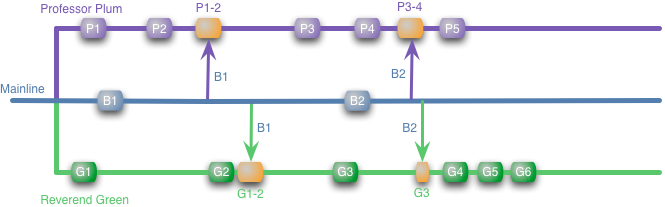
Добрый день, сегодня хотелось бы рассказать, как наша команда работает с базами данных. У нас в компании в основном используется Oracle и в нашей команде много людей, кто умеет хорошо его готовить. Нам изначально хотелось получить полный доступ к его возможностям: иерархическим запросам, аналитическим функциям, передаче объектов и коллекций, как параметров запросов, и, может быть, если не будет другого способа — хинтам. Модель у нас не очень сложная, поэтому сознательно отказались от ORM.
Добрый день, сегодня хотелось бы рассказать, как наша команда работает с базами данных. У нас в компании в основном используется Oracle и в нашей команде много людей, кто умеет хорошо его готовить. Нам изначально хотелось получить полный доступ к его возможностям: иерархическим запросам, аналитическим функциям, передаче объектов и коллекций, как параметров запросов, и, может быть, если не будет другого способа — хинтам. Модель у нас не очень сложная, поэтому сознательно отказались от ORM.В качестве основы взяли Apache DbUtils и сделали для него простую обёртку на Scala. Ниже я расскажу, как возможности Scala, особенно её последней версии 2.10, помогли упростить работу с базой данных.
А пытливых читателей, кто дочитает до конца, ждёт сюрприз.
 Статические анализаторы кода любят за то, что они помогают найти ошибки, сделанные по невнимательности. Но гораздо интереснее то, что они помогают исправить ошибки, сделанные по незнанию. Даже если в официальной документации к языку всё написано, не факт, что все программисты это внимательно прочитали. И программистов можно понять: всю документацию читать замучаешься.
Статические анализаторы кода любят за то, что они помогают найти ошибки, сделанные по невнимательности. Но гораздо интереснее то, что они помогают исправить ошибки, сделанные по незнанию. Даже если в официальной документации к языку всё написано, не факт, что все программисты это внимательно прочитали. И программистов можно понять: всю документацию читать замучаешься. . Полный перебор крайне долгий, ведь время его работы растёт экспоненциально относительно размера входных данных. Например, время поиска максимального пути в графе из 15 вершин наивным перебором становится заметным, а при 20 — очень долгим.
. Полный перебор крайне долгий, ведь время его работы растёт экспоненциально относительно размера входных данных. Например, время поиска максимального пути в графе из 15 вершин наивным перебором становится заметным, а при 20 — очень долгим.

 Наверняка вы хоть раз видели химические источники света — светящиеся палочки, которые начинают работать после «переламывания». Внутри — стеклянная капсула, которая при этом ломается, и начинается какая-то мистическая химическая реакция. Мне всегда было интересно разобраться, как это работает.
Наверняка вы хоть раз видели химические источники света — светящиеся палочки, которые начинают работать после «переламывания». Внутри — стеклянная капсула, которая при этом ломается, и начинается какая-то мистическая химическая реакция. Мне всегда было интересно разобраться, как это работает.  В
В 
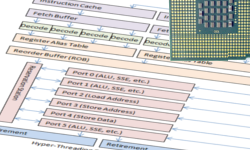 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.