их декодирование, преобразование в микро-инструкции. В более продвинутом варианте у нас скорее всего даже есть кэш микро-инструкций, который даже не смотря на свой небольшой размер, будет существенно снижать нагрузку на декодер.
back-end состояит из execution units(integer/fp) и load/store. Каждый свободный unit получает от OoO движка микро-инструкцию и ее входящие параметры. Эта инструкция для которой входные зависимости уже готовы, OoO движок это знает так как у него есть граф исполнения(в простейшем случаи это реализация в духе register renaming). Таким образом back-end всегда оптимально загружен во "всю ширину". Если нам попался плохой участок кода, с длинной цепной зависимостью, то да их придется исполнить одна за одной. Но обычно граф исполнения, гораздо более разряжен, что позволяет исполнять значительное количество инструкций параллельно.
OoO за счет "окна инструкций", которые содержат текущий кусок графа исполнения, позволяет сделать развязку front-end и back-end. По сути нам важно лишь чтобы средний throughput front-end и back-end совпадали.
самая плохая вещь, это сброс графа исполнения OoO конвеера из-за не предсказанного ветвления, что заставляет отбрасывать спекулятивность и "раскручивать" другую ветку
>Ну, с этим параллелизмом обратно к синхронному конвейру, зависимостям данных >и вычислимым частям CISC-инструкций.
>Нет, вы правы в том, что аппаратные компараторы используются при >декодировании и работают они асинхронно. Но только в этом.
Декодер в OoO подходе это просто штука, которая преобразует некоторый буфер в входной набор микро-инструкций и обладает нужной пропускной способностью. Под "параллельностью" я естественно имею ввиду реализацию в виде комбинаторно-регистровой схемы, которая декодирует с пропускной способностью гораздо больше чем инструкция за такт. (компаратор это к слову по определению аналоговое устройство, и как его применять в данном вопросе цифровой схемотехники, я не представляю. а так да, цифровая схема, состоит из параллельно работающих логических элементов и регистров)
>Вы буквально на несколько предложений выше сказали: скорость >декодирования гораздо выше чем инструкция-такт. А теперь говорите о >большой сложности.
Естественно, чтобы получить IPC >> 1, необходима скорость декодирования значительно больше 1, для любого декодера. Реализация декодера(как функционального блока в рамках OoO процессоора) для CISC сложнее, из-за переменной длины инструкций. Естественно, это будет выливаться как в усложнение алгоритмов, схемотехники, так и увеличение транзисторного бюджета. Но принципиально это ничего не меняет. Даже в самом оптимистичном сценарии, вы сэкономите 5-10% транзисторов, от бюджета всего ядра.
2К uop это совсем не маленький
2k uOPs vs billions instructions and Instruction >>> uOP
Это значит, что его нужно регулярно и быстро пополнять.
если была возможность две соседние инструкции могли исполнится параллельно
Вы же понимаете, что для этого их надо обе декодировать, для начала?
В любом случае, это было еще возможно во времена x86, путем установки x87. Но не для всех инструкций, только для float — потому что у сопроцессора был свой декодер, работавший независимо.
Ну и в вики, наконец, прямо говорится о двух конвейеризированных декодерах, U and V pipelines.
Давайте условимся, что рассматриваем некоторый современный процессор с развитым OoO
Можно даже сделать еще предметнее, рассмотрев конкретный экземпляр.
На блок-схеме видно 4 (конвейерезированных) Decoder. У каждого.
реализацию в виде комбинаторно-регистровой схемы, которая декодирует с пропускной способностью гораздо больше чем инструкция за такт
Это очень эпично; вернемся к этому позже, если будет смысл…
компаратор это к слову по определению аналоговое устройство
ШТА‽
Декодер в OoO подходе
ШТА‽
Декодер, как это ни удивительно, занимается декодированием инструкций. А внеочередное выполнение (OoO) берет уже декодированные инструкции и пытается их выполнить, если не обнаружит зависимостей по данным.
Это разные и независимые сущности.
Естественно, чтобы получить IPC >> 1, необходима скорость декодирования значительно больше 1
Снова посмотрите на блок-схемы ядер современных процессоров с IPC>>>1.
Никаких эфирно-торсионных асинхронно-регистровых(!) супердекодеров в них нет. Зато есть несколько независимых койнвейеризированных декодеров в одной упряжке.
Каждый из которых может выдавать на выходе до двух декодированных инструкций на такт, но имеет штраф в длина конвейра на заполнение с нуля.
> 2k uOPs vs billions instructions and Instruction >>> uOP
> Это значит, что его нужно регулярно и быстро пополнять.
Для hot spot, где прежде всего и бывают затыки - не нужно.
>На блок-схеме видно 4 (конвейерезированных) Decoder. У каждого.
На блок-схеме видно единый блок декодирования, с надписью 4-way, то что я собственно и пытаюсь до вас донести.
>ШТА‽
Не понятно, только почему тогда в исходном посте вы назвали его "аналоговым". И еще более непонятно, почему вы ему уделили такое внимание в контексте декодера.
>Декодер, как это ни удивительно, занимается декодированием инструкций. А >внеочередное выполнение (OoO) берет уже декодированные инструкции и >пытается их выполнить, если не обнаружит зависимостей по данным.
Декодер преобразует инструкции в микро-инструкции, микро-инструкции исполняются OoO движком, о чем я вам наверное уже 2 или 3 раза написал.
>Никаких эфирно-торсионных асинхронно-регистровых(!) супердекодеров в >них нет. Зато есть несколько независимых койнвейеризированных декодеров >в одной упряжке.
Про асинхронных, никто речь и не вел, а вот про алгоритмы и схемотехнические решения, да. Ровно тем же образом как и умножение можно реализовать за несколько тактов добавив логических элементов, а не то как считают "столбиком".
> Каждый из которых может выдавать на выходе до двух декодированных >инструкций на такт, но имеет штраф в длина конвейра на заполнение с нуля.
Это ваши фантазии. Zen к примеру декодирует 4 инструкции за такт, и декодер, что вполне логично является единым блоком. И сразу, очевидный вопрос, расскажите как эти четыре декодера могут быть независимыми, если инструкции переменной длины, и чтобы получить начало следующей надо в какой-то мере декодировать предыдущую.
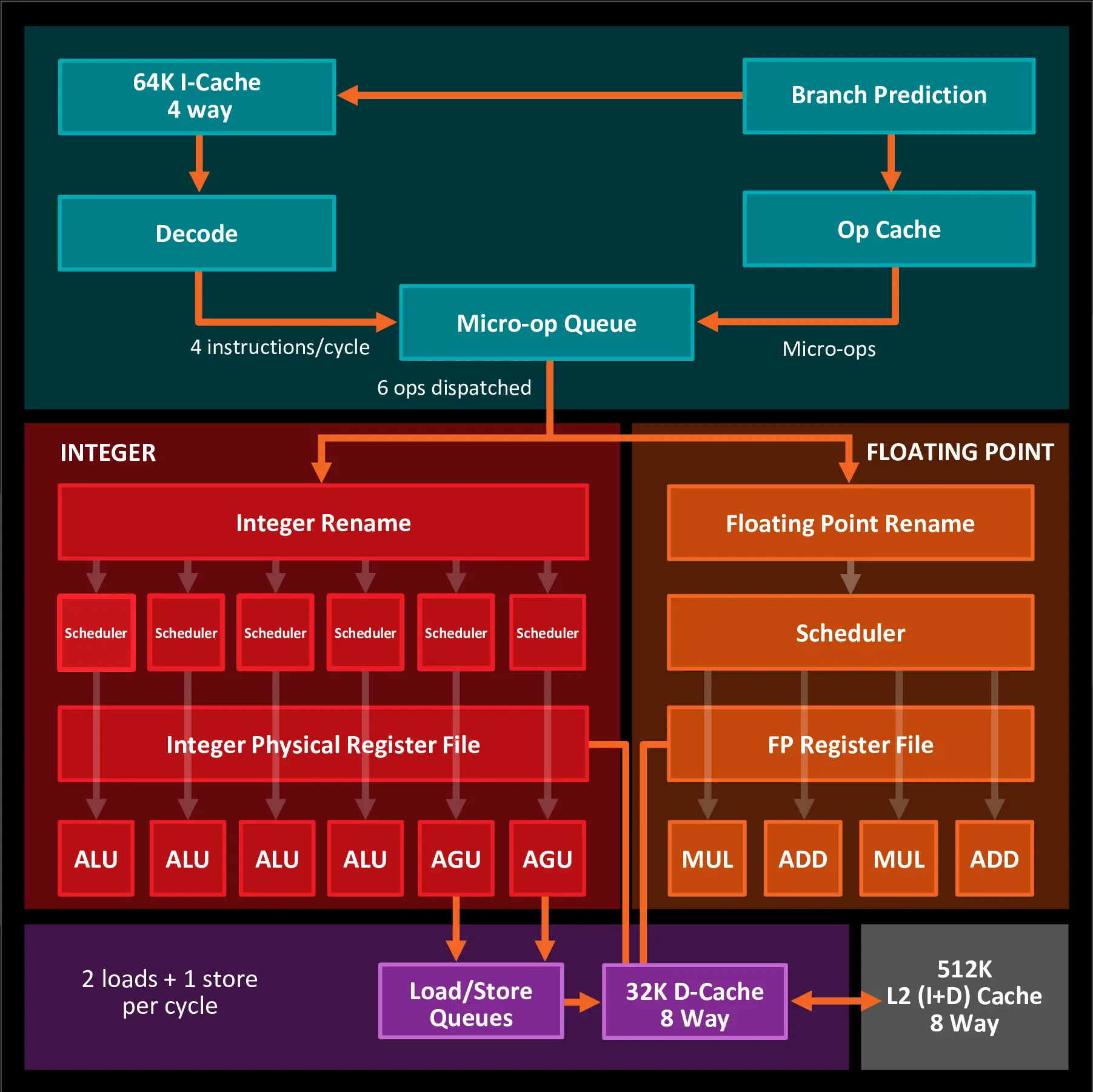{kind=link}
Сброс конвейера, это конечно плохо, но в OoO подходе он в основном возможен лишь при ошибки предсказания ветвления.
PS: но вообще я не особо понимаю, о чем мы с вами спорим, особенно в контексте моего начального комментария и статьи. Будете спорить, что RISC за счет снижения сложности декодера(и снижения общего транзисторного бюджета ядра на 5-10%), имеет какие-то существенные преимущества, в контексте OoO архитектур современных высоко производительных процессоров?
Для hot spot,
Вы считате, что нет кода кроме hot spot или что наполнение этого кеша ничего не стоит?
Если ни то, ни другое, то не совсем понятно, к чему это..
почему тогда в исходном посте вы назвали его "аналоговым"
Вообще-то, нет. Будьте внимательны, там написано аппаратный.
Декодер преобразует инструкции в микро-инструкции, микро-инструкции исполняются OoO движком, о чем я вам наверное уже 2 или 3 раза написал.
Это вы сейчас так непроизвольно взяли слова каджита и приписали их себе? При том, что сами недавно объявили декодер частью OoO?
… Это ваши фантазии…
Без комментариев.
После того, как вы дважды подряд в соседних абзацах поймались на своих фантазиях, и несколько раз на невнимательности — они уже не нужны.
Zen к примеру декодирует 4 инструкции за такт, и декодер, что вполне логично является единым блоком
Чукча не читатель, да?
Decoding is done by the 4 Zen decoders — прямо в той статье, откуда дернута картинка.
Везде по статье decoders, в подвале: pipeline stages 19 +
расскажите как эти четыре декодера могут быть независимыми, если инструкции переменной длины
Вы просите в одном комментарии пересказать тысячи человекочасов исследовательской работы?
Что ж, это просто: как сказано выше (и что вы поленились прочитать), конвейр синхронный, аж на 19 стадий (у Zen). Кроме того, у синих и армов (ссылки выше, ищите) эта часть изображена гораздо подробнее, и там видны части, когда-то принадлежавшие древнему декодеру: префетчер, предекодер, etc.
Когда длина инструкции становится известной, можно отдать следующую иструкцию на декодирование, даже если она не прошла через декодер полностью. Более того, в зависимости от устройства декодера, у него может находиться на каждой стадии конвейра по инструкции, в разных стадиях декодирования, и это то, что делает конвейерный декодер — конвейерным.
Но преддекодирование занимает время, и не позволяет загрузить конвейры одновременно, выступая бутылочным горлышком. В особо запущенных случаях преддекодер может вообще сказать я все и дожидаться результатов частичного декодирования инструкции (в тех же первых пентиумах это была штатная ситуация, емнип).
Но вот от уже ваших фантазий о тахионном декодере это действительно далеко.
Сброс конвейера, это конечно плохо, но в OoO подходе он в основном возможен лишь при ошибки предсказания ветвления.
Только лишь?
В мире монопольного доступа единственного потока к процу — да.
Но это не магия внеочередного выполнения инструкций, OoO этим не занимается тоже.
вообще я не особо понимаю, о чем мы с вами спорим
Спорите вы, в основном — из-за невнимательности и незнания матчасти.
Этот просто показал на примере, что утверждение Поэтому CISC, там или RISC, не имеет никакого решающего значения — неверно, да нашел несколько крупных изъянов в ваших построениях.
А вы, не удосужившись ознакомиться с предметом, понеслись доказывать что-то свое.
>берет уже декодированные инструкции и >пытается их выполнить, если не >обнаружит зависимостей по данным.
Прочитайте еще раз все что я вам писал. Декодирование инструкций, OoO и исполнение, полностью развязаны. OoO оперирует некоторой формой графа зависимости инструкций, поэтому то что исполняется - *уже имеет все готовые зависимости*. Это абсолютно, не тот "линейный" супер-скаляр в духе первого пентиума, про который вы мне пытаетесь, что-то рассказать.
>Вы считате, что нет кода кроме hot spot или что наполнение этого кеша >ничего не стоит?
> Если ни то, ни другое, то не совсем понятно, к чему это..
Я имею ввиду, что мало или много для кэша зависит от вероятности cache-miss и латентности на этот cache-miss. И в контексте количественной оценки зависимости производительности архитектуры от этого параметра, она имеет некоторый вероятностный и совершенно нелинейный характер.
>Вообще-то, нет. Будьте внимательны, там написано аппаратный.
Хорошо.
>Это вы сейчас так непроизвольно взяли слова каджита и приписали их >себе?
Давайте считать:
ISA преобразуется один раз декодером в микро-инструкции,
микро-инструкции сохраняются в кэше микро-инструкций, когда OoO ядро надо получить данные по инструкциям они берутся из кэша.front-end дополняет этот граф исполнения сверху, то есть делает префетч на подгрузку инструкций и их декодирование, преобразование в микро-инструкции.
Декодер в OoO подходе это просто штука, которая преобразует некоторый буфер в входной набор микро-инструкций и обладает нужной пропускной способностью.
>При том, что сами недавно объявили декодер частью OoO?
Еще раз жирным "Декодер в OoO подходе", и где вы увидели что декодер является частью OoO? При том что я вам явно до этого расписал, про front-end, back-end и связующей их OoO. Отличии от классики очевидно, в том что инструкции превращаются в микро-инструкции, а не отправляются на исполнение. В это же время вы мне рассказывали про супер-скаляры в духе первого пентиума.
>Чукча не читатель, да?Decoding is done by the 4 Zen decoders > — прямо в той статье, откуда дернута картинка.
>Когда длина инструкции становится известной, можно отдать следующую
> иструкцию на декодирование, даже если она не прошла через декодер
> полностью. Более того, в зависимости от устройства декодера, у него
> может находиться на каждой стадии конвейра по инструкции, в разных
> стадиях декодирования, и это то, что делает конвейерный декодер —
> конвейерным.
Именно поэтому я вам с самого начала и говорил, что декодер является единым блоком, потому что там есть полно внутренних оптимизаций. И рассматривать его как копи-паст четырех декодеров, не корректно.
>Но вот от уже ваших фантазий о тахионном декодере это действительно >далеко.
Там не было фантазий:
"то есть скорость декодирования гораздо выше чем инструкция-такт"
Если я вам скажу, что скорость обычно подразумевает throughput вас это успокоит?
>Только лишь?
>В мире монопольного доступа единственного потока к процу — да.
>Но это не магия внеочередного выполнения инструкций, OoO этим не >занимается тоже.
Для начала хорошо бы разобраться с одно поточкой прежде чем лезть в дебри.
>Спорите вы, в основном — из-за невнимательности и незнания матчасти.
>Этот просто показал на примере, что утверждение Поэтому CISC, >там или RISC, не имеет никакого решающего значения — >неверно, да нашел несколько крупных изъянов в ваших построениях.
Мне не надо изъяны, интересна количественная оценка прироста производительности при переходе ISA с CISC на RISC. В данном случаи она будет равна, что-то в духе: дельта изменения длины конвейера * вероятность сброса (то есть не предсказанного ветвления). При этом вы утверждаете что эта дельта изменения длины конвейера будет существенной, а не была просто забросана дополнительными вентилями в CISC подходе (пример с умножением).
Статью про софт не будьте написать. Так как тему сложного софта на x86 подняли и так и оставили в стороне. А нынче наступает эпоха, когда ARM процессоры (архитектура) врываются уже на вотчину x86 систем - с появлением Windows 11 ARM (условно всё раньше началось - но это, скорее пробы пера) - позволяющую запускать как софт созданный для ARM систем, так и софт для x86 систем (в эмуляции - условно скрытой с глаз виртуальной машине) - что уже позволяет использовать сложный софт и на вотчине ARM система - мощности то ARM чипов заметно подросли!
Apple тоже пошла путём перехода с x86 на ARM процессоры в своих десктопных и серверных системах - но тут всё куда жёстче - без вариантов перевели всю ОС на ARM - и включили эмуляцию для старого софта x86. Тут уже разделение по сложности софта для разных платформ не выглядит уже значимым!
Есть и обратная тенденция - ARM софт запускают на x86 системах. То есть начался процесс симбиоза платформ на одном софтверном обеспечении. И, хоть, пока это ещё всё в зачаточном состоянии - но если не тенденция не загнётся - следующее поколение ОС (обоих лагерей) могут уже создаваться с обобщённой поддержкой всех популярных платформ, а новый софт под эти ОС будет уже уже изначально проектироваться сразу под все эти платформы (заодно тут ещё и экосистему Linux сейчас под себя начали подминать - ещё один слой симбиоза софта) - как дальше будут развиваться платформы и какая выживет в итоге?
Может это будет открытая RISC-V - ведь эпоха экспоненциального развития ARM, по слухам, уже заканчивается - и спустя лет 10 там тоже начнётся застой.... успеет ли ARM окончательно перетянуть на себя одеяло?
Вот про ОС Linux тоже ни слова пока не сказали. А ведь чем интересна эта ОС так как раз многоплатформенностью - тут есть и RISC и CISC системы. Ядро Linux можно и на принтере запустить - не говоря уже о x86 и ARM компьютерах или смартфонах - везде работает. Да, конечно, прикладной софт так просто уже не запустишь - но было бы желание исходники и библиотеки - можно было бы адаптировать. А в эпоху кроссплатформенной разработки и специальных платформ как .NET и JVM - делать это сало куда проще.
Это я всё к тому - что сейчас наступает эпоха кроссплатформенного софта - и даже если изначально он не создавался под разные платформы - на помощь приходит скрытая виртуализация - и программы запускаются даже не на своей родной архитектуре железа. То есть - софт перестаёт быть якорем, удерживающим на плаву ту или иную архитектуру - и если эта тенденция сохранится - то что же будет лет через 10? Останется ли потребность в нескольких архитектурах процессоров? Или наоборот - вырвутся всё-новые и новые архитектуры и для разных задач будут выбирать наиболее оптимальную - но уже без софтверных ограничений!
И это я ещё не приплёл сюда тенденцию к смещению вычислений в облака! А облачные серверы - это отдельная индустрия - здесь алгоритмы проще всего делать крос-платформенными и даже создавать кластеры из разных платформ, распределяя задачи по ним, исходя из критериев эффективности той или иной архитектуры - и тут будет уже своя конкуренция - и не факт что в итоге какая-то из архитектур не затмит остальные - и всё серверное оборудование плавно не заменят на новую единую архитектуру. А потребителей так ничего и вовсе не заметят - и в этом как раз не будет лишних якорей, тормозящих этот процесс!
А раз вычисления будут больше в облака уходить - то клиентским системам вообще не нужны будут сложные программы - клиентские архитектуры начнут "деградировать" - в угоду меньшего энергопотребления и стоимости. Тут архитектура x86 тогда вообще обречена.
Но есть пока одно исключение: Игры! Да - есть тенденция тоже вносить их в облака - но пока я на это смотрю очень скептически. Ибо тут очень большой трафик (а с ростом разрешения картинки он будет расти неимоверно) и очень высокая требовательность в лагам и стабильности связи - а тут пока всё очень плохо. Сейчас с 8K картинкой без компрессии (с потерями) не справляется даже короткий локальный видео кабель - чтобы обеспечить 120 кадров в секунду - а что уж говорить о сети Интернет - сейчас там относительно стабильную игру можно получить только в FHD. А что будет с 16K? А ведь они рано или поздно придут. Скажете - зачем так много - это уже извращение! Возможно - но всё-равно придут. А Интернет сети не резиновые - уже сейчас там всё очень плотно - и с какого-то момента роста трафика прогресс развития сетей просто не будет за ним успевать!
А уж если говорить о VR и AR технологиях - то они к лагам очень чувствительны (и тут уже желательна 16K картинка для каждого глаза - т.е. 32K) - транслировать такой рантайм контент без лагов по сети в ближайшем будущем вовсе не возможно! И не фак что пока на это даже предпосылки будут! А лаги тут не допустимы!
Вот тут мощное локальное вычислительное оборудование окажется востребованным! Но вряд ли это будет x86 - специфичные задачи будут требовать специфичного адаптированного решения. VR и AR и 3D не базируются на x86 архитектуре (у них она своя - и свои унифицированные API), но пока всё упирается в драйверы - они пока ещё заточены под x86. Но, возможно, в недалёком будущем всё изменится - и игровые консоли переползут на ARM архитектуру (будут оптимизированные драйверы и для PC) - ведь первая ласточка в лице Nintendo Switch то уже есть!
Но облачное серверное применение, как и игровая сфера - это всё-таки темы для отдельных статей!
В плане гибкости RISC-V нет равных: имея один базовый набор команд, архитектура может быть расширена большим количеством дополнений разной степени эффективности. Можно создать высокопроизводительную числодробилку с поддержкой всего и вся, можно микрошку для battery-less IoT. И софт потом создается в рамках одной архитектуры, одного контекста разработки.
Так ли важна общая архитектура у числодробилки и микроконтроллера? Нынешние примеры на ARM показывают обратное: программисты под Mac «просто программируют в xcode» что для Intel, что для Apple Silicon, программисты микроконтроллеров хоть и заявляют «я освоил ARM», на деле программируют периферию конкретного вендора, при переходе с какого-нибудь STM на NXP общая архитектура ядер не помогает практически никак (а, к примеру, переход с ARM GD32F на RISC-V GD32VF не особо и ощущается). Разница в архитектурах, ощутимо торчащая в софт - 8-битные времена (плохо скрываемый компиляторами зоопарк способов организации памяти/стека/итд).
Из вашего комментария я узнал больше, чем из статьи. Спасибо!
Мне кажется у автора неверный посыл - что архитектура x86 устаревает.
И в качестве доказательства он приводит то, что каждая вновь появляющаяся архитектура все быстрее и быстрее её догоняет.
Apple вообще понадобилось для этого 4-5 итераций ( выпусков новых моделей процессоров на своей архитектуре ).
Доказательством устаревания x86 было-бы то, какая-то архитектура её уверенно обошла по быстродействию, а не просто очень быстро догнала.
Имхо - правильный вывод, что роль архитектуры ВООБЩЕ становится не важна:
Проектирование процессоров все более автоматизируется.
Роль опытной команды разработчиков и наработанных годами оптимизаций архитектуры снижается по мере роста числа транзисторов в процессоре:
Как программу на языке высокого уровня в 100 строк можно ускорить в разы переписав на хард ассемблере.
А переписанная на ассемблере программа в 10 000 000 строк ( если такое было-бы вообще возможно ) скорее всего проиграет программе написанной на языке высокого уровня и откомпилированной оптимизирующим компилятором.Человечество набирает опыт сильных и слабых сторон тех или иных решений в проектировании процессоров.
Например - малое множество простых команд раздувает размер программы. И кэши работают менее эффективно ( в них меньше влазит ).
Богатое множество команд - сложности с их интерпретацией внутри процессора.
И т.д. и т.п.
Грубо говоря - можно выдумать свою архитектуру.
Взять современный САПР, учебник где написано как делать ( и как делать не стоит ), пару миллиардов долларов. Допилить в LLVM компиляторе нужную кодогенерацию. И за 3-4 итерации ( выпусков новых моделей процессоров на своей архитектуре ) догнать лидера.
И упереться в техпроцесс - из которого большего быстродействия не выжмешь.
То же самое с другой архитектурой и третьей...
P.S. Что-то похожее как JIT компиляция быстро прогрессировала, догнала предварительную компиляцию, но так превзойти её не смогла. В чем то один подход на пару процентов лучше. В чем-то другой. А в общем-то паритет.
В следующей статье я разберу серверные ARM-процессоры, где в некоторых моделях производительность (пиковая и на Ватт) — выше за единицу стоимости и на потребляемую энергию. А потребление энергии — архиважный момент в дата-центрах. Есть серверные ARM-процессоры со 128 ядрами уже сейчас, что улучшает консолидацию ресурсов, а у той же AMD проц EPYС Bergamo со 128 ядрам только в планах на 2023 год. TDP там будет 320 Ватт, а не 250. В общем, я приготовил много интересного :)
Я не знаю - но как-то подозреваю что у ARM все хуже в плане межпроцессорного взаимодействия. И возможностей виртуализации ( x86 уже на какую глубину в этом продвинулся? - виртуальная машина из виртуальных машин виртуальных машин ; ))) )
Думаю отними у x86 эти возможности и он сравняется с ARM в производительности на Ватт.
Но это только мои выдумки. Если получится - осветите их в новой статье.
Расскажите пожалуйста и о том как у армов с максимальной производительностью на ядро в алгоритмах без аппаратного ускорения. В ситуации когда вот прямо завтра выходит новый видеокодек, поддержки которого нет ни в x86 ни в арм, и он не паралелится, и нужно выбрать процессор для максимально быстрого кодирования.
Некоторые топовые x86‐процессоры обходят M1 в одноядерной производительности ценой турбобуста и дикого энергопотребления, то есть обходят на короткой дистанции
Некоторые топовые x86‐процессоры обходят M1 в одноядерной
производительности ценой турбобуста и дикого энергопотребления, то есть
обходят на короткой дистанции
Уточните пожалуйста на каких задачах и сравнивалась ли чисто софтовая реализация алгоритмов или софтовая у x86 против (полу)аппаратной у M1?
Тут речь о ядрах общего назначения, разумеется.
В гугле можно поглядеть результаты бенчмарков, если вводить запрос вида «[модель какого‐то процессора] vs M1»
Тут главный секрет успеха в том, что у ARM фиксированная длина инструкций, и Apple поставила 8 простых и эффективных декодеров инструкций против четырёх сложных и часто ошибающихся в x86
Проблема производительности в том, что задача общего назначения написана абы как абы кем. Как только задача становится более-менее определенной, то ее решение сразу оптимизируется и подбирается/создается подходящее железо. х86 - это процессор для задач общего назначения, там применено огромное число оптимизаций для ускорения белого шума из кода. Удивительно, но работает. ARM не ставил себе целью решать задачи общего назначения, у него была вполне конкретная сфера применения. Но так уж исторически сложилось, что именно эта сфера начала активно расти и уже много где пересекается с задачами для х86. ARM успешно рос вместе со своей сферой, и теперь много где может успешно заменить х86. При этом сохраняя относительно низкое потребление, заложеное в него изначально.
@uvic мне ваш вывод не только нравится, но я уверен, что ход мыслей у вас правильный. Построить то, что уже существует - нелегко но в принципе- возможно. Выйти на новый уровень - тут другими талантами надо владеть. Хотя и лидеров в той или иной теме иногда с трона тоже скидывают. Примеров тоже немало. Спасибо за ваши слова. Такого объяснения я не слышал.
А не кажется ли вам что мы медленно, но уверенно движемся к ARM? Смартфоны уже давно там, cloud-провайдеры предлагают сервера, осталось только десктопы обновить и всё, прощай x86?
ИМХО. Если x86 будет двигаться в том же темпе, то да, через какое-то время Intel и AMD могут потерять рынок ПК, серверов и консолей (если не перейдут на ARM, конечно).
Microsoft и Apple уже смотрят в строну ARM (Apple уже активно переходит, Microsoft пока осторожничает и не сильно спешит).
AMD уже тоже потихоньку смотрит в сторону ARM и покупает профильные компании.
nVIDIA полностью на стороне ARM так - что вот всё пытается её купить с потрохами!
Intel.... вот тут всё туманнее - информации про освоение ARM Интелом очень мало - но вероятно проекты есть - но пока они засекреченные и не большие! Тут очень много репутационных рисков. Но если да - они сильно промедлят - то со временем то займутся официальным выпуском систем на ARM архитектуре, но уже в роле сильно отстающего (как когда-то были дела у AMD когда делили рынок x86 архитектуры - тогда на плову AMD помогли оставить наработки удачные 64битной архитектуры и инструкции AMD 3DNOW! - ныне уже устаревшие; у других старых вендоров x86 решений в загашнике ничего стоящего не нашлось и их выкинули с рынка данной архитектуры - им нечем было закрепить своё право) - но это всё дела давно минувших дней. Так что с Intel пока всё не ясно - если мир десктопа и серверов окончательно сдвинется в сторону ARM (а на это явно потребуется ещё минимум пара десятилетий) - то дела у Intel будут не очень хороши, но это не означает, что они не сумеют перестроиться - талантливых инженеров и программистов у Итнтела предостаточно, как и финансовых ресурсов и силы влияния - если всё не профукают окончательно - то выплывут. Тем более, что через 30 лет у ARM может начаться такой же застой, как у x86 процессоров лет 20 назад. Может к тому моменту ARM уже и не будет такой уж перспективной платформой, а на рынке уже будут активно действовать другие конкурирующие архитектуры - та же RISC-V или ещё какая-нибудь, что появится за эти 30 лет (может что-то совсем новое - на основе продвинутого AI и ультрамногопоточгных нелинейных вычислений - как когда-то случилось с видеокартами). Вот Intel тогда может попробовать сразу сделать ставку на новую архитектуру. Тем более, что к тому моменту прикладной софт в большинстве своём будет уже ориентироваться на кроссплатформенную разработку и не будет таким уж чувствительным к разным платформам - а ОС могут сразу разрабатываться с поддержкой разных архитектур процессоров!
Тема поднята интересная и важная, но статья грешит множеством неточностей и лакун. Например, делается такое утверждение:
Например, Intel Core i9-12900K или AMD Ryzen 7 4750G — это не CPU, как мы привыкли их называть, а APU (Accelerated Processor Unit), то есть процессор с интегрированной графикой (iGPU) на одном кристалле
и далее:
А вот на ARM чаще всего другая логика — SoC (System-on-a-Chip) или система на кристалле
Это какое-то кривое сравнение, я бы сказал в корне неверное. Все современные процессоры от Intel, Amd, а также ARM-чипы - это SoC'и. APU - это некоторый термин, придуманный скорее в маркетинговых целях, по сути обозначающий, что в состав конкретного SoC'а входит GPU. Т.е. можно считать APU подвидом SoC'а, но никаких "других логик" тут нет и в помине.
В статье, как мне кажется, расплывчато сформулировано то, а почему всё же АРМ стал побеждать. Да, есть преимущества в лицензировании, но почему тогда не MIPS, или какой-нибудь OpenRISC, например? Или почему тот же Intel не смог предложить нужные продукты? Ведь на серверных и десктопных рынках у него это до последнего времени прекрасно получалось. Всё же важно подчеркнуть, что лицензирование от Arm важно не просто чисто экономически, но даёт производителям гибкость в создании специализированных SoC, что и было драйвером роста Arm-экосистемы. И компания ARM смогла предложить здесь хороший компромисс в соотношении цены лицензий и развитости предоставляемого IP.
Статья вообще какая-то дурацкая, честно говоря из серии "на пикабу такое уже не опубликуешь, только на одноклассниках". Как это могло появиться на Хабре - тем более непонятно.
Зашёл, чтобы написать вот ровно то, что вы написали - инженерные успехи в случае arm важны ровно в той же степени, что и маркетинговые и, отдельно, бизнесовые. Мы двадцать лет живём в мире, когда почти кто угодно может прийти к arm holdings, но почти никто даже не подумает прийти к интелу за ядром/шинами/etc. А рынок требует всяких приколюх, и нужно не менее 100500 кооперативов по пошиву процессоров прямо сейчас, а не когда интел решится выпустить что-то там очередное. Вот и вся песня. Какое-то время ещё доили альтернативы типа mips/power, но все сдохли от недостатка внимания и/или денег от своих правообладателей. Сейчас конечно mips в очередных инкарнациях активно давит, и другие суетятся, но кажется время упущено, разве что балансировать на risc-v ещё получится (а то хозяева arm тоже порой нехило будоражат тех, кто собственно денежки им несет).
Очередное маркетинговое дерьмо, в которой маркетолог изнасиловал инженера. Степень погружения в тему просто потрясает, зато хайповых заголовков и утверждений тьма тьмущая.
В этом году сменил телефон OnePlus 5 (2017года) на snapdragon 835 и установил Kali Linux и был удивлен как отлично работают десктопные программы (например Firefox) и количеством адаптированного софта под arm. В данный момент держу на нем домашний сервер Minecraft.
Важное отличие CISC и RISC, на которое редко обращают внимание - длина конвеера, от которой зависит цена ошибки предсказаний переходов. Для популярных задач, таких как научные вычисления, машинное обучение, компьютерная графика, это не очень важно, переходы там предсказываются достаточно точно. Для бизнес-приложений (обработка документов, вебсервисы) это более весомо, но здесь часто все упирается в ввод/вывод - производительность диска и сети, да и кеш тоже играет бОльшую роль, чем предсказания переходов.
Но есть задачи, на которых оно вполне заметно - это программисткие задачи, компиляция, проверка правильности кода, разные солверы и моделчекеры.
Программисты вроде как вполне платежеспособны и многочислены, но на нас рынок почему-то не ориентируется...
Ну, а пользователя как обычно никто не спрашивает, выгодна ли ему ситуация, когда для получения обновления ОС нужно кланяться вендору в ножки и делать два раза ку, потому что на огроженный ARM SoC поставить можно только то и только тех версий, которые поддерживаются вендором.
Вот серьёзно: что вообще хорошего получает рядовой пользователь ARM-устройств? Необходимость каждые два года покупать новый девайс, потому что на старый уже новая версия Android не становится?
x86 — сейчас единственная платформа, которая оставляет пользователю хоть какую-то свободу.
Случай с ARM напоминает другие примеры подрывающих технологий из книги Клейтона Кристенсена "Дилемма инноватора" https://habr.com/ru/company/rocketcallback/blog/291068/ В книге Кристенсена ARM, конечно, не упомянут, но все квалификационные признаки подрывающей технологии налицо.
"Любая компания может купить у ARM лицензию на готовые ядра или архитектуру и создавать свои SoC, как это делают, например, Apple, Qualcomm и Samsung. Это даёт относительно низкий порог входа."
У автора короткая память. В 2019 году ARM отозвала лицензию у китайского гиганта HUAWEI, а в этом году - у российской "Байкал Электроникс". Деньги-то заплатить за лицензию может любая компания. Но потом ARM может в любой момент решить, что эта компания "неправильная" и отозвать лицензию. И "любая компания", которая уже вложилась в эту архитектуру, понесёт большие убытки.
Объясняю, почему так происходит. Начну с аналогии Генри Киссинджера "Великая шахматная доска". Проблема в том, что реальность - это не шахматная доска. За шахматной доской главное - правила игры в шахматы. В реальности главное - интересы. И джентльмены никогда не позволят, чтобы какие-то там договора или правила игры мешали их интересам. Когда правила игры перестают устраивать джентльменов и начинают им мешать - джентльмены меняют правила игры. В реальности джентльмены, делая свой ход, меняют правила и объявляют, в какую игру они играют сейчас - в шахматы, в шашки, в поддавки или вообще в "чапаева". А "уважение к частной собственности", "демократия", "равенство всех перед законом" - это товары для лохов...
Пресловутые длинные команды из мира CISC на самом деле разбиваются на несколько микроопераций и исполняются RISC ядром — вот тебе и x86.
странно, что никто ещё не написал тут, что это распространённое заблуждение. микрокод это ни разу не RISC команды, а инструкции управления блоками процессора, по сути это ещё сильно-сильно меньше чем RISC команда.
Intel’s x86’s do NOT have a RISC engine “under the hood.”
читаем ответ "Former Ex-Intel Chief X86 Architect, Ex-DARPA/MTO Directo" Why are RISC processors considered faster than CISC processors?
M1 -> M1 Ultra
TDP выросла в 7 раз. Производительность выросла в три раза.
Так и до Интела недалеко по "производительность на ватт".
Скандальное разоблачение x86: ARM врывается с двух ног