Nvidia подешевела на 10% после выхода на рынок Llama-3.
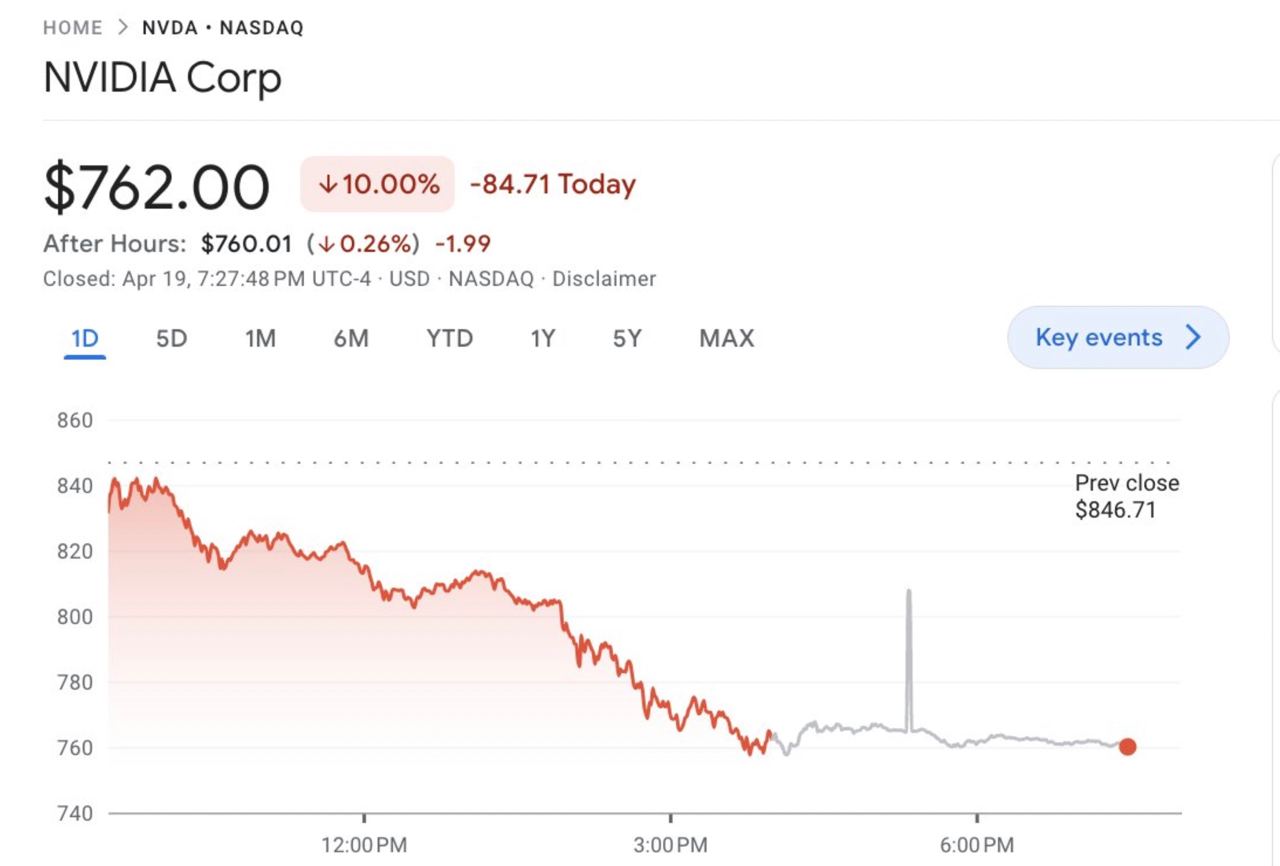
Зачем покупать графические процессоры для обучения LLM, когда у нас уже есть несколько LLM мирового класса с открытым исходным кодом 🤷♀️ 🤷♀️
Теперь у нас есть модель с открытым исходным кодом, которая превосходит Claude 3 Opus... и дышит в спину GPT-4.
Скорость работы составляет почти 300 токенов в секунду.
LLAMA-3 - самая загружаемая модель, которую я когда-либо видел на HF.🚀
За 24 часа ее скачали более 36 200 раз!!!
Вангую: GPT-5 будет анонсирован до релиза Llama-3-400B. Релизы OpenAI определяются внешними факторами 🤣
Если вы вдруг не видели LLAM3 почитать подробнее можно здесь.
