
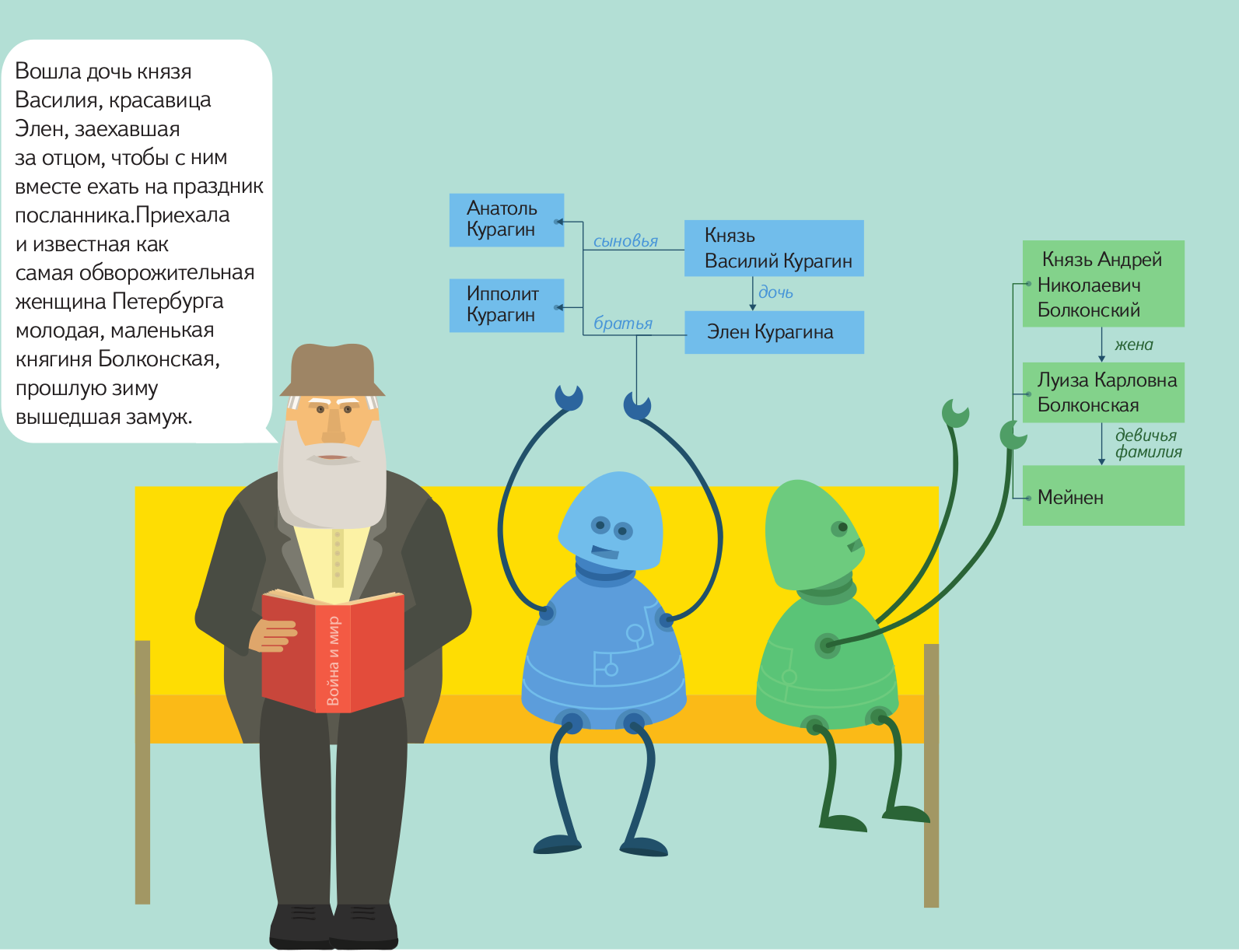
Статья рассказывает о работе whois протокола, о существующих клиентских решениях и об особенностях коммуникации с различными whois серверами (а также о выборе правильного whois сервера). Ее основная задача — помочь в написании скриптов для получения whois информации для IP адресов и доменов.
Что такое и для чего нужен whois можно прочитать, например, здесь: http://en.wikipedia.org/wiki/Whois.
В нескольких словах, whois (от английского «who is» — «кто такой») – сетевой протокол, базирующийся на протоколе TCP. Его основное предназначение – получение в текстовом виде регистрационных данных о владельцах IP адресов и доменных имен (главным образом, их контактной информации). Запись о домене обычно содержит имя и контактную информацию «регистранта» (владельца домена) и «регистратора» (организации, которая домен зарегистрировала), имена DNS серверов, дату регистрации и дату истечения срока ее действия. Записи об IP адресах сгруппированы по диапазонам (например, 8.8.8.0 — 8.8.8.255) и содержат данные об организации, которой этот диапазон делегирован.
Что такое whois?
Что такое и для чего нужен whois можно прочитать, например, здесь: http://en.wikipedia.org/wiki/Whois.
В нескольких словах, whois (от английского «who is» — «кто такой») – сетевой протокол, базирующийся на протоколе TCP. Его основное предназначение – получение в текстовом виде регистрационных данных о владельцах IP адресов и доменных имен (главным образом, их контактной информации). Запись о домене обычно содержит имя и контактную информацию «регистранта» (владельца домена) и «регистратора» (организации, которая домен зарегистрировала), имена DNS серверов, дату регистрации и дату истечения срока ее действия. Записи об IP адресах сгруппированы по диапазонам (например, 8.8.8.0 — 8.8.8.255) и содержат данные об организации, которой этот диапазон делегирован.




 1.
1.  1. Введение
1. Введение




