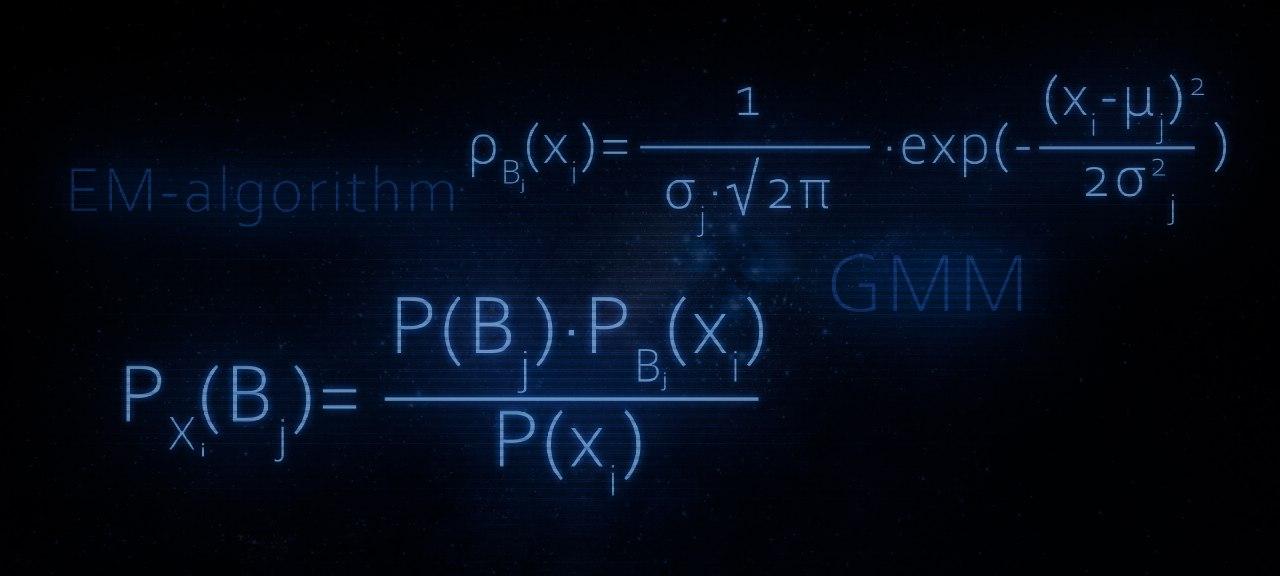
В этой статье, как Вы уже, наверное догадались, речь пойдет об устройстве EM-алгоритма. Статья прежде всего может быть интересна тем, кто потихонечку уже вступает в сообщество датасайнтистов. Материал изложенный в статье в большей степени будет полезен тем, кто недавно начал проходить третий курс «Поиск структуры в данных» в рамках специализации «Машинное обучение и анализ данных» от МФТИ и Яндекс.
Изложенный в статье материал, в каком-то смысле, является дополнением к первой неделе обучения на вышеобозначенном курсе, а именно, позволяет ответить на некоторые немаловажные вопросы, касательно принципа действия EM-алгоритма. Для лучшего понимания материала нашему многоуважаемому читателю желательно уметь осуществлять операции с матрицами (умножение матриц, нахождение определителя матрицы и обратной матрицы), разбираться в основах теории вероятности и матстата, ну и конечно же, иметь хотя бы базовое представление о базовых алгоритмах кластеризации и понимать какое место кластеризация занимает в машинном обучении. Хотя, безусловно, и без этих знаний можно ознакомиться со статьей, что-то да наверняка будет понятным :)
Также по старой традиции, статья не будет содержать глубоких теоретических изысканий, но будет наполнена простыми и доступными для понимания примерами. Каждый последующий пример будет немного глубже предыдущего объяснять действие EM-алгоритма, что в конечном итоге приведет нас прямёхонько к разбору самого алгоритма. Для каждого примера будет написан код. Весь код написан на языке python 2.7, и за это я заранее приношу извинения. Так вышло, что сейчас я использую именно эту версию, но после перехода на python 3, постараюсь изменить код в статье.