Работая с svn нередко появляются моменты, когда во время коммита твой рабочий каталог становится неактуальным. При этом приходится обновлять свою локальную копию из репозитория и составлять коммит по-новой. Хорошо когда коммитить нужно всё, а если нужны лишь три файла из ста? В таком случае приходится по новой искать свои файлы. Хотя TortoiseSVN и упрощает жизнь в таких случаях, бережно сохраняя комментарий, но всё равно, время, потраченное на обновление каталога и получение дерева с удаленного SVN сервера не вернуть. Создатели TortoiseSVN упростили нам жизнь ещё больше, создав небольшую утилиту, речь о которой и пойдет в данной статье – CommitMonitor.

Разработчик БД
Моделирование курса валют методом Монте-Карло
Easy
12 min

Метод Монте-Карло — это мощный инструмент стохастического моделирования, который используется в самых разнообразных областях науки и инженерии. В финансах, этот метод часто применяется для анализа и прогнозирования временных рядов, таких как курс валют или акций. Использование Монте-Карло позволяет оценить не только ожидаемые значения, но и распределение возможных исходов, что крайне важно для управления рисками и принятия обоснованных инвестиционных решений.
Принцип метода заключается в выполнении большого количества стохастических экспериментов (симуляций), основанных на случайных выборках из вероятностных распределений входных параметров. В контексте прогнозирования курса валют, это позволяет моделировать различные экономические сценарии и оценивать потенциальные колебания валютных пар, используя исторические данные.
Ключевой аспект использования Монте-Карло в финансах — это его способность учитывать и анализировать волатильность и дрейф курсов валют. Для повышения точности моделирования и реалистичности получаемых данных часто применяется ГАРЧ модель (Generalized Autoregressive Conditional Heteroskedasticity). ГАРЧ помогает адекватно оценить и моделировать изменчивость волатильности, что является критичным при анализе финансовых временных рядов.
Идейно код выполнялся без готовых реализованных методов из различных либ.
Проект использует следующие библиотеки и инструменты:
Как настроить работу на Канбан-досках с нуля за 15 минут? Руководство для начинающих
Easy
6 min
Tutorial
На канбан-досках могут быть различные виды задач, в зависимости от конкретного проекта, типа бизнеса или потребностей команды. В этой статье разберём основы ведения учета задач на Канбан-доске, необходимые колонки, виды и типы задач, в том числе Epic, userstory, task.
Восхитительная теория [якорных] баз данных от Ларса Рённбека
Medium
10 min
Opinion
Translation
Обнаружил серию статей по принципам организации информации и базам данных от математика из Стокгольмского университета и с энтузиазмом перевожу. Моя уверенность в том, что реляционки с 3-й формой нормализации - лучшее, что придумало человечество, резко убавилась... Я бы назвал это "субъективной теорией информации", автор называет "Transitional modeling", но обычно это применяется под названием "якорная модель данных"...
Безопасный Continuous Deployment БД по принципам DB-First
Medium
12 min
Tutorial
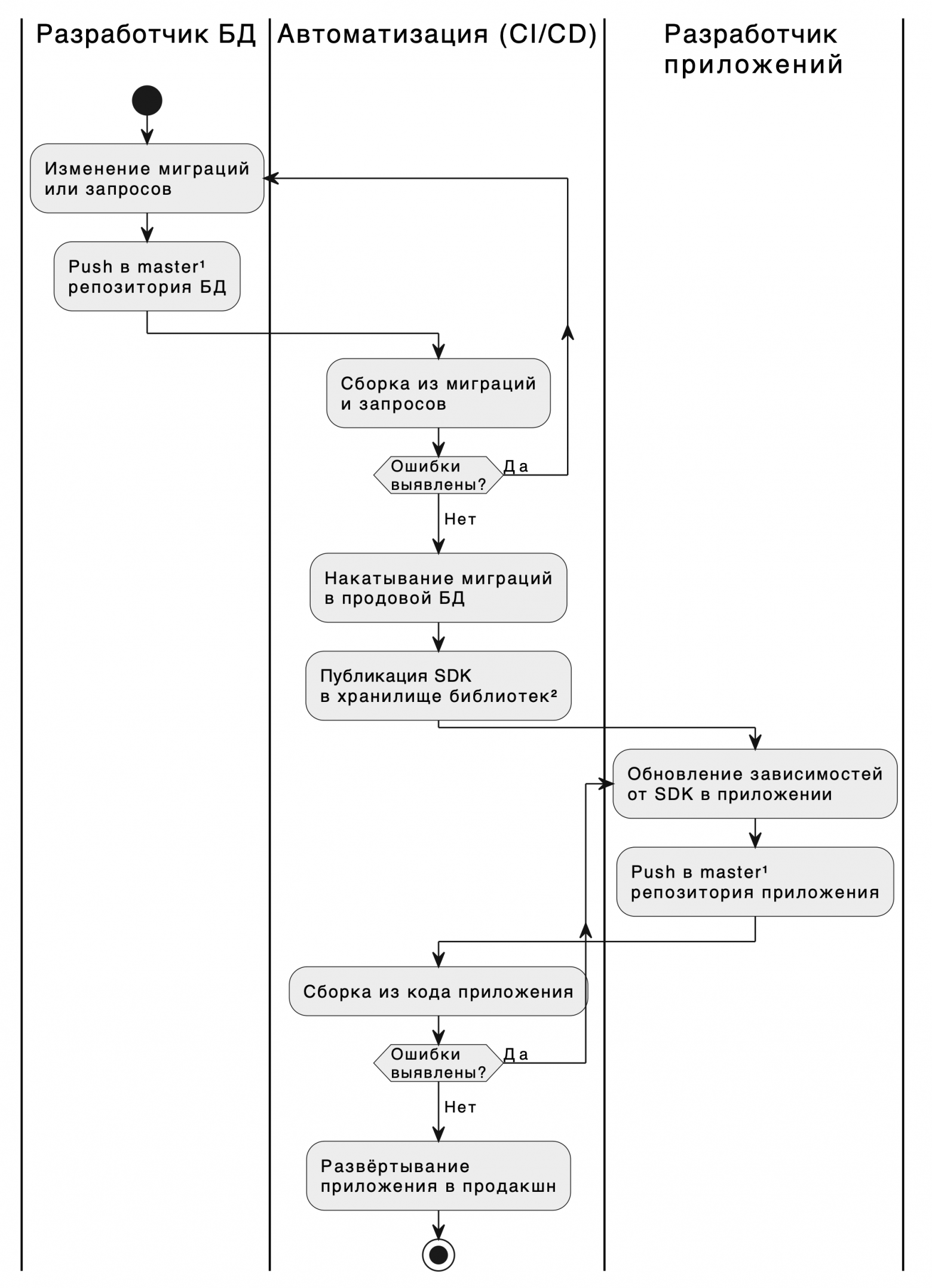
В статье рассматривается Continuous Deployment для БД с бесшовными релизами за счёт обратно-совместимых обновлений и автоматизации проверок совместимости с помощью подхода DB-First.
Постфиксный калькулятор на Haskell
Medium
6 min

Можно ли внедрить в Haskell постфиксный калькулятор?
begin push 1 push 2 add end
begin push 1 push 2 push 3 add mul end
На первый взгляд такой код на Haskell не может работать. Функция begin должна иметь произвольное количество аргументов, а Haskell является языком со статической типизацией. Но на самом деле, для написания вариативных (polyvariadic) функций достаточно полиморфизма.
Legacy: поддерживать нельзя переписать
Easy
7 min
Opinion

Легаси — реальность любого программиста. Объясняем, как софт становится легаси и почему это нормально, а также какие существуют плюсы при работе с легаси. Не всегда стоит относиться к легаси как к проклятию, стоит взглянуть на него как на естественный этап жизненного цикла программного обеспечения. Меня зовут Алексей Рузин, я уже 27 лет работаю и знаю, как работать с легаси.
«Легаси» — это слово, которым программисты пугают друг друга (и менеджеров). Оно означает устаревший софт, работать с которым обычно сложно и/или неприятно по причине небольшого «выхлопа» в пересчете на вкладываемые усилия. В целом, словом «легаси» можно назвать любой «код», который сложно поддерживать. И чем сложнее, тем он более «легаси».
Сегодня расскажем, откуда оно берется, как удерживать его “в рамках” и чем оно может быть полезно для начинающих специалистов.
Ты — это то, как ты пишешь. Как расти через качество кода
Medium
10 min
Opinion

Каждый код уникален. Несмотря на работу линтеров, спустя несколько лет вы с уверенностью сможете определить, что писали вы, а что — другой разработчик. Даже если не помните, что это была за задача. А ещё, код может рассказать об авторе едва ли не больше, чем разговор с ним. Например, какие книги он читал, на каких языках писал раньше. Можно сделать выводы о характере и привычках автора и предположить, как быстро он сможет вырасти.
Я Юрий Митус, фронтенд-разработчик в Сбере. Предлагаю поговорить о коде, который мы пишем, и практиках его улучшения. Расскажу, на что обращать внимание, покажу типичные ошибки, которые «портят» код и как их избегать. Научу писать код так, чтобы вас хотели нанять и перенять ваши практики.
Подписываемся на Kafka по HTTP или как упростить себе Веб-хуки
11 min
Существует множество способов обработки сообщений из Pub-Sub систем: использование отдельного сервиса, выделение изолированного процесса, оркестрация пулом процессов/потоков, сложные IPC, Poll-over-Http и многие другие. Сегодня я хочу рассказать о том, как использовать Pub-Sub по HTTP и про свой сервис, написанный специально для этого.
Использование готового HTTP -бэкенда сервисов в некоторых случаях является идеальным решением для обработки очереди сообщений:
Этот подход имеет и минусы:
Я реализовал идею в виде сервиса Queue-Over-Http, о котором и пойдёт речь далее. Проект написан на Kotlin с использованием Spring Boot 2.1. В качестве брокера сейчас доступна только Apache Kafka.
Использование готового HTTP -бэкенда сервисов в некоторых случаях является идеальным решением для обработки очереди сообщений:
- Балансировка из коробки. Обычно, бэкенд и так стоит за балансировщиком и имеет готовую к нагрузкам инфраструктуру, что сильно упрощает работу с сообщениями.
- Использование обычного REST-контроллера (любой HTTP-ресурс). Потребление сообщений по HTTP сводит к минимуму затраты на реализацию консюмеров под разные языки, если бэкенд разношерстный.
- Упрощение использования Веб-хуков других сервисов. Сейчас почти каждый сервис (Jira, Gitlab, Mattermost, Slack…) так или иначе поддерживает Веб-хуки для взаимодействия с внешним миром. Можно облегчить жизнь, если научить очередь выполнять функции HTTP-диспатчера.
Этот подход имеет и минусы:
- Можно забыть о легковесности решения. HTTP тяжёлый протокол, а использование фреймворков на стороне консюмера мгновенно приведёт к увеличению задержки (latency) и нагрузки.
- Лишаемся сильных сторон Poll-подхода, получая слабые стороны Push.
- Обработка сообщений теми же инстансами сервиса, которые обрабатывают клиентов, может сказаться на отзывчивости. Это несущественно, так как лечится балансировкой и изоляцией.
Я реализовал идею в виде сервиса Queue-Over-Http, о котором и пойдёт речь далее. Проект написан на Kotlin с использованием Spring Boot 2.1. В качестве брокера сейчас доступна только Apache Kafka.
Вычислительные выражения: Введение
Hard
9 min
Tutorial
Translation
Скотт Влащин — безусловный гуру в мире F#, написавший введение в язык, которое рекомендуют новичкам вместо официального руководства.
Группа энтузиастов давно (и с переменным успехом) пытается перевести руководство Скотта на русский.
Я завершаю перевод цикла, посвящённого одной из самых сакральных тем языка — вычислительным выражениям. Это как монады, только в .NET.
Неизвестно, когда нам удастся запустить полноценный русский сайт, поэтому я попросил у ребят разрешения опубликовать цикл на Хабре.
Материал интересный и хочется им поделиться.
Далее передают слово автору. Перед вами — первая статья цикла.
По многочисленным просьбам, мы поговорим про тайны вычислительных выражений, о том, что они из себя представляют и как могут применяться на практике (и я постараюсь избегать запрещённого слова на букву М).
В этом цикле статей вы узнаете, что такое вычислительные выражения, как их создавать, а также освоите несколько общих паттернов, связанных с ними. В процессе мы также познакомимся с продолжениями, функцией связывания, типами-обёртками и прочим.
Введение
Кажется, что вычислительные выражениях имеют репутацию заумной штуки, трудной для понимания.
С одной стороны, их достаточно легко применять. Любой, кто написал достаточно кода на F# наверняка использовал стандартные конструкции, такие как seq{...} или async{...}.
Но как вы можете создать новую похожую конструкцию? Как они работают за кулисами?
Медленное выполнение команды TRUNCATE: анализ проблемы блокировок спинлока в SQL Server
Medium
6 min

Приветствую всех читателей Хабра! Меня зовут Михаил, я администратор DBA в компании «Автомакон». На данный момент работаю на проекте для «ВкусВилл».
Решил затронуть одну из насущных проблем, связанную с работой SQL Server, а именно со спинлоками в нем. Да, даже такой зрелый и стабильный продукт как Microsoft SQL Server иногда подкидывает неожиданные задачи. Этот кейс хорошо демонстрирует, насколько увлекательные и интересные задачи решают администраторы баз данных.
Проблемы при переходе с MS SQL на PostgreSQL. Типы данных
Easy
4 min
Opinion
Исходя из того, что предыдущую статью не заминусовали и даже не сильно критиковали, попробую продолжить серию и поделиться с проблемами некоторых различий типов данных в MS SQL и PostgreSQL.
Как был создан потоковый SQL-движок
10 min
Translation

Возможно, вы как раз их тех, кто, просыпаясь каждое утро, задаёт себе три самых вечных жизненных вопроса: 1) как мне сделать потоковый SQL‑движок? 2) Что это такое — потоковый SQL‑движок? 3) Способен ли Господь наш сбрасывать те таблицы, коими владеет иной пользователь?
Я тоже ловил себя на том, что задаю себе эти вопросы, и порой они не оставляют меня даже во сне. Мне снятся различные SQL‑операторы, которые тычут в меня пальцем, насмехаются над моей некомпетентностью, а я умоляю их, чтобы они ответили на эти вопросы.
Так вот, где‑то год назад я (довольно смело, если «смелость» — это вообще про меня) снарядился как следует и пустился в долгий и тернистый путь, искать ответы на эти вопросы. Я шёл от монаха к пресвитеру, а от того — к жрецу макаронного монстра, и только в ужасе осознавал, сколь жалкие вопросы их занимают — например, каков смысл жизни, и как обрести мир с самим собой. Но, в конце концов, потерявшись в глубочайших расщелинах моего разума, я набрёл на часовенку, над входом которой значилось: «Epsio Labs». Тут я преисполнился откровения и вошёл в двери этого храма.
Друзья, сегодня я поделюсь с вами теми таинствами, которые познал там (за исключением тех, что подпадают под многочисленные NDA).
Детализированные стратегии кэширования динамических запросов
7 min
Translation
Сегодня я хотел бы поговорить о стратегиях кэширования для совокупных запросов к часто обновляемым данным, основанным на времени. На предыдущем месте работы я провел немало «мозговых циклов» и с удовольствием поделюсь некоторыми своими находками.
Рекомендации по ведению SQL-кода
Easy
8 min
Tutorial
В этом материале разберем общие рекомендации по ведению SQL-кода на примере СУБД MS SQL (T-SQL). Однако, многие пункты можно также применить и к другим СУБД.
Мигрируем с SQL Server на PostgreSQL двумя способами
6 min
Translation
Будучи одной из самых популярных баз данных, SQL Server славится простотой установки и настройки, функциями безопасности, среди которых есть шифрование, великолепными возможностями восстановления данных и множеством удобных инструментов.
Однако из-за ряда ограничений SQL Server постепенно теряет своих пользователей. SQL Server имеет достаточно сковывающую лицензию и стоимость обслуживания, растущую по мере увеличения размера базы данных или числа клиентов. Ее максимальный размер составляет 10 ГБ, а буферный кэш — 1 МБ. Она работает только под Windows.
Переманить же пользователей SQL Server может PostgreSQL — полностью бесплатная база данных с открытым исходным кодом. Эта база данных может похвастаться поддержкой международного сообщества и доступна под Windows, Mac, Linux, FreeBSD и Solaris. Кроме того, для нее существуют множество опенсорсных дополнений.
Я начну эту статью со знакомства с двумя бесплатными инструментами для миграции с SQL Server на PostgreSQL, затем поэтапно продемонстрирую, как выполнить миграцию между этими двумя базами данных, а в конце расскажу о полноценном решении для резервного копирования с защитой для управления сразу несколькими базами данных.
Как я уронил прод на полтора часа (и при чем тут soft delete и partial index)
7 min

В жизни любого разработчика наступает момент, когда он роняет прод. Представьте: полдень, в Skyeng час пик, тысячи запланированных онлайн-уроков, а наша платформа лежит…
Все упало из-за ошибки в процессе деплоя, которая связана с тонкостью PostgreSQL. К сожалению, на этом моменте у нас прокололась не одна команда. И чтобы такое больше не произошло ни у нас, ни в другой компании — велкам под кат.
Как работает NDA в разработке приложений? + шаблон НДА
Easy
3 min
Opinion
Recovery Mode

Текущий информационный мир полон не только возможностей, но и ограничений. Если вы работает в B2B и B2G, то не раз встречались с NDA от заказчика. Я расскажу о своем опыте в сфере аутсорсинг‑разработки: как выгодно пользоваться этим документом.
Эволюция системы разработки на SQL
Easy
9 min
Case

Мы — SQL команда Срочного рынка Московской Биржи, занимаемся разработкой и сопровождением бэкофиса торгово-клиринговой системы Spectra с момента ее возникновения. Срочный рынок Московской Биржи — это более 500 фьючерсных и 30000 опционных инструментов, несколько миллионов сделок в день.
Торгово-клиринговая система Срочного рынка (ТКС Spectra) изначально строилась на основе MS SQL, и за пару десятков лет прошла сложный путь от нескольких серверов БД до огромной системы с сервис-ориентированной архитектурой. Долгое время вся бизнес-логика системы разрабатывалась в программном слое на серверах MS SQL: и матчинг заявок, и расчет обеспечения, и управление клиентами были реализованы на T-SQL.
На сегодняшний день весь высоконагруженный функционал вынесен в отдельные сервисы, но в базах данных остаются сотни таблиц и тысячи программных объектов. Особенностью кода является высокая когнитивная и цикломатическая сложность. Управлять этим кодом с учетом всех требований по надежности и быстродействию – очень интересная задача.
В этой статье мы хотим рассказать об эволюции нашей системы разработки на SQL.
Стартуем без транзакции. Альтернативный вариант вопросов на собеседовании «по SQL»
Medium
29 min
Статей о селектах хватает, попробуем про апдейты. "ТОП-100" вопросов не обещаю - тут бы с одним разобраться. Разработчиков OLTP-систем под MS SQL Server и кандидатов на подобные вакансии приглашаю под кат.
Код на T-SQL, и он идеален. Атомарности нет, целостность вернём ручными апдейтами, изоляция с дюрабилити только мешают. Программируем без оглядки на ACID, который жив лишь в статье википедии.