Комментарии 38
Для фильтров хорошо подходит спецификация (но согласен, там тоже текучесть).
При должном усилии можно подружить с чистым sql.
И как вы сделаете, чтобы одновременно было удобно (т.е. пользователь мог сделать свой фильтр) и не текло, как IQueryable?
А зачем пользователю делать свой фильтр?
Пользователь API — программист.
Но вообще, конечно, если для вас ситуации, когда пользователь (конечный) хочет фильтры в табличке "чтобы как в экселе" — экзотика, то у нас с вами радикально разные целевые аудитории.
У вас фильтрация только на равенство. Этого недостаточно. Нужны диапазоны, нужны строковые операции, нужны операции над частями дат (включая запрос "только по будням").
Ну и что — все это так сложно сделать?
Не столько сложно, сколько просто много кода. Лайк, очень много кода.
Все равно для пользователя будет только определенный набор опций.
Вот об этом, собственно и речь: когда этого набора будет не хватать, кто и в каких местах системы должен внести изменения?
Разработчик.
Разработчик какого слоя системы? У вас как минимум есть DAL и UI.
Я для себя нашел решение в виде повторения синтаксического дерева SQL (даже статья на хабре про это есть "Дерево синтаксиса и альтернатива LINQ при взаимодействии с базами данных SQL"). “Разухабистый” фильтр передается в виде выражения по всем уровням абстракции (сериализация /десериализация в JSON/XML происходит без проблем) в репозиторий, где он легко превращается в SQL текст. Пользуюсь этим подходом уже несколько лет, забыв про все эти IQueryable как про страшный сон. Все наработки выложил в виде библиотеки на github.
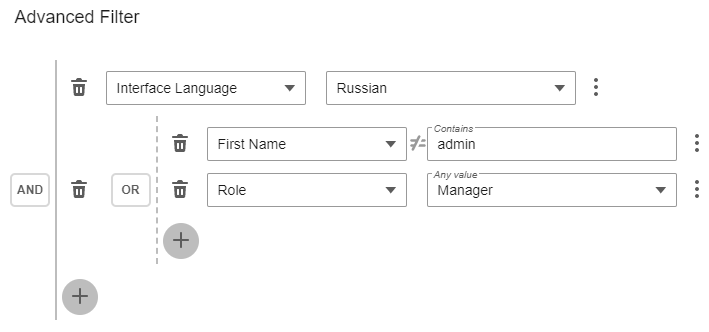
и JSON создаваемый в клиентском приложении, который легко преобразуется в синтаксическое дерево логического выражения и передается в таком виде до репозитория, где и вставляется в нужный запрос.
{"typeTag":"and","items":[{"typeTag":"oneOfNum","field":"i_lcid","values":[1049]},{"typeTag":"or","items":[{"typeTag":"not","expr":{"typeTag":"containsStr","field":"vch_firstname","value":"admin"}},{"typeTag":"hasAnyInt","field":"i_user_role","values":[11]}]}]}Причем к запросу можно автоматически добавить подзапрос, добавляющий “вычисляемое” поле если оно есть в фильтре.
Иногда надо просто принять что, набор данных на 100 записей из 5-7 полей лучше отфильтровать на слое бизнес-логики, а не пытаться сделать все в БД и получать дырявые абстракции. Но тут конечно, надо быть осторожным. Такие таблицы иногда могут вырасти)
В общем золотой пули нет, и каждый раз надо смотреть на баланс трудозатрат на разработку, тестирование и поддержку «красивого решения» и профита которое оно даст.
Всё плохо, но что делать, куда идти и прочее — отсутствует.
При этом, проблема действительно есть, есть давно, все уже привыкли =)
А вывод простой — не передавать IQueryable между слоями, его надо оставить его на уровне DAL.
Или я что-то не знаю про GraphQL?
Ну а если кто то что то не правильно реализовал, его вина, пусть исправляет. Как то я не знаю такого языка или фреймворка который бы помогал с такого рода проблемами ))
Может автор прокомментирует.
Каким образом интерфейс может нарушать LSP? Реализация — запросто, но интерфейс то как?
В общем случае плохо «отвечать за все сразу», но это никак к LSP не относится.
Вся дискуссия в итоге о том, стоит ли IQueryable светить в «публичном» API. Я соглашусь с тем, что не стоит, но LSP тут ни при чем. LSP ничего не говорит о сложности реализации или вероятности ошибиться во время реализации. Вот скажите — если вместо IQueryable в API будет Expression от этого что-то поменяется? Expression вообще реализовывать не нужно, он дан нам свыше :)
Я могу аргументировать против IQueryable в публичном API, без привлечения Лисков. Так как IQueryable завязан на провайдера, который часто владеет ценным ресурсом вроде подключения к БД, то нужно всегда знать время жизни этого объекта. А если мы его отдаём всем направо и налево, то жди беды.
Где в IQueryable сказано о базе и о времени жизни? Хм, может быть в IQueryProvider? Нет? Что же это — «детали реализации» получается? Может быть, даже существуют провайдеры, работающие со внешним API, а не БД в качестве источника данных? Так это, выходит, что разные реализации провайдеров не взаимозаменяемы? Как же назывался этот принцип?
Если невозможно сделать две взаимозаменяемых (и полезных) реализации интерфейса, то выполнение LSP для этого интерфейса невозможно.
IQueryable порождает сильную связанность