Через любую высоконагруженную систему ежесекундно проходит огромный поток трафика. Релизы, хотфиксы, ddos-атаки, невалидные и ухудшающие эксперименты и многие другие события могут привести к проблемам, которые влияют на пользователей. Поэтому такие ситуации не терпят задержек.
Можно провести простую аналогию: если вы чем-то заболели, то лучше узнать об этом как можно раньше и тем самым минимизировать побочные эффекты после и в процессе выздоровления. Так и в сервисе: будь то баннерная крутилка, поиск, маркетплейс или онлайн-доставка пиццы.
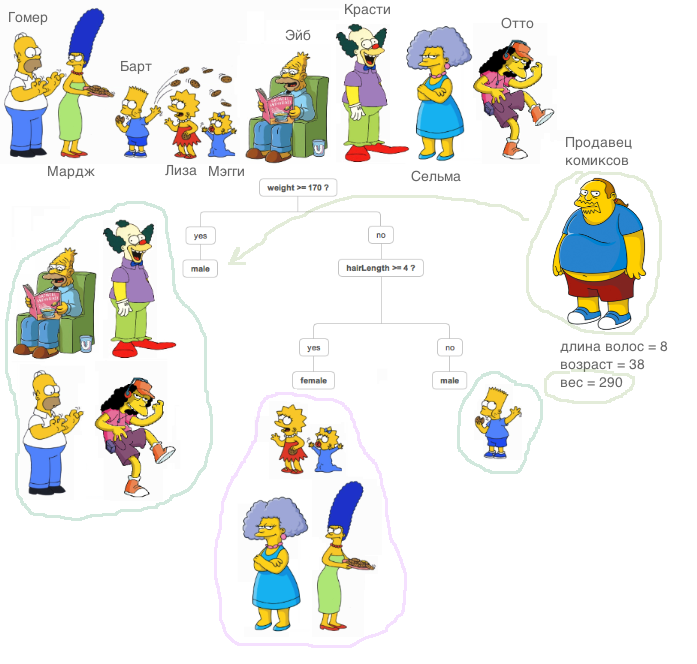
Меня зовут Владимир Точилин, я работаю в группе развития рекламных продуктов и стабильности. Вместе со своим коллегой, Александром Самусенко, я расскажу, как мы создали новый инструмент realtime-детекции разладок в проде рекламных технологий. Мы работаем с системой, где на отдельные кластеры нагрузка превышает 1000000 RPS.
Историю будет интересно прочитать аналитикам, разработчикам и менеджерам любого уровня.