CPU-bound вычисления в питоне выполняются однопроцессно
Нет! Это издержки GIL. Если лень смотреть в исходники, просто см. результат для многопоточного исполнения (натяжение "ручника" зависит от количества потоков, что при N threads < M CPU core однозначно указывает на overhead от "чрезмерной" блокировки).
Странный пример...
Пример как пример... Можно попробовать что-нибудь другое (не "CPU-bound"), результат не изменится. А можно попробовать что-нибудь без GIL (Iron, PyPy STM, хоть тот же PoC Сэма) и узреть разницу.
только в данном случае переключать поток
Никакой поток тут нигде не переключается (напрямую)... каждый поток исполняет собственный изолированный код (с собственным циклом и своими переменными - с полностью независымыми объектами PyObjectи PyVarObject) и context-switch если и происходит, то исключительно на lock-ах в GIL (совершенно не нужном здесь, т.к. пересечений и shared references нет совсем). Пример собственно это и показывает.
Если что, в приведенном примере ("тупой" инкремент в цикле 100M раз) для 4-х потоков, python медленнее вашего любимого языка без GIL tcl в 15 раз (35 сек. vs. 2.3 сек.), а однопоточно более чем в 3 раза. И это при том, что собственно код исполнения не "пересекается" нигде - не использует общих (shared) объектов.
Несомненно, что бинарное возведение в степень на практике даёт неточный результат.
Ну дак а я о чем, "Погрешность: нет" - как бы не совсем верно, если про этот алгоритм...
Я про другое: что «родная» pow даёт столь же неточный результат.
В рамках double - конечно. Я вам больше скажу, например тот же bigfloat.pow (даже с precision 400) также выдает "неточный" результат (и он менее точен чем нативный pow):
Но если округлить результаты до оригинальной accuracy - то все результаты верны. Что не отменяет факт, что результат pow может сильно отличатся и погрешность есть, хоть и небольшая - для bigfloat.pow (и BinaryPower) около 11.04e-7%, а для pow - 08.04e-7%, что очень неплохо для степени 134217728.
Ну у Wolfram precision и accuracy настраиваемые (если не ошибаюсь оно умеет длинную FP-арифметику, exact quantities и всё такое)... Пример алгоритма был для double (aka 64 bits IEEE normalized double-precision floating-point number) и C/C++... Я это о чем, собственно - что-то математически правильное (и доказуемо верное) в конкретной реализации на конкретном языке для какой-либо платформы может вылиться в неслабую такую погрешность (из-за переполнений, недостаточной precision промежуточных результатов и т.п.)...
В приведённой таблице не микротики (и вероятно даже не зомби-хосты), а грубо говоря количество точек с активным TCP-listener на 5678 порту, ибо:
Возможно, Mikrotik и Linksys не единственные, но у нас нет другого выбора, кроме как предположить, что 328 723 – это и есть число хостов в активном ботнете.
Например, у меня рутер тоже 5678 портом наружу торчит, но ваш покорный слуга использует его для совершенно других нужд (порт то как бы для RRAC изначально), и у меня не микротик, но меня возможно тоже посчитали.
Странно, что сперва речь шла про комбинацию с портом 2000:
Однако конкретная комбинация порта 2000 с «Bandwidth test server» и порта 5678 с «Mikrotik Neighbor Discovery Protocol» почти не оставляет почвы для сомнений в наших выводах.
Но просканировали почему-то только на предмет открытости TCP 5678:
... мы решили проверить TCP-порт 5678 с помощью Qrator.Radar
Давайте уже говорить про адекватно определённые целые типы.
А давайте без давайте не передёргивать — что имелось ввиду я думаю понятно, ну или если хотите замените char на int8_t.
Я не думаю, что T-деление более странное, чем F-деление.
Кавычки на слове "странный" вы старательно не заметили по видимому. Если что это была попытка в сарказм.
ни тесты не помогут против такого, когда компилятору вдруг взбрело в "голову"
И как оно не проявится на тестах? Когда код покрывают тестами, оно должно быть для всех corner case. Если компилятору что то там "взбрело в голову", вплоть до UB, то ваши тесты должны это показать, иначе у вас покрытие как минимум не полное.
Компилятор транслирует код из С++ через несколько представлений в код процессора (читай Ассемблера).
Ну да, ну да...
А у Ассемблера правил меньше, но они чёткие и ясные.
То-то все всегда всё пишут на ассемблере. А например какие-нибудь SIMD или псевдоинструкции и подобное ну очень ясные и понятные.
И делить -3 на 3u командой DIV сразу вылезет боком.
Вы удивитесь возможно, но делить можно совсем без DIV инструкций.
Я уж умолчу когда C-код компилится во что-нибудь другое, не нативное, типа LLVM (clang -emit-llvm), не говоря уже про экзотику типа WASM и т.д. и т.п.
Есть еще теория компиляторов. Там за такие преобразования сразу с экзамена долой.
У нас с вами разные профессора по видимому преподавали — мне например объясняли почему так и зачем оно может быть нужно.
А может и вам объясняли да позабылось, эта картинка ничего не напоминает?
Есть еще и другие языки программирования. На них такого поведения не наблюдается.
Правда?!.. Дайте угадаю, вы пришли в С/С++ из так называемых "высокоуровневых" языков?
А по теме если — ну вот при чём тут другие языки? В качестве примера разделите -300001 на 50000 на сях или плюсах и затем на вашем любимом "другом" языке.
Подсказка — ни то, ни другое не является неправильным, это просто разные подходы (а именно remainder vs. residual arithmetic), и обоим есть соответствующее обоснование в парадигмах конкретного языка.
Хорошо задокументированная бага становится фичей! Многие не видят уже багу, а видят фичу.
Это не бага от слова совсем. Если вы не понимаете зачем это нужно, это не значит, что это сразу внезапно ошибка.
Ну почитайте классику в конце-то концов.
В качестве примера вопрос для "на подумать" — у вас есть две целочисленные переменные фиксированной (что важно), но при этом разной разрядности (ибо одно грубо говоря на 1 бит короче), которые вы делите или умножаете друг на друга… Как наиболее оптимально сделать это без объявления такого действия UB, максимально используя их разрядность (или оставаясь в заданной размерности), при этом согласуя их conversion rank и т.п., чтобы в большем числе случаев результат оказался предсказуемо "хорошим"? (заметьте не математически правильным, ибо это просто нереально при вероятном переполнении)… Другими словами — как оттянуть тот момент переполнения?
Даже с 20 годами опыта легко расслабиться и пропустить подобную диверсию где-то в коде, особенно когда это осложнено макрами, шаблонами и прочими факторами, которые сбивают очевидность, рассеивая внимание и делая неочевидными влияющие факторы (где какой тип).
Ну да, странно же в языках типа C/C++ с целочисленными типами фиксированной разрядности… где и переполнение точно таким же образом словить можно (вас не смущает например что (char)127+2 == -127?), и несколько "странный" остаток при делении отрицательного на положительное число (см. remainder vs. residual arithmetic) и т.п.
Я стесняюсь спросить а те 20 лет опыта точно в C/C++?
Кроме того ну есть же warnings, тестовое покрытие и т.д.
Шутки типа "участие unsigned int приводит к беззнаковой операции, а участие unsigned short — нет, ибо он вначале конвертируется в signed int" ещё усложняют это.
Ничего оно тут не усложняет — приведение типов к большей разрядности это тоже часть usual arithmetic conversions и это просто тупо — вопрос приоритетов.
Кастить -4 к беззнаковому в общем случае полная ерунда, поэтому если кастишь, то должен быть точно уверен зачем.
Совершенно верно!
Тут как бы деление с остатком (внезапно это 1), т.е. чтобы из -4 сделать -3 (или 4294967293), нужно по всем правилам добавить тот остаток после умножения, т.е. написать такое:
// (4294967293 / 3 * 3 + 4294967293 % 3) == 4294967293 == -3 (as signed int)
(-3/3u)*3 + (-3%3u)
// ну или кастить собственно до деления:
-3/(signed)3u*3
Я вообще не понимаю о чем тут баттхерт и почему вдруг стандарт надо переписать?! Потому что человек вдруг открыл для себя увидел usual arithmetic conversions в действии? Ну ОК тогда.
Нет. Все риски (ну как все — один) на себя берёт пользователь выдавший Lastschrift-мандат третьей стороне. Выдав его, он "обязан" собственноручно проверять свой счет (самостоятельно мониторить те Lastschrift списания со счета), а также наличие средств на том счете. При этом у него есть 8 недель чтобы отозвать платеж, если тот мандат выдавался фирме "списавшей" деньги, и до 13 месяцев, если он совсем неправомерный (мандат не был выдан вовсе или был отозван).
Да ну? Вот прямо штраф, вот прямо государству? ...
и
Так я же именно про это и говорил
ну как бы не совсем про это, nicht wahr? :)
В праве действительно есть параграф про денежный штраф, не говоря уже про срок…
Я просто уточнил, для "сумлевающихся" так сказать, что таки — да, "вот прямо штраф".
Было бы интересно посмотреть на Bußgeldbescheid :)
Да пожалуйста, вот вам даже приговор суда (BGH I ZR 48/15), первый попавшийся…
В этом случае Bußgeldbescheid не будет, будет только Kostenentscheidung (с оплатой штрафа, если назначат + Gerichtskosten, и т.п.).
А вообще зависит от того, доведут ли дело до суда, ибо очень часто решается досудебным договором (aussergerichtlich), ну и если довели, как судья на то посмотрит…
В худшем случае может грозить Urheberrechtverletzung, а Urheberrecht ужесточили (кажется в 2019 или 2020):
"В этом случае частным лицам грозит либо денежный штраф, либо лишение свободы на срок до трех лет."
(А если вдруг признают что вы тем занимались в коммерческих целях то до 5 лет).
В общем, тут довольно много нюансов, и ходящая среди эмигрантов из СНГ страшилка про «штрафы за скачивание фильмов» по факту очень сильно преувеличена.
За "скачивание" — то действительно чушь, но проблема с торрентами — как правило — это параллельное "распространение", ибо торрент-клиенты тот ваш стрим могут тут же расшарить.
Из моих знакомых — около десятка случаев, причем половина не доводили до суда (оплатили требования + стоимость адвокатов + подписали договор), вторая же часть тупо не оплачивала, и тут как свезло, или не успели в срок (в этих делах Verjährungsfrist — 3 года от конца года в котором Abmahnung прилетел), просто потому что суды переполнены судей не хватает, или на вас попросту забили (потому что рыбка пожирнее нашлась), или всё таки довели до суда, и тогда — всё по полной программе.
А доказать что-то там всё очень сложно, и там не как в уголовном праве — презумпции невиновности нет. Т. е. доказывать например, что вашим WLAN воспользовались какие-то "злоумышленники" (а вы и знать не знали) придется именно вам (вашему адвокату).
Посадить то из них никого не посадили, но одному штраф не маленький такой присудили. Ну а судебные издержки и адвокаты истца оплачиваются всеми (если вина признана хотя бы частично).
В логику ТСПУ вставили проверку для замедления на все .*t.co.*, вместо, например, ^t.co$.
Ну для поиска первой регулярки .* спереди/сзади без якорей как бы не нужны, точки перед доменом (в обоих вариантах) надо проэскейпить, и лучше к якорю для начала добавить туже точку (чтобы ловить и под-домены) или какой другой lookbehind для границ домена, т.е. будет что то вида:
- `.*t.co.*`, вместо, например, `^t.co$`
+ `t\.co`, вместо, например, `(?:^|\.)t\.co$`
Ну ну, расскажите мне как тут всё "нормально"… Я уже как бы добрую четверть века в Германии инженером оттрубил и весь этот outsourcing тренд можно сказать изнутри пережил… Про "просрали" речь действительно не идет (но то ваши а не мои слова), однако назвать это "нормальным" у меня язык точно никак не поворачивается.
Да да… сначала вывезли всё и вся, что только каким-либо способом реально было перетащить (аутсорсинг наше всё)… а теперь будем "активно" строить.
А всё остальное от сырья до инженеров по видимому само появится. Особенно интересно когда в том дефиците чипов прослеживается например нехватка поли-Si пластин, крупнейшим поставщиком которых (наряду с другими не менее важными типами сырья) внезапно является опять Китай… Т.е. активно строить будем вероятно всё, обеспечивающее всю ту цепочку производственного процесса от и до.
А если ещё вспомнить всем известную немецкую бюрократию, кучу регулирующих органов, то всё это строительство в особенно прекрасном свете предстаёт.

Что, простите?!
Нет! Это издержки GIL. Если лень смотреть в исходники, просто см. результат для многопоточного исполнения (натяжение "ручника" зависит от количества потоков, что при N threads < M CPU core однозначно указывает на overhead от "чрезмерной" блокировки).
Пример как пример... Можно попробовать что-нибудь другое (не "CPU-bound"), результат не изменится. А можно попробовать что-нибудь без GIL (Iron, PyPy STM, хоть тот же PoC Сэма) и узреть разницу.
Никакой поток тут нигде не переключается (напрямую)... каждый поток исполняет собственный изолированный код (с собственным циклом и своими переменными - с полностью независымыми объектами
PyObjectиPyVarObject) и context-switch если и происходит, то исключительно на lock-ах в GIL (совершенно не нужном здесь, т.к. пересечений и shared references нет совсем).Пример собственно это и показывает.
Как-то пытался объяснять последствия изоляции всего и вся GIL-ом в python, и накидал маленький пример для наглядности:
https://gist.github.com/sebres/230c4bfafc36c99074202dc59b194a95
Если что, в приведенном примере ("тупой" инкремент в цикле 100M раз) для 4-х потоков, python медленнее
вашего любимого языка без GILtcl в 15 раз (35 сек. vs. 2.3 сек.), а однопоточно более чем в 3 раза.И это при том, что собственно код исполнения не "пересекается" нигде - не использует общих (shared) объектов.
Ну дак а я о чем, "Погрешность: нет" - как бы не совсем верно, если про этот алгоритм...
В рамках double - конечно.
Я вам больше скажу, например тот же bigfloat.pow (даже с precision 400) также выдает "неточный" результат (и он менее точен чем нативный pow):
bigfloat.pow, precision 400 ...
Для сравнения возьмем корни от обоих (этот алгоритм у bigfloat насколько знаю точнее чем pow):
bigfloat.root в сравнении с Wolfram ...
Но если округлить результаты до оригинальной accuracy - то все результаты верны.
Что не отменяет факт, что результат pow может сильно отличатся и погрешность есть, хоть и небольшая - для bigfloat.pow (и BinaryPower) около
11.04e-7%, а для pow -08.04e-7%, что очень неплохо для степени 134217728.Ну у Wolfram precision и accuracy настраиваемые (если не ошибаюсь оно умеет длинную FP-арифметику, exact quantities и всё такое)...
Пример алгоритма был для double (aka 64 bits IEEE normalized double-precision floating-point number) и C/C++...
Я это о чем, собственно - что-то математически правильное (и доказуемо верное) в конкретной реализации на конкретном языке для какой-либо платформы может вылиться в неслабую такую погрешность (из-за переполнений, недостаточной precision промежуточных результатов и т.п.)...
Я бы не стал так категорично...
Как видим ошибка может быть довольно значительной, я уж не говорю про
-Ofast(без-fno-fast-math).Поправка: пример компилился в
-m32toolchain... для-m64погрешности действительно нет (по крайней мере на этих числах).А правильно было бы как-то так:
A girl with a plait on a spit mowed the grass with a scythe.
В приведённой таблице не микротики (и вероятно даже не зомби-хосты), а грубо говоря количество точек с активным TCP-listener на 5678 порту, ибо:
Например, у меня рутер тоже 5678 портом наружу торчит, но ваш покорный слуга использует его для совершенно других нужд (порт то как бы для RRAC изначально), и у меня не микротик, но меня возможно тоже посчитали.
Странно, что сперва речь шла про комбинацию с портом 2000:
Но просканировали почему-то только на предмет открытости TCP 5678:
Бог с ней с новостью… А то что этот "полу-новость-полу-пост" выглядит практически переводом (без плашки и указаний источника) никого не смущает?
А давайте
без давайтене передёргивать — что имелось ввиду я думаю понятно, ну или если хотите замените char на int8_t.Кавычки на слове "странный" вы старательно не заметили по видимому. Если что это была попытка в сарказм.
И как оно не проявится на тестах? Когда код покрывают тестами, оно должно быть для всех corner case. Если компилятору что то там "взбрело в голову", вплоть до UB, то ваши тесты должны это показать, иначе у вас покрытие как минимум не полное.
Нет. Точка.
Оно оправдано и обосновано.
Ну да, ну да...
То-то все всегда всё пишут на ассемблере. А например какие-нибудь SIMD или псевдоинструкции и подобное ну очень ясные и понятные.
Вы удивитесь возможно, но делить можно совсем без DIV инструкций.
Я уж умолчу когда C-код компилится во что-нибудь другое, не нативное, типа LLVM (
clang -emit-llvm), не говоря уже про экзотику типа WASM и т.д. и т.п.У нас с вами разные профессора по видимому преподавали — мне например объясняли почему так и зачем оно может быть нужно.
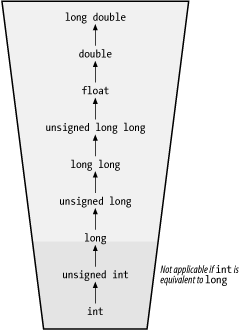
А может и вам объясняли да позабылось, эта картинка ничего не напоминает?
Правда?!.. Дайте угадаю, вы пришли в С/С++ из так называемых "высокоуровневых" языков?
А по теме если — ну вот при чём тут другие языки? В качестве примера разделите -300001 на 50000 на сях или плюсах и затем на вашем любимом "другом" языке.
Подсказка — ни то, ни другое не является неправильным, это просто разные подходы (а именно remainder vs. residual arithmetic), и обоим есть соответствующее обоснование в парадигмах конкретного языка.
Это не бага от слова совсем. Если вы не понимаете зачем это нужно, это не значит, что это сразу внезапно ошибка.
Ну почитайте классику в конце-то концов.
В качестве примера вопрос для "на подумать" — у вас есть две целочисленные переменные фиксированной (что важно), но при этом разной разрядности (ибо одно грубо говоря на 1 бит короче), которые вы делите или умножаете друг на друга… Как наиболее оптимально сделать это без объявления такого действия UB, максимально используя их разрядность (или оставаясь в заданной размерности), при этом согласуя их conversion rank и т.п., чтобы в большем числе случаев результат оказался предсказуемо "хорошим"? (заметьте не математически правильным, ибо это просто нереально при вероятном переполнении)… Другими словами — как оттянуть тот момент переполнения?
Ну да, странно же в языках типа C/C++ с целочисленными типами фиксированной разрядности… где и переполнение точно таким же образом словить можно (вас не смущает например что
(char)127+2 == -127?), и несколько "странный" остаток при делении отрицательного на положительное число (см. remainder vs. residual arithmetic) и т.п.Я стесняюсь спросить а те 20 лет опыта точно в C/C++?
Кроме того ну есть же warnings, тестовое покрытие и т.д.
Ничего оно тут не усложняет — приведение типов к большей разрядности это тоже часть usual arithmetic conversions и это просто тупо — вопрос приоритетов.
Совершенно верно!
Тут как бы деление с остатком (внезапно это 1), т.е. чтобы из -4 сделать -3 (или 4294967293), нужно по всем правилам добавить тот остаток после умножения, т.е. написать такое:
Я вообще не понимаю о чем тут баттхерт и почему вдруг стандарт надо переписать?! Потому что человек вдруг
открыл для себяувидел usual arithmetic conversions в действии? Ну ОК тогда.Хмм… Как бы Танатос, Фанатос, Танат и Фанат — это всё одно лицо (др.-греч. Θάνατος).
Раздвоился?
Нет. Все риски (ну как все — один) на себя берёт пользователь выдавший Lastschrift-мандат третьей стороне. Выдав его, он "обязан" собственноручно проверять свой счет (самостоятельно мониторить те Lastschrift списания со счета), а также наличие средств на том счете. При этом у него есть 8 недель чтобы отозвать платеж, если тот мандат выдавался фирме "списавшей" деньги, и до 13 месяцев, если он совсем неправомерный (мандат не был выдан вовсе или был отозван).
и
ну как бы не совсем про это, nicht wahr? :)
В праве действительно есть параграф про денежный штраф, не говоря уже про срок…
Я просто уточнил, для "сумлевающихся" так сказать, что таки — да, "вот прямо штраф".
Слабоумие иотвага? Или upload (раздача) в торрент-клиенте отрублен?Почитайте мой ответ выше.
Да пожалуйста, вот вам даже приговор суда (BGH I ZR 48/15), первый попавшийся…
В этом случае Bußgeldbescheid не будет, будет только Kostenentscheidung (с оплатой штрафа, если назначат + Gerichtskosten, и т.п.).
А вообще зависит от того, доведут ли дело до суда, ибо очень часто решается досудебным договором (aussergerichtlich), ну и если довели, как судья на то посмотрит…
В худшем случае может грозить Urheberrechtverletzung, а Urheberrecht ужесточили (кажется в 2019 или 2020):
"Privatpersonen droht in diesem Fall entweder eine Geldstrafe oder eine Freiheitsstrafe von bis zu drei Jahren."
"В этом случае частным лицам грозит либо денежный штраф, либо лишение свободы на срок до трех лет."
(А если вдруг признают что вы тем занимались в коммерческих целях то до 5 лет).
За "скачивание" — то действительно чушь, но проблема с торрентами — как правило — это параллельное "распространение", ибо торрент-клиенты тот ваш стрим могут тут же расшарить.
Из моих знакомых — около десятка случаев, причем половина не доводили до суда (оплатили требования + стоимость адвокатов + подписали договор), вторая же часть тупо не оплачивала, и тут как свезло, или не успели в срок (в этих делах Verjährungsfrist — 3 года от конца года в котором Abmahnung прилетел), просто потому что
суды переполненысудей не хватает, или на вас попросту забили (потому что рыбка пожирнее нашлась), или всё таки довели до суда, и тогда — всё по полной программе.А доказать что-то там всё очень сложно, и там не как в уголовном праве — презумпции невиновности нет. Т. е. доказывать например, что вашим WLAN воспользовались какие-то "злоумышленники" (а вы и знать не знали) придется именно вам (вашему адвокату).
Посадить то из них никого не посадили, но одному штраф не маленький такой присудили. Ну а судебные издержки и адвокаты истца оплачиваются всеми (если вина признана хотя бы частично).
Ну для поиска первой регулярки
.*спереди/сзади без якорей как бы не нужны, точки перед доменом (в обоих вариантах) надо проэскейпить, и лучше к якорю для начала добавить туже точку (чтобы ловить и под-домены) или какой другой lookbehind для границ домена, т.е. будет что то вида:Ну ну, расскажите мне как тут всё "нормально"… Я уже как бы добрую четверть века в Германии инженером оттрубил и весь этот outsourcing тренд можно сказать изнутри пережил… Про "просрали" речь действительно не идет (но то ваши а не мои слова), однако назвать это "нормальным" у меня язык точно никак не поворачивается.
Да да… сначала вывезли всё и вся, что только каким-либо способом реально было перетащить (аутсорсинг наше всё)… а теперь будем "активно" строить.
А всё остальное от сырья до инженеров по видимому само появится. Особенно интересно когда в том дефиците чипов прослеживается например нехватка поли-Si пластин, крупнейшим поставщиком которых (наряду с другими не менее важными типами сырья) внезапно является опять Китай… Т.е. активно строить будем вероятно всё, обеспечивающее всю ту цепочку производственного процесса от и до.
А если ещё вспомнить всем известную немецкую бюрократию, кучу регулирующих органов, то всё это строительство в особенно прекрасном свете предстаёт.