Программист зверь ленивый, поэтому всё, что будет делаться больше одного раза надо непременно заскриптовать.
Я уже некоторое время ковыряю
TDD и задача постоянного контроля качества для меня становится всё актуальней. Особенно при пополнении команды новыми разработчиками.
Сначала я запускал тесты руками: save, switch, $ nosetests. Потом к тестам добавились проверялки качества кода и пришлось всё засунуть в скрипт:
pyflakes *.py
pep8 *.py
pylint *.py
nosetests
Скрипт запускать каждый раз ужасно лениво, поэтому небольшая оболочка на inotifywait стала запускать тесты и проверки после каждого сохранения:
while true; do
inotifywait -e modify project/*.py -qq; clear
./do_tests
done
Тут я стал более-менее доволен происходящим и даже на некоторое время расслабился. Но ведь программист кроме того, что ленив ещё и горд, поэтому результаты хочется кому-нибудь показать. Чтобы вести историю происходящего (которая очень помогает когда заходит начальник начальника и спрашивает: «ну-с, чем вы занимались последний месяц?») уже есть система контроля версий. Но она показывает только, что сделано и не даёт обзора успешности каждой ревизии. Получается что код лежит, но непонятно в каком он состоянии и что где ещё надо сделать.
Кроме того довольно тяжело следить за коллегами, которые тоже могут что-то сделать и забыть прогнать тесты, в результате в репозитории лежит битый код, не прошедший code review и при очередном pull может внезапно начаться clusterfuck.
И тут очень вовремя kmmbvnr@lj выпустил
скринкаст, в котором он демонстрировал интеграцию тестирования для django-проектов с сабжем Jenkins (бывш. Hudson). Посмотрел я на все эти красоты, графики и отчёты и тоже захотел чтобы всё само пело и играло. Но у него django-jenkins, как и следует из названия, встраивается в джангу и генерит отчёты используя хитрую систему. Мой проект до джанги не дорос и скорее всего не дорастёт — это достаточно тривиальное WSGI-приложение, которое правда стремительно разрастается. Пришлось поднимать всё с нуля.
Воскресенье я на это убил, но в целом всё довольно прямолинейно и теперь у меня есть симпатичные отчёты:
 Что внутри?
Что внутри?




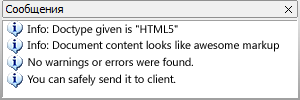 Вы PM. Как узнать – готова ли вёрстка к реальному использованию?
Вы PM. Как узнать – готова ли вёрстка к реальному использованию?
 Загрузка файлов всегда занимала особое место в веб-разработке.
Загрузка файлов всегда занимала особое место в веб-разработке. Под катом — описание восьми сервисов, которые могут заметно облегчить жизнь веб-разработчика, верстальщика или дизайнера.
Под катом — описание восьми сервисов, которые могут заметно облегчить жизнь веб-разработчика, верстальщика или дизайнера. 
 Мой
Мой 

