
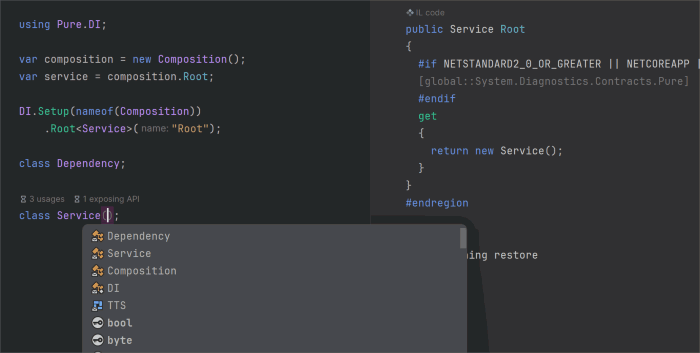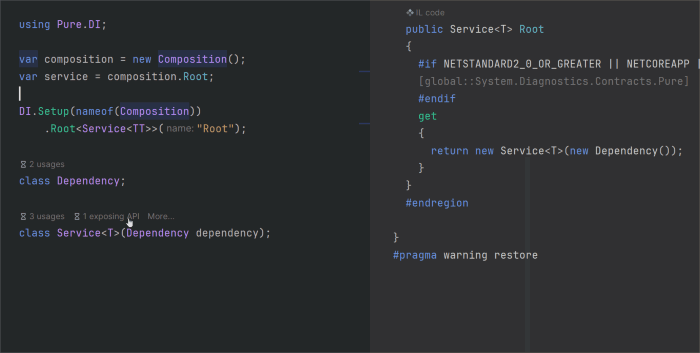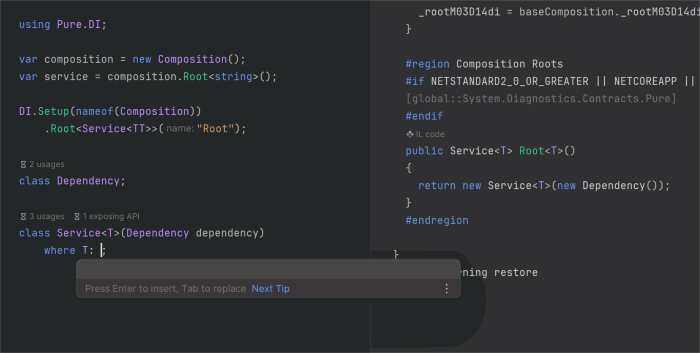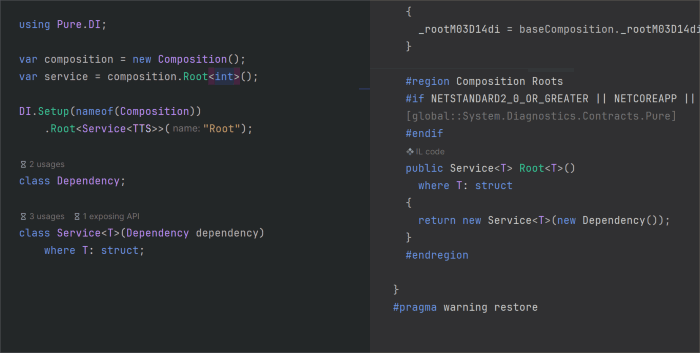
Эта статья о том, что появилось нового в генераторе исходного кода Pure.DI с момента выхода предыдущей статьи Pure.DI v2.1. Помимо исправления некоторых ошибок основной акцент был сделан на упрощении использования API для настройки генерации кода. Появилась возможность определить корни композиции обобщенных типов. Добавились накопители, что решило вопрос утилизации объектов со временем жизни отличным от Lifetime.Singleton и Lifetime.Scoped. Удалось улучшить производительность методов Resolve() и корней композиции.


















