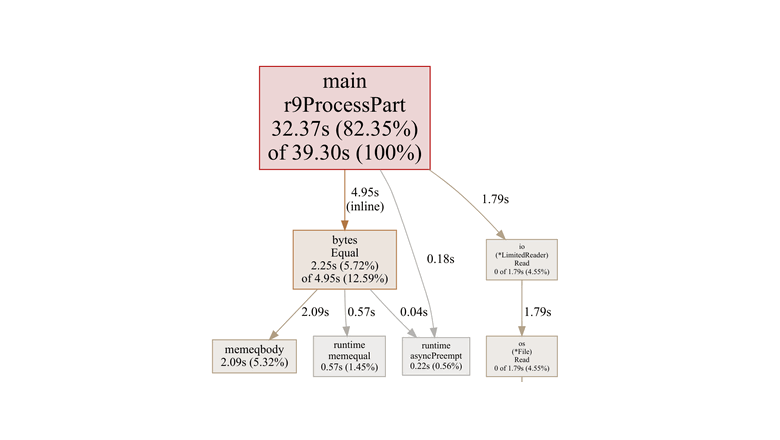
Много лет назад, учась computer science на старших курсах, я долго изучал различные вакансии онлайн, надеясь найти подходящую должность стажёра-программиста.
Кроме вакансий для стажёров я иногда случайно нажимал на объявления о вакансиях «сеньор-разработчика». Помню, больше всего меня поражало то, что первой строкой шло требование определённого количества лет работы: «Эта должность требует 5+ лет опыта».
Полному новичку, ни дня не проработавшему в этой отрасли, такие требования к опыту казались избыточными. Но хотя это немного приводило меня в уныние, я не мог не пофантазировать: «Наверно, пять лет работы программистом — это впечатляющее достижение? Должно быть, для таких людей писать код проще пареной репы».
Время летело, не успел моргнуть глазом, как прошло больше десятка лет. Сегодня я с гордостью могу сказать, что работаю программистом уже 14 лет. Спустя годы боёв на фронтах разработки ПО я осознал, что многие её аспекты сильно отличаются от того, что я представлял на старших курсах, а именно:
• С опытом программирование не становится намного проще, о «проще пареной репы» можно только мечтать.
• Написание кода для множества «больших проектов» — это не только неинтересное, но и опасное занятие, гораздо менее увлекательное, чем решение алгоритмических задач в LeetCode.
• Мышление только с технической точки зрения не сделает тебя хорошим программистом, некоторые вещи гораздо важнее технологий.
Поразмыслив, я пришёл гораздо к большему множеству мыслей о программировании. В этой статье я вкратце изложу восемь из них.