Деревья в базах данных можно хранить тремя основными методами: Adjacency List, Matherialized Path & Nested Set. Когда мы хотим переехать с AL на NS, это можно сделать с помощью рекурсии (если БД расово верная). Но что делать в случае MySQL?

Дмитрий Цапко @taaraora
Software Engineer
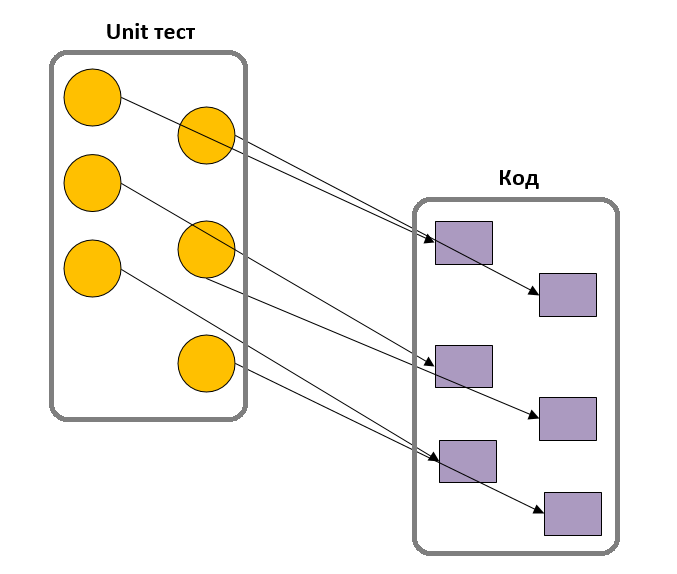
Юнит тесты. Первый шаг к качеству
7 min
Однажды меня попросили рассказать о юнит тестировании в javascript, но прежде чем рассказывать о тестировании в мире front-end, надо было сделать небольшой обзор юнит тестирования как такового. В результате чего на свет и появилась эта статья, в которой я попытался рассказать о самых важных моментах в юнит тестировании.
Собеседование для фронтенд-разработчика на JavaScript: самые лучшие вопросы
9 min
Translation
Недавно мне довелось побывать на встрече участников проекта FreeCodeCamp в Сан-Франциско. Если кто не знает, Free Code Camp — это сообщество, нацеленное на изучение JavaScript и веб-программирования. Там один человек, который готовился к собеседованиям на позицию фронтенд-разработчика, попросил меня подсказать, какие вопросы по JavaScript стоит проработать. Я немного погуглил, но не смог найти подходящего списка вопросов, на который я бы мог дать ссылку и сказать: «Разбери эти вопросы и работа твоя». Некоторые списки были близки к тому, что мне хотелось найти, некоторые выглядели очень уж простыми, но все они были либо неполными, либо содержали вопросы, которые вряд ли кто станет задавать на реальном собеседовании.

Dive into Ethereum
14 min
Сегодня платформа Ethereum стала одним из самых узнаваемых брендов блокчейн сферы, вплотную приблизившись по популярности (и капитализации) к Bitcoin. Но из-за отсутствия "полноценного" рускоязычного гайда, отечественные разработчики все еще не очень понимают, что это за зверь и как с ним работать. Поэтому в данной статье я попытался максимально подробно охватить все аспекты разработки умных контрактов под Ethereum.
Я расскажу про инструменты разработки, сам ЯП, процесс добавления UI и еще много интересного. В конечном итоге мы получим обычный сайт-визитку, но "под капотом" он будет работать на умных контрактах Ethereum. Кого заинтересовало — прошу под кат.

Hibernate cache
6 min
Довольно часто в java приложениях с целью снижения нагрузки на БД используют кеш. Не много людей реально понимают как работает кеш под капотом, добавить просто аннотацию не всегда достаточно, нужно понимать как работает система. Поэтому этой статье я попытаюсь раскрыть тему про то, как работает кеш популярного ORM фреймворка. Итак, для начала немного теории.
Прежде всего Hibernate cache — это 3 уровня кеширования:
Кеш первого уровня всегда привязан к объекту сессии. Hibernate всегда по умолчанию использует этот кеш и его нельзя отключить. Давайте сразу рассмотрим следующий код:
Возможно, Вы ожидаете, что будет выполнено 2 запроса в БД? Это не так. В этом примере будет выполнен 1 запрос в базу, несмотря на то, что делается 2 вызова load(), так как эти вызовы происходят в контексте одной сессии. Во время второй попытки загрузить план с тем же идентификатором будет использован кеш сессии.
Один важный момент — при использовании метода load() Hibernate не выгружает из БД данные до тех пор пока они не потребуются. Иными словами — в момент, когда осуществляется первый вызов load, мы получаем прокси объект или сами данные в случае, если данные уже были в кеше сессии. Поэтому в коде присутствует getName() чтобы 100% вытянуть данные из БД. Тут также открывается прекрасная возможность для потенциальной оптимизации. В случае прокси объекта мы можем связать два объекта не делая запрос в базу, в отличии от метода get(). При использовании методов save(), update(), saveOrUpdate(), load(), get(), list(), iterate(), scroll() всегда будет задействован кеш первого уровня. Собственно, тут нечего больше добавить.
Прежде всего Hibernate cache — это 3 уровня кеширования:
- Кеш первого уровня (First-level cache);
- Кеш второго уровня (Second-level cache);
- Кеш запросов (Query cache);
Кеш первого уровня
Кеш первого уровня всегда привязан к объекту сессии. Hibernate всегда по умолчанию использует этот кеш и его нельзя отключить. Давайте сразу рассмотрим следующий код:
SharedDoc persistedDoc = (SharedDoc) session.load(SharedDoc.class, docId);
System.out.println(persistedDoc.getName());
user1.setDoc(persistedDoc);
persistedDoc = (SharedDoc) session.load(SharedDoc.class, docId);
System.out.println(persistedDoc.getName());
user2.setDoc(persistedDoc);
Возможно, Вы ожидаете, что будет выполнено 2 запроса в БД? Это не так. В этом примере будет выполнен 1 запрос в базу, несмотря на то, что делается 2 вызова load(), так как эти вызовы происходят в контексте одной сессии. Во время второй попытки загрузить план с тем же идентификатором будет использован кеш сессии.
Один важный момент — при использовании метода load() Hibernate не выгружает из БД данные до тех пор пока они не потребуются. Иными словами — в момент, когда осуществляется первый вызов load, мы получаем прокси объект или сами данные в случае, если данные уже были в кеше сессии. Поэтому в коде присутствует getName() чтобы 100% вытянуть данные из БД. Тут также открывается прекрасная возможность для потенциальной оптимизации. В случае прокси объекта мы можем связать два объекта не делая запрос в базу, в отличии от метода get(). При использовании методов save(), update(), saveOrUpdate(), load(), get(), list(), iterate(), scroll() всегда будет задействован кеш первого уровня. Собственно, тут нечего больше добавить.
Книга об интенсивной обработке данных
4 min
Translation
Здравствуйте, дорогие читатели. Мы редко пишем о книжных «долгостроях», то есть, о работах, которые никак не выйдут на Западе. Но сегодня хотим познакомить вас с постом из блога Мартина Клеппмана, который уже не первый год трудится над фундаментальной книгой "Designing Data-Intensive Applications"

В сравнительно небольшой публикации автору удалось изложить базовые идеи столь объемной книги, обрисовать целевую аудиторию и почти убедить нас, что за перевод надо браться. Но вы все равно почитайте и не стесняйтесь голосовать.
В сравнительно небольшой публикации автору удалось изложить базовые идеи столь объемной книги, обрисовать целевую аудиторию и почти убедить нас, что за перевод надо браться. Но вы все равно почитайте и не стесняйтесь голосовать.
N+5 полезных книг
5 min

Привет! Это пятый с 2010 года список полезных книг. Набралась всего дюжина за два года. Смотрите, что можно скачать в дорогу или просто почитать, когда будет время, и делитесь, пожалуйста, в комментариях своими (я буду поднимать их в пост). В этой подборке довольно много социнжиниринга, точнее, тем около него. Поехали.
Конструкции, или почему не ломаются вещи, Дж. Гордон
Прекрасная, хоть и очень длинная штука, которая рассказывает про сопромат простыми словами и почти для детей. Но на уровне жёсткого хардкора. По своей полезности для осознания физики вокруг может сравниться с не менее прекрасной современной «Квантовая вселенная. Как устроено то, что мы не можем увидеть» Брайана Кокса и Джеффа Форшоу. Рекомендую обе. Будет, что почитать в дороге, если вдруг почувствуете, что играть на планшете надоело. И о чём подумать, когда выяснится, что вся та фигня, которую вам давали на уроках химии, физики и прочего в школе и университете вдруг начинает выстраиваться в стройную теорию.
Evil by Design, Крис Ноддер
Один из лучших подходов к проектированию чего-то хорошего — это спроектировать сначала самое ужасное из возможного. Пользователь обычно не скажет, как сделать ему хорошо, но точно знает, как бывает плохо. Например, юзер не говорит «я хочу, когда нажимаю на ссылку напоминания пароля, там в поле уже была введена почта», зато вполне способен сказать: «слушай, меня дико бесит, когда логинишься, тебе показывают новую страницу про то, что пароль не подошёл, и, чтобы его восстановить, надо ещё один долбанный раз вводить почту». Вся книга Криса состоит из таких «тёмных» шаблонов, когда какие-то гады намеренно вводят вас в заблуждение. Он там очень переживает за этику, поэтому вступления лучше пропустить. Единственная в этом обзоре книга на английском, но довольно простом.
Как выгрузить логически согласованый набор данных из нескольких таблиц в БД под OLTP нагрузкой
2 min
Как выгрузить логически согласованый набор данных из нескольких таблиц в БД под OLTP нагрузкой?
[СПб, Анонс] Встреча с Андреем Паньгиным — Всё, что вы хотели знать о стек-трейсах и хип-дампах
1 min
В четверг, 26 мая, в 20:00 в питерском офисе компании Luxoft состоится встреча JUG.ru с Андреем Паньгиным aka apangin, ведущим разработчиком Одноклассников. Тема встречи — особенности JDK, связанные с обходом Heap-a и стеками потоков.

Stack Trace и Heap Dump — не только инструменты отладки, но ещё и дверцы к самым недрам виртуальной машины Java. Презентация посвящена особенностям JDK, так или иначе связанным с обходом хипа и стеками потоков. В её основе лежат популярные вопросы про JVM со StackOverflow и реальные случаи из практики.
Участие бесплатное, регистрация — ТУТ.
Stack Trace и Heap Dump — не только инструменты отладки, но ещё и дверцы к самым недрам виртуальной машины Java. Презентация посвящена особенностям JDK, так или иначе связанным с обходом хипа и стеками потоков. В её основе лежат популярные вопросы про JVM со StackOverflow и реальные случаи из практики.
- Влияют ли стек-трейсы на производительность?
- Как снимать дампы в продакшне без побочных эффектов?
- Как устроены утилиты jmap и jstack изнутри?
- Почему все профайлеры врут, и как с этим бороться?
- Как сканировать хип средствами JVMTI и Serviceability Agent?
Участие бесплатное, регистрация — ТУТ.
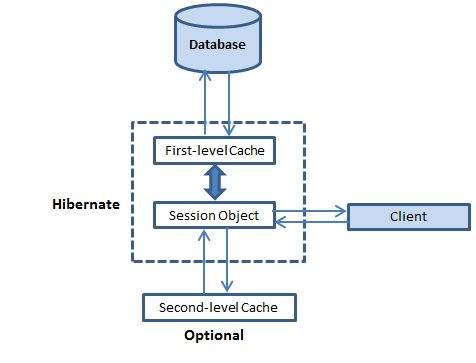
Документация разработчика Hibernate – Глава VI. Кэширование
7 min
Представляю вашему вниманию перевод шестой главы официальной документации Hibernate.
Перевод статьи актуален для версии Hibernate 4.2.19.Final
Предыдущая глава — Документация разработчика Hibernate – Глава V. Блокировки
Что собой представляют кэш первого и второго уровня в Hibernate, показано на следующий диаграмме (прим. автора).
Если у вас есть запросы, выполняющиеся снова и снова, с одними и теми же параметрами, кэширование запросов предоставит выигрыш в производительности.
Кэширование вводит дополнительные накладные расходы в области выполнения транзакций. К примеру, если вы кэшируете результаты запроса по отношению к какому-либо объекту, Hibernate необходимо отслеживать, были ли закоммичены какие-либо изменения по объекту, и в соответствии с этим, аннулировать записи в кэше. В дополнение, плюсы от кэширования запросов ограничены, и очень зависят от шаблонов использования вашего приложения. По этим причинам, Hibernate по-умолчанию выключает кэширование запросов.
Перевод статьи актуален для версии Hibernate 4.2.19.Final
Предыдущая глава — Документация разработчика Hibernate – Глава V. Блокировки
Что собой представляют кэш первого и второго уровня в Hibernate, показано на следующий диаграмме (прим. автора).
6.1. Кэш запросов
Если у вас есть запросы, выполняющиеся снова и снова, с одними и теми же параметрами, кэширование запросов предоставит выигрыш в производительности.
Кэширование вводит дополнительные накладные расходы в области выполнения транзакций. К примеру, если вы кэшируете результаты запроса по отношению к какому-либо объекту, Hibernate необходимо отслеживать, были ли закоммичены какие-либо изменения по объекту, и в соответствии с этим, аннулировать записи в кэше. В дополнение, плюсы от кэширования запросов ограничены, и очень зависят от шаблонов использования вашего приложения. По этим причинам, Hibernate по-умолчанию выключает кэширование запросов.
Документация разработчика Hibernate – Глава V. Блокировки
6 min
Tutorial
Представляю вашему вниманию перевод пятой главы официальной документации Hibernate.
Перевод статьи актуален для версии Hibernate 4.2.19.Final
Предыдущая глава — Документация разработчика Hibernate – Глава IV. Пакетная обработка
Следующая глава — Документация разработчика Hibernate – Глава VI. Кэширование
Содержание
5.1. Оптимистичные блокировки
5.1.1 Выделенный номер версии
5.1.2. Timestamp
5.2. Пессимистичные блокировки
Перевод статьи актуален для версии Hibernate 4.2.19.Final
Предыдущая глава — Документация разработчика Hibernate – Глава IV. Пакетная обработка
Следующая глава — Документация разработчика Hibernate – Глава VI. Кэширование
Содержание
5.1. Оптимистичные блокировки
5.1.1 Выделенный номер версии
5.1.2. Timestamp
5.2. Пессимистичные блокировки
Как поступить в магистратуру в Англии
3 min
Мне 26 лет, я веб-разработчик в Берлине и я никогда не учился в университете.
Как работает реляционная БД
51 min
Tutorial
Translation
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.На самом деле, мало кто действительно понимает, как работают реляционные БД. А многие разработчики очень не любят, когда они чего-то не понимают. Если реляционные БД используют порядка 40 лет, значит тому есть причина. РБД — штука очень интересная, поскольку в ее основе лежат полезные и широко используемые понятия. Если вы хотели бы разобраться в том, как работают РБД, то эта статья для вас.
Что хабровчане носят с собой, или хвастаемся EDC (+ обзор рюкзака Thule TCBP-217)
8 min
С каждым днем количество электроники которую человек берет с собой за пределы дома растет, и несмотря на ее тотальное уменьшение и облегчение, количество гаджетов у отдельных особей может составлять весьма длинный список. Встает вопрос: в чем носить? Да так, чтобы удобно и безопасно для электроники? Сегодня расскажу о годном гик-рюкзаке на 32 литра Thule TCBP217 ну, и конечно же, всех приглашаю в EDC тред.

Осторожно: много картинок!
Осторожно: много картинок!
Что почитать, чтобы повысить свой уровень JavaScript
3 min
Translation
От переводчика: Я думаю многие читали статью Rey Bango — What to Read to Get Up to Speed in JavaScript, но до хабра обсуждение так и не докатилось. Предлагаю закрыть этот пробел и поговорить о хороших книгах, блогах, тренингах и конференциях, посвященных в первую очередь клиентскому JavaScript и клиентской веб-разработке. Чтобы не копипастить оформляю статью в виде перевода.
Сейчас в рассылке JSMentors JavaScript идет обсуждение книг, который стоит прочитать, чтобы улучшить свои знания. Там было много позитивных отзывов и предложений. Я хочу показать вам те книги и интернет-ресурсы, который я считаю важными и которые помогут вам в обучении. На этой странице я перечислил большое количество источников, разделенных по уровням.
Учтите, что некоторый ресурсы могут принадлежать нескольким уровням и охватывают широкие аспекты языка. Если вы считаете, что я что-то упустил, пожалуйста, дополните меня в комментариях.
Не заставляю вас читать все книги, которые предложены ниже. Эти книги я читал на протяжении многих лет и почерпнул в каждой много полезного. Я их распределяю по категориям, чтобы вам было проще работать с ними. Выберите книги, которые подходят вам.
Сейчас в рассылке JSMentors JavaScript идет обсуждение книг, который стоит прочитать, чтобы улучшить свои знания. Там было много позитивных отзывов и предложений. Я хочу показать вам те книги и интернет-ресурсы, который я считаю важными и которые помогут вам в обучении. На этой странице я перечислил большое количество источников, разделенных по уровням.
Учтите, что некоторый ресурсы могут принадлежать нескольким уровням и охватывают широкие аспекты языка. Если вы считаете, что я что-то упустил, пожалуйста, дополните меня в комментариях.
Не заставляю вас читать все книги, которые предложены ниже. Эти книги я читал на протяжении многих лет и почерпнул в каждой много полезного. Я их распределяю по категориям, чтобы вам было проще работать с ними. Выберите книги, которые подходят вам.
node.js для Java-разработчиков: первые шаги
9 min
Tutorial

У опытного программиста, сталкивающегося с новой технологией для решения конкретной прикладной задачи, сразу возникает множество практических вопросов. Как правильно установить платформу? Где и что будет лежать после установки? Как создать каркас проекта, как он будет структурирован? Как разбивать код на модули? Как добавить библиотеку в проект? Где вообще взять готовую библиотеку, которая делает то, что нужно? Как и в чём отлаживать код? Как написать модульный тест?
Ответы на эти вопросы можно при желании легко найти в сети, но придётся перечитать дюжину статей, и на каждый вопрос ответов будет, скорее всего, несколько. Некоторое время назад мне понадобилось написать небольшой туториал по node.js, который бы позволил быстро запустить разработку и познакомить новых программистов в проекте с этой технологией. Рассчитан он на опытных Java-разработчиков, которые и язык JavaScript хорошо знают, но node.js как платформа для бэкэнда для них в новинку.
Думаю, что данная статья будет полезна не только разработчикам из мира Java, но и всем, кто начинает работу с платформой node.js.

Антон Кекс: Как нам спасти Java?
2 min
Recovery Mode
Здравствуй, %USERNAME%!
Наткнулся в этих ваших интернетах на одно замечательное видео — презентация Антона Кекса в двух частях.
Приглашаю вас посмотреть это видео и присоединиться к дискуссии в комментариях. После опубликования поста я собираюсь выслать на указанные на слайдах контакты Антона приглашение присоединиться к нам, и ответить на наши вопросы. Надеюсь, у него уже есть аккаунт на Хабре, ибо инвайта у меня нету.
Наткнулся в этих ваших интернетах на одно замечательное видео — презентация Антона Кекса в двух частях.
Приглашаю вас посмотреть это видео и присоединиться к дискуссии в комментариях. После опубликования поста я собираюсь выслать на указанные на слайдах контакты Антона приглашение присоединиться к нам, и ответить на наши вопросы. Надеюсь, у него уже есть аккаунт на Хабре, ибо инвайта у меня нету.
20 и другие цифры
3 min
Я, как и вы, знаю, что Джеймс Гослинг — великий человек, гигант, такой же, как Керниган, Ричи и Страуструп — начал разработку нового языка Oak 24 года назад. Я так же, как и вы, знаю, что активная жизнь нового языка началась 19 лет назад, когда в Интернете появилась его первая официальная версия от Sun Microsystems, и все мировые софтверные разработчики начали приобретать лицензии на Java 1.0. Но я праздную именно 20-летие Java. Возможно, я сентиментален, но для меня Java — это Java, а не какой-нибудь дуб. И для меня важно, что язык Java получил свое настоящее имя именно 20 лет назад. В честь вот этой вот чашечки кофе:

Про Git на пальцах (для переходящих с SVN)
8 min
Год назад мы с командой решили перейти с SVN на Git. Зачем это было надо — писать не буду, т.к. на эту тему уже и так много написано. А хочу я описать типичные алгоритмы работы, понятные человеку, который долгое время пользовался SVN. Ниже — памятка, написанная для команды год назад, чтобы легче было мигрировать. Надеюсь, кому-нибудь пригодится.
Забудьте САР теорему как более не актуальную
12 min
Translation
или «Прекратите характеризовать хранилища данных как CP или AP»
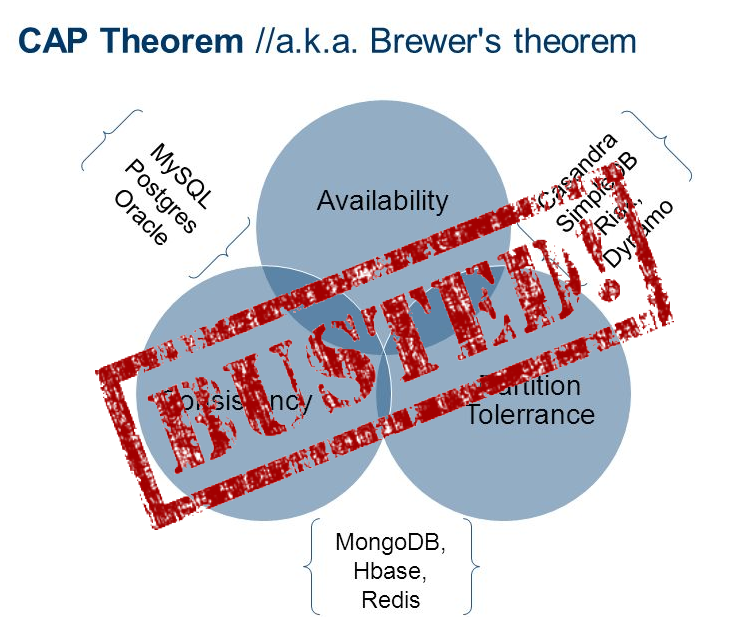 Джеф Ходжес в своем прекрасном посте «Заметки о распределенных системах для новичков» рекомендует использовать САР теорему для критики найденных решений. Многие, похоже, восприняли этот совет слишком близко к сердцу, описывая свои системы как «СР» (согласованность данных, но без постоянной доступности при сетевой распределенности), «АР» (доступность без согласованного состояния при сетевой распределенности), или иногда «СА» (означает «Я всё ещё не читал статью Коды (Coda Hale) почти 5-летней давности»).
Джеф Ходжес в своем прекрасном посте «Заметки о распределенных системах для новичков» рекомендует использовать САР теорему для критики найденных решений. Многие, похоже, восприняли этот совет слишком близко к сердцу, описывая свои системы как «СР» (согласованность данных, но без постоянной доступности при сетевой распределенности), «АР» (доступность без согласованного состояния при сетевой распределенности), или иногда «СА» (означает «Я всё ещё не читал статью Коды (Coda Hale) почти 5-летней давности»).
Я согласен со всеми пунктами статьи кроме того, что касается САР теоремы. Она слишком всё упрощает и слишком многие понимают её неверно для того, чтобы использовать для определения характеристик системы. Так что я прошу перестать ссылаться на САР теорему, говорить о ней и дать ей уже спокойно уйти на покой. Вместо неё мы должны использовать более точную терминологию для обсуждения различных компромиссов.
(Да, я понимаю всю иронию написания целой статьи по теме того, о чём призываю не писать других вообще. Но, как минимум, у меня будет ссылка, которую я смогу давать интересующимся, когда меня будут спрашивать, почему я не одобряю обсуждение САР теоремы. Также, я хочу извиниться, если статья вам покажется слишком напыщенной, но эта напыщенность опирается на множество ссылок.)
Если вы хотите ссылаться на САР как на теорему (а не на расплывчатый концепт в маркетинговых материалах к вашей базе данных), вы должны быть точны. Математика требует точности. Доказательство сохраняется только если вы вкладывается в слова, то же самое значение, что было использовано при доказательстве. И оно опирается на очень точные определения:
Джеф Ходжес в своем прекрасном посте «Заметки о распределенных системах для новичков» рекомендует использовать САР теорему для критики найденных решений. Многие, похоже, восприняли этот совет слишком близко к сердцу, описывая свои системы как «СР» (согласованность данных, но без постоянной доступности при сетевой распределенности), «АР» (доступность без согласованного состояния при сетевой распределенности), или иногда «СА» (означает «Я всё ещё не читал статью Коды (Coda Hale) почти 5-летней давности»).Я согласен со всеми пунктами статьи кроме того, что касается САР теоремы. Она слишком всё упрощает и слишком многие понимают её неверно для того, чтобы использовать для определения характеристик системы. Так что я прошу перестать ссылаться на САР теорему, говорить о ней и дать ей уже спокойно уйти на покой. Вместо неё мы должны использовать более точную терминологию для обсуждения различных компромиссов.
(Да, я понимаю всю иронию написания целой статьи по теме того, о чём призываю не писать других вообще. Но, как минимум, у меня будет ссылка, которую я смогу давать интересующимся, когда меня будут спрашивать, почему я не одобряю обсуждение САР теоремы. Также, я хочу извиниться, если статья вам покажется слишком напыщенной, но эта напыщенность опирается на множество ссылок.)
САР использует слишком узкое определение
Если вы хотите ссылаться на САР как на теорему (а не на расплывчатый концепт в маркетинговых материалах к вашей базе данных), вы должны быть точны. Математика требует точности. Доказательство сохраняется только если вы вкладывается в слова, то же самое значение, что было использовано при доказательстве. И оно опирается на очень точные определения: