Сегодня я расскажу о том, как можно использовать данные о пользователях из социальных сетей для рекомендаций веб-страниц на
холодном старте. Все приведенные в статье результаты носят чисто экспериментальный характер и в настоящий момент не реализованы в продакшене. Здесь, как и в
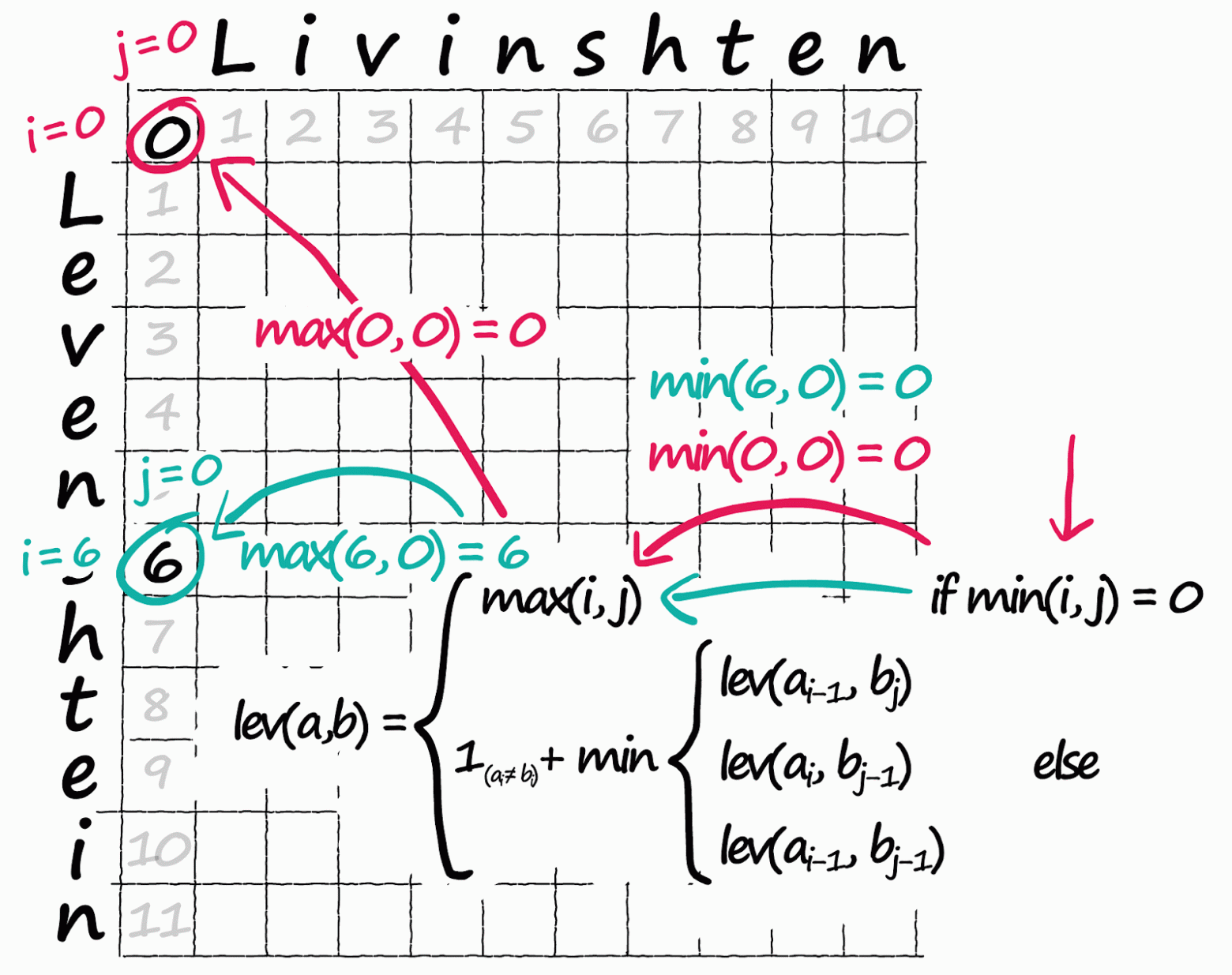
прошлой статье, будут использоваться элементы текстмайнига для анализа текстового контента веб-страниц.
Сначала немного статистики для того, чтобы показать важность настоящего исследования. Около 50% пользователей нашей системы регистрируются с привязкой аккаунтов социальных сетей vkontakte (VK) и facebook (FB). Причем из зарегистрированных через социальные сети 71% приходится на VK и 29% на FB.
API FB и
API VK позволяют извлекать некоторые данные об интересах и предпочтениях пользователя. Но не все так просто, как может показаться. Для получения данных пользователя нужно получить особые права, согласие на которые дает сам пользователь при регистрации в системе. Здесь возникает тонкий момент. С одной стороны, мы ходим вытянуть как можно больше информации о пользователе. С другой стороны, просить слишком много прав — наглость, которая может отпугнуть пользователя. Нужно найти компромисс — тонкое равновесие между полезностью получаемых данных для улучшения рекомендаций и «суммой» кредита доверия от пользователя, который соглашается, чтобы мы залезли в его персональные данные.