Добрый день!
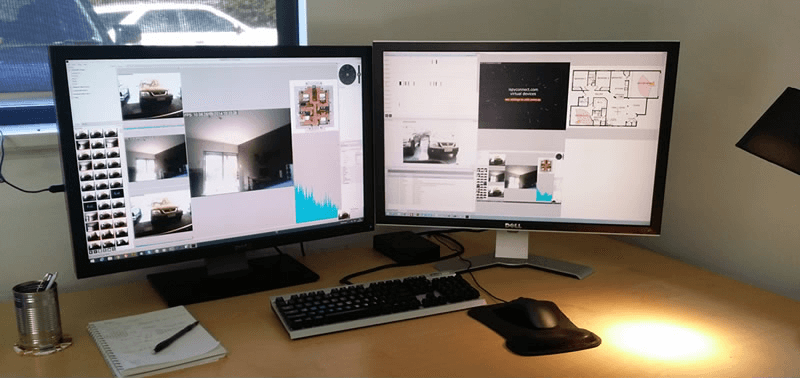
В данной статье хочу рассказать о том, как немного повысить производительность хоста ESXi с помощью SSD кэширования. На работе и дома я использую продукты от компании VMware, домашняя лаборатория построена на базе Free ESXi 6.5. На хосте запущены виртуальные машины как для домашней инфраструктуры, так и для тестирования некоторых рабочих проектов (как-то мне пришлось запустить на нем инфраструктуру VDI). Постепенно приложения толстых ВМ начали упираться в производительность дисковой системы, а на SDD все не помещалось. В качестве решения был выбран lvmcache. Логическая схема выглядит так:

В данной статье хочу рассказать о том, как немного повысить производительность хоста ESXi с помощью SSD кэширования. На работе и дома я использую продукты от компании VMware, домашняя лаборатория построена на базе Free ESXi 6.5. На хосте запущены виртуальные машины как для домашней инфраструктуры, так и для тестирования некоторых рабочих проектов (как-то мне пришлось запустить на нем инфраструктуру VDI). Постепенно приложения толстых ВМ начали упираться в производительность дисковой системы, а на SDD все не помещалось. В качестве решения был выбран lvmcache. Логическая схема выглядит так:







 И сегодня она попала в поток «Администрирование». Сегодня мы не будем
И сегодня она попала в поток «Администрирование». Сегодня мы не будем