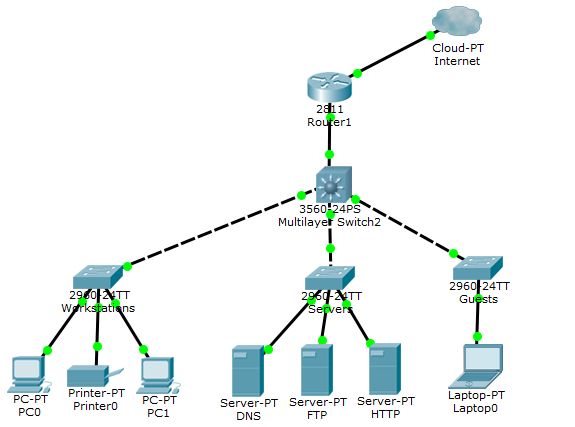
Сегодня мы будет изучать протокол IPv6. Предыдущая версия курса CCNA не требовала детального ознакомления с этим протоколом, однако в третьей версии 200-125 его углубленное изучение является обязательным для сдачи экзамена. Протокол IPv6 был разработан довольно давно, однако долгое время не находил широкого применения. Он очень важен для дальнейшего развития интернета, поскольку предназначен для устранения недостатков повсеместно распространенного протокола IPv4.
Так как протокол IPv6 — довольно обширная тема, я разбил ее на два видеоурока: День 24 и День 25. Первый день мы посвятим основным понятиям, а на второй рассмотрим настройку IP адресов по протоколу IPv6 для устройств Cisco. Сегодня мы как обычно рассмотрим три темы: необходимость IPv6, формат адресов IPv6 и типы адресов IPv6.

До сих пор на наших уроках мы пользовались IP-адресами по протоколу v4, и вы привыкли к тому, что они выглядят достаточно просто. Когда вы видели адрес, изображенный на этом слайде, то прекрасно понимали, о чем идет речь.
Так как протокол IPv6 — довольно обширная тема, я разбил ее на два видеоурока: День 24 и День 25. Первый день мы посвятим основным понятиям, а на второй рассмотрим настройку IP адресов по протоколу IPv6 для устройств Cisco. Сегодня мы как обычно рассмотрим три темы: необходимость IPv6, формат адресов IPv6 и типы адресов IPv6.
До сих пор на наших уроках мы пользовались IP-адресами по протоколу v4, и вы привыкли к тому, что они выглядят достаточно просто. Когда вы видели адрес, изображенный на этом слайде, то прекрасно понимали, о чем идет речь.







 Всем привет! Одно из видений
Всем привет! Одно из видений