Всем привет. Эта статья продолжение
10к на ядро с конкретными примерами оптимизаций, которые были проделаны для повышения производительности сервера. С написания первой части прошло уже 5 мес и за это время нагрузка на наш продакшн сервер выросла с 500 рек-сек до 2000 с пиками до 5000 рек-сек. Благодаря netty, мы даже не заметили это повышение (разве что место на диске уходит быстрее).
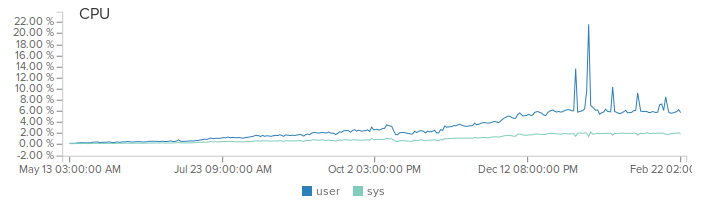
(Не обращайте внимание на пики, это баги при деплое)
Эта статья будет полезна всем тем кто работает с netty или только начинает. Итак, поехали.
Нативный Epoll транспорт для Linux
Одна из ключевых оптимизаций, которую стоит использовать всем — это подключение нативного
Epoll транспорта вместо реализации на java. Тем более, что с netty это означает добавить лишь 1 зависимость:
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-transport-native-epoll</artifactId>
<version>${netty.version}</version>
<classifier>linux-x86_64</classifier>
</dependency>
и автозаменой по коду осуществить замену следующих классов:
- NioEventLoopGroup → EpollEventLoopGroup
- NioEventLoop → EpollEventLoop
- NioServerSocketChannel → EpollServerSocketChannel
- NioSocketChannel → EpollSocketChannel
Дело в том, что java реализация для работы с не блокирующими сокетами реализуется через класс
Selector, который позволяет вам эффективно работать с множеством соединений, но его реализация на java не самая оптимальная. Сразу по трем причинам:
- Метод selectedKeys() на каждый вызов создает новый HashSet
- Итерация по этому множеству создает iterator
- И ко всему прочему внутри метода selectedKeys() огромное количество блоков синхронизации
В моем конкретном случае я получил прирост производительности около 30%. Конечно же, эта оптимизация возможна только для Linux серверов.