В статье и комментариях есть замеры - reduce + concat на массиве из 1000 элементов отрабатывает около 2мс.
При обработке 1000 элементов, скорее всего, не эта операция окажется узким местом.
Более близкой аналогия была бы, если предположить, что статья предлагает использовать ополаскиватель для рта. Это полезно и с этим никто не спорит, но неиспользование ополаскивателя не является ключевым фактором проблем с зубами.
Если у вас 1-ая версия (где slice после map, а не наоборот) может пройти code-review
Да, такой код может пройти code-review (как и код с concat), если учитывать контекст применения кода. Например, если нам достаточно, чтобы код корректно работал и выполнялся не дольше минуты.
я рад что не работаю у вас :) На мой взгляд это уже настоящее разгильдяйство
Стало еще более субьективно. А как же условия, контексты?
Предлагаю на этом сообщений завершить тред, т.к. от цифр мы пришли к обвинению в непрофессионализме, как в настоящем холиваре :)
это вопрос конкретных условий как и где эти 250 элементов обрабатываются.
Согласен, всегда следует оттакливаться от контекста. Есть контексты, где это важная оптимизация, которая ускорит процесс. Но, по моим ощущениям, их очень мало. А в большинстве контекстов неважно, concat там будет или не concat
Судя по бенчмаркам, 250 элементов обработаются достаточно быстро.
Для того чтобы этой проблемы не было обязательно ждать таску в Jira? Вот эта строка кода стоит того
Эта строка кода не гарантирует, что проблем не будет. Проблема не в том, что concat писали, а в том, что проектировали под список из 10-20 элементов. Ну будет вместо concat что-то более оптимизированное, а рендер не оптимизировали и UX неудобный т.к. изначально не предполагали больше 10 элементов в списке.
Мне, при беглом прочтении статьи, показалось, что обработка 1000 элементов через concat занимает 2 секунды , а через push - 30 мс.
Но там делается 1000 прогонов по 1000 элементов и потом замеряется общее время. Получается, concat на 1000 элементов в среднем выполнялся за 2мс. Это, конечно, много и повлияет на рендер, но не прям драмматично.
Если нам нужно эти 1000 элементов еще и отрендерить, то полезнее будет заняться оптимизацией рендера, а не заменой concat
Сделал бенч на jsbench.me и выглядит, что чтобы не уложится в 16 мс, нужно пару сотен элементов в массиве.
Это я не к тому, что использовать concat в reduce - хорошая практика. Но из статьи выглядит, будто бы уже при 30 элементах в массиве будет проседать перформанс, однако это не так. Граница, когда все становится плохо, находится дальше и там, возможно, concat будет не самой большой проблемой
Готовых решений не знаю. Я бы на коленке попробовал бы сделать микроплагин в котором свойство будет прокидываться как в Vuex. Насколько помню, в vuex плагине при инициализации инстанса компонента он копирует себе ссылку на $store от родителя.
Там что-то типа
if (this.parent.$store) {
this.$store = this.parent.$store;
}
Можно также сделать и провайдить моки на верхнем компоненте истории
Вот Вы упомянули vue-test-utils и jest — подозреваю как-то они использовались, чтобы мокать глобальные параметры/запросы в stories
Они использовались для тестов логики (клик на кнопку => сделали запрос => обработали ответ)
Не поделитесь опытом как это делается?
Сниппетов кода на Vue под рукой у меня нет, а с Vue я уже давненько не работал и не помню точно, как там все делается. Но сам подход не привязан к какому-то конкретному фреймворку, попробую описать.
Допустим, у нас есть фича, которая использует данные о cookie и делает http запрос. В этом случае, для того чтобы протестировать верстку в storybook мы можем:
Разделить логику и представление
Вынести знания об использовании cookie и делании http запроса из компонента. По сути вынести логику из компонента. Это можно вынести в Vuex, но насколько я знаю Vuex — это уже не торт и сейчас торт — хуки. В любом случае, мы можем разделить сущность на 2: компонент, который рендерит верстку и что-то, что отвечает за логику (другой компонент или стор+компонент, суть которого — взять данные и колбеки из стора и прокинуть их в наш рендер-компонент). В этом случае наш рендер-компонент будет чистым, а тут задача со сторибуком решена.
Плюсы:
легко получаем любые возможные состояния компонента.
Минусы:
логику нужно тестировать иначе.
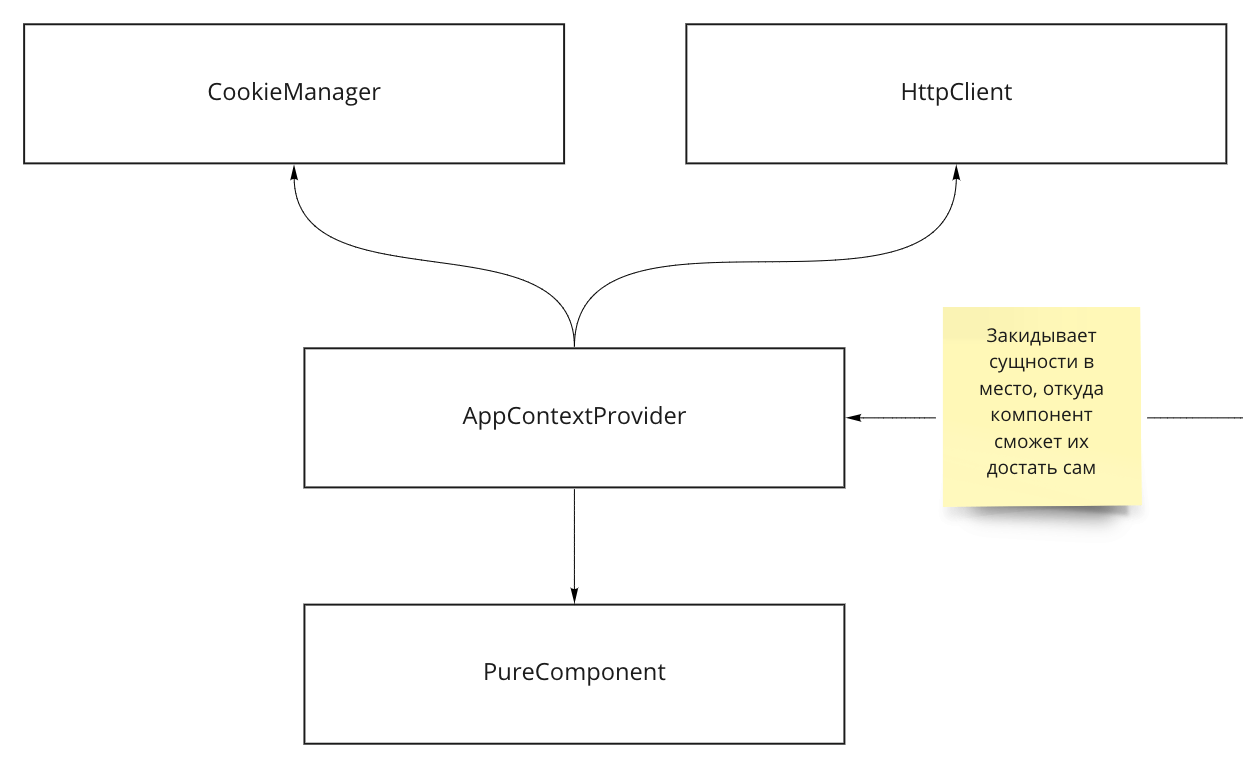
Выделить сущности CookieManager и HttpClient и провайдить их через контекст
Мы выделяем явные сущности для доступа к cookie и деланию запросов: CookieManager и HttpClient, которые мы достаем в компоненте из контекста/глобальной переменной. В приложении мы это делаем с помощью AppContextProvider (заполняет какой-то контекст), а для storybook историй пишем специальный HoC, который умеет заполнять тот же контекст моками (в случае глобального контекста делаем это перед mount). Таким образом в каждой истории перед маунтом мы будем подменять сущности на нужные моки и истории будут изолированы.
Структура в приложении
Структура в storybook
Минусы:
глобальный контекст — это не очень здорово
может быть сложнее получать нужные для теста состояния компонента
Хардкорные моки
Мы не выделяем никаких сущностей, а сразу по хардкору мокаем сеть, например с помощью msw или любого другого решения. Ну и cookie чем нибудь мокаем.
Имел пару лет назад опыт настройки окружения тестирования для vue.js@2 и могу сказать, что работа с экосистемой vue.js — это путь боли и страдания :)
К сожалению, не могу подсказать, как сейчас обстоят с этим дела в vue.js. 2 года назад я использовал связку vue-test-utils + jest и storybook/vue. Кажется в обоих случаях пришлось напилиньком дорабатывать конфиги jest и storybook.
Не то чтобы я защищал redux или нападал на mobx. Но в контексте статьи мне непонятно причем здесь redux и mobx.
Звучит, как будто бы какой бы инструмент мы не выбрали, принципиальной разницы для архитектуры нет. А значит можно отвязать весь топик и от redux и от mobx и говорить просто о принципах хорошей (по каким-то показателям) архитектуры, не спекулируя о субьективных минусах и плюсах конкретных инструментов.
А в чем принципиальная разница между этим решением и использованием:
redux или useReducer для хранения данных
thunk-middleware или обычных функций для логики контроллера
Кажется, что с точки зрения "слоев" и отношений между ними полный паритет. Разница только в синтаксисе, но бороться с бойлерплэйтом redux научились уже давно.
Вы так говорите, будто Core Web Vitals — единственная метрика по ранжированию сайтов. Можно иметь 100 баллов в Lighthouse, но не быть даже на первой странице в выдаче по сотне других причин.
пусть пользователь сам решает, готов ли он ждать дополнительные 500 мс или ему выдать оптимизированный список.
Пользователь в итоге сам и решает. Он уйдет к конкурентам, если его не устроит скорость загрузки сервиса, и сервис, при этом, не имеет уникальных удерживающих факторов.
пусть разработчик то же решает сам, охватить ему всех, или нацелиться на нужную локацию
google не заставляет разработчиков оптимизировать свои метрики Core Web Vitals. Не хотите — не оптимизируйте. Можно быть в топе выдачи по другим признакам.
Более того, всегда можно запретить гуглу индексировать себя, это тоже выбор разработчика.
ИМХО, В целом большинство сайтов как были медленными, так и останутся, не смотря на потуги гугла. Ускоряться будут лишь те сервисы, где конкуренция настолько сильная, что "скорость работы сервиса" считается преимуществом.
Хорошо вам, внутри МКАДа. А у меня в городе-миллионнике 3G не везде ловит и есть места где единственная возможность выйти в сеть — ADSL интернет за 600 рублей в месяц.
Звучит банально, если скрипты рекламных блоков будут загружаться долго, на это разработчик не может повлиять
Зато есть куча других вещей, на которые разработчик может повлиять:
Загрузка и использование шрифтов
Выделение critical css
Загрузка только необходимой для показа части приложения
Предзагрузка данных для первичного отображения страницы
Оптимизация запросов в API
Оптимизация рендера
Кроме медленного интернета также нужно учитывать устройства пользователей. В отличии от разработчиков, у среднего пользователя не 8-ядерный intel и не 32 ГБ ОЗУ.
Не знаю, сначала бы найти фреймворк, который создает DOM. Вроде никто DOM не создает. VDOM может быть делают, а может и нет. Не углублялся в исходники фреймворков.
Знаю, что Vue умеет в серверные оптимизации рендера, включая рендер статических частей сразу в строку. В собранном вебпаком бандле можно найти код того же уровня, что и в статье — рендер строкой сразу. И потоковый рендер там есть.
Я не утверждал, что кто-то еще использует потоковый рендер без создания DOM (что бы это ни значило). Я утверждал, что потоковый рендер — не изобретение marko.
И то, что заявления вида "Marko.js неистово быстр" ничем не подкреплены.
apapacy а можно вот написать про все, что описал faiwer ?
А то в текущей статьей больше вопросов, чем ответов, т.к. куча тезисов просто остались нераскрытыми:
Marko.js неистово быстр
Marko.js можно считать SSR-first библиотекой
Всем известно, что node.js не так хорош, если его нагружать сложными расчетами
Код компонентов интуитивно понятен
Ко всем тезисам базовый вопрос "почему?".
Из статьи это осталось непонятным.
Также непонятно, почему я мог бы задуматься об его использовании.
Насколько он удобен в работе?
Какие фишки у него есть, которых нет у других?
Легко ли его встроить в существующее приложение?
А что там по типизации?
А что по тестам?
А сторибук поддержиается?
По текущей статье я узнал о существовании universal-router и о том, что, возможно marko.js быстро рендерит на сервере. Хотя не он один использует потоковый рендер.

Это очень спекулятивная аналогия.
В статье и комментариях есть замеры - reduce + concat на массиве из 1000 элементов отрабатывает около 2мс.
При обработке 1000 элементов, скорее всего, не эта операция окажется узким местом.
Более близкой аналогия была бы, если предположить, что статья предлагает использовать ополаскиватель для рта. Это полезно и с этим никто не спорит, но неиспользование ополаскивателя не является ключевым фактором проблем с зубами.
Да, такой код может пройти code-review (как и код с
concat), если учитывать контекст применения кода. Например, если нам достаточно, чтобы код корректно работал и выполнялся не дольше минуты.Стало еще более субьективно. А как же условия, контексты?
Предлагаю на этом сообщений завершить тред, т.к. от цифр мы пришли к обвинению в непрофессионализме, как в настоящем холиваре :)
Смотря что понимать под оптимизацией. Но я не знаю определения, по которому код с
pushменее оптимальный, чем код сconcatЭто звучит очень субьективно
Согласен, всегда следует оттакливаться от контекста. Есть контексты, где это важная оптимизация, которая ускорит процесс. Но, по моим ощущениям, их очень мало. А в большинстве контекстов неважно,
concatтам будет или неconcatЕсли честно, я не понял вашу мысль.
Судя по бенчмаркам, 250 элементов обработаются достаточно быстро.
Эта строка кода не гарантирует, что проблем не будет. Проблема не в том, что
concatписали, а в том, что проектировали под список из 10-20 элементов. Ну будет вместоconcatчто-то более оптимизированное, а рендер не оптимизировали и UX неудобный т.к. изначально не предполагали больше 10 элементов в списке.Проблем нет. Ощутимой пользы, в подавляющем большинстве случаев, тоже.
Мне, при беглом прочтении статьи, показалось, что обработка 1000 элементов через
concatзанимает 2 секунды , а черезpush- 30 мс.Но там делается 1000 прогонов по 1000 элементов и потом замеряется общее время. Получается,
concatна 1000 элементов в среднем выполнялся за 2мс. Это, конечно, много и повлияет на рендер, но не прям драмматично.Если нам нужно эти 1000 элементов еще и отрендерить, то полезнее будет заняться оптимизацией рендера, а не заменой
concatЯ повторил бенч из скриншотов из Firefox и Chrome. Там где сравниваются 2600 vs 30
Сделал бенч на jsbench.me и выглядит, что чтобы не уложится в 16 мс, нужно пару сотен элементов в массиве.
Это я не к тому, что использовать
concatвreduce- хорошая практика. Но из статьи выглядит, будто бы уже при 30 элементах в массиве будет проседать перформанс, однако это не так. Граница, когда все становится плохо, находится дальше и там, возможно,concatбудет не самой большой проблемойБенч: https://jsbench.me/45kwbqj1xj/1
Готовых решений не знаю. Я бы на коленке попробовал бы сделать микроплагин в котором свойство будет прокидываться как в Vuex. Насколько помню, в vuex плагине при инициализации инстанса компонента он копирует себе ссылку на $store от родителя.
Там что-то типа
Можно также сделать и провайдить моки на верхнем компоненте истории
Они использовались для тестов логики (клик на кнопку => сделали запрос => обработали ответ)
Сниппетов кода на Vue под рукой у меня нет, а с Vue я уже давненько не работал и не помню точно, как там все делается. Но сам подход не привязан к какому-то конкретному фреймворку, попробую описать.
Допустим, у нас есть фича, которая использует данные о cookie и делает http запрос. В этом случае, для того чтобы протестировать верстку в storybook мы можем:
Разделить логику и представление
Вынести знания об использовании cookie и делании http запроса из компонента. По сути вынести логику из компонента. Это можно вынести в Vuex, но насколько я знаю Vuex — это уже не торт и сейчас торт — хуки. В любом случае, мы можем разделить сущность на 2: компонент, который рендерит верстку и что-то, что отвечает за логику (другой компонент или стор+компонент, суть которого — взять данные и колбеки из стора и прокинуть их в наш рендер-компонент). В этом случае наш рендер-компонент будет чистым, а тут задача со сторибуком решена.
Плюсы:
Минусы:
Выделить сущности CookieManager и HttpClient и провайдить их через контекст
Мы выделяем явные сущности для доступа к cookie и деланию запросов: CookieManager и HttpClient, которые мы достаем в компоненте из контекста/глобальной переменной. В приложении мы это делаем с помощью AppContextProvider (заполняет какой-то контекст), а для storybook историй пишем специальный HoC, который умеет заполнять тот же контекст моками (в случае глобального контекста делаем это перед mount). Таким образом в каждой истории перед маунтом мы будем подменять сущности на нужные моки и истории будут изолированы.
Структура в приложении
Структура в storybook
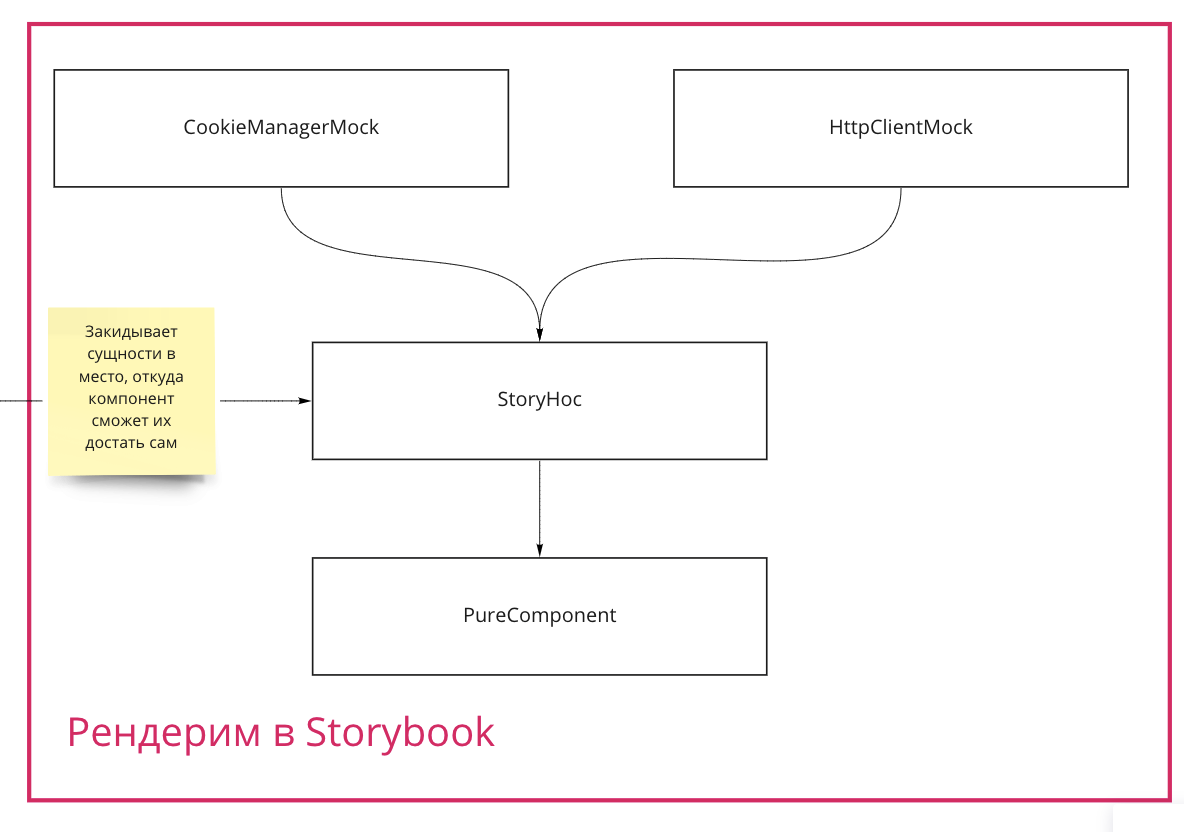
Минусы:
Хардкорные моки
Мы не выделяем никаких сущностей, а сразу по хардкору мокаем сеть, например с помощью msw или любого другого решения. Ну и cookie чем нибудь мокаем.
Плюсы:
Минусы:
Имел пару лет назад опыт настройки окружения тестирования для vue.js@2 и могу сказать, что работа с экосистемой vue.js — это путь боли и страдания :)
К сожалению, не могу подсказать, как сейчас обстоят с этим дела в vue.js. 2 года назад я использовал связку
vue-test-utils+jestиstorybook/vue. Кажется в обоих случаях пришлось напилиньком дорабатывать конфиги jest и storybook.Не то чтобы я защищал redux или нападал на mobx. Но в контексте статьи мне непонятно причем здесь redux и mobx.
Звучит, как будто бы какой бы инструмент мы не выбрали, принципиальной разницы для архитектуры нет. А значит можно отвязать весь топик и от redux и от mobx и говорить просто о принципах хорошей (по каким-то показателям) архитектуры, не спекулируя о субьективных минусах и плюсах конкретных инструментов.
А в чем принципиальная разница между этим решением и использованием:
Кажется, что с точки зрения "слоев" и отношений между ними полный паритет. Разница только в синтаксисе, но бороться с бойлерплэйтом redux научились уже давно.
Вы так говорите, будто Core Web Vitals — единственная метрика по ранжированию сайтов. Можно иметь 100 баллов в Lighthouse, но не быть даже на первой странице в выдаче по сотне других причин.
Пользователь в итоге сам и решает. Он уйдет к конкурентам, если его не устроит скорость загрузки сервиса, и сервис, при этом, не имеет уникальных удерживающих факторов.
google не заставляет разработчиков оптимизировать свои метрики Core Web Vitals. Не хотите — не оптимизируйте. Можно быть в топе выдачи по другим признакам.
Более того, всегда можно запретить гуглу индексировать себя, это тоже выбор разработчика.
ИМХО, В целом большинство сайтов как были медленными, так и останутся, не смотря на потуги гугла. Ускоряться будут лишь те сервисы, где конкуренция настолько сильная, что "скорость работы сервиса" считается преимуществом.
Хорошо вам, внутри МКАДа. А у меня в городе-миллионнике 3G не везде ловит и есть места где единственная возможность выйти в сеть — ADSL интернет за 600 рублей в месяц.
Зато есть куча других вещей, на которые разработчик может повлиять:
Кроме медленного интернета также нужно учитывать устройства пользователей. В отличии от разработчиков, у среднего пользователя не 8-ядерный intel и не 32 ГБ ОЗУ.
Не знаю, сначала бы найти фреймворк, который создает DOM. Вроде никто DOM не создает. VDOM может быть делают, а может и нет. Не углублялся в исходники фреймворков.
Знаю, что Vue умеет в серверные оптимизации рендера, включая рендер статических частей сразу в строку. В собранном вебпаком бандле можно найти код того же уровня, что и в статье — рендер строкой сразу. И потоковый рендер там есть.
Я не утверждал, что кто-то еще использует потоковый рендер без создания DOM (что бы это ни значило). Я утверждал, что потоковый рендер — не изобретение marko.
И то, что заявления вида "Marko.js неистово быстр" ничем не подкреплены.
apapacy а можно вот написать про все, что описал faiwer ?
А то в текущей статьей больше вопросов, чем ответов, т.к. куча тезисов просто остались нераскрытыми:
Ко всем тезисам базовый вопрос "почему?".
Из статьи это осталось непонятным.
Также непонятно, почему я мог бы задуматься об его использовании.
По текущей статье я узнал о существовании universal-router и о том, что, возможно marko.js быстро рендерит на сервере. Хотя не он один использует потоковый рендер.
Могу помочь с публикацией в chrome store.
Это же наконец-то можно двух обреченных подкастеров забанить в своей ленте
Работаю программистом, пользуюсь iris клавиатурой.
Именно потому что спецсимволы приходится шлёпать часто, поместил самые нужные
-=<>(){}[]рядом друг с другом на отдельном слое.На другом слое навигация — стрелочки, pgup, pgdn, home, end.
Желания возвращаться на большую квадратную клавиатуру — нет.