История появления
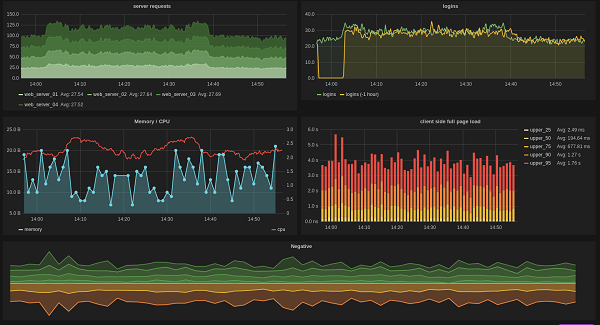
Одной из главных целей команды разработчиков GitHub всегда была высокая производительность. У них даже существует поговорка: «it's not fully shipped until it's fast» (продукт считается готовым только тогда, когда он работает быстро). А как понять, что что-то работает быстро или медленно? Нужно мерять. Измерять правильно, измерять надёжно, измерять всегда. Нужно следить за измерениями, визуализировать всевозможные метрики, держать руку на пульсе, особенно, когда дело имеешь с высоконагруженными онлайн системами, такими как GitHub. Поэтому метрики — это инструмент, позволяющий команде предоставлять столь быстрые и доступные сервисы, почти без даунтаймов.
В своё время GitHub одними из первых внедрили у себя инструмент под названием
statsd от разработчиков из Etsy. statsd — это агрегатор метрик, написанный на Node.js. Его суть состояла в том, чтобы собирать всевозможные метрики и агрегировать их в сервере, для последующего сохранения в любом формате, например, в
Graphite в виде данных на графике. statsd — это хороший инструмент, построенный на UDP сокетах, удобный в использовании как на основном Rails приложении, так и для сбора простейших метрик, наподобие вызова
nc -u. Проблема с ним начала проявляться позже, по мере роста количества серверов и метрик, отправляемых в statsd.